
Infrastructure Automation: From Scripts to IaC


Infrastructure automation used to mean a folder of shell scripts, a few README files, and someone on the team who “just knows” how to bring environments back from the dead. That approach can work, until it doesn’t. As systems grow across multiple cloud accounts, regions, environments, and compliance constraints, manual steps and one-off scripts become a reliability and security liability.
The modern answer is not “more scripts.” It’s a progression toward Infrastructure as Code (IaC) and related practices (policy as code, GitOps, automated testing) that make infrastructure reproducible, reviewable, and operable at scale.
What “infrastructure automation” actually covers
Infrastructure automation is broader than provisioning servers. It includes any repeatable, machine-driven process that creates, changes, validates, or repairs infrastructure and its operational configuration.
Examples include:
- Provisioning cloud resources (networks, clusters, databases, queues)
- Configuring workloads (runtime settings, system packages, service configs)
- Deploying changes safely (pipelines, canaries, rollbacks)
- Enforcing security and compliance controls (guardrails, policies)
- Detecting and correcting drift (the real world diverging from intended state)
If you want a crisp baseline definition to align stakeholders, this glossary entry on automation (definition and examples) is a useful reference for framing the concept beyond just DevOps tooling.
The evolution: from scripts to IaC (and why it matters)
Teams usually arrive at IaC after living through the pain of script-based operations. Understanding the trade-offs helps you modernize without turning it into a religious debate.
Phase 1: scripts (fast to start, hard to scale)
What it looks like: bash scripts, PowerShell, ad-hoc SSH, cloud CLI snippets, “runbook-driven” operations.
Why teams like it:
- Low barrier to entry
- Quick wins for repetitive tasks
- Works well for small systems or temporary environments
Where it breaks down:
- Hidden state: scripts often assume current reality (what exists, what is named, what credentials work)
- Non-idempotent changes: running twice may not produce the same outcome
- Limited reviewability: diffs are unclear (what changed, and why)
- Reliance on tribal knowledge: operational quality depends on specific people
Scripts are not “bad.” They are just rarely enough as the system becomes business-critical.
Phase 2: configuration management and templating (repeatability for hosts)
What it looks like: Ansible, Chef, Puppet, Salt, plus templating systems and image baking (for example, Packer).
This phase improves consistency for server configuration and application runtime dependencies. It often pairs with “golden images” to reduce bootstrapping time and configuration drift.
Common limitation: configuration management tools are excellent at converging machine state, but they are not always the best fit for provisioning cloud primitives (VPCs, IAM policies, managed databases) where declarative resource graphs and lifecycle controls matter.
Phase 3: Infrastructure as Code (declarative infrastructure)
What it looks like: Terraform/OpenTofu, AWS CloudFormation, Azure Bicep, Pulumi, Kubernetes manifests, and related tooling.
IaC shifts the mental model from “run steps” to “describe desired state.” The tool computes what needs to change and applies it in a predictable way.
Key ideas that make IaC different from scripts:
- Declarative intent: you define what should exist, not how to click through it
- Plan and diff: you can preview changes before applying
- Idempotency: applying the same config repeatedly should converge to the same result
- Dependency graph: resources are created/changed in a controlled order
Phase 4: GitOps and policy as code (operating at scale)
Once infrastructure is code, the next bottleneck becomes governance and safe change delivery.
Two practices commonly extend IaC:
- Policy as code: guardrails that prevent unsafe or non-compliant changes (for example, blocking public storage buckets or overly permissive IAM)
- GitOps: Git becomes the source of truth, and automated agents reconcile the running environment to match what’s approved in version control
IaC is the foundation, but governance and operations are what make it sustainable.
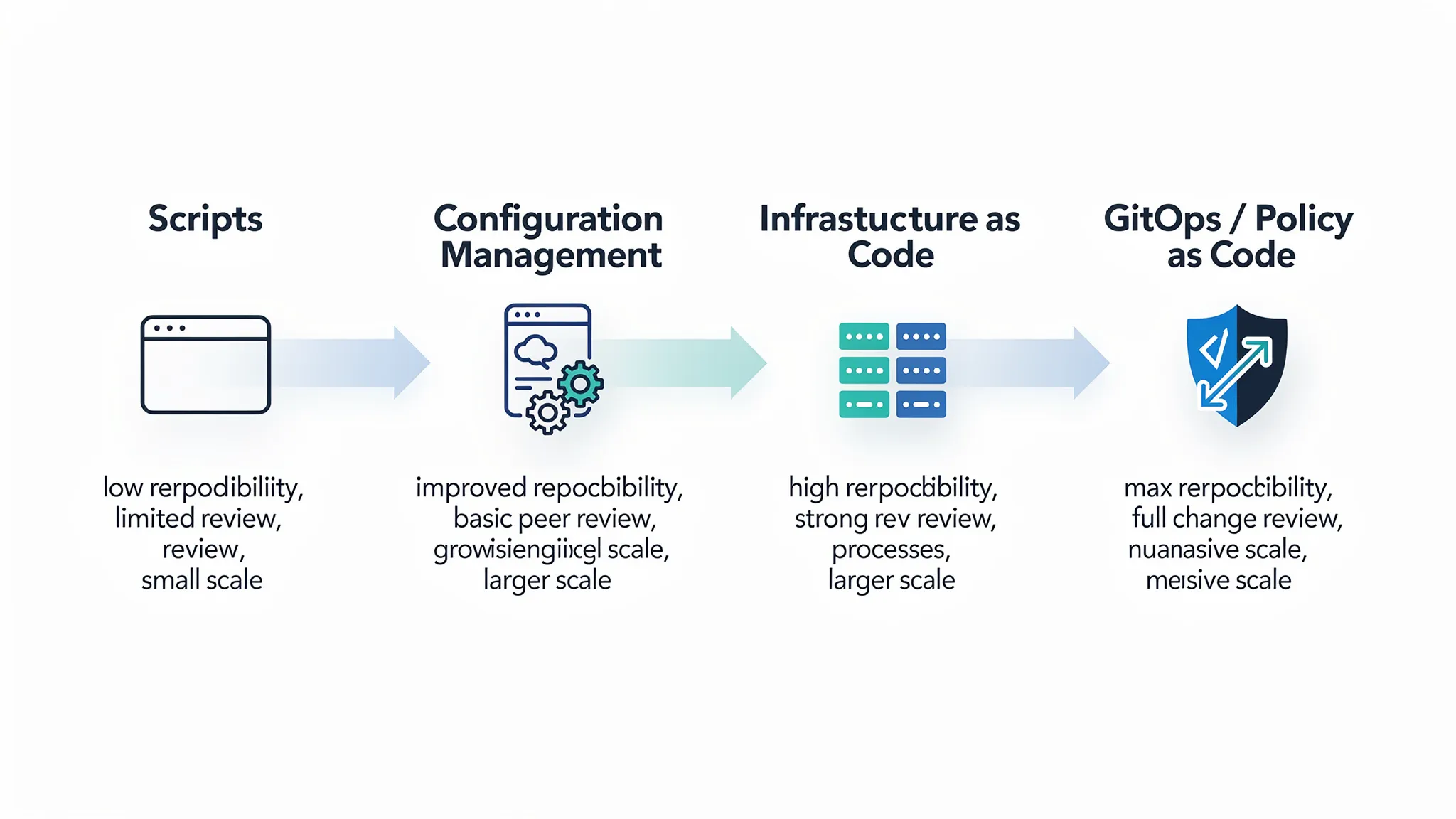
Scripts vs IaC: a practical comparison
Both have a place. The trick is using each where it fits.
| Approach | Best for | Strengths | Typical failure modes |
|---|---|---|---|
| Scripts (CLI, bash, PowerShell) | One-off tasks, migrations, emergency fixes, glue logic | Fast to write, easy to customize | Non-idempotent changes, unclear diffs, fragile assumptions, hard to audit |
| Config management (Ansible/Chef/Puppet) | Host configuration, package/service convergence, standard baselines | Strong convergence model, repeatable machine setup | Can sprawl into “do everything,” weaker lifecycle management for cloud resources |
| IaC (Terraform/CloudFormation/Bicep/Pulumi) | Cloud resource lifecycle, environments, reusable infrastructure modules | Plan/apply, dependency graph, reviewable changes | State/drift problems, large blast radius if not modularized |
| GitOps + policy as code | Multi-team governance, compliance at speed, continuous reconciliation | Strong auditability, automated enforcement | Too rigid if governance is misdesigned, noisy policies, slow approvals |
What “good” IaC looks like in real teams
Infrastructure automation fails most often because teams copy patterns without building the supporting engineering discipline. A robust IaC practice tends to share these characteristics.
1) Version control is the source of truth
Every change goes through the same path:
- Pull request
- Review (security and platform concerns included)
- Automated checks
- Controlled promotion to environments
This is less about process theater and more about creating an auditable, repeatable workflow.
2) Small blast radius by design
If “apply” can accidentally take down production, teams will avoid automation and revert to manual changes.
Practical techniques to reduce blast radius:
- Modularize by domain boundaries (networking, IAM, data, runtime platform)
- Separate state for independent components
- Use environment isolation (separate accounts/subscriptions/projects where appropriate)
- Prefer additive changes and safe migrations over destructive replacements
3) Testing exists, even if it’s lightweight
Infrastructure changes deserve testing, but it does not need to be perfect on day one.
Examples of high-leverage checks:
- Formatting and linting
- Policy checks (security baselines)
- “Plan” in CI to detect unexpected diffs
- Smoke tests after apply (connectivity, health checks, permissions)
4) Secrets and identity are not an afterthought
Most production incidents in “automated infrastructure” are not caused by tools, they are caused by bad credential and permission practices.
Baseline expectations:
- No long-lived secrets in repositories
- Clear separation of human vs workload identities
- Least-privilege IAM with reviewable policy changes
- Rotations and incident-ready revocation procedures
5) Drift is measured and handled
Drift is inevitable in the real world (hotfixes, console changes, incident actions). Mature teams detect it and have a response policy.
Common options include:
- Alert on drift and force changes back through PRs
- Allow temporary drift with explicit expiry (documented exceptions)
- Automatically reconcile drift for specific categories of resources
The missing piece: state management (and why IaC projects fail)
If you adopt Terraform or similar tools, state becomes central. State answers: “What does the tool believe exists?”
When state management is weak, you see:
- Conflicts between teams (two pipelines trying to manage the same resources)
- Surprise deletes or replacements
- Inability to safely import existing infrastructure
- Paralyzing fear of running
apply
Practical guidance that tends to work:
- Use remote, locked state (not local files)
- Split state by component and environment
- Control who can apply changes, and how
- Treat state moves and imports as production-grade operations with peer review
A migration path: from scripts to IaC without stopping delivery
Most organizations cannot freeze delivery for a “big IaC rewrite.” The safer approach is incremental.
Start with an inventory and clear boundaries
Before choosing tools, map:
- What you have (accounts, networks, clusters, databases)
- Who owns what (teams, domains)
- What changes most frequently (the best first targets for automation)
- What is highest risk (where guardrails matter most)
This is also where you decide whether you need a platform team, shared modules, or a simpler model.
Build a thin, working slice
A thin slice is a small end-to-end implementation that proves the workflow, not just the syntax.
A good thin slice typically includes:
- One component (for example, a service’s infrastructure or a shared environment capability)
- One environment (dev first)
- CI that runs checks and produces a plan
- A controlled apply step
- Minimal documentation so another engineer can run it
Once that slice works, scaling becomes engineering, not guessing.
Adopt “strangler” tactics for infrastructure
Just like application modernization, infrastructure modernization benefits from strangler patterns:
- Import existing resources gradually instead of rebuilding everything
- Automate new resources first, then backfill existing ones
- Replace manual processes with pipelines one workflow at a time
The goal is steady risk reduction while delivery continues.
Add governance when it starts hurting
Governance too early can slow teams down. Governance too late leads to cloud sprawl and audit failures.
A practical trigger: when multiple teams are shipping changes weekly, you want policy checks, review standards, and a repeatable promotion model.
Tool selection: criteria that matter more than brand names
Most IaC tools are “good enough.” The differentiator is fit to your operating model.
Here are decision criteria that consistently matter:
| Criterion | What to look for | Why it matters |
|---|---|---|
| Cloud coverage | First-class support for your cloud resources | Gaps force brittle scripts and manual work |
| Team workflow | Strong diff/plan, review flows, and environment promotion | Keeps changes auditable and safe |
| State and drift model | Clear state handling and drift detection | Prevents “apply fear” and incidents |
| Policy integration | Works with policy-as-code tooling and CI | Enables guardrails without bureaucracy |
| Modularity and reuse | Modules/components that match your org boundaries | Reduces duplication and inconsistencies |
| Skill alignment | Fits your team’s language and debugging preferences | Adoption fails when nobody can maintain it |
Common IaC pitfalls (and how to avoid them)
“One repo to rule them all” that nobody can change
A monolithic infrastructure repo can create a single choke point.
Instead, aim for:
- Clear ownership boundaries
- Reusable shared modules (with versioning)
- Separate state for independent components
Automating without operability
Provisioning is not the finish line. If your automation creates infrastructure that cannot be observed, upgraded, or recovered, you just automated future pain.
Ensure your baseline includes:
- Logging and metrics for key services
- Backup/restore or recovery procedures where needed
- Clear SLO-impacting dependencies (databases, queues, identity)
Over-permissioned automation
Automation often runs with powerful credentials. If those credentials are too broad, you have created a high-impact security risk.
A better approach:
- Least privilege for pipelines
- Scoped roles per environment
- Manual approval gates only for truly high-risk changes
Measuring success: what to track
Infrastructure automation is only “done” when it improves outcomes. Metrics help you avoid building a beautiful system that doesn’t move the business.
A practical scorecard:
- Provisioning lead time: request to ready environment/resource
- Change failure rate: how often infra changes cause incidents or rollbacks
- MTTR contribution: whether automation reduces recovery time
- Drift rate: how often reality diverges from code
- Cost variance: unexpected cost spikes after infra changes
If you already track delivery and reliability metrics, add the infrastructure lens to the same dashboard. The goal is one story, not separate reporting.
Frequently Asked Questions
Is Infrastructure as Code only for cloud infrastructure? IaC is most commonly used for cloud resources, but the idea applies anywhere you can define desired state (on-prem virtualization, Kubernetes, networking, even some SaaS configurations). The value comes from versioning, reviewability, and repeatability, not from the cloud itself.
Do we still need scripts after adopting IaC? Yes. Scripts remain useful for glue tasks, data migrations, and incident response. The difference is that scripts should stop being the primary mechanism for provisioning and governing long-lived infrastructure.
What’s the difference between IaC and GitOps? IaC is how you define and manage infrastructure as code. GitOps is an operating model where Git is the source of truth and automated agents reconcile environments to match approved changes. You can use IaC without GitOps, but GitOps often makes IaC safer at scale.
How do we prevent IaC from becoming a bottleneck for teams? Reduce blast radius (modular design and separate state), create reusable modules, automate checks in CI, and define clear ownership. The goal is self-service with guardrails, not a central team that must approve every small change.
What are the first signs we’ve outgrown scripts? Repeated environment inconsistencies, frequent “works on staging” issues, long onboarding times, risky manual changes during incidents, and difficulty passing audits are common signals that scripts are no longer sufficient.
Want to move from ad-hoc automation to scalable IaC?
Wolf-Tech helps teams design and implement infrastructure automation that supports real delivery speed and reliability, not just a tool rollout. If you’re modernizing legacy environments, tightening governance, or building a repeatable foundation for growth, we can support with tech stack strategy, cloud and DevOps expertise, and hands-on full-stack delivery.
Explore Wolf-Tech at wolf-tech.io or start with a practical roadmap-focused read: Application Development Roadmap for Growing Teams.