
Modernizing Legacy Systems Without Disrupting Business


Modernizing mission critical systems while keeping them running is possible, but it requires a plan that treats continuity as a first class requirement. The objective is not just new tech, it is progress without outages, lost orders, or impaired customer experience. This guide lays out the patterns, rollout practices, and human factors that let you modernize legacy systems without disrupting the business.
Start by defining what “no disruption” really means
Before choosing tools or patterns, translate “no disruption” into measurable targets that you can design and verify against.
- SLOs tied to user journeys: for example, checkout p95 latency under 400 ms, 99.9 percent availability during business hours.
- RTO and RPO: the maximum acceptable recovery time and data loss if something goes wrong.
- Blackout windows and peak periods: protect payroll runs, quarter end closes, enrollment seasons, or holiday traffic.
- Error budget policy: clear thresholds that trigger rollback or pause the rollout.
When there is a shared definition of acceptable risk, engineering and business leaders can make informed tradeoffs.
Principles for low risk modernization
- Carve at seams, do not rip and replace. Isolate replaceable capabilities behind interfaces and move them one by one.
- Prefer additive change. Add new endpoints, schemas, and services while keeping older ones intact until traffic fully migrates.
- Make rollback cheap. Every change should have a fast, reversible path.
- Prove safety continuously. Rely on automated tests, shadow traffic, and progressive delivery rather than big bang cutovers.
- Instrument first, change second. Observability is part of the migration plan, not an afterthought.
Architecture patterns that keep the lights on
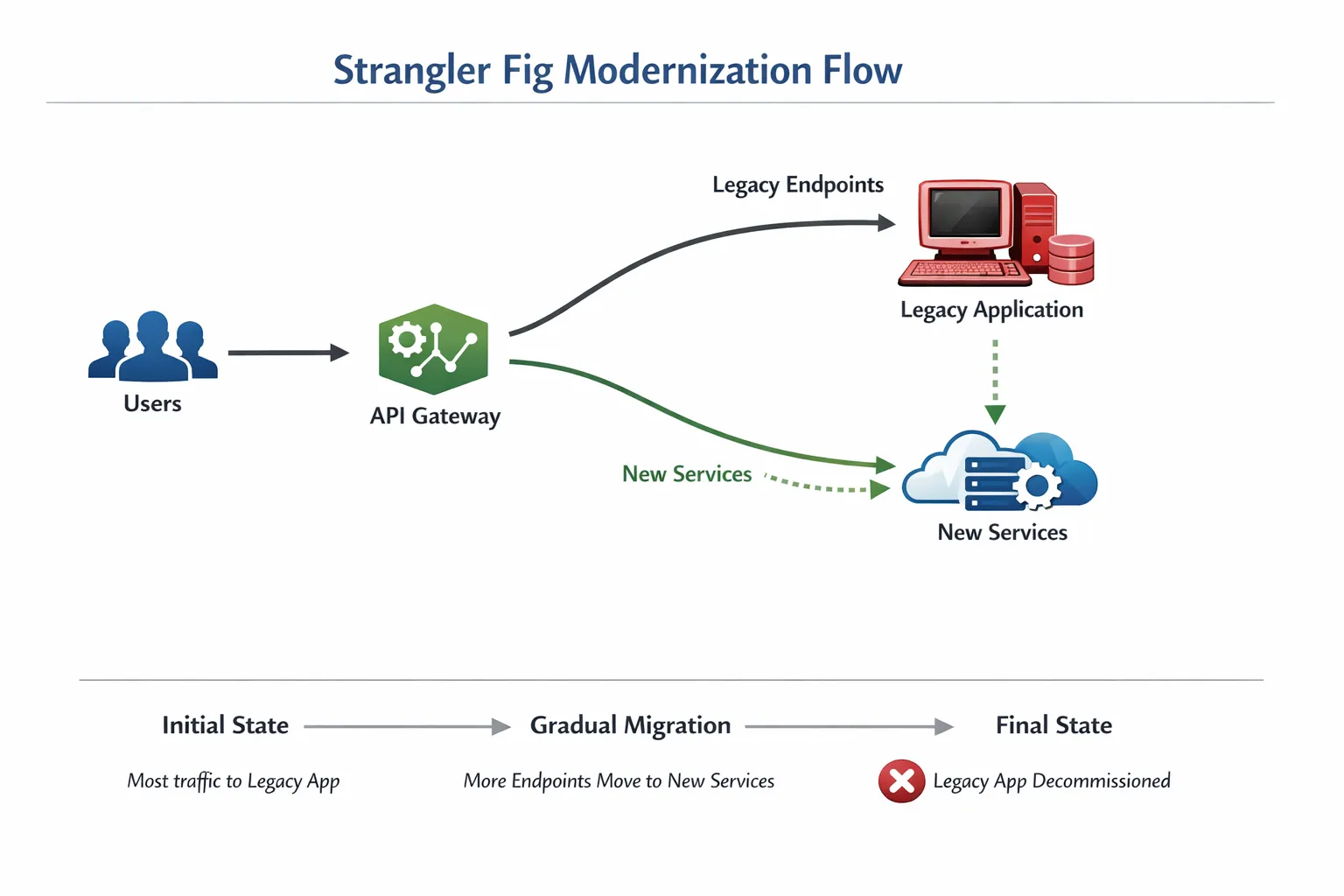
The Strangler Fig pattern
Wrap the legacy application with a façade, route a subset of requests to new services, and incrementally replace functionality. Martin Fowler’s write up on the Strangler Fig pattern remains the reference. In practice, teams often implement the façade with an API gateway or an edge proxy. Start with a narrow, high value slice, then expand routing rules as confidence grows.
Blue green and canary releases
Keep two production ready environments, blue and green, switch traffic between them when you deploy, and maintain instant rollback by flipping back. Fowler also documents Blue Green Deployment. Combine this with canary releases by gradually sending 1 percent, 5 percent, then 25 percent of real traffic to the new version while monitoring service level objectives.
Feature flags and progressive delivery
Feature toggles let you deploy code dark, enable specific features for internal users, and gate rollouts by cohort. ThoughtWorks summarizes best practices for feature toggles. Flags also decouple deployments from releases, which shortens mean time to recovery because you can disable a change without a redeploy.
Consumer driven contract testing
When you split a monolith into services, outages shift from code bugs to interface mismatches. Contract tests ensure both sides of an integration agree on payloads and behavior. Pact is a widely used framework for this. Run contract tests in CI, then enforce that only versions passing the consumer’s contracts reach production.
Shadow traffic and characterization tests
Send a copy of production traffic to the new implementation, compare responses, and reconcile differences before switching real users. Under the hood, use characterization tests to lock in current behavior, including edge cases, so refactors do not change outcomes users rely on.
For deeper tactical advice on refactoring and modernization mechanics, see Wolf Tech’s guides on refactoring legacy software and code modernization techniques.
Data migration without downtime
Applications are replaceable only if their data is, so treat data as its own workstream with its own safety net.
- Start with read replicas. Place a replica or mirror next to the new service to reduce blast radius while you build.
- Bulk backfill, then stream deltas. Migrate historical records in batches during off peak windows, then use change data capture to keep targets in sync. Debezium documentation is a solid starting point for CDC options.
- Use dual writes with idempotency. For a period, write to both old and new stores, deduplicate with idempotent operations and stable message keys.
- Switch reads first. Point read paths to the new store under a flag, then switch writes when confidence is high.
- Validate continuously. Compare row counts, checksums, and business invariants like totals and balances. Sample user journeys and reconcile discrepancies before moving to the next slice.
- Apply parallel change for schemas. Expand, migrate, contract in three steps so producers and consumers remain compatible during the transition.
The operational rollout playbook
Borrow practices from site reliability engineering to make each change boring in production.
- Pre flight: production like staging, synthetic traffic, load tests to the next power of expected peak, and a dry run with the exact release steps.
- Release gates: pass rates for tests and runbooks, green dashboards, error budget remaining, and an explicit go or no go checkpoint.
- During rollout: a staffed channel, owner on point, a live status page, and a rollback procedure tested within the last week. The Google SRE book outlines practical guardrails.
- Aftercare: heightened monitoring for 24 to 72 hours, capture learnings, and retire flags when metrics stabilize.

Governance, security, and compliance do not need to slow you down
- Change advisory lightweight rituals: small, frequent changes with pre agreed guardrails and automated evidence should get fast path approvals.
- Least privilege and secrets hygiene: rotate credentials, isolate blast radius per service, and keep audit trails for every production action.
- Data protection: mask or tokenize sensitive data in lower environments and document lawful bases and retention rules during the migration.
The people side of modernization
Most modernization efforts fail because of change fatigue, not because of technology. Protect your teams the same way you protect your systems.
- Communicate in public: weekly internal notes on what changed, what is next, and how to ask for help.
- Pair and cross train: spread legacy system knowledge beyond a few keepers of history.
- Work at a sustainable pace: use release windows, rotate on call, and avoid long running heroics.
- Support well being: encourage practices that maintain focus and resilience during long transformations.
How Wolf Tech delivers modernization without disruption
With more than 18 years of engineering experience, Wolf Tech partners with you to modernize safely while your business keeps moving.
- Full stack modernization and legacy optimization: we identify seams, build anti corruption layers, and move critical capabilities behind an API gateway.
- Data and integration expertise: we plan and execute CDC based migrations, introduce idempotent messaging, and harden database and API boundaries.
- Cloud and DevOps maturity: we establish blue green or canary release pipelines, feature flagging, and production grade observability.
- Code quality and testing: we add characterization tests and contract tests to make every change verifiable.
- Strategy and delivery: we align the roadmap to outcomes and SLOs, then ship value in short, reversible increments.
If you are evaluating stack choices as part of the journey, our guide on choosing the right tech stack in 2025 can help frame your decisions in business terms.
Quick decision framework
Use this table to choose the right tactic per capability. The best programs combine several of these approaches.
| Approach | What it is | Downtime risk | When to use | Notes |
|---|---|---|---|---|
| Strangler façade + incremental replacement | Route selected endpoints to new services and expand over time | Very low | Customer facing flows and APIs | Requires solid routing and observability |
| UI rewrite over legacy APIs | Replace the frontend, keep existing backend contracts | Low to medium | When UX is the primary pain and APIs are stable | Add contract tests to lock API behavior |
| Re platform (lift and shift) | Move workloads to a new runtime or cloud with minimal code change | Low if well rehearsed | Legacy infra end of life, need elasticity or reliability fast | Pair with autoscaling and managed services |
| Re architect critical service | Redesign a hotspot into a separate, well bounded service | Medium | Performance or reliability issues are localized | Use canary and shadow traffic, isolate data |
| Big bang rewrite | Build a full replacement before cutover | High | Rarely, only for small systems with low coupling | Hard to validate and roll back in time |
A practical 90 day plan to get started
- Weeks 1 to 2, baselining: define SLOs and error budgets, map critical user journeys, identify seams, and set up minimal observability.
- Weeks 3 to 6, first slice: implement a façade, add characterization tests around the target capability, backfill data, and ship the first canary behind a flag.
- Weeks 7 to 10, expand: ramp traffic in stages, add contract tests with upstream or downstream consumers, and switch reads to the new data store.
- Weeks 11 to 12, consolidate: decommission the replaced code path, document learnings, and choose the next slice.
Measure what matters each week: change failure rate, mean time to recovery, p95 latency for the affected journey, error budget burn, and user satisfaction. These are the modernization KPIs that keep the program honest.
Move forward without pausing the business
Modernization without disruption is not a myth, it is an engineering and delivery discipline. Start with clear SLOs, add safety nets before changes, migrate in thin slices, and take care of the people doing the work. If you want a partner that has done this across stacks and industries, Wolf Tech can help you design a zero downtime plan and execute it end to end.
Ready to explore your safest path off legacy constraints? Reach out to Wolf Tech for a modernization readiness conversation, and let us help you build, optimize, and scale with confidence.