
Backend Development Best Practices for Reliability


Reliability is rarely won with a single “big” architecture decision. It is earned through dozens of small, repeatable backend development practices: consistent timeouts, defensive database patterns, clear service boundaries, production-grade observability, and incident discipline. The payoff is direct: fewer outages, faster recovery, and predictable performance that your customers can trust.
This guide focuses on backend development best practices for reliability that work across stacks (monoliths, microservices, event-driven systems) and across cloud providers. If you lead engineering or own production services, treat this as a practical playbook.
Start with reliability requirements you can measure
Many teams say “we need high availability,” then ship a system that cannot prove it. Reliability becomes actionable when it is measured in user outcomes, not infrastructure uptime.
A solid baseline is the SRE model of:
- SLIs (Service Level Indicators): the metrics that reflect user experience (for example, successful checkout rate, p95 API latency)
- SLOs (Service Level Objectives): the targets for those SLIs (for example, 99.9% success rate per 30 days)
- Error budgets: the tolerated unreliability before work shifts from features to stability
Google’s SRE guidance remains one of the clearest references for this approach: see the free Site Reliability Engineering book.
Practical SLIs that map to reality
For most backends, these SLIs cover 80% of reliability outcomes:
- Availability: percentage of successful requests (exclude client errors you did not cause)
- Latency: p50, p95, p99 by endpoint and customer tier
- Correctness: business invariants (for example, “every payment has exactly one ledger entry”) tracked via audits
- Freshness: for async pipelines, time-to-visible (event created to user-visible state)
When you define SLIs, also define the measurement point (edge, API gateway, service, database) and sampling strategy (all traffic vs sampled), otherwise teams argue about numbers during incidents.
Design for failure, not for the happy path
Modern systems fail in messy, partial ways: one dependency degrades, a database replica lags, a queue backs up, a deploy increases memory. Reliability improves fastest when your backend assumes failure is normal and contains it.
The AWS Well-Architected Reliability Pillar is a strong vendor-neutral checklist (even if you are not on AWS).
Timeouts, retries, and backoff (with guardrails)
A common reliability anti-pattern is “we added retries” and accidentally caused a traffic storm.
Good defaults:
- Always set timeouts on outbound calls (HTTP, gRPC, database queries). No timeout means “hang forever,” which is rarely correct.
- Retry only when it is safe (idempotent operations, or operations with idempotency keys).
- Use exponential backoff with jitter to avoid synchronized retry spikes.
- Cap retries and prefer fast failure when a downstream is unhealthy.
If you remember one rule: a retry is additional load. If the downstream is failing due to load, retries amplify the failure.
Idempotency as a first-class API feature
Reliability is not only “staying up,” it is also “not corrupting state when things go wrong.” Idempotency prevents duplicate processing when clients retry, networks drop, or you run parallel consumers.
Common patterns:
- Idempotency keys stored server-side for create-like operations (payments, orders, subscriptions)
- Exactly-once effect via de-duplication tables (messageId as unique key)
- Optimistic concurrency using version fields or ETags for updates
Circuit breakers and bulkheads to stop cascading failures
Cascading failures are what turn small blips into outages.
- Circuit breaker: stop calling a failing dependency for a short window, then probe recovery.
- Bulkhead isolation: separate thread pools, connection pools, or queues per dependency so one slow downstream does not exhaust shared resources.
These patterns are especially valuable when you have “must-not-fail” dependencies such as authentication, payment providers, or broker-style integrations.
Make the database a reliability asset, not a liability
Backend reliability often collapses at the database layer: lock contention, runaway queries, schema migrations, or fragile transaction boundaries.
Guard your data model with invariants
Define invariants that must always hold, then enforce them in the database where possible:
- Unique constraints (prevent duplicate orders)
- Foreign keys (prevent orphan records)
- Check constraints (prevent invalid state)
Application-level validation is important, but database constraints are your last line of defense when concurrency rises.
Control query risk
High-traffic incidents frequently trace back to a single expensive query.
Best practices:
- Establish query timeouts and track slow queries by fingerprint
- Use read replicas carefully (plan for replication lag in user flows)
- Add indexes intentionally, and measure write amplification
- Avoid unbounded queries in customer-facing endpoints (always paginate)
Schema migrations without downtime
Reliability-friendly migrations are incremental and reversible:
- Expand then contract (add new columns, backfill, switch reads, then drop old)
- Use backward-compatible changes during rolling deploys
- Treat migration scripts as production code (reviewed, tested, observable)
Event-driven reliability: consistency, replays, and poison messages
Queues and streams improve resilience, but only if you design for the failure modes.
Use the outbox pattern for reliable event publishing
A classic reliability bug: you update the database, then fail to publish an event, leaving downstream systems inconsistent.
The transactional outbox pattern solves this by writing the event to an outbox table in the same transaction, then publishing asynchronously.
Plan for reprocessing as a normal operation
If you cannot safely replay events, you will be afraid to fix bugs.
- Keep events immutable and versioned
- Make consumers idempotent
- Store enough context to rebuild state (or use compacted topics carefully)
Handle poison messages and backpressure
A single “bad” message can block a partition or saturate a worker pool.
- Implement a dead-letter queue (DLQ) with alerting
- Add max retry counts with exponential backoff
- Expose queue depth and consumer lag as first-class metrics
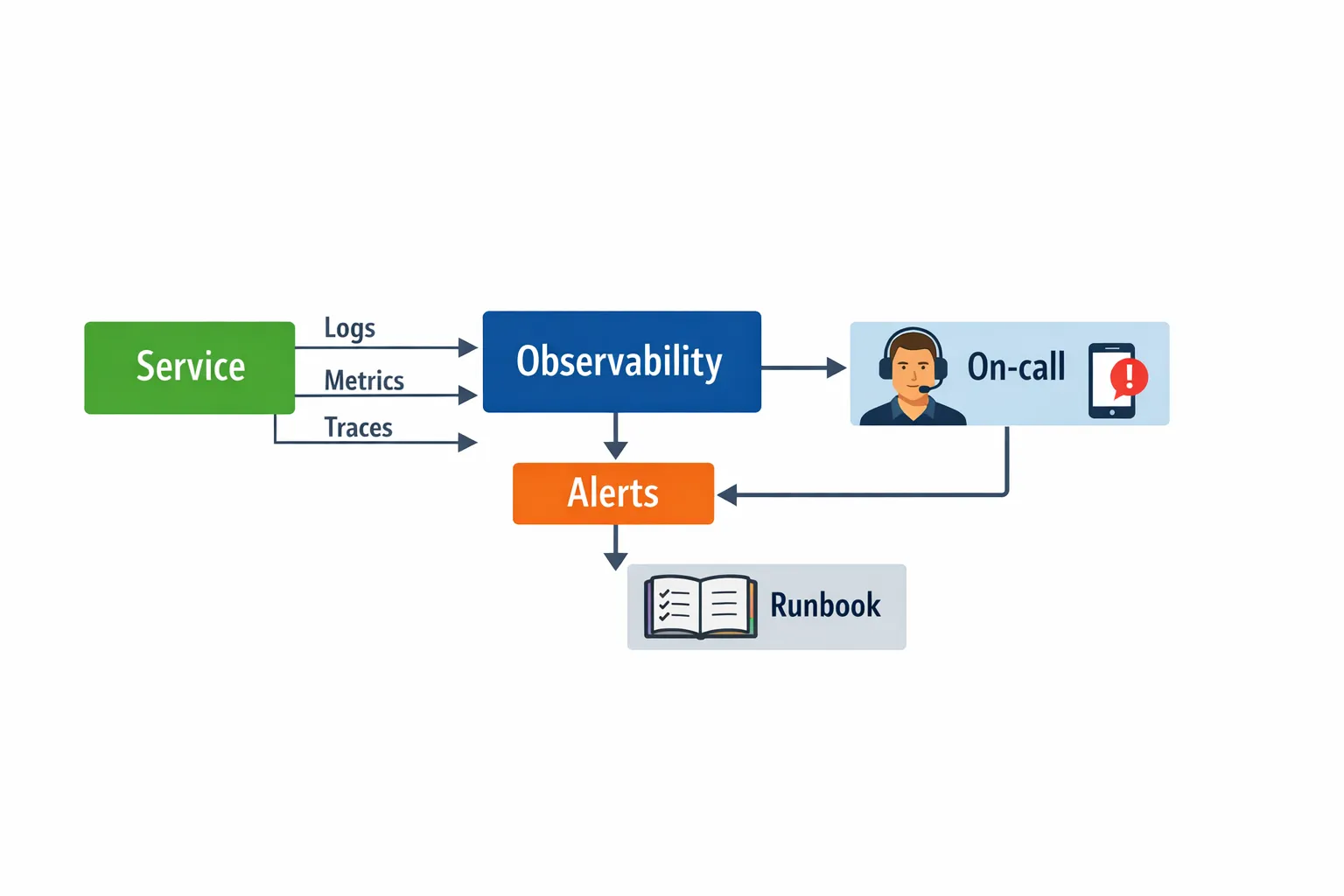
Observability that supports fast diagnosis
Reliability is as much about MTTR (mean time to recovery) as it is about preventing failure. You cannot recover quickly if you cannot see what is happening.
OpenTelemetry has become a practical standard for traces and metrics across languages and vendors: see the OpenTelemetry project.
The minimum viable observability stack
- Structured logs with correlation IDs (requestId, traceId, userId where appropriate)
- Metrics for SLIs, saturation (CPU, memory, pool usage), and business KPIs
- Distributed tracing across service boundaries and async flows
- Actionable alerts tied to SLO burn rate, not raw infrastructure noise
A strong operational habit is to attach a trace or log example to every alert runbook so on-call engineers can jump from “pager” to “where is the time going?” in minutes.
Reliability testing that reflects production
Unit tests are necessary, but they rarely prove reliability. Reliability failures come from integration boundaries, concurrency, and load.
Contract tests for dependency safety
Contract testing prevents breaking changes between services and clients:
- API schema compatibility checks (OpenAPI, protobuf)
- Consumer-driven contracts for critical integrations
- Backward compatibility rules as CI gates
Load tests with realistic failure injection
Aim to answer:
- What is the maximum sustainable throughput before latency spikes?
- What happens when a dependency slows down by 5x?
- What happens when the database is partially unavailable?
Chaos engineering does not need to be dramatic. Even simple, controlled experiments (kill one instance, add latency to one downstream) can reveal hidden coupling.
Deployment practices that reduce blast radius
Most “backend reliability” incidents are change-related. Your deployment process is a reliability feature.
Progressive delivery over big-bang releases
- Canary releases for high-risk services
- Blue/green when rollback speed matters
- Feature flags for business logic changes
The key is observability and automated rollback criteria: if error rates or latency breach thresholds, the system should stop the rollout.
Make rollbacks boring
Rollbacks fail when:
- Schema changes are not backward compatible
- You cannot redeploy the previous artifact quickly
- You rely on manual steps under pressure
A reliable team can answer, “How do we roll back?” as quickly as they answer, “How do we deploy?”
Common backend failure modes and proven mitigations
The table below is a practical mapping you can use during design reviews and incident retrospectives.
| Failure mode | What it looks like in production | Mitigation patterns | What to monitor |
|---|---|---|---|
| Slow downstream dependency | Latency climbs, thread pools saturate | Timeouts, circuit breaker, bulkheads, caching where safe | p95 latency by dependency, pool saturation, error rate |
| Traffic spikes | Elevated 429/503, queue backlogs | Rate limiting, autoscaling, load shedding, backpressure | RPS, queue depth/lag, CPU/memory, rejected requests |
| Duplicate requests/events | Double charges, duplicate orders | Idempotency keys, de-dup tables, exactly-once effect | Duplicate rate, constraint violations, DLQ volume |
| Database contention | High latency, deadlocks, timeouts | Index tuning, query limits, isolate hot rows, caching, sharding only when necessary | Slow queries, lock wait time, connection pool usage |
| Bad deploy | Sudden error rate increase | Canary, automated rollback, feature flags | Error rate by version, SLO burn rate |
| Hidden data corruption | Reports drift, reconciliation failures | Constraints, audit trails, invariants, periodic reconciliation jobs | Invariant violations, reconciliation diffs |
Reliability is domain-dependent (a trading example)
Reliability expectations change by domain. A B2B internal tool can tolerate brief degradation. A financial system often cannot.
For example, in options trading and execution workflows, users expect fast, predictable interactions and clear risk visibility. Even if you are not building trading software, the principle transfers: define reliability around the user’s moment of truth, then engineer backward from it.
A pragmatic reliability checklist by backend layer
Use this as a lightweight review template for new services and for reliability hardening.
| Layer | Reliability best practices | Quick evidence to look for |
|---|---|---|
| API boundary | Timeouts, request limits, idempotency strategy, clear error taxonomy | API docs include retry guidance, 429 usage, idempotency keys |
| Service code | Defensive dependency calls, circuit breaker, bulkheads, graceful shutdown | Configurable timeouts, bounded queues, readiness/liveness checks |
| Data layer | Constraints, safe migrations, query budgets, backups tested | Migration playbooks, slow query dashboards, restore tests |
| Async processing | Outbox, DLQ, replay strategy, idempotent consumers | DLQ alerts, replay tooling, de-dup keys |
| Observability | SLIs/SLOs, traces, structured logs, runbooks | SLO dashboards, trace sampling policy, on-call docs |
| Delivery | Canary/blue-green, automated rollback, config management | Pipeline gates tied to SLO burn, rollback drills |
Where teams get stuck (and how to unblock)
“We are too busy shipping features”
Treat reliability work like product work by tying it to measurable outcomes:
- Reduce change failure rate
- Reduce MTTR
- Improve p95 latency on revenue-critical endpoints
When you frame reliability as “protecting delivery speed,” it competes less with features.
“We do not know what to fix first”
Start with production truth:
- Top 5 incident causes from the last quarter
- Highest SLO burn services
- Most expensive support tickets tied to performance or downtime
Then run a focused hardening sprint with clear exit criteria (for example, “timeouts everywhere,” “idempotency on payments,” “DLQ with alerts”).
How Wolf-Tech can help
If you want an outside, senior review of a backend system’s reliability posture, Wolf-Tech provides full-stack development and engineering consulting across architecture, code quality, legacy optimization, cloud and DevOps, and database/API systems. Typical engagements start with a targeted assessment of failure modes, observability gaps, and deployment risk, then move into hands-on implementation of the highest ROI improvements.
If you are planning a reliability push this quarter, the fastest first step is to define SLIs/SLOs for one critical user journey and map the top three failure scenarios end to end. That creates an execution plan you can actually ship.