
How to Choose the Right Tech Stack in 2025


Choosing a tech stack in 2025 is less about picking trendy tools and more about aligning technology to business outcomes, risk, and operating realities. The right choices accelerate delivery, reduce long‑term costs, and make hiring easier. The wrong ones slow teams down and lock you into brittle systems. This guide gives you a practical, defensible way to decide, with scorecards, tradeoffs, and example stacks you can tailor to your context.
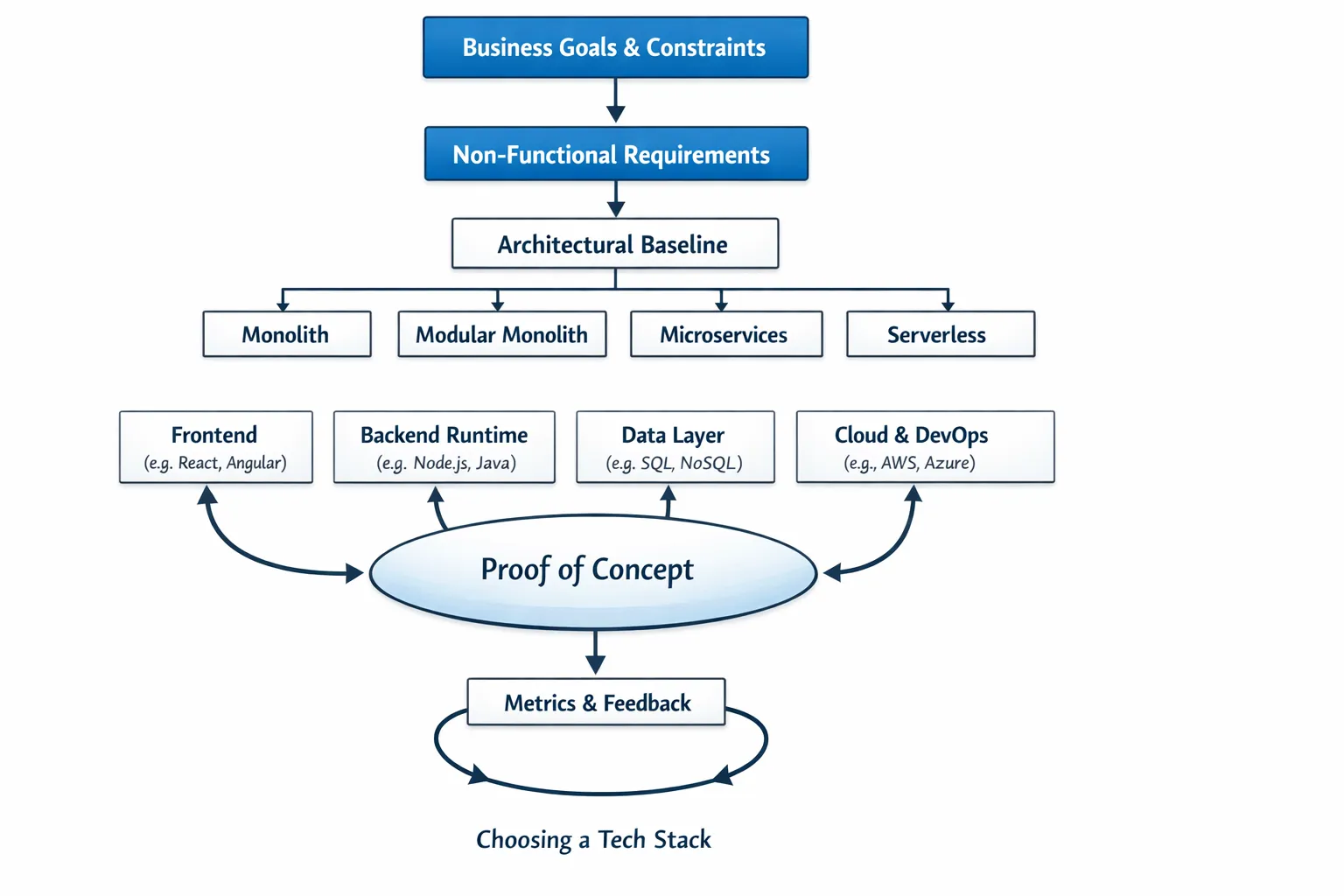
Start with outcomes, not tools
Before evaluating frameworks, make three decisions that anchor every other choice.
Clarify business goals and constraints
- What must the product achieve in the next 6 to 12 months, and what is non negotiable for year two
- What are your budget, hiring market, and regulatory constraints
- Where will performance, uptime, or security be scrutinized
Define non functional requirements
- Scalability expectations, peak load, data growth, latency targets
- Reliability targets such as SLOs, RTO and RPO
- Compliance needs such as SOC 2, HIPAA, PCI, GDPR
Choose an architectural baseline
Pick the simplest architecture that meets your next two horizons of growth.
| Style | When it fits | Benefits | Risks |
|---|---|---|---|
| Monolith | Early stage products with one team, straightforward domain | Fast to ship, easy to reason about | Can become tangled if modularity is ignored |
| Modular monolith | Most SaaS and enterprise apps with multiple domains | Clear boundaries, single deployable | Requires discipline in module boundaries |
| Microservices | Independent domains, multiple teams, need for independent scaling | Team autonomy, selective scalability | Higher ops complexity, distributed transactions |
| Serverless first | Spiky workloads, event driven apps, low ops team | Pay per use, scales automatically | Cold starts, provider coupling, testing complexity |
A modular monolith is the default for many in 2025 because it balances speed and maintainability, a view echoed by industry guidance like the Thoughtworks Technology Radar.
Make your selection measurable with a scorecard
Use a weighted scorecard to compare options objectively. Keep it short and transparent.
| Criterion | Why it matters | Suggested weight |
|---|---|---|
| Team familiarity and hiring pool | Ramp time and recruiting risk dominate early delivery | 25 |
| Maintainability and maturity | Documentation, stability, upgrade path | 15 |
| Ecosystem and community | Libraries, tooling, active contributors | 10 |
| Performance for your use case | Throughput, latency, memory footprint | 10 |
| Scalability and operability | Horizontal scale, observability, deployment model | 10 |
| Security posture | Supply chain, patches, hardening guidance | 10 |
| Cost of ownership | Infra plus people costs to operate | 10 |
| Compliance and governance | Meets auditability expectations | 5 |
| Interoperability and portability | Avoids hard vendor lock in | 5 |
Score candidates on a 1 to 5 scale, multiply by the weight, add them up. Socialize the scorecard with stakeholders so tradeoffs are explicit.
Two sources can help you ground assumptions about maturity and hiring market availability.
- The Stack Overflow 2024 Developer Survey shows JavaScript and TypeScript remain among the most used languages, with strong ecosystems and hiring pools.
- The DB Eng ines Ranking consistently places PostgreSQL at or near the top, reflecting broad adoption and tooling support.
Frontend choices: optimize for delivery and performance budgets
Pick the rendering strategy first, then the framework.
Rendering strategy
- Server rendered or static first, when SEO matters, initial load must be fast, or content is public and cacheable.
- Client heavy SPA, when the app is a complex, authenticated product with rich state and low SEO needs.
- Islands or partial hydration, when you need the SEO of SSR with interactive components without shipping a heavy client bundle.
Frameworks that are safe bets in 2025
- React with Next.js, versatile for SSR, SSG, and hybrid routes. Huge ecosystem and hiring pool.
- Vue with Nuxt, approachable with strong SSR story and growing ecosystem.
- Angular, opinionated with built in patterns, often preferred in enterprises.
- SvelteKit, lean runtime and great DX for smaller teams aiming for performance.
For mobile, React Native and Flutter remain pragmatic cross platform options when a shared codebase is important. For platform specific experiences or advanced device integrations, Swift and Kotlin are still the gold standard.
Backend runtime: match runtime strengths to your workloads
- TypeScript on Node.js or runtimes like Bun, great for web backends, APIs, and developer velocity with one language across the stack.
- Java or Kotlin with Spring Boot, enterprise grade maturity, a deep talent pool, strong observability and security patterns.
- .NET with C#, excellent for Windows heavy environments and enterprises that standardize on Azure.
- Go, small memory footprint, easy concurrency, strong for network services and containers.
- Python with FastAPI or Django, ideal for data heavy workflows, ML adjacent services, or internal tools.
- Rust, when you need performance and safety in systems level services, sometimes as a complement to a higher level stack.
If your team is mixed, favor a primary runtime for most services and allow exceptions only when a clear capability gap exists.
Data layer: choose boring for your source of truth
Relational databases still power most line of business systems. PostgreSQL is a strong default for OLTP, with robust extensions, indexing options, and a large community. Rankings such as DB Eng ines reflect its sustained popularity across industries.
Guidelines for common data needs:
- Primary store, PostgreSQL for transactional workloads. MySQL is also solid, especially where legacy expertise exists.
- Analytics and reporting, a separate warehouse like BigQuery, Snowflake, or Redshift, or an open source columnar store such as ClickHouse for fast aggregates.
- Search and logs, OpenSearch or Elasticsearch for full text and log analytics.
- Caching, Redis for hot keys and rate limiting.
- Messaging and streaming, Kafka for high throughput streams, RabbitMQ for work queues and simple pub sub.
Avoid premature polyglot persistence. Start with one primary database and add specialized stores only when a clear, measured need emerges.
Cloud and DevOps: keep operations simple
- Containers, use Docker for packaging. Orchestrate with Kubernetes when you have multiple independent services and need autoscaling and self healing. Otherwise, start with managed container services to reduce toil.
- Serverless, use Functions as a Service for spiky or event driven workloads with light state, and managed databases to reduce ops overhead.
- IaC, standardize on Terraform or a cloud native equivalent for repeatable environments.
- CI and CD, GitHub Actions or GitLab CI are reliable defaults. Aim for trunk based development and fast pipelines.
- Observability, standardize on OpenTelemetry for traces, metrics, and logs, then export to your APM of choice. Learn more at OpenTelemetry.io.
Security and compliance from day one
- Follow the OWASP Top 10 for baseline application risks and the OWASP API Security Top 10 for APIs.
- Automate dependency scanning, SAST, and container image scanning in CI.
- Centralize secrets management and rotate keys regularly.
- Generate SBOMs and track components to prepare for audits.
Security posture is part of your stack choice. Favor ecosystems with frequent patching and clear hardening guidance.
2025 shifts to watch, without betting the farm
- Edge and regional compute, frameworks and platforms that support running close to users reduce latency. Favor frameworks that can render on the edge, but measure the ops tradeoffs.
- WebAssembly and Rust in the backend, growing in performance critical paths and plugin models. Consider them where they tackle specific bottlenecks.
- AI assisted features, plan for model integrations via APIs and vector enhanced search, but keep user privacy, cost predictability, and observability front of mind.
Use these as incremental enhancements, not reasons to overhaul your baseline stack.
Example stacks you can justify with the scorecard
| Scenario | Architecture | Frontend | Backend | Data layer | Infra and ops |
|---|---|---|---|---|---|
| B2B SaaS MVP | Modular monolith | Next.js, TypeScript | Node.js, TypeScript with a mature web framework | PostgreSQL primary, Redis cache | Containerized, managed container service, GitHub Actions, OpenTelemetry |
| Enterprise platform | Modular monolith evolving to services | React or Angular | Java or Kotlin with Spring Boot | PostgreSQL, Kafka for async events, Elasticsearch for search | Kubernetes, Terraform, GitLab CI, centralized observability |
| Real time data product | Event driven microservices | Lightweight SPA or SvelteKit | Go services for ingestion, Python for analytics jobs | Kafka streams, ClickHouse for analytics, Redis for fast reads | Kubernetes or serverless for ingestion, IaC, autoscaling |
| Mobile first consumer app | API plus edge caching | React Native or Flutter app, SSR website for marketing | Node.js or .NET for APIs | PostgreSQL, object storage for media, CDN edge caching | Serverless APIs plus managed DB, CI for mobile builds |
Treat these as starting points. Re score with your weights before committing.
Run a thin vertical slice to de risk choices
Build a narrow, end to end slice that mirrors a real user journey and measures the hard parts.
- Implement one critical user flow with the proposed stack, including auth, data writes, caching, and observability.
- Run load tests that mimic expected traffic and data growth.
- Validate local dev experience, test execution time, and deploy time.
- Compare measured results against your non functional requirements and scorecard.
If it misses targets or the developer experience is poor, adjust now. It is cheaper than refactoring at scale later.
Red flags that signal stack trouble
- Picking a tool because it is new or popular without a measurable advantage for your use case.
- Excessive microservices before product market fit or before you have strong platform engineering.
- Multiple languages and runtimes for similar services that fragment expertise and tooling.
- No upgrade path or long term maintenance plan for key dependencies.
- Ignoring observability until production incidents force it.
Quick checklist before you finalize
- The stack aligns to business goals, SLOs, and compliance needs.
- You can hire and onboard engineers into it within your timeline.
- There is a clear migration or upgrade story for the next two years.
- You have observability, security scanning, and CI in place from the first sprint.
- A thin vertical slice has met baseline performance and reliability targets.
How Wolf Tech can help
Wolf Tech has shipped and scaled products across modern tech stacks for more than 18 years. Whether you need a second opinion on your scorecard, a rapid proof of concept, or help hardening your CI, security, and infrastructure, our team brings full stack development, code quality consulting, legacy optimization, and cloud expertise to your decision. Start a conversation at Wolf Tech to de risk your stack choices and accelerate delivery.