
Code-Quality-Metriken, die zählen


Über Code-Qualität zu sprechen ist leicht — sie zu messen überraschend schwer. Die meisten Teams verfolgen bereits viele Zahlen (Coverage, Lint-Warnungen, Bugs, Velocity), spüren aber dort den Schmerz, wo es zählt: langsame Änderungen, fragile Releases und „nur noch ein Feature", das in eine Woche Archäologie umschlägt.
Die Lösung ist nicht „mehr Metriken". Sie besteht darin, eine kleine Menge an Code-Quality-Metriken zu wählen, die Ergebnisse vorhersagen (Liefergeschwindigkeit, Zuverlässigkeit, Wartbarkeit, Sicherheit) — und sie in alltägliche Engineering-Entscheidungen einzubetten.
Was „gute" Code-Quality-Metriken leisten (und was sie nie tun sollten)
Eine nützliche Metrik ändert Verhalten in die richtige Richtung. Eine schädliche Metrik erzeugt Theater.
Gute Code-Quality-Metriken sind:
- Handlungsorientiert: Wenn die Zahl sich verschlechtert, weiß das Team, was als Nächstes zu tun ist (einen Hotspot refactorn, Tests an Nahtstellen ergänzen, PR-Größe reduzieren).
- Über die Zeit vergleichbar: Sie sehen Trendlinien, nicht nur Snapshots.
- Günstig genug, um kontinuierlich erhoben zu werden: Idealerweise automatisiert in CI.
- Mit Risiko verknüpft: Sie heben Bereiche hervor, die wahrscheinlich Incidents, Nacharbeit oder Security-Exposure verursachen.
Metriken scheitern, wenn sie zu Zielen werden. Wenn die Führung sagt „Coverage auf 90 % heben", können Teams das mit niedrigwertigen Tests erspielen. Wenn Sie „Bugs pro Entwickler" messen, entmutigen Sie Reporting und Zusammenarbeit.
Ein besserer Ansatz: Behandeln Sie Metriken als Entscheidungsunterstützung, nicht als Performance-Bewertung.
Mit den Ergebnissen beginnen, die Sie schützen wollen
Bevor Sie Metriken wählen, einigen Sie sich darauf, welches Ergebnis Sie schützen wollen.
- Wenn Sie schnellere Feature-Lieferung wollen, brauchen Sie Wartbarkeits- und Review-Flow-Metriken.
- Wenn Sie weniger Incidents wollen, brauchen Sie Metriken zu Change-Risiko und Defect-Escape.
- Wenn Sie niedrigere Langzeitkosten wollen, brauchen Sie Hotspot- und Komplexitätsmetriken, die Refactorings lenken.
- Wenn Sie bessere Security-Posture wollen, brauchen Sie Dependency- und Remediation-Metriken.
Deshalb paaren Teams Code-Quality-Metriken oft mit Delivery- und Reliability-Maßen wie DORA-Indikatoren (Deploy-Frequenz, Lead Time for Changes, Change Failure Rate, MTTR). Nicht weil DORA „der einzige Weg" ist, sondern weil es die Diskussion an Geschäftsimpact verankert.
Wartbarkeitsmetriken, die wirklich etwas bewegen
Wartbarkeit ist der Punkt, an dem Code-Qualität entweder zum Beschleuniger oder zur Steuer wird. Das Ziel ist nicht perfekte Eleganz, sondern vorhersehbare Änderungen zu vertretbaren Kosten.
Komplexität (zum Auffinden von Refactor-Kandidaten — nicht zum Bloßstellen von Entwicklern)
Komplexitätsmetriken helfen Ihnen, Funktionen und Module zu lokalisieren, die schwer zu verstehen und riskant zu ändern sind.
Verbreitete Ansätze:
- Zyklomatische Komplexität: Zählt unabhängige Pfade durch Code. Nützlich, um stark verzweigte Logik zu markieren.
- Kognitive Komplexität: Versucht zu modellieren, wie schwer Code zu durchdenken ist (oft besser an „das ist schwer zu lesen"-Feedback ausgerichtet).
Wie Sie sie sinnvoll nutzen:
- Verfolgen Sie die schlimmsten Übeltäter (Top N Funktionen) statt Mittelwerte.
- Bewerten Sie komplexen Code im Kontext von Test-Coverage und Churn. Hohe Komplexität bei hohem Churn ist Priorität.
Code-Churn und „Hotspots" (das praktischste Risikosignal)
Churn beschreibt, wie häufig sich Code ändert. Code, der sich ständig ändert, ist nicht automatisch schlecht — aber hoher Churn kombiniert mit Defekten, Incidents oder Komplexität deutet oft auf einen brüchigen Bereich hin.
Ein einfaches Hotspot-Modell, das viele Teams nutzen:
- Häufigkeit von Änderungen (Commits) in einer Datei/einem Modul
- Geänderte Zeilen (added + removed)
- Defekte oder Incident-Verknüpfungen, die mit dem Bereich assoziiert sind
Das ist eine der besten Möglichkeiten, Modernisierungsarbeit zu priorisieren, weil es die Frage beantwortet: „Wo zahlt sich ein Refactor am schnellsten aus?" Wenn Sie aktiv Legacy-Systeme modernisieren, übertrifft hotspot-getriebene Priorisierung breite „den ganzen Klotz neu schreiben"-Initiativen meist deutlich. (Wolf-Techs Legacy-Arbeit beginnt häufig mit dieser Art Targeting in einem Codebase-Assessment- und Remediation-Plan.)
Duplikation (Trendlinien messen, nicht nur den aktuellen Prozentsatz)
Duplikation ist ein Wartbarkeits-Multiplikator. Wenn Logik kopiert wird, zahlen Sie für jede künftige Änderung mehrfach.
Worauf es vor allem ankommt:
- Nehmen duplizierte Blöcke zu?
- Konzentrieren sich Duplikate in kritischen Domänen (Pricing, Permissions, Billing)?
Eine praktische Regel: Tolerieren Sie etwas Duplikation, während sich ein Feature stabilisiert, und konsolidieren Sie, sobald Sie die Form des Problems verstehen. Metriken sollten diese Entscheidung stützen — keine verfrühte Abstraktion erzwingen.
„Wartbarkeits"-Bewertungen aus statischer Analyse (als Gesprächseinstieg nutzen)
Tools wie SonarQube und ähnliche Plattformen können kombinierte Scores und „Technical-Debt"-Schätzungen erzeugen. Diese können nützlich sein, um Muster zu erkennen (Null-Handling, Resource Leaks, übermäßig komplexe Methoden) — behandeln Sie den Roll-up-Score aber als Rauchmelder, nicht als Präzisionsinstrument.
Hier eine schnelle Übersicht der Wartbarkeitsmetriken, ihrer Erfassung und der häufigsten Fehlanwendungen:
| Metrik | Was sie Ihnen sagt | Wie erheben | Häufige Fallstrick |
|---|---|---|---|
| Zyklomatische oder kognitive Komplexität | Code, der schwer zu durchdenken und riskant zu ändern ist | Statische Analyse in CI | Niedrige Komplexität überall jagen, auch wo Code stabil ist |
| Code-Churn (pro Datei/Modul) | Wo sich Änderungen und Nacharbeit konzentrieren | Git-Analytics | „Geschäftigen Code" mit „schlechtem Code" verwechseln, ohne Defekt-Kontext |
| Hotspots (Churn + Komplexität + Incidents) | Bereiche mit dem besten Refactor-ROI | Git + statische Analyse + Incident-Tagging | Incidents nicht konsistent zurück auf Codebereiche verknüpfen |
| Duplikation | Versteckte zukünftige Wartungskosten | Statische Analyse | Zu früh überabstrahieren, um die Metrik zu erfüllen |
Test-Qualitäts-Metriken (jenseits von „Coverage %")
Testen ist ein wesentlicher Hebel für Code-Qualität, doch die am häufigsten berichtete Metrik (Coverage) ist auch die am leichtesten misszuverstehende.
Coverage (als Risiko-Karte nutzen, nicht als Ziel)
Coverage ist weiterhin wertvoll, wenn Sie sie als Bereich behandeln, in dem Sie kein Sicherheitsnetz haben.
So nutzen Sie Coverage am besten:
- Verfolgen Sie Coverage auf geändertem Code (Diff-Coverage), um neue Arbeit abzusichern.
- Schauen Sie speziell auf Coverage rund um Hotspots und kritische Pfade (Auth, Payments, Datenmigrationen).
Vermeiden Sie es, sie in ein einzelnes Ziel wie „80 % überall" zu verwandeln. Manche Code wird besser durch Integrationstests, Contract-Tests oder Property-based Tests validiert — und Coverage kann diese unterrepräsentieren.
Flaky-Test-Rate (eine der unterschätztesten Delivery-Metriken)
Flaky Tests zerstören Vertrauen in CI, verlangsamen Releases und gewöhnen Engineers daran, Pipelines neu zu starten, bis sie „grün" werden.
Flaky-Test-Metriken zum Verfolgen:
- Anteil der Builds, die wegen nichtdeterministischer Tests fehlschlagen
- Top-flaky-Tests nach Häufigkeit
- Time-to-Remediate für flaky Tests (wie Reliability-Arbeit behandeln)
Das ist eine Code-Quality-Metrik, weil flaky Tests häufig Symptome schlechter Grenzen sind (zu viel globaler State, Zeitabhängigkeit, brüchige UI-Selektoren, nicht isolierte Integrationsumgebungen).
Mutation-Testing-Score (hohes Signal, höherer Aufwand)
Mutation-Testing verändert Ihren Code in kleinen Schritten (Mutationen) und prüft, ob Tests fehlschlagen. Wenn Tests trotzdem grün bleiben, prüfen sie möglicherweise kein bedeutungsvolles Verhalten.
Nicht jedes Team braucht Mutation-Testing überall. Wo es glänzt:
- Kern-Bibliotheken für Geschäftslogik
- Sicherheitskritische Validierungslogik
- Komplexe Berechnungen (Finanzen, Pricing, Disposition)
Test-Suite-Dauer (Qualität heißt auch „schnelles Feedback")
Lange laufende Tests führen zu Batching und Big-Bang-Merges, was das Risiko erhöht. Verfolgen Sie:
- Zeit von PR-Eröffnung bis zum vollen CI-Signal
- Zeit, einen fehlgeschlagenen Job neu zu starten
Oft ist die beste Investition, Test-Layer zu trennen (Unit vs. Integration) und Integrationsumgebungen reproduzierbar zu machen.
Code-Review- und Kollaborationsmetriken (Qualität ist Teamsport)
Einige der stärksten „Qualitätsprädiktoren" leben im Pull-Request-Workflow, weil Reviews der Ort sind, an dem Design- und Wartbarkeitsfragen früh erkannt werden.
PR-Größe
Kleinere PRs sind leichter zu reviewen, zu testen und zurückzudrehen. Sie brauchen keine harte Regel, aber viele Teams stellen fest, dass das Reviewen von Hunderten geänderter Zeilen auf einmal die Anzahl übersehener Probleme dramatisch erhöht.
Was zu verfolgen ist:
- Median-PR-Größe (geänderte Dateien, geänderte Zeilen)
- Anteil sehr großer PRs (Ihr „Tail-Risk")
Wenn große PRs üblich sind, liegt der Fix meist in Prozess und Architektur: Vertical Slicing, Feature Flags, inkrementelle Refactors und bessere Grenzen.
Review-Latenz (Zeit bis zum ersten Review, Zeit bis zum Merge)
Lange Review-Zyklen erzeugen Merge-Konflikte, Kontextwechsel und hektische Last-Minute-Freigaben. Review-Latenz ist eine Qualitätsmetrik, weil sie korreliert mit:
- Geringerer Review-Tiefe
- Größerer Batchgröße
- Mehr Nacharbeit
Ein gesundes Ziel ist nicht „so schnell wie möglich", sondern „schnell genug, dass die Autorin noch im Kontext ist".
Rework-Rate
Wenn PRs häufig mit größeren Änderungen zurückgehen, kann das ein Zeichen sein für:
- Unklare Akzeptanzkriterien
- Fehlendes Design-Alignment vor dem Coden
- Fehlende gemeinsame Konventionen
Hier zahlen sich leichtgewichtige Architekturnotizen und konsistente Code-Review-Standards aus.

Defekt- und Reliability-Metriken, die Code-Qualität an reale Wirkung binden
Stakeholder erleben Qualität letztlich als Zuverlässigkeit. Die nützlichsten reliability-nahen Metriken sind diejenigen, die Änderungen mit Incidents verknüpfen.
Defect-Escape-Rate
Sie misst Bugs, die nach dem Release gefunden werden, im Verhältnis zu Bugs, die vor dem Release gefunden werden.
Implementierungswege:
- Produktionsdefekte pro Release zählen
- Oder den Anteil aller Defekte messen, die in der Produktion entdeckt werden
Paaren Sie sie mit Severity. Zehn kosmetische Probleme entsprechen nicht einem kritischen Ausfall.
Change Failure Rate
Change Failure Rate misst, wie oft eine Änderung einen Incident, ein Rollback oder einen dringenden Fix verursacht. Das ist eine der saubersten Brücken zwischen Engineering-Aktivität und operativen Ergebnissen.
Um sie handlungsorientiert zu machen, verknüpfen Sie Fehler zurück mit:
- Komponenten (welches Modul fällt am häufigsten aus)
- Mustern (Migrationsfehler, Konfigurationsfehler, Null-Handling)
- Fehlenden Test-Layern (keine Contract-Tests an einer API-Grenze)
Mean Time to Restore (MTTR)
MTTR ist nicht rein „Code-Qualität", aber Code-Qualität beeinflusst sie stark. Systeme mit:
- Klaren Modulgrenzen
- Gutem Logging und Tracing
- Feature Flags
- Sicheren Rollback-Pfaden
erholen sich schneller.
Wenn MTTR hoch ist, könnte Ihre „Code-Quality-Arbeit" tatsächlich Observability- und Operability-Verbesserung sein.
Sicherheitsfokussierte Code-Quality-Metriken (die, die Führungskräfte verstehen)
Security-Metriken können schnell laut werden. Das Ziel ist, Exposure und Remediation zu messen — nicht die rohe Anzahl der Findings.
Gute Einstiegsmetriken:
- Vulnerability-Alter: Wie lange bekannte Schwachstellen in Dependencies ungelöst bleiben.
- Patch-Latenz: Zeit von Verfügbarkeit eines Fixes bis zum Produktions-Deployment.
- Trend der Secrets-Erkennung: Werden Credentials im Zeitverlauf seltener committet (und werden sie rotiert)?
- Coverage von Hochrisikobereichen: Tests und Reviews rund um Auth, Permissions, Input-Validierung und Deserialisierung.
Security-Metriken funktionieren am besten, wenn Engineering und Security sich darauf einigen, was „erledigt" bedeutet (triagiert, akzeptiertes Risiko, gefixt und deployt, verifiziert).
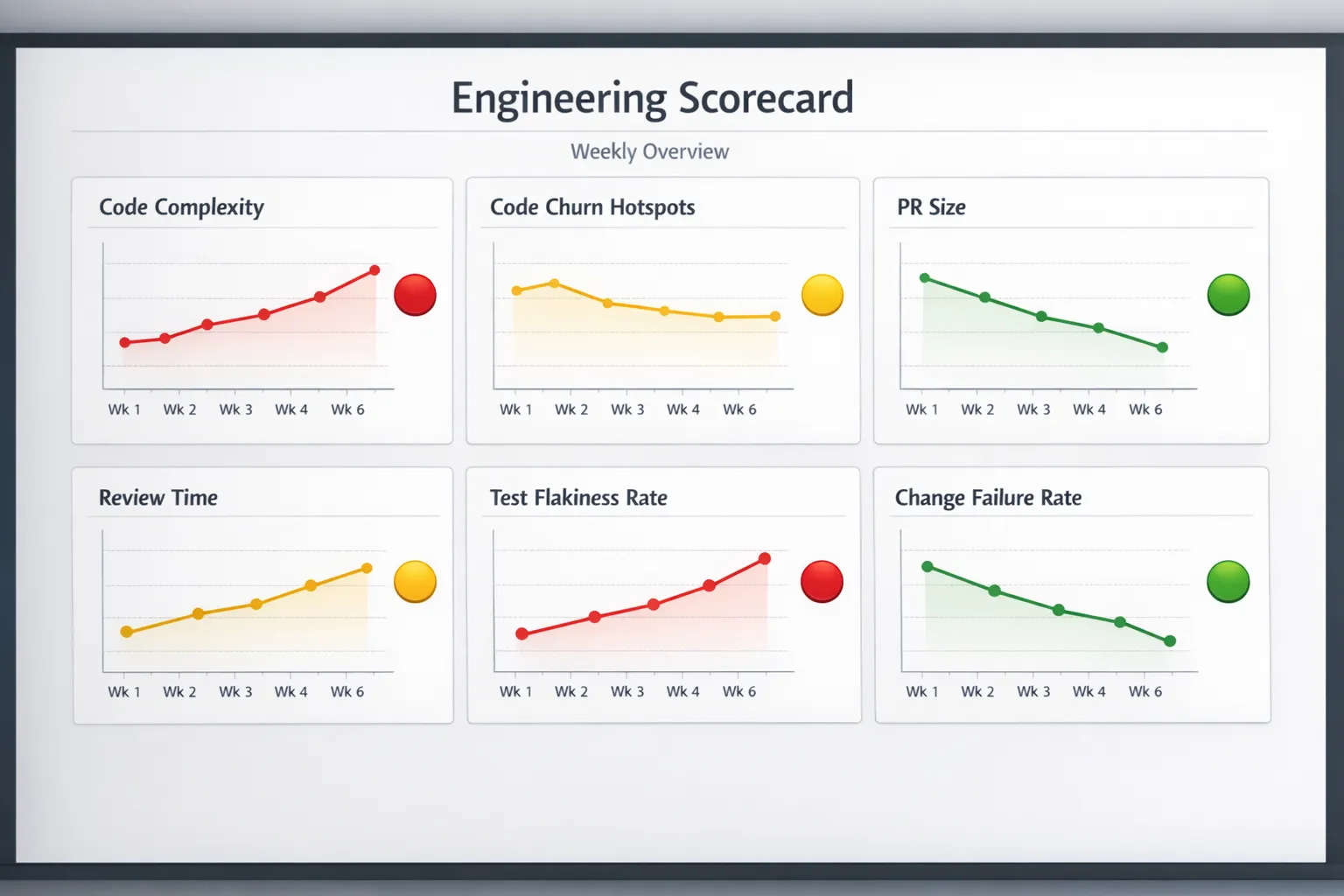
Eine leichtgewichtige „Code-Quality-Scorecard" für den Wochenrhythmus
Wenn Sie etwas wollen, das über die meisten Stacks hinweg funktioniert, starten Sie mit einer Scorecard, die Wartbarkeit, Testqualität und Change-Risiko mischt.
| Kategorie | Metrik | Wochenfrage, die sie beantwortet | Vorgeschlagene Verantwortung |
|---|---|---|---|
| Wartbarkeit | Top-Hotspots (Churn + Komplexität) | Wo investieren wir nächsten Sprint Refactor-Zeit? | Tech Lead |
| Wartbarkeit | Duplikations-Trend | Kopieren wir mehr Logik, als wir konsolidieren? | Team |
| Flow | Median-PR-Größe | Bündeln wir Arbeit zu stark? | Eng Manager |
| Flow | Zeit bis zum ersten Review | Blockieren Reviews die Lieferung und erhöhen sie Risiko? | Team |
| Tests | Flaky-Test-Rate | Können wir CI-Ergebnissen vertrauen? | Team |
| Tests | Diff-Coverage auf geändertem Code | Liefern wir Änderungen ohne Sicherheitsnetz aus? | Tech Lead |
| Reliability | Change Failure Rate | Verursachen Releases Incidents? | Eng Manager + SRE |
| Reliability | MTTR | Wie schnell erholen wir uns, wenn etwas schiefgeht? | SRE/Plattform |
| Security | Vulnerability-Alter (hohe Severity) | Häufen wir bekannte Exposure an? | Security + Team |
| Qualitätskosten | Engineering-Zeit für Nacharbeit | Zahlen wir eine wachsende „Steuer" für Code-Änderungen? | Eng Manager |
Sie können die Scorecard klein halten und trotzdem wirksam sein. Die Disziplin liegt in der Review-Kadenz und im Follow-through, nicht in der Anzahl der Charts.
Metriken, die häufig nach hinten losgehen (und was stattdessen funktioniert)
Manche Metriken erzeugen perverse Anreize oder messen schlicht das Falsche.
- Geschriebene Codezeilen: Belohnt Aufgeblasenheit, entmutigt Löschen und Vereinfachen. Bevorzugen Sie Hotspot-Reduktion oder Lead-Time-Verbesserungen.
- Erledigte Story Points: Leicht zu manipulieren, nicht teamübergreifend portierbar. Bevorzugen Sie Outcome-Metriken (Lead Time, Change Failure Rate) und Produktmetriken.
- „Bugs pro Entwickler": Bestraft Transparenz und Zusammenarbeit. Bevorzugen Sie Defect-Escape-Rate pro Komponente und lernorientierte Incident-Reviews.
- Rohe Coverage-Ziele: Fördern niedrigwertige Tests. Bevorzugen Sie Diff-Coverage, Flaky-Test-Rate und Coverage in kritischen Domänen.
Ein praktischer 30-Tage-Rollout-Plan
Wenn Sie wollen, dass Code-Quality-Metriken Bestand haben, setzen Sie sie wie ein Produkt um: kleiner Scope, schnelles Feedback, sichtbare Erfolge.
- Woche 1: Wählen Sie 6 bis 10 Metriken, definieren Sie sie präzise (was zählt, woher die Daten kommen) und entscheiden Sie, wer sie reviewt.
- Woche 2: Automatisieren Sie die Erfassung in CI, wo möglich (statische Analyse, Testergebnisse, PR-Analytics). Erstellen Sie ein gemeinsames Dashboard.
- Woche 3: Führen Sie das erste Review, identifizieren Sie einen Hotspot und schreiben Sie die Hypothese auf (zum Beispiel: „Modul X refactorn, um Incident-Rate und Review-Zeit zu senken").
- Woche 4: Liefern Sie eine Verbesserung aus und validieren Sie, ob sich die Metrik in der erwarteten Richtung bewegt hat.
Eine zentrale Gewohnheit: Jedes Mal, wenn Sie eine Metrik hinzufügen, entfernen oder relativieren Sie eine andere. Metric Sprawl ist real.
Wo externe Hilfe Ergebnisse beschleunigen kann
Manchmal ist der schnellste Weg zu besserer Code-Qualität ein extern geleitetes, expertengestütztes Assessment, das die wenigen Änderungen mit dem höchsten ROI identifiziert: Komplexität in den Hotspot-Modulen reduzieren, die richtigen Test-Nahtstellen einführen, CI-Feedback-Schleifen straffen und praktische Standards setzen.
Wolf-Tech ist auf Full-Stack-Entwicklung und Code-Quality-Consulting spezialisiert, einschließlich Legacy-Code-Optimierung und Modernisierungsplanung. Wenn Sie sich bereits durch Modernisierungsarbeit arbeiten, könnten diese Leitfäden ebenfalls hilfreich sein: Code-Modernisierungstechniken und Refactoring von Legacy-Anwendungen.
Die zentrale Botschaft: Messen Sie, was Schmerzen vorhersagt, reviewen Sie es regelmäßig und lassen Sie die Daten kleine, kontinuierliche Verbesserungen lenken. So hört Code-Qualität auf, vage Aspiration zu sein, und wird zum kumulierenden Vorteil.