
Den richtigen Tech Stack in 2025 wählen


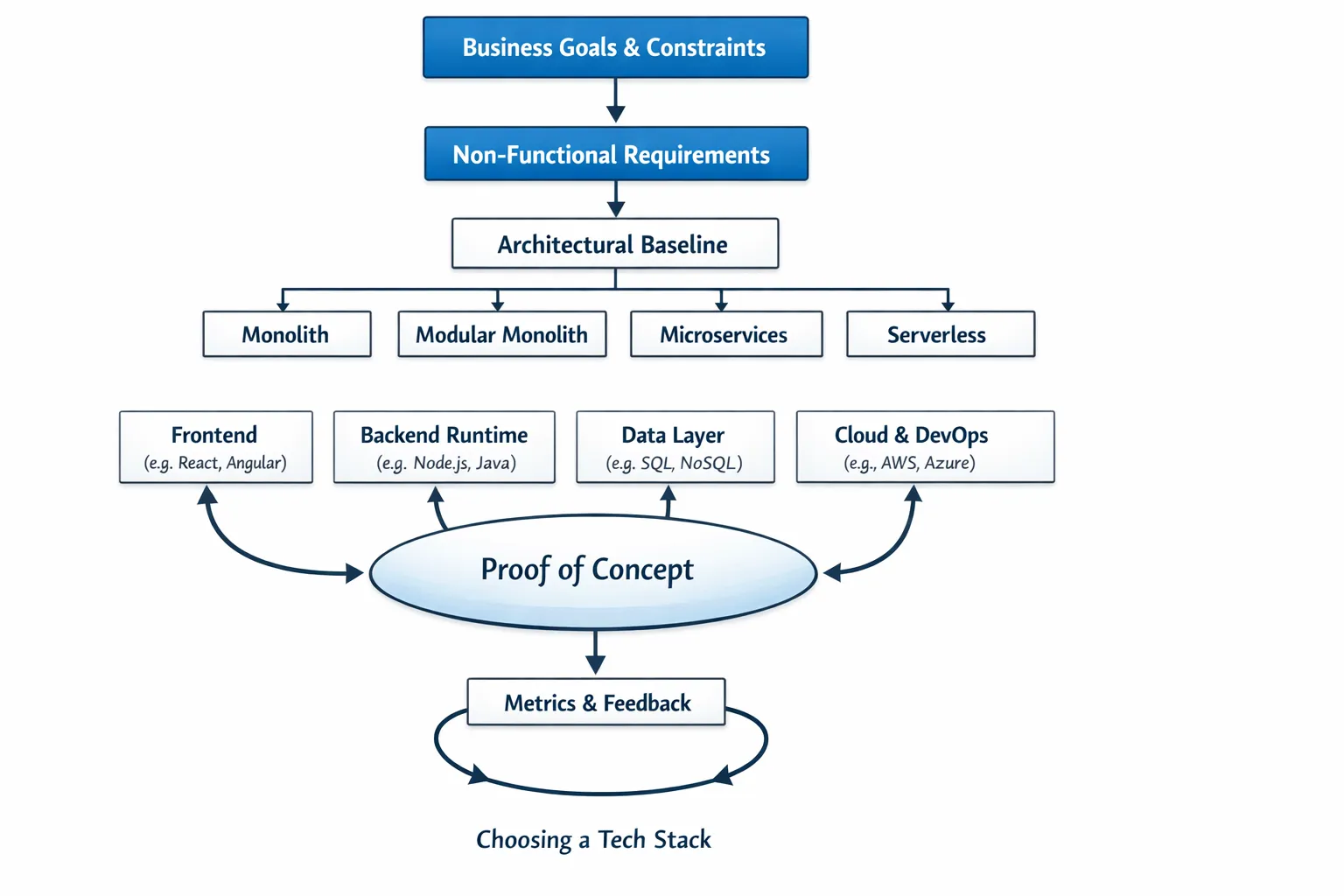
Einen Tech Stack in 2025 zu wählen bedeutet weniger, trendige Tools auszusuchen, und mehr, Technologie an Geschäftsergebnisse, Risiken und operative Realitäten anzupassen. Die richtigen Entscheidungen beschleunigen die Auslieferung, senken langfristige Kosten und erleichtern die Personalgewinnung. Die falschen bremsen Teams aus und binden Sie an brüchige Systeme. Dieser Leitfaden bietet Ihnen einen praxisnahen, fundierten Entscheidungsweg – mit Scorecards, Abwägungen und Beispiel-Stacks, die Sie an Ihren Kontext anpassen können.
Mit Ergebnissen starten, nicht mit Tools
Bevor Sie Frameworks evaluieren, treffen Sie drei Entscheidungen, die jede weitere Wahl verankern.
Geschäftsziele und Rahmenbedingungen klären
- Was muss das Produkt in den nächsten 6 bis 12 Monaten erreichen, und was ist für das zweite Jahr unverzichtbar
- Welche Budget-, Arbeitsmarkt- und regulatorischen Rahmenbedingungen gelten
- Wo werden Performance, Verfügbarkeit oder Sicherheit besonders geprüft
Nicht-funktionale Anforderungen definieren
- Skalierbarkeitserwartungen: Spitzenlast, Datenwachstum, Latenz-Ziele
- Zuverlässigkeitsziele wie SLOs, RTO und RPO
- Compliance-Anforderungen wie SOC 2, HIPAA, PCI, DSGVO
Eine architektonische Basis wählen
Wählen Sie die einfachste Architektur, die Ihre nächsten zwei Wachstumshorizonte abdeckt.
| Stil | Wann passend | Vorteile | Risiken |
|---|---|---|---|
| Monolith | Frühphasen-Produkte mit einem Team, überschaubarer Domäne | Schnell auslieferbar, leicht nachvollziehbar | Kann verwickelt werden, wenn Modularität vernachlässigt wird |
| Modularer Monolith | Die meisten SaaS- und Enterprise-Apps mit mehreren Domänen | Klare Grenzen, einzelnes Deployable | Erfordert Disziplin bei Modulgrenzen |
| Microservices | Unabhängige Domänen, mehrere Teams, unabhängige Skalierung nötig | Team-Autonomie, selektive Skalierbarkeit | Höhere Ops-Komplexität, verteilte Transaktionen |
| Serverless First | Unregelmäßige Workloads, ereignisgesteuerte Apps, kleines Ops-Team | Pay-per-Use, skaliert automatisch | Cold Starts, Anbieter-Kopplung, Test-Komplexität |
Ein modularer Monolith ist 2025 für viele die Standardwahl, weil er Geschwindigkeit und Wartbarkeit ausbalanciert – eine Einschätzung, die auch der Thoughtworks Technology Radar teilt.
Die Auswahl mit einer Scorecard messbar machen
Verwenden Sie eine gewichtete Scorecard, um Optionen objektiv zu vergleichen. Halten Sie sie kurz und transparent.
| Kriterium | Warum es wichtig ist | Empfohlene Gewichtung |
|---|---|---|
| Team-Vertrautheit und Talentpool | Einarbeitungszeit und Rekrutierungsrisiko dominieren die frühe Auslieferung | 25 |
| Wartbarkeit und Reife | Dokumentation, Stabilität, Upgrade-Pfad | 15 |
| Ökosystem und Community | Bibliotheken, Tooling, aktive Contributor | 10 |
| Performance für Ihren Anwendungsfall | Durchsatz, Latenz, Speicherbedarf | 10 |
| Skalierbarkeit und Betreibbarkeit | Horizontale Skalierung, Observability, Deployment-Modell | 10 |
| Sicherheitsniveau | Supply Chain, Patches, Härtungsleitfaden | 10 |
| Betriebskosten | Infrastruktur- plus Personalkosten für den Betrieb | 10 |
| Compliance und Governance | Erfüllt Audit-Anforderungen | 5 |
| Interoperabilität und Portabilität | Vermeidet harten Vendor-Lock-in | 5 |
Bewerten Sie Kandidaten auf einer Skala von 1 bis 5, multiplizieren Sie mit der Gewichtung und addieren Sie. Teilen Sie die Scorecard mit Stakeholdern, damit Abwägungen transparent sind.
Zwei Quellen können Ihnen helfen, Annahmen über Reife und Verfügbarkeit von Talenten zu untermauern.
- Die Stack Overflow 2024 Developer Survey zeigt, dass JavaScript und TypeScript zu den meistgenutzten Sprachen gehören, mit starken Ökosystemen und Talentpools.
- Das DB Eng ines Ranking platziert PostgreSQL konstant an oder nahe der Spitze, was breite Adoption und Tooling-Unterstützung widerspiegelt.
Frontend-Entscheidungen: Für Auslieferung und Performance-Budgets optimieren
Wählen Sie zuerst die Rendering-Strategie, dann das Framework.
Rendering-Strategie
- Server-gerendert oder statisch zuerst: wenn SEO wichtig ist, der initiale Load schnell sein muss oder Content öffentlich und cachbar ist.
- Client-lastiges SPA: wenn die App ein komplexes, authentifiziertes Produkt mit reichhaltigem State und geringen SEO-Anforderungen ist.
- Islands oder partielle Hydration: wenn Sie die SEO-Vorteile von SSR mit interaktiven Komponenten brauchen, ohne ein schweres Client-Bundle auszuliefern.
Frameworks, die 2025 sichere Wetten sind
- React mit Next.js: vielseitig für SSR, SSG und hybride Routes. Riesiges Ökosystem und Talentpool.
- Vue mit Nuxt: zugänglich mit starker SSR-Unterstützung und wachsendem Ökosystem.
- Angular: opinionated mit eingebauten Patterns, oft in Enterprises bevorzugt.
- SvelteKit: schlanke Runtime und hervorragende DX für kleinere Teams mit Performance-Fokus.
Für Mobile bleiben React Native und Flutter pragmatische plattformübergreifende Optionen, wenn eine gemeinsame Codebasis wichtig ist. Für plattformspezifische Erlebnisse oder fortgeschrittene Geräte-Integrationen sind Swift und Kotlin nach wie vor der Goldstandard.
Backend-Runtime: Runtime-Stärken an Ihre Workloads anpassen
- TypeScript auf Node.js oder Runtimes wie Bun: hervorragend für Web-Backends, APIs und Entwicklergeschwindigkeit mit einer Sprache über den gesamten Stack.
- Java oder Kotlin mit Spring Boot: Enterprise-Grade-Reife, tiefer Talentpool, starke Observability- und Sicherheits-Patterns.
- .NET mit C#: exzellent für Windows-lastige Umgebungen und Unternehmen, die auf Azure standardisieren.
- Go: geringer Speicherbedarf, einfache Concurrency, stark für Netzwerk-Services und Container.
- Python mit FastAPI oder Django: ideal für datenintensive Workflows, ML-nahe Services oder interne Tools.
- Rust: wenn Sie Performance und Sicherheit in systemnahen Services benötigen, manchmal als Ergänzung zu einem höherstufigen Stack.
Wenn Ihr Team gemischt ist, bevorzugen Sie eine primäre Runtime für die meisten Services und erlauben Sie Ausnahmen nur bei einer klaren Fähigkeitslücke.
Datenschicht: Langweilig wählen für Ihre Quelle der Wahrheit
Relationale Datenbanken betreiben nach wie vor die meisten geschäftskritischen Systeme. PostgreSQL ist ein starker Standard für OLTP, mit robusten Erweiterungen, Indexierungsoptionen und einer großen Community. Rankings wie DB Eng ines spiegeln seine anhaltende Beliebtheit branchenübergreifend wider.
Richtlinien für häufige Datenanforderungen:
- Primärspeicher: PostgreSQL für transaktionale Workloads. MySQL ist ebenfalls solide, besonders wo Legacy-Expertise vorhanden ist.
- Analytics und Reporting: ein separates Warehouse wie BigQuery, Snowflake oder Redshift, oder ein Open-Source-Columnar-Store wie ClickHouse für schnelle Aggregate.
- Suche und Logs: OpenSearch oder Elasticsearch für Volltextsuche und Log-Analytics.
- Caching: Redis für Hot Keys und Rate Limiting.
- Messaging und Streaming: Kafka für Hochdurchsatz-Streams, RabbitMQ für Work Queues und einfaches Pub/Sub.
Vermeiden Sie voreilige polyglotte Persistenz. Starten Sie mit einer primären Datenbank und fügen Sie spezialisierte Stores erst hinzu, wenn ein klarer, gemessener Bedarf entsteht.
Cloud und DevOps: Betrieb einfach halten
- Container: Docker für Packaging verwenden. Mit Kubernetes orchestrieren, wenn Sie mehrere unabhängige Services haben und Autoscaling sowie Self-Healing benötigen. Andernfalls mit verwalteten Container-Services starten, um Aufwand zu reduzieren.
- Serverless: Functions as a Service für unregelmäßige oder ereignisgesteuerte Workloads mit wenig State nutzen, plus verwaltete Datenbanken für weniger Ops-Aufwand.
- IaC: Auf Terraform oder ein Cloud-natives Äquivalent standardisieren für wiederholbare Environments.
- CI und CD: GitHub Actions oder GitLab CI sind zuverlässige Standards. Trunk-based Development und schnelle Pipelines anstreben.
- Observability: Auf OpenTelemetry für Traces, Metriken und Logs standardisieren, dann an Ihr APM Ihrer Wahl exportieren. Mehr erfahren unter OpenTelemetry.io.
Sicherheit und Compliance von Anfang an
- Folgen Sie den OWASP Top 10 für grundlegende Anwendungsrisiken und den OWASP API Security Top 10 für APIs.
- Automatisieren Sie Dependency-Scanning, SAST und Container-Image-Scanning in CI.
- Zentralisieren Sie das Secrets-Management und rotieren Sie Schlüssel regelmäßig.
- Generieren Sie SBOMs und tracken Sie Komponenten zur Vorbereitung auf Audits.
Das Sicherheitsniveau ist Teil Ihrer Stack-Entscheidung. Bevorzugen Sie Ökosysteme mit häufigem Patching und klaren Härtungsleitfäden.
Trends in 2025, die man beobachten sollte – ohne alles darauf zu setzen
- Edge und regionale Compute: Frameworks und Plattformen, die nah am Nutzer laufen, reduzieren Latenz. Bevorzugen Sie Frameworks, die am Edge rendern können, aber messen Sie die Ops-Abwägungen.
- WebAssembly und Rust im Backend: wachsend in performance-kritischen Pfaden und Plugin-Modellen. Erwägen Sie sie dort, wo sie spezifische Engpässe adressieren.
- KI-gestützte Features: Planen Sie Modell-Integrationen über APIs und vektorgestützte Suche, aber behalten Sie Nutzerdatenschutz, Kostenvorhersagbarkeit und Observability im Blick.
Nutzen Sie diese als inkrementelle Verbesserungen, nicht als Gründe, Ihren Basis-Stack umzubauen.
Beispiel-Stacks, die Sie mit der Scorecard rechtfertigen können
| Szenario | Architektur | Frontend | Backend | Datenschicht | Infrastruktur und Ops |
|---|---|---|---|---|---|
| B2B-SaaS-MVP | Modularer Monolith | Next.js, TypeScript | Node.js, TypeScript mit einem reifen Web-Framework | PostgreSQL primär, Redis-Cache | Containerisiert, verwalteter Container-Service, GitHub Actions, OpenTelemetry |
| Enterprise-Plattform | Modularer Monolith, entwickelt sich zu Services | React oder Angular | Java oder Kotlin mit Spring Boot | PostgreSQL, Kafka für asynchrone Events, Elasticsearch für Suche | Kubernetes, Terraform, GitLab CI, zentralisierte Observability |
| Echtzeit-Datenprodukt | Ereignisgesteuerte Microservices | Schlankes SPA oder SvelteKit | Go-Services für Ingestion, Python für Analytics-Jobs | Kafka Streams, ClickHouse für Analytics, Redis für schnelle Reads | Kubernetes oder Serverless für Ingestion, IaC, Autoscaling |
| Mobile-First-Consumer-App | API plus Edge Caching | React Native oder Flutter App, SSR-Website für Marketing | Node.js oder .NET für APIs | PostgreSQL, Object Storage für Medien, CDN Edge Caching | Serverless APIs plus verwaltete DB, CI für Mobile-Builds |
Betrachten Sie diese als Ausgangspunkte. Bewerten Sie mit Ihren Gewichtungen, bevor Sie sich festlegen.
Einen schmalen vertikalen Schnitt durchführen, um Risiken zu reduzieren
Bauen Sie einen schmalen, End-to-End-Schnitt, der eine echte Nutzerreise abbildet und die schwierigen Teile misst.
- Implementieren Sie einen kritischen Nutzerflow mit dem vorgeschlagenen Stack, inklusive Auth, Datenschreibvorgängen, Caching und Observability.
- Führen Sie Lasttests durch, die erwarteten Traffic und Datenwachstum simulieren.
- Validieren Sie die lokale Entwicklererfahrung, Testausführungszeit und Deploy-Zeit.
- Vergleichen Sie gemessene Ergebnisse mit Ihren nicht-funktionalen Anforderungen und der Scorecard.
Wenn die Ziele verfehlt werden oder die Entwicklererfahrung schlecht ist, passen Sie jetzt an. Das ist günstiger als späteres Refactoring im großen Maßstab.
Warnsignale, die auf Stack-Probleme hindeuten
- Ein Tool wählen, weil es neu oder beliebt ist, ohne messbaren Vorteil für Ihren Anwendungsfall.
- Übermäßige Microservices vor dem Product-Market-Fit oder bevor Sie starkes Platform Engineering haben.
- Mehrere Sprachen und Runtimes für ähnliche Services, die Expertise und Tooling fragmentieren.
- Kein Upgrade-Pfad oder langfristiger Wartungsplan für wichtige Abhängigkeiten.
- Observability ignorieren, bis Produktionsausfälle sie erzwingen.
Schnelle Checkliste vor der Finalisierung
- Der Stack stimmt mit Geschäftszielen, SLOs und Compliance-Anforderungen überein.
- Sie können Entwickler innerhalb Ihres Zeitrahmens dafür einstellen und einarbeiten.
- Es gibt einen klaren Migrations- oder Upgrade-Pfad für die nächsten zwei Jahre.
- Sie haben Observability, Security-Scanning und CI ab dem ersten Sprint eingerichtet.
- Ein schmaler vertikaler Schnitt hat die Baseline-Ziele für Performance und Zuverlässigkeit erreicht.
Wie Wolf-Tech helfen kann
Wolf-Tech hat seit über 18 Jahren Produkte über moderne Tech Stacks hinweg ausgeliefert und skaliert. Ob Sie eine zweite Meinung zu Ihrer Scorecard benötigen, einen schnellen Proof of Concept oder Hilfe bei der Härtung Ihres CI, Ihrer Sicherheit und Infrastruktur – unser Team bringt Full-Stack-Entwicklung, Code-Qualitätsberatung, Legacy-Optimierung und Cloud-Expertise in Ihre Entscheidung ein. Starten Sie ein Gespräch bei Wolf-Tech, um Ihre Stack-Entscheidungen abzusichern und die Auslieferung zu beschleunigen.