
Best Practices der Backend-Entwicklung für Zuverlässigkeit


Zuverlässigkeit gewinnt man selten mit einer einzigen „großen“ Architekturentscheidung. Sie wird durch Dutzende kleiner, wiederholbarer Backend-Entwicklungspraktiken erarbeitet: konsistente Timeouts, defensive Datenbank-Patterns, klare Service-Grenzen, produktionsreife Observability und Incident-Disziplin. Der Nutzen ist direkt: weniger Ausfälle, schnellere Wiederherstellung und eine vorhersehbare Performance, auf die Ihre Kunden vertrauen können.
Dieser Leitfaden konzentriert sich auf Best Practices der Backend-Entwicklung für Zuverlässigkeit, die über Stacks (Monolithen, Microservices, ereignisgesteuerte Systeme) und Cloud-Anbieter hinweg funktionieren. Wenn Sie Engineering leiten oder produktive Services verantworten, behandeln Sie diesen Beitrag als praxisorientiertes Playbook.
Beginnen Sie mit messbaren Zuverlässigkeitsanforderungen
Viele Teams sagen „wir brauchen High Availability“ und liefern dann ein System, das das nicht belegen kann. Zuverlässigkeit wird umsetzbar, wenn sie anhand von Nutzerergebnissen gemessen wird, nicht anhand der Infrastruktur-Uptime.
Eine solide Grundlage ist das SRE-Modell mit:
- SLIs (Service Level Indicators): die Metriken, die das Nutzererlebnis abbilden (zum Beispiel die Erfolgsquote von Checkouts, p95-API-Latenz)
- SLOs (Service Level Objectives): die Zielwerte für diese SLIs (zum Beispiel 99,9 % Erfolgsquote über 30 Tage)
- Error Budgets: die tolerierte Unzuverlässigkeit, bevor die Arbeit von Features auf Stabilität verlagert wird
Googles SRE-Leitfaden bleibt eine der klarsten Referenzen für diesen Ansatz: siehe das frei verfügbare Site Reliability Engineering Buch.
Praxistaugliche SLIs, die zur Realität passen
Für die meisten Backends decken diese SLIs 80 % der Zuverlässigkeitsergebnisse ab:
- Verfügbarkeit: Anteil erfolgreicher Anfragen (Client-Fehler, die nicht von Ihnen verursacht wurden, ausschließen)
- Latenz: p50, p95, p99 pro Endpoint und Kundensegment
- Korrektheit: Geschäftsinvarianten (zum Beispiel „jede Zahlung hat genau einen Buchungseintrag“), nachverfolgt über Audits
- Aktualität: für asynchrone Pipelines die Time-to-Visible (vom Event bis zum für den Nutzer sichtbaren Zustand)
Wenn Sie SLIs definieren, legen Sie auch den Messpunkt (Edge, API-Gateway, Service, Datenbank) und die Sampling-Strategie (gesamter Traffic vs. Stichprobe) fest – sonst streiten sich Teams während Incidents über Zahlen.
Designen Sie für den Fehlerfall, nicht für den Happy Path
Moderne Systeme fallen auf chaotische, partielle Weise aus: Eine Abhängigkeit wird langsam, eine Datenbank-Replica gerät in Verzug, eine Queue staut sich, ein Deploy erhöht den Speicherverbrauch. Zuverlässigkeit verbessert sich am schnellsten, wenn Ihr Backend davon ausgeht, dass Fehler normal sind, und sie eindämmt.
Die AWS Well-Architected Reliability Pillar ist eine starke, herstellerneutrale Checkliste (auch wenn Sie nicht auf AWS sind).
Timeouts, Retries und Backoff (mit Schutzmechanismen)
Ein häufiges Zuverlässigkeits-Anti-Pattern ist „wir haben Retries hinzugefügt“ und damit versehentlich einen Traffic-Storm ausgelöst.
Gute Defaults:
- Setzen Sie immer Timeouts auf ausgehende Calls (HTTP, gRPC, Datenbank-Queries). Kein Timeout bedeutet „hänge für immer“, was selten korrekt ist.
- Retries nur, wenn sie sicher sind (idempotente Operationen oder Operationen mit Idempotency Keys).
- Verwenden Sie exponentielles Backoff mit Jitter, um synchronisierte Retry-Spitzen zu vermeiden.
- Begrenzen Sie Retries und ziehen Sie schnelles Fehlschlagen vor, wenn ein Downstream-System unzuverlässig ist.
Wenn Sie sich nur eine Regel merken: Ein Retry ist zusätzliche Last. Wenn das Downstream-System wegen Last fehlschlägt, verstärken Retries den Fehler.
Idempotenz als API-Feature erster Klasse
Zuverlässigkeit bedeutet nicht nur „erreichbar bleiben“, sondern auch „den Zustand nicht beschädigen, wenn etwas schiefgeht“. Idempotenz verhindert Doppelverarbeitung, wenn Clients Retries ausführen, Netzwerke Verbindungen verlieren oder Sie parallele Consumer betreiben.
Gängige Patterns:
- Idempotency Keys, die serverseitig für create-ähnliche Operationen gespeichert werden (Zahlungen, Bestellungen, Subscriptions)
- Exactly-once-Effekt über De-Duplication-Tabellen (messageId als Unique Key)
- Optimistic Concurrency mit Versionsfeldern oder ETags für Updates
Circuit Breaker und Bulkheads gegen kaskadierende Ausfälle
Kaskadierende Ausfälle sind das, was kleine Aussetzer in echte Ausfälle verwandelt.
- Circuit Breaker: Hören Sie für kurze Zeit auf, eine ausfallende Abhängigkeit aufzurufen, und prüfen Sie dann auf Erholung.
- Bulkhead-Isolation: Trennen Sie Thread-Pools, Connection-Pools oder Queues pro Abhängigkeit, damit ein langsames Downstream nicht gemeinsam genutzte Ressourcen erschöpft.
Diese Patterns sind besonders wertvoll bei „darf-nicht-ausfallen“-Abhängigkeiten wie Authentifizierung, Payment-Providern oder Broker-Integrationen.
Machen Sie die Datenbank zum Zuverlässigkeits-Asset, nicht zur Hypothek
Backend-Zuverlässigkeit bricht häufig auf der Datenbankebene zusammen: Lock-Contention, Runaway-Queries, Schema-Migrationen oder fragile Transaktionsgrenzen.
Schützen Sie Ihr Datenmodell mit Invarianten
Definieren Sie Invarianten, die immer gelten müssen, und erzwingen Sie sie nach Möglichkeit in der Datenbank:
- Unique Constraints (verhindern Duplikate bei Bestellungen)
- Foreign Keys (verhindern verwaiste Datensätze)
- Check Constraints (verhindern ungültige Zustände)
Validierung auf Anwendungsebene ist wichtig, aber Datenbank-Constraints sind Ihre letzte Verteidigungslinie, wenn die Nebenläufigkeit zunimmt.
Kontrollieren Sie das Query-Risiko
Bei stark frequentierten Vorfällen lässt sich häufig eine einzelne teure Query als Ursache identifizieren.
Best Practices:
- Etablieren Sie Query-Timeouts und tracken Sie langsame Queries nach Fingerprint
- Nutzen Sie Read-Replicas mit Bedacht (planen Sie für Replikations-Lag in Nutzer-Workflows)
- Setzen Sie Indizes bewusst ein und messen Sie die Write-Amplifikation
- Vermeiden Sie unbegrenzte Queries in kundenseitigen Endpoints (immer paginieren)
Schema-Migrationen ohne Downtime
Zuverlässigkeitsfreundliche Migrationen sind inkrementell und reversibel:
- Expand-then-Contract (neue Spalten hinzufügen, Backfill, Reads umstellen, alte Spalten entfernen)
- Verwenden Sie rückwärtskompatible Änderungen während Rolling Deploys
- Behandeln Sie Migrationsskripte wie Produktivcode (reviewt, getestet, beobachtbar)
Event-getriebene Zuverlässigkeit: Konsistenz, Replays und Poison Messages
Queues und Streams verbessern die Resilienz – aber nur, wenn Sie die Fehlermodi mitdenken.
Verwenden Sie das Outbox-Pattern für zuverlässiges Event-Publishing
Ein klassischer Zuverlässigkeits-Bug: Sie aktualisieren die Datenbank, scheitern dann beim Publishen eines Events und hinterlassen Downstream-Systeme inkonsistent.
Das Transactional-Outbox-Pattern löst das, indem das Event in derselben Transaktion in eine Outbox-Tabelle geschrieben und anschließend asynchron veröffentlicht wird.
Planen Sie Reprocessing als normalen Betriebsfall ein
Wenn Sie Events nicht sicher replayen können, werden Sie sich davor scheuen, Bugs zu fixen.
- Halten Sie Events unveränderlich und versioniert
- Machen Sie Consumer idempotent
- Speichern Sie genug Kontext, um den Zustand wiederherzustellen (oder verwenden Sie Compacted Topics mit Bedacht)
Behandeln Sie Poison Messages und Backpressure
Eine einzige „schlechte“ Nachricht kann eine Partition blockieren oder einen Worker-Pool sättigen.
- Implementieren Sie eine Dead-Letter-Queue (DLQ) mit Alerting
- Fügen Sie maximale Retry-Counts mit exponentiellem Backoff hinzu
- Stellen Sie Queue-Depth und Consumer-Lag als erstklassige Metriken bereit
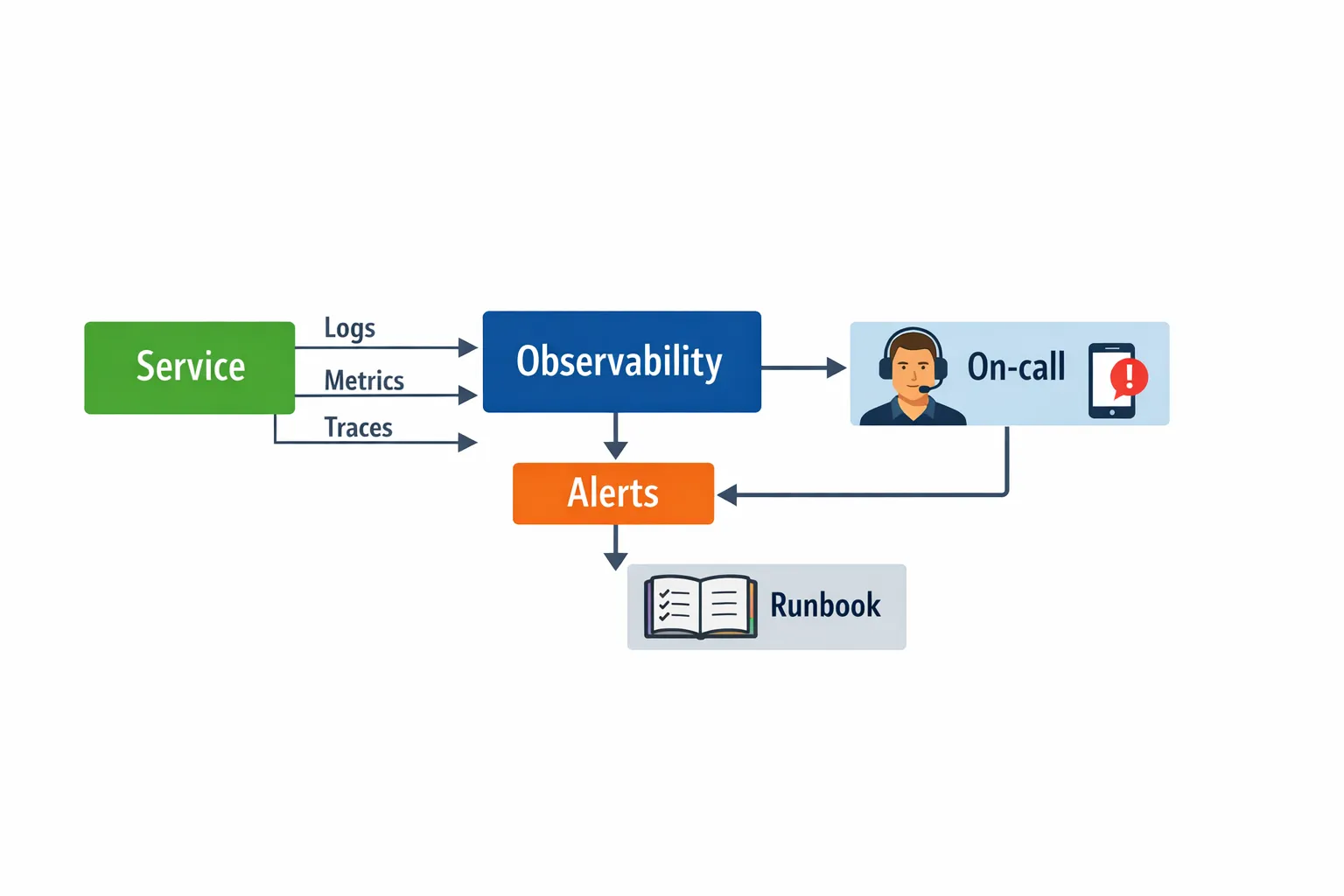
Observability, die schnelle Diagnosen unterstützt
Zuverlässigkeit dreht sich genauso um MTTR (Mean Time to Recovery) wie um Fehlervermeidung. Sie können sich nicht schnell erholen, wenn Sie nicht sehen, was passiert.
OpenTelemetry hat sich als praxistauglicher Standard für Traces und Metriken über Sprachen und Anbieter hinweg etabliert: siehe das OpenTelemetry-Projekt.
Der Minimum Viable Observability Stack
- Strukturierte Logs mit Correlation IDs (requestId, traceId, ggf. userId)
- Metriken für SLIs, Sättigung (CPU, Speicher, Pool-Auslastung) und Business-KPIs
- Distributed Tracing über Service-Grenzen und asynchrone Flows hinweg
- Umsetzbare Alerts, gekoppelt an SLO-Burn-Rate, nicht an reines Infrastruktur-Rauschen
Eine starke operative Gewohnheit ist es, an jedem Alert-Runbook ein Trace- oder Log-Beispiel anzuhängen, damit On-Call-Engineers in Minuten von „Pager“ zu „Wo geht die Zeit verloren?“ springen können.
Zuverlässigkeitstests, die die Produktion abbilden
Unit-Tests sind notwendig, beweisen aber selten Zuverlässigkeit. Zuverlässigkeitsprobleme entstehen an Integrationsgrenzen, in der Nebenläufigkeit und unter Last.
Contract Tests für sichere Abhängigkeiten
Contract Testing verhindert Breaking Changes zwischen Services und Clients:
- API-Schema-Kompatibilitätsprüfungen (OpenAPI, Protobuf)
- Consumer-driven Contracts für kritische Integrationen
- Rückwärtskompatibilitätsregeln als CI-Gates
Lasttests mit realistischer Failure Injection
Versuchen Sie zu beantworten:
- Was ist der maximal nachhaltige Durchsatz, bevor die Latenz hochschlägt?
- Was passiert, wenn eine Abhängigkeit 5x langsamer wird?
- Was passiert, wenn die Datenbank teilweise nicht verfügbar ist?
Chaos Engineering muss nicht spektakulär sein. Selbst einfache, kontrollierte Experimente (eine Instanz killen, einem Downstream Latenz hinzufügen) können verborgene Kopplungen aufdecken.
Deployment-Praktiken, die den Blast Radius reduzieren
Die meisten „Backend-Reliability“-Vorfälle sind änderungsbedingt. Ihr Deployment-Prozess ist ein Zuverlässigkeits-Feature.
Progressive Delivery statt Big-Bang-Releases
- Canary-Releases für risikoreiche Services
- Blue/Green, wenn Rollback-Geschwindigkeit zählt
- Feature Flags für Änderungen an der Geschäftslogik
Der Schlüssel liegt in Observability und automatisierten Rollback-Kriterien: Wenn Fehlerraten oder Latenzen Schwellen überschreiten, sollte das System das Rollout stoppen.
Machen Sie Rollbacks langweilig
Rollbacks scheitern, wenn:
- Schema-Änderungen nicht rückwärtskompatibel sind
- Sie das vorherige Artefakt nicht schnell redeployen können
- Sie unter Druck auf manuelle Schritte angewiesen sind
Ein zuverlässiges Team kann „Wie rollen wir zurück?“ genauso schnell beantworten wie „Wie deployen wir?“.
Häufige Backend-Fehlermodi und bewährte Gegenmaßnahmen
Die folgende Tabelle ist eine praxistaugliche Referenz, die Sie in Design-Reviews und Incident-Retrospektiven verwenden können.
| Fehlermodus | Wie es in der Produktion aussieht | Mitigations-Patterns | Was zu überwachen ist |
|---|---|---|---|
| Langsame Downstream-Abhängigkeit | Latenz steigt, Thread-Pools sättigen | Timeouts, Circuit Breaker, Bulkheads, Caching wo sicher | p95-Latenz pro Abhängigkeit, Pool-Sättigung, Fehlerrate |
| Traffic-Spikes | Erhöhte 429/503, Queue-Backlogs | Rate Limiting, Autoscaling, Load Shedding, Backpressure | RPS, Queue-Depth/Lag, CPU/Speicher, abgelehnte Requests |
| Doppelte Requests/Events | Doppelbuchungen, doppelte Bestellungen | Idempotency Keys, De-Dup-Tabellen, Exactly-once-Effekt | Duplikatrate, Constraint-Verletzungen, DLQ-Volumen |
| Datenbank-Contention | Hohe Latenz, Deadlocks, Timeouts | Index-Tuning, Query-Limits, Hot-Rows isolieren, Caching, Sharding nur bei Bedarf | Slow Queries, Lock-Wait-Time, Connection-Pool-Auslastung |
| Fehlerhafter Deploy | Plötzlicher Anstieg der Fehlerrate | Canary, automatisierter Rollback, Feature Flags | Fehlerrate pro Version, SLO-Burn-Rate |
| Versteckte Datenbeschädigung | Reports driften, Reconciliation schlägt fehl | Constraints, Audit-Trails, Invarianten, regelmäßige Reconciliation-Jobs | Invariantenverletzungen, Reconciliation-Diffs |
Zuverlässigkeit ist domänenabhängig (Beispiel Trading)
Zuverlässigkeitserwartungen ändern sich je nach Domäne. Ein internes B2B-Tool kann kurze Beeinträchtigungen verkraften. Ein Finanzsystem oft nicht.
Im Optionshandel und in Execution-Workflows etwa erwarten Nutzer schnelle, vorhersehbare Interaktionen und klare Risikosicht. Auch wenn Sie keine Trading-Software bauen, gilt das Prinzip: Definieren Sie Zuverlässigkeit rund um den „Moment der Wahrheit“ des Nutzers und entwickeln Sie rückwärts daraus.
Eine pragmatische Zuverlässigkeits-Checkliste pro Backend-Schicht
Verwenden Sie diese als leichtgewichtige Review-Vorlage für neue Services und für Hardening-Initiativen.
| Schicht | Best Practices für Zuverlässigkeit | Schnelle Belege, auf die zu achten ist |
|---|---|---|
| API-Grenze | Timeouts, Request-Limits, Idempotenz-Strategie, klare Fehler-Taxonomie | API-Docs enthalten Retry-Hinweise, 429-Nutzung, Idempotency Keys |
| Service-Code | Defensive Dependency Calls, Circuit Breaker, Bulkheads, Graceful Shutdown | Konfigurierbare Timeouts, beschränkte Queues, Readiness/Liveness |
| Datenebene | Constraints, sichere Migrationen, Query-Budgets, getestete Backups | Migration-Playbooks, Slow-Query-Dashboards, Restore-Tests |
| Async Processing | Outbox, DLQ, Replay-Strategie, idempotente Consumer | DLQ-Alerts, Replay-Tooling, De-Dup-Keys |
| Observability | SLIs/SLOs, Traces, strukturierte Logs, Runbooks | SLO-Dashboards, Trace-Sampling-Policy, On-Call-Dokumentation |
| Delivery | Canary/Blue-Green, automatisierter Rollback, Konfigurationsmanagement | Pipeline-Gates an SLO-Burn gekoppelt, Rollback-Drills |
Wo Teams hängen bleiben (und wie sich das lösen lässt)
„Wir haben zu viel mit Features zu tun“
Behandeln Sie Reliability-Arbeit wie Produktarbeit, indem Sie sie an messbare Ergebnisse koppeln:
- Change Failure Rate senken
- MTTR reduzieren
- p95-Latenz auf umsatzkritischen Endpoints verbessern
Wenn Sie Reliability als „Schutz der Liefergeschwindigkeit“ framen, konkurriert sie weniger mit Features.
„Wir wissen nicht, was wir zuerst angehen sollen“
Starten Sie mit der Wahrheit aus der Produktion:
- Top-5-Incident-Ursachen aus dem letzten Quartal
- Services mit dem höchsten SLO-Burn
- Teuerste Support-Tickets, die mit Performance oder Downtime zusammenhängen
Führen Sie dann einen fokussierten Hardening-Sprint mit klaren Exit-Kriterien durch (zum Beispiel „überall Timeouts“, „Idempotenz bei Zahlungen“, „DLQ mit Alerts“).
Wie Wolf-Tech unterstützen kann
Wenn Sie ein externes, erfahrenes Review der Zuverlässigkeitslage eines Backend-Systems wünschen, bietet Wolf-Tech Full-Stack-Entwicklung und Engineering-Beratung über Architektur, Code-Qualität, Legacy-Optimierung, Cloud und DevOps sowie Datenbank- und API-Systeme hinweg. Typische Engagements starten mit einer gezielten Analyse von Fehlermodi, Observability-Lücken und Deployment-Risiken und gehen dann in die praktische Umsetzung der ROI-stärksten Verbesserungen über.
Wenn Sie in diesem Quartal eine Reliability-Initiative planen, ist der schnellste erste Schritt, SLIs/SLOs für eine kritische User-Journey zu definieren und die drei wichtigsten Fehlerszenarien Ende-zu-Ende abzubilden. Daraus entsteht ein Umsetzungsplan, der wirklich lieferbar ist.