
Application Development Roadmap for Growing Teams


Shipping fast is not the same as scaling well. As headcount grows, coordination cost rises, quality slips at the edges, and the release train starts to wobble. A clear application development roadmap gives growing teams a shared operating model, so speed compounds instead of collapsing under complexity.
This guide lays out a pragmatic, 12‑month roadmap for engineering leaders who are moving from a handful of developers to several cross‑functional teams. It focuses on outcomes, guardrails, and the minimum set of practices that unlock sustainable velocity.
Why growing teams need a roadmap
Without a plan, growth introduces hidden queues and friction. Onboarding slows because every repo is different, releases bunch up because environments are snowflakes, and urgent refactors steal time from features. A roadmap aligns decisions across architecture, delivery, security, and team design, so each increment reduces future toil.
The payoff is measurable. Teams that standardize on small batch changes, trunk‑based development, and continuous delivery practices consistently improve lead time, deployment frequency, change failure rate, and time to restore service. These are the widely used DORA metrics, documented by industry research at dora.dev.
Guiding principles for sustainable speed
- Start from business outcomes, then choose technology and process to serve them.
- Prefer simple architecture until you feel pain, then modularize along real domain seams.
- Default to small, reversible changes, trunk‑based development, and high‑signal reviews.
- Automate what hurts, especially tests, builds, environments, and security checks.
- Security and reliability are features, integrate them into everyday work.
- Measure what matters, share dashboards, and fix the system, not people.
- Optimize developer experience, because time to first commit and time to safe release drive throughput.
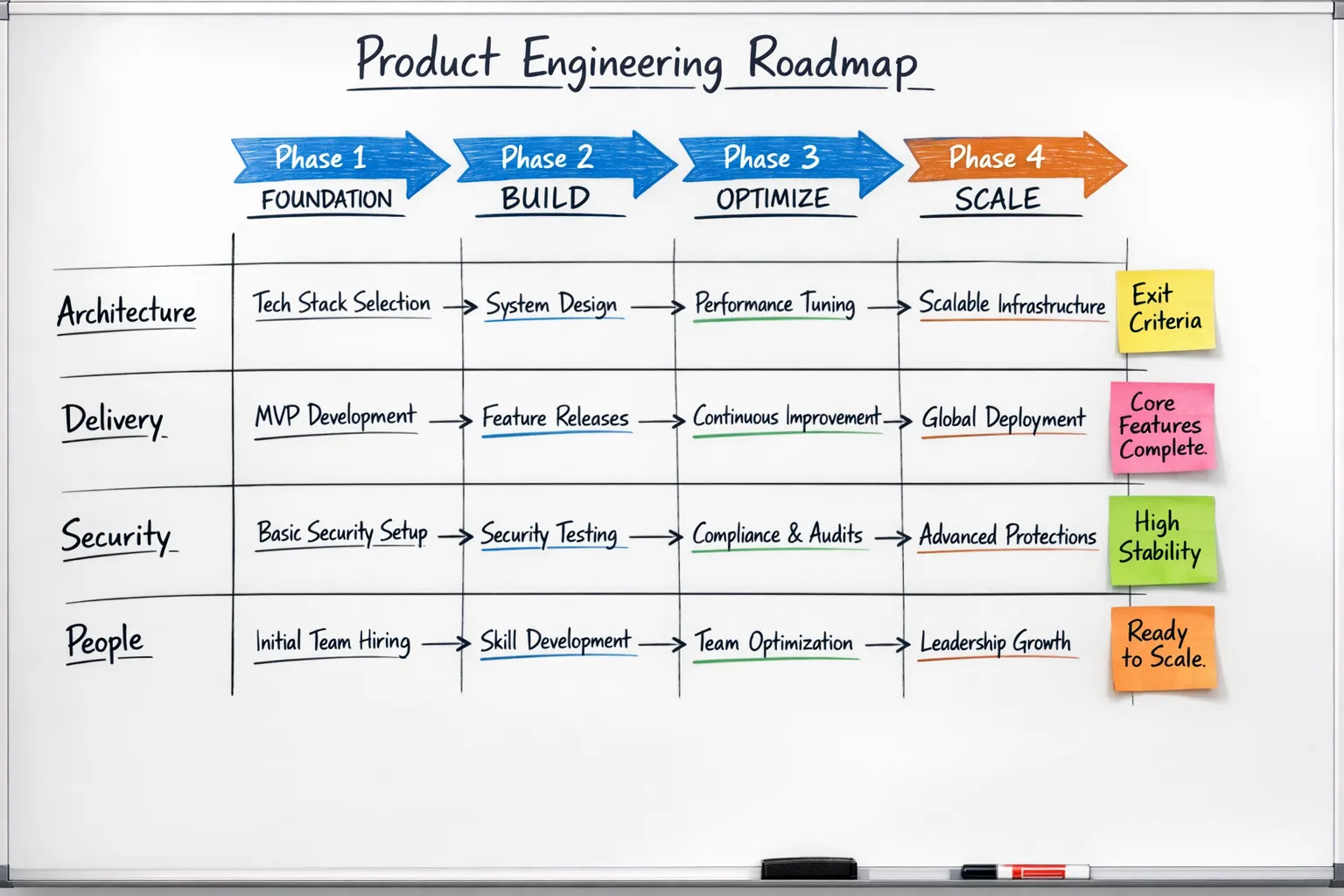
A 12‑month application development roadmap
This roadmap is structured in phases. Timelines are guidelines. If you already have parts in place, apply the exit criteria and move forward.
Phase 1, Foundation, 0 to 90 days
Lay the baseline so developers can ship confidently and consistently.
Architecture and code
- Choose an architectural baseline that minimizes coordination, often a modular monolith with clear domain boundaries and interfaces.
- Establish a single repo or a limited set, with consistent project scaffolds, build scripts, and naming.
- Introduce Architecture Decision Records so trade‑offs are documented as you grow.
Delivery and quality
- Adopt trunk‑based development with short‑lived branches, require CI green before merge, and keep pull requests small.
- Stand up CI for build, lint, unit tests, and dependency scanning. Treat failing pipelines as stop signs.
- Define a practical test pyramid. Aim for fast unit and component tests, a handful of targeted end‑to‑end checks.
Environments and operations
- Codify infrastructure and environments. At minimum, have development, staging, and production created with IaC.
- Add baseline observability. Centralized logs, request metrics, and error monitoring with alerting on user‑visible failures.
Security and compliance
- Implement secret management and prevent secrets from entering source control.
- Add software composition analysis and start generating SBOMs. Align your security stories to OWASP ASVS levels that fit your risk profile.
People and ways of working
- Define Definition of Ready and Definition of Done, code review standards, and incident handoffs.
- Create a lightweight onboarding playbook and a golden project template.
Exit criteria
- New engineers can go from laptop to first merged, deployed change in under one day.
- Every change runs through a green CI pipeline and is traceable to a ticket or ADR.
- Staging and production are built from code and are environment‑parity compatible.
- Secrets are managed, dependencies scanned, and basic monitoring alerts work.
Phase 2, Acceleration, 90 to 180 days
Reduce batch size, increase feedback, and remove handoffs.
Architecture and code
- Formalize domain boundaries. Introduce internal modules or packages with published interfaces. Use contract tests to keep boundaries honest.
- Apply performance budgets and profiling to the hottest paths. Build a simple caching strategy.
Delivery and quality
- Introduce ephemeral preview environments per pull request so reviewers see real behavior.
- Move to continuous delivery. Automate deployment to staging on merge, then a controlled, low‑risk promotion to production behind feature flags.
- Enrich test suites. Add integration and contract tests for APIs and key workflows. Start synthetic monitoring.
Operations and reliability
- Define service level objectives for user‑visible latency, error rate, and availability. Tie alerts to error budget burn, not raw CPU.
- Add blue‑green or canary deploys for core services, with automated rollback when health checks fail.
Security and supply chain
- Expand checks to include static analysis, IaC scanning, and container image scanning.
- Establish a secure pipeline aligned to NIST SP 800-218 SSDF. Require code owners and mandatory reviews for sensitive areas.
Metrics and product feedback
- Instrument DORA metrics and publish them weekly. Pair them with a few product metrics like activation and task success rate.
Exit criteria
- Every merged change has a preview, a green test suite, and deploys to staging automatically.
- Production releases are routine and low drama. Rollbacks are push‑button and fast.
- SLOs exist for key flows, with dashboards and on‑call runbooks.
Phase 3, Scale, 6 to 12 months
Prepare for multi‑team delivery and higher stakes.
Architecture and platform
- Introduce a small platform capability that curates a paved path for teams. Provide templates, starter repos, and a simple internal developer portal that documents golden paths.
- Break out independently scaling or fast‑changing domains only when justified by data. Keep shared data models and contracts stable.
- Use eventing or a reliable outbox for cross‑domain communication when needed. Keep operational complexity proportional to value.
Reliability and cost
- Manage capacity proactively. Adopt autoscaling, rate limiting, and graceful degradation. Precompute or cache expensive operations.
- Add cost observability by team and product slice. Track unit costs like cost per thousand requests or per active user.
Security and compliance
- Raise the bar on supply chain integrity. Add provenance and signed artifacts. Align builds with the SLSA framework.
- Conduct threat modeling on critical flows. Expand security tests in CI and add runtime protections where appropriate.
People and operating model
- Move to a Team Topologies inspired model. Stream‑aligned teams own slices of the product, an enabling team accelerates adoption of practices, and a thin platform capability removes friction.
- Publish an engineering handbook and tech radar. Teach how to use the golden path, not just what it is.
Exit criteria
- Teams can create a new service or app on the paved path in under one hour, with CI/CD, observability, security scans, and templates prewired.
- Most work happens on stream‑aligned teams that can deliver independently with minimal coordination.
- The platform team operates as a product, with a backlog, SLAs, and adoption metrics.
Phase 4, Multi‑team operating model, beyond 12 months
At this point the roadmap becomes cyclical. You evolve the platform, prune complexity, and grow leadership capacity. Focus areas include:
- Cross‑team API governance and versioning, with clear deprecation policies.
- Objective decision gates for introducing new services or technologies.
- Regular architecture fitness functions that test non‑functional requirements.
- Security posture reviews mapped to OWASP ASVS and pipeline controls mapped to NIST SSDF.
- Capacity planning, incident analysis, and reliability game days. Treat incidents as opportunities to improve socio‑technical systems.
Phase exit criteria at a glance
| Phase | Primary goals | Key exit criteria |
|---|---|---|
| Foundation | Create a consistent, safe baseline for shipping | Onboarding under 1 day, CI green is mandatory, environments codified, basic monitoring and secret management in place |
| Acceleration | Increase feedback and reduce batch size | Preview environments on PRs, CD to staging, flags for safe release, SLOs defined, weekly DORA visibility |
| Scale | Pave golden paths and split where it pays | IDP or portal with templates, cost and reliability guardrails, limited and justified service boundaries, signed artifacts |
| Multi‑team | Govern without slowing teams | API governance, platform as a product, regular fitness checks, evolving security and reliability practices |
Architecture decisions that age well
- Prefer a modular monolith to start, with clear domain boundaries, dependency rules, and build isolation. Move a boundary out only when it unlocks clear flow or scaling benefits.
- Keep contracts stable. Version APIs, support at least one deprecated version for a set period, and publish change logs.
- Treat the database as part of the system’s interface. Use zero‑downtime migration patterns and an outbox for reliable events.
- Bake in operational concerns early. Health checks, idempotency, backpressure, and predictable timeouts prevent cascading failures.
- Use 12‑factor principles for configuration, stateless services, and parity across dev and prod. See The Twelve‑Factor App.
For frontend web apps and BFFs, align rendering and caching with product needs. If your team is exploring modern React runtimes and server rendering strategies, our guide on Next.js best practices dives deeper.
Delivery and DevEx guardrails
Small, consistent practices create compounding leverage.
- Keep pull requests small and review time short. Encourage pairing or mobbing for complex changes.
- Automate preview environments for visual and functional review. It reduces rework.
- Cache builds and tests to keep feedback fast. Optimize the longest 10 percent of pipelines first.
- Standardize lint, format, type checking, and commit conventions. Enforce in CI to avoid style debates.
- Document run scripts, environment variables, and local dev setup in the repo. Aim for a one‑command start.
When selecting or refining your stack, align it to non‑functional requirements and operating realities. If you need a structured way to do this, see our guide on how to choose the right tech stack in 2025.
Testing and reliability, right‑sized
- Focus on fast unit and component tests, then add a thin layer of integration and a few end‑to‑end flows.
- Invest in contract tests at domain and API boundaries. They prevent accidental coupling as teams multiply.
- Add synthetic checks for critical journeys and use them as canary signals during deploys.
- Define SLOs that reflect user experience, not server internals. Tie alerts to error budget burn so teams can prioritize reliability work.
For modernization scenarios, choose patterns that avoid disruption. Our playbook on modernizing legacy systems without disrupting business covers Strangler Fig, feature flags, and rollout strategies.
Security by design for growing teams
Security posture should improve as a natural outcome of delivery practices.
- Integrate secret scanning, SAST, SCA, IaC and container scanning into CI. Fail builds for critical issues and track time to remediate.
- Generate SBOMs for each release and store them alongside artifacts. This speeds response to upstream vulnerabilities.
- Apply least privilege for services and humans. Centralize identity and access, and rotate credentials automatically.
- Threat model high‑risk flows and create targeted abuse cases and tests. Align your verification levels to OWASP ASVS.
- Align pipeline controls and secure development practices to NIST SSDF. For software supply chain hardening, review the SLSA levels and adopt what fits your context.
Metrics that steer, not punish
Choose a small, balanced set of outcome and health measures and make them visible.
- Delivery health. Lead time for changes, deployment frequency, change failure rate, and mean time to restore service. These are the DORA metrics.
- Product outcomes. Activation, funnel conversion, task success, and retention for your key journeys.
- Reliability. SLOs and error budget burn, plus incident frequency and time to detect.
- Developer experience. Time to first commit, time to first deploy, CI duration, and flaky test rate.
- Financials. Unit cost by key dimension, for example per 1,000 requests or per active user, and total cloud spend against a budget.
Publish these in a shared dashboard. Review them in weekly engineering forums to keep the conversation focused on improving the system.
Team design that scales with autonomy
Organization design is part of the architecture. As scope grows, evolve toward clear ownership and thin, purposeful platforms.
- Stream‑aligned teams own cohesive slices of the product. They have the skills to design, build, release, and operate their slice.
- An enabling team accelerates adoption of new skills and practices.
- A small platform capability treats the internal developer platform as a product, with docs, SLAs, and a feedback loop.
This model is popularized by Team Topologies. The key is to design for fewer handoffs and faster learning.
A compact checklist to start this quarter
- Write down exit criteria for your next phase and share the plan in an engineering forum.
- Create or refresh the golden path template so new services start productive and secure.
- Instrument DORA metrics and SLOs and put them on a team‑visible dashboard.
- Add ephemeral previews on pull requests and a feature flag system for safe releases.
- Adopt ADRs for architecture trade‑offs and require them for cross‑cutting changes.
If you are just beginning your journey, our primer on web app development can help you scope a high‑leverage MVP and avoid early pitfalls.

How Wolf‑Tech can help
Wolf‑Tech partners with companies to design and execute pragmatic roadmaps like the one above. We bring full‑stack development, cloud and DevOps expertise, code quality and legacy optimization, database and API solutions, and industry‑specific experience. Whether you are codifying your golden path, de‑risking a modernization, or standing up a platform capability, we can help you move faster with confidence.
If you want a tailored application development roadmap for your team, along with hands‑on delivery support and measurable milestones, get in touch at wolf‑tech.io.
Further reading from Wolf‑Tech
- Next.js Best Practices for Scalable Apps
- How to Choose the Right Tech Stack in 2025
- Modernizing Legacy Systems Without Disrupting Business
- Refactoring Legacy Software: From Creaky to Contemporary
References
- DORA metrics and research at dora.dev
- OWASP ASVS
- NIST SP 800-218 SSDF
- SLSA framework
- The Twelve‑Factor App