
Next.js Best Practices für skalierbare Apps


Hochfrequentierte Next.js-Apps skalieren nicht allein durch Infrastruktur. Sie skalieren, weil Architektur, Rendering-Strategie, Datenschicht und Observability gemeinsam konzipiert werden. Dieser Leitfaden fasst die wichtigsten Best Practices zusammen, die wir in Produktionssystemen einsetzen, damit skalierbare Apps entstehen, Ihre Teams jetzt schnell ausliefern und die Performance beim Wachstum vorhersagbar bleibt.
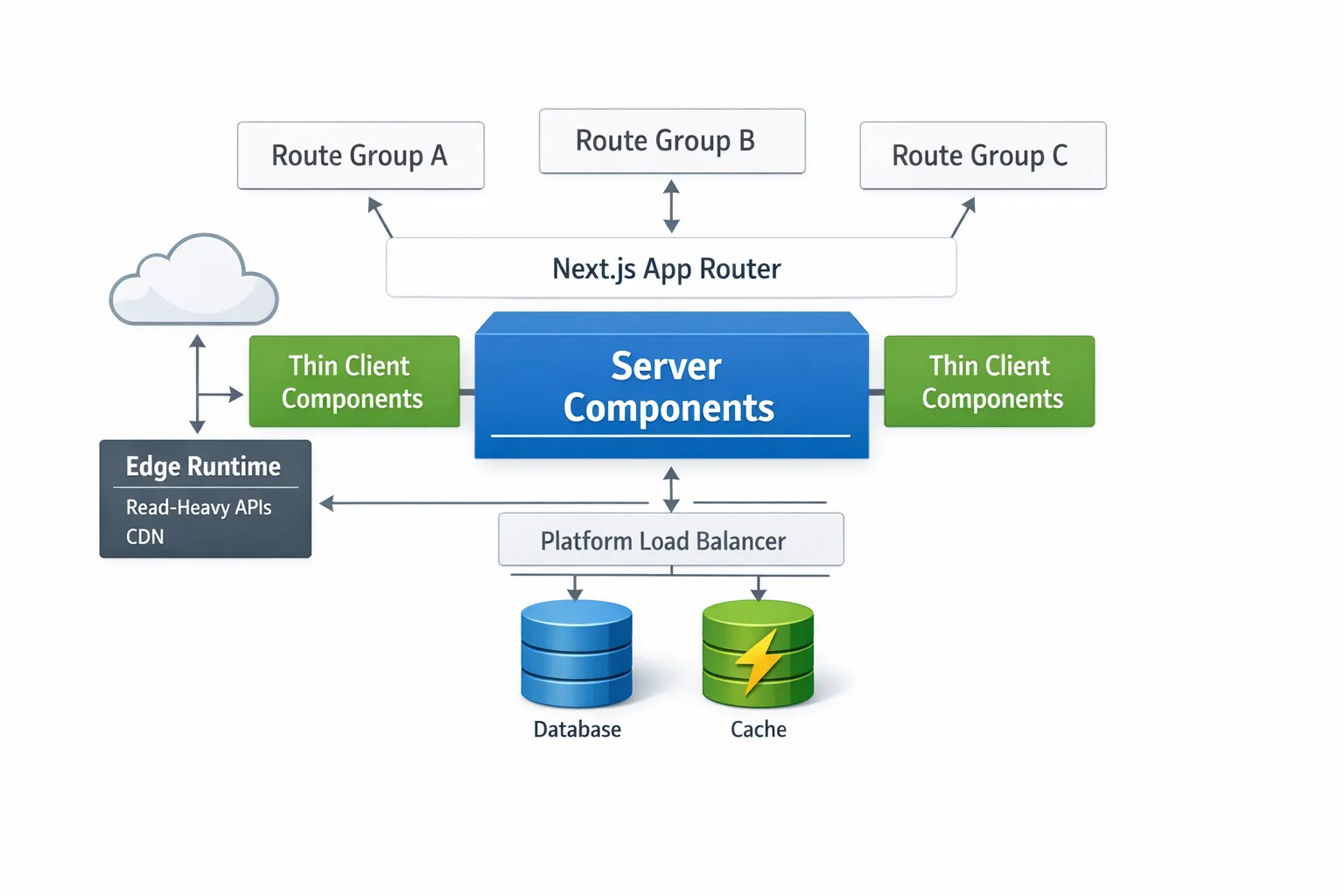
Die Architektur von Anfang an auf Skalierung auslegen
Next.js lenkt Sie in Richtung App Router und React Server Components – und genau das ist der richtige Ansatz für Skalierung.
- Standardmäßig Server Components verwenden. Der Großteil der UI kann auf dem Server gerendert werden, was die Bundle-Größe reduziert und die Time to Interactive verbessert.
- Client Components schlank halten. Verwenden Sie die
use client-Direktive nur, wenn Sie tatsächlich Interaktivität, Browser-APIs oder lokalen State benötigen. - Ihre App mit Route Groups und klaren Modulgrenzen modellieren. Behandeln Sie jedes Segment wie ein Feature-Modul, um Abhängigkeiten einzudämmen und Shared-State-Kopplung zu vermeiden.
Beispiel einer modularen Ordnerstruktur, die mit Teams skaliert:
app/
layout.tsx
(marketing)/
page.tsx
(app)/
dashboard/
page.tsx
analytics/
page.tsx
settings/
page.tsx
api/
products/route.ts
lib/
db/
services/
validations/
Referenz: Machen Sie sich mit dem modernen App Router vertraut, bevor Sie Ihre Struktur festlegen – siehe die Next.js App Router Docs.
Die richtige Rendering- und Caching-Strategie pro Route wählen
Eine Einheitslösung gibt es nie. Weisen Sie einen Rendering-Modus basierend auf Datenvolatilität und UX-Erwartungen zu und dokumentieren Sie diese Entscheidung im Code. Nutzen Sie export const dynamic, revalidate und Fetch-Cache-Optionen, um die Wahl in jeder Route festzuschreiben.
| Strategie | Geeignet für | Skalierungsvorteil | Achtung |
|---|---|---|---|
| Static Generation | Marketing-Seiten, Docs, Preise, die sich selten ändern | Null Serverkosten bei Hit, maximale CDN-Auslagerung | Build-Größe und Rebuild-Zeit, Invalidierung planen |
| Incremental Static Regeneration | Kataloge, Blogs, Dashboards mit tolerierbarer Aktualität | Effizientes Refresh, vermeidet vollständige Rebuilds | Realistische revalidate-Intervalle und Invalidierungs-Tags |
| Streaming SSR | Personalisierte oder datenintensive Ansichten | Schnellerer First Paint mit progressiver Hydration | Erfordert sorgfältige Suspense-Boundaries und Loading States |
| Client-side Rendering | Hochinteraktive, nutzerspezifische Widgets | Verlagert Rechenleistung in den Browser | Größere Bundles, langsamer auf schwachen Geräten |
| Edge Runtime | Leseintensive APIs, geo-sensitiver Content | Geringere Latenz und globale Skalierung | HTTP-basierte DB oder Caches bevorzugen, hohe CPU vermeiden |
Vertiefung zu Caching-Kontrollen: Next.js Caching Docs.
Data Fetching und Mutationen als erstklassiges Design behandeln
- Fetch-Semantik standardisieren. Spezifizieren Sie immer Caching und Revalidierung, damit das Laufzeitverhalten explizit ist.
- Tag-basierte Invalidierung für präzise Kontrolle über Routes und Components nutzen.
- Server Actions für Mutationen bevorzugen, die Daten aktualisieren und Caches in einem Schritt invalidieren – die Logik bleibt auf dem Server.
Beispiel: Fetch mit Tags und Revalidierung über eine Server Action
// app/products/page.tsx
import { revalidateTag } from 'next/cache';
export default async function ProductsPage() {
const products = await fetch('https://api.example.com/products', {
next: { revalidate: 60, tags: ['products'] },
}).then(r => r.json());
return (
<ul>{products.map(p => <li key={p.id}>{p.name}</li>)}</ul>
);
}
// app/products/actions.ts
export async function updateProduct(id: string, payload: unknown) {
'use server';
// ...Mutation gegen Ihre API oder DB ausführen
revalidateTag('products');
}
Timeouts hinzufügen, damit ein langsamer Upstream Ihr Rendering nicht blockiert:
await fetch(url, { signal: AbortSignal.timeout(5000), cache: 'no-store' })
Für In-App-APIs, die andere Services konsumieren, implementieren Sie Route Handlers mit strikter Validierung und vorhersagbaren Statuscodes. Siehe Route Handlers.
Für Performance optimieren, bevor Sie Server hinzufügen
- Client-Bundles klein halten. Begrenzen Sie
use client, bevorzugen Sie Server Components und vermeiden Sie, Umgebungsvariablen an den Client weiterzugeben. - Schwere, nicht-kritische UI dynamisch importieren.
import dynamic from 'next/dynamic'
const HeavyChart = dynamic(() => import('./HeavyChart'), { ssr: false })
- Lang laufende Abschnitte mit Suspense streamen, um die gefühlte Geschwindigkeit zu verbessern. Beginnen Sie das Rendering so früh wie möglich und enthüllen Sie späte Daten progressiv.
- Bilder und Medien optimieren. Verwenden Sie
next/image, setzen Sie akkuratesizesund bevorzugen Sie moderne Formate. Siehe Image Optimization. - Third-Party-Skripte verantwortungsvoll laden. Nutzen Sie
next/scriptmitstrategy="afterInteractive"oderlazyOnloadund messen Sie die Kosten jedes Skripts. - Performance-Budgets einführen. Tracken Sie Bundle-Größe, LCP, INP und CLS bei jedem PR und blockieren Sie Merges, wenn Budgets überschritten werden. Lernen Sie die Metriken unter Core Web Vitals.
Die richtige Runtime pro Route wählen
Next.js ermöglicht es Ihnen, pro Route zwischen Node.js und Edge zu wählen, passend zum Workload.
- Edge Runtime ist ideal für cachbare Reads, geo-spezifischen Content, Feature Flags und latenzarme Personalisierung.
- Node.js Runtime passt für rechenintensive Aufgaben, große Abhängigkeiten oder Treiber, die Node-APIs benötigen.
// app/api/geo/route.ts
export const runtime = 'edge' // oder 'nodejs'
Wenn Sie am Edge laufen, bevorzugen Sie HTTP-gesteuerte Datenbanken oder Caches. Wenn Sie auf Node.js laufen, nutzen Sie Connection Pooling und vermeiden Sie es, bei jedem Request neue Verbindungen zu öffnen. Erstellen Sie eine einzelne DB-Client-Instanz pro Prozess und verwenden Sie sie über alle Handler hinweg.
Zuverlässigkeit durch Instrumentierung und Leitplanken stärken
- Tracing und Logs hinzufügen. Verwenden Sie OpenTelemetry, um Server-Arbeit zu instrumentieren, und exportieren Sie Traces an Ihr APM Ihrer Wahl. Beginnen Sie mit Request-IDs und Span-Boundaries für Fetches und DB-Aufrufe. Das OpenTelemetry-Projekt hat einen soliden Einstiegsleitfaden – siehe die OpenTelemetry Docs.
- Business-KPIs als Metriken exponieren. Tracken Sie Cache-Hit-Rate, ISR-Revalidierungs-Zähler und Queue-Backlogs – nicht nur CPU und Speicher.
- Backpressure in jede Integration einbauen. Timeouts, Retries mit Jitter und Circuit Breaker verhindern kaskadierende Ausfälle.
- Graceful Degradation umsetzen. Stellen Sie Skeletons und gecachte Fallbacks bereit, wenn Live-Daten nicht verfügbar sind.
Sicherheit, die mit dem Traffic skaliert
- Eine strikte Content Security Policy durchsetzen und Script-Origins einschränken. Bevorzugen Sie
nonceodersha256für Inline-Skripte, wenn nötig. - Secrets serverseitig halten. Exponieren Sie nur Werte mit dem
NEXT_PUBLIC_-Präfix, wenn sie für Clients unbedenklich sind. - Jeden Input am Edge validieren. Verwenden Sie einen Schema-Validator in Route Handlers und Server Actions.
- Sichere Cookies mit
HttpOnly-,Secure- undSameSite-Attributen setzen. Vermeiden Sie localStorage für sensible Tokens. - Öffentliche Endpoints rate-limitieren und Missbrauchserkennung in Anmelde- und Registrierungsflows integrieren.
CI/CD, Builds und Environments
- Builds und Tests cachen. Monorepos mit Turborepo oder einem ähnlichen System reduzieren redundante Arbeit und beschleunigen Feedback.
- Smoke- und E2E-Tests gegen kurzlebige Preview-Environments für jeden PR ausführen.
- Routes und APIs explizit versionieren. Alte Versionen mit Telemetrie deprecaten, nicht mit Vermutungen.
- Environment-Konfigurationen klar trennen. Produktion unveränderlich halten und Release Candidates unter realistischem Traffic und Daten testen.
Datenschicht-Patterns für Skalierung
- Einen Read-Cache einführen. Platzieren Sie Redis oder einen verwalteten Key-Value-Store vor Ihrer Primärdatenbank für leseintensive Abfragen.
- Tag-basierte Invalidierung end-to-end nutzen. Route-Segmente, Fetch-Aufrufe und Caches sollten dieselben Tags teilen, um veraltete Reads zu vermeiden.
- Responses normalisieren und Mapper zentral in
lib/halten. Halten Sie rohe Adapter-Logik getrennt von UI-Komponenten. - Requests wo möglich batchen oder per-Request mit Memoization cachen, damit wiederholte Server-Aufrufe im selben Render zusammengefasst werden.
Migrationshinweise für Teams, die vom Pages Router wechseln
Übernehmen Sie den App Router inkrementell. Beginnen Sie mit Leaf-Routes, die am meisten von Server Components und Streaming profitieren. Halten Sie das Verhalten identisch, um Scope Creep zu vermeiden, und deaktivieren Sie Legacy-Seiten erst, wenn Sie Features migriert haben. Die Next.js App Router Docs enthalten Patterns, die gemischtes Routing während der Transition ermöglichen.
Eine schnelle, praktische Checkliste
- Jede Route deklariert ihren Rendering-Modus und ihre Cache-Policy.
- Server Components als Standard, Client Components sind Opt-in und klein.
- Lange Operationen streamen hinter Suspense mit nützlichen Skeletons.
fetch-Aufrufe haben Timeouts, Retries und Tags für Invalidierung.- Mutationen nutzen Server Actions oder typisierte Route Handlers mit Validierung.
- Bilder verwenden
next/imagemit korrektensizesund responsiven Dimensionen. - Third-Party-Skripte werden gemessen, deferred oder entfernt.
- Edge wird für leseintensive und geo-sensitive Endpoints verwendet, Node.js für rechenintensive Aufgaben.
- Observability ist ab Tag eins aktiv, mit Traces und Business-Metriken.
- Security Headers, CSP und Secrets-Management werden in jeder Umgebung durchgesetzt.
Wo Wolf-Tech helfen kann
Skalierung dreht sich nicht nur um Einstellungen in next.config.js. Es geht darum, die richtigen architektonischen Entscheidungen zu treffen, bevor der Code wächst, und diese Entscheidungen durch Tooling, Tests und CI durchzusetzen. Wenn Sie einen erfahrenen Partner suchen, der Ihre Architektur reviewt, Performance-Budgets etabliert oder kritische Features mitentwickelt, kann unser Team helfen.
- Architektur- und Codequalitäts-Audits für Next.js
- Rendering- und Caching-Strategie-Design
- Legacy-Modernisierung in den App Router
- Cloud-, Datenbank- und CI/CD-Grundlagen für Skalierung
Sprechen Sie mit uns bei Wolf-Tech. Wir bringen Full-Stack-Expertise, Cloud- und DevOps-Erfahrung und einen pragmatischen Ansatz für den Aufbau nachhaltiger Systeme mit.
Weiterführende Lektüre direkt von der Quelle:
- Next.js App Router Docs
- Caching und Revalidation
- Route Handlers
- Edge und Node.js Runtimes
- Image Optimization
- Core Web Vitals
- OpenTelemetry Docs