
Infrastruktur-Automatisierung: Von Skripten zu IaC


Infrastruktur-Automatisierung bedeutete früher einen Ordner mit Shell-Skripten, ein paar README-Dateien und jemanden im Team, der „einfach weiß", wie man Umgebungen wieder zum Laufen bringt. Dieser Ansatz kann funktionieren – bis er es nicht mehr tut. Sobald Systeme über mehrere Cloud-Accounts, Regionen, Umgebungen und Compliance-Anforderungen hinweg wachsen, werden manuelle Schritte und Einmal-Skripte zu einem Zuverlässigkeits- und Sicherheitsrisiko.
Die moderne Antwort lautet nicht „mehr Skripte". Sie ist eine Entwicklung hin zu Infrastructure as Code (IaC) und verwandten Praktiken (Policy as Code, GitOps, automatisiertes Testen), die Infrastruktur reproduzierbar, reviewbar und im großen Maßstab betreibbar machen.
Was „Infrastruktur-Automatisierung" tatsächlich umfasst
Infrastruktur-Automatisierung ist mehr als die Bereitstellung von Servern. Sie umfasst jeden wiederholbaren, maschinell gesteuerten Prozess, der Infrastruktur und ihre Betriebskonfiguration erstellt, ändert, validiert oder repariert.
Beispiele:
- Bereitstellung von Cloud-Ressourcen (Netzwerke, Cluster, Datenbanken, Queues)
- Konfiguration von Workloads (Runtime-Einstellungen, Systempakete, Service-Konfigs)
- Sichere Auslieferung von Änderungen (Pipelines, Canaries, Rollbacks)
- Durchsetzung von Sicherheits- und Compliance-Kontrollen (Guardrails, Policies)
- Erkennung und Korrektur von Drift (die reale Welt weicht vom Soll-Zustand ab)
Wenn Sie eine prägnante Basisdefinition für die Abstimmung mit Stakeholdern brauchen, ist dieser Glossareintrag zu Automation (Definition und Beispiele) eine nützliche Referenz, um das Konzept jenseits reinen DevOps-Toolings zu fassen.
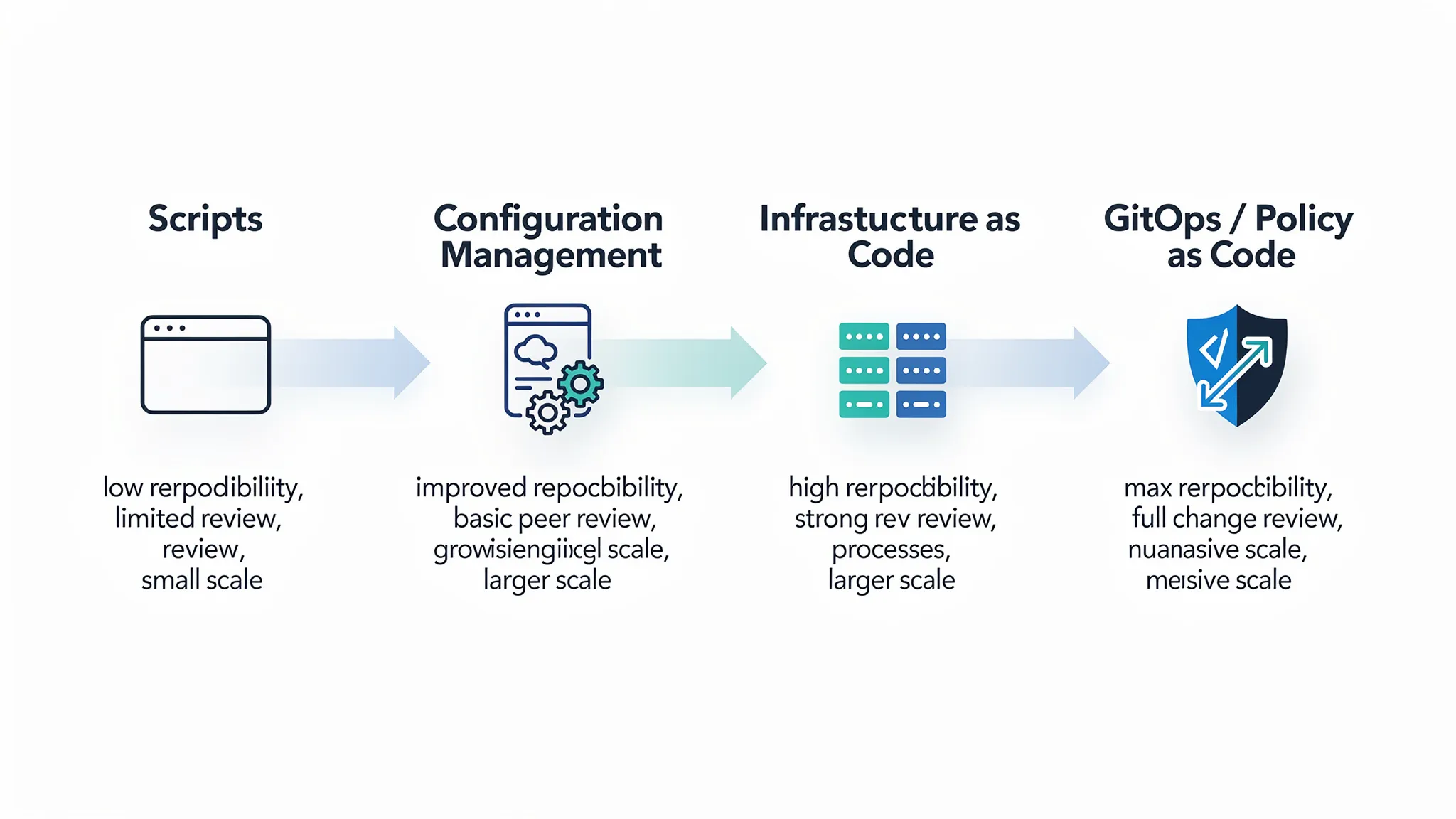
Die Evolution: von Skripten zu IaC (und warum es zählt)
Teams kommen meist erst dann zu IaC, wenn sie den Schmerz skriptbasierter Operationen erlebt haben. Wenn Sie die Trade-offs verstehen, modernisieren Sie, ohne dass es zu einer Glaubensdebatte wird.
Phase 1: Skripte (schneller Start, schwer skalierbar)
Wie es aussieht: Bash-Skripte, PowerShell, ad-hoc SSH, Cloud-CLI-Snippets, „Runbook-getriebene" Operationen.
Warum Teams das mögen:
- Niedrige Einstiegshürde
- Schnelle Erfolge bei wiederkehrenden Aufgaben
- Funktioniert gut für kleine Systeme oder temporäre Umgebungen
Wo es zusammenbricht:
- Versteckter Zustand: Skripte gehen oft von der aktuellen Realität aus (was existiert, wie es heißt, welche Credentials funktionieren)
- Nicht-idempotente Änderungen: Zweimaliges Ausführen führt nicht unbedingt zum gleichen Ergebnis
- Begrenzte Reviewbarkeit: Diffs sind unklar (was hat sich geändert, und warum)
- Abhängigkeit von Stammeswissen: Operative Qualität hängt von einzelnen Personen ab
Skripte sind nicht „schlecht". Sie reichen nur selten aus, sobald das System geschäftskritisch wird.
Phase 2: Configuration Management und Templating (Wiederholbarkeit für Hosts)
Wie es aussieht: Ansible, Chef, Puppet, Salt, plus Templating-Systeme und Image-Baking (zum Beispiel Packer).
Diese Phase verbessert die Konsistenz für Server-Konfiguration und Anwendungs-Runtime-Abhängigkeiten. Sie wird oft mit „Golden Images" kombiniert, um Bootstrapping-Zeit und Konfigurations-Drift zu reduzieren.
Häufige Einschränkung: Configuration-Management-Tools sind exzellent darin, Maschinenzustand zu konvergieren, aber sie sind nicht immer die beste Wahl für die Bereitstellung von Cloud-Primitives (VPCs, IAM-Policies, Managed Databases), wo deklarative Ressourcengraphen und Lifecycle-Kontrollen wichtig sind.
Phase 3: Infrastructure as Code (deklarative Infrastruktur)
Wie es aussieht: Terraform/OpenTofu, AWS CloudFormation, Azure Bicep, Pulumi, Kubernetes-Manifeste und verwandtes Tooling.
IaC verschiebt das Denkmodell von „Schritte ausführen" zu „Soll-Zustand beschreiben". Das Tool berechnet, was geändert werden muss, und wendet es vorhersehbar an.
Schlüsselideen, die IaC von Skripten unterscheiden:
- Deklarative Absicht: Sie definieren, was existieren soll, nicht wie man sich durchklickt
- Plan und Diff: Sie können Änderungen vorab betrachten
- Idempotenz: Mehrmaliges Anwenden derselben Konfiguration sollte zum gleichen Ergebnis konvergieren
- Abhängigkeitsgraph: Ressourcen werden in kontrollierter Reihenfolge erstellt/geändert
Phase 4: GitOps und Policy as Code (Betrieb im großen Maßstab)
Sobald Infrastruktur Code ist, wird der nächste Engpass Governance und sichere Änderungsauslieferung.
Zwei Praktiken erweitern IaC häufig:
- Policy as Code: Guardrails, die unsichere oder nicht-konforme Änderungen verhindern (zum Beispiel das Blockieren öffentlicher Storage-Buckets oder zu permissiver IAM)
- GitOps: Git wird zur Single Source of Truth, und automatisierte Agents reconcilen die laufende Umgebung mit dem in der Versionskontrolle Genehmigten
IaC ist das Fundament, aber Governance und Betrieb machen es nachhaltig.
Skripte vs. IaC: ein praktischer Vergleich
Beides hat seinen Platz. Der Trick ist, jeden Ansatz dort einzusetzen, wo er passt.
| Ansatz | Geeignet für | Stärken | Typische Fehlermodi |
|---|---|---|---|
| Skripte (CLI, Bash, PowerShell) | Einmalige Aufgaben, Migrationen, Notfall-Fixes, Glue-Logik | Schnell zu schreiben, leicht anpassbar | Nicht-idempotente Änderungen, unklare Diffs, fragile Annahmen, schwer auditierbar |
| Config Management (Ansible/Chef/Puppet) | Host-Konfiguration, Paket-/Service-Konvergenz, Standard-Baselines | Starkes Konvergenzmodell, wiederholbares Setup | Kann zu „macht alles" verkommen, schwächeres Lifecycle-Management für Cloud-Ressourcen |
| IaC (Terraform/CloudFormation/Bicep/Pulumi) | Cloud-Ressourcen-Lifecycle, Umgebungen, wiederverwendbare Infrastruktur-Module | Plan/Apply, Abhängigkeitsgraph, reviewbare Änderungen | State/Drift-Probleme, großer Wirkungsradius bei fehlender Modularisierung |
| GitOps + Policy as Code | Multi-Team-Governance, Compliance bei Tempo, kontinuierliche Reconciliation | Starke Auditierbarkeit, automatisierte Durchsetzung | Zu rigide bei schlechtem Governance-Design, laute Policies, langsame Genehmigungen |
Wie „gutes" IaC in echten Teams aussieht
Infrastruktur-Automatisierung scheitert am häufigsten daran, dass Teams Muster kopieren, ohne die unterstützende Engineering-Disziplin aufzubauen. Eine robuste IaC-Praxis hat meist diese Merkmale.
1) Versionskontrolle ist die Single Source of Truth
Jede Änderung geht denselben Weg:
- Pull Request
- Review (inklusive Sicherheits- und Plattform-Aspekte)
- Automatisierte Checks
- Kontrollierte Promotion in Umgebungen
Das ist weniger Prozesstheater als das Schaffen eines auditierbaren, wiederholbaren Workflows.
2) Kleiner Wirkungsradius by Design
Wenn „Apply" versehentlich die Produktion lahmlegen kann, vermeiden Teams Automatisierung und kehren zu manuellen Änderungen zurück.
Praktische Techniken zur Reduzierung des Wirkungsradius:
- Modularisieren entlang Domänengrenzen (Networking, IAM, Daten, Runtime-Plattform)
- Separater State für unabhängige Komponenten
- Umgebungsisolation nutzen (separate Accounts/Subscriptions/Projekte, wo angemessen)
- Additive Änderungen und sichere Migrationen vor destruktiven Ersetzungen bevorzugen
3) Tests existieren, auch wenn sie schlank sind
Infrastruktur-Änderungen verdienen Tests, aber sie müssen am ersten Tag nicht perfekt sein.
Beispiele für hochwirksame Checks:
- Formatierung und Linting
- Policy-Checks (Sicherheits-Baselines)
- „Plan" in CI, um unerwartete Diffs zu erkennen
- Smoke-Tests nach Apply (Konnektivität, Health-Checks, Berechtigungen)
4) Secrets und Identität sind kein Nachgedanke
Die meisten Produktionsvorfälle in „automatisierter Infrastruktur" werden nicht durch Tools verursacht – sie werden durch schlechte Credential- und Berechtigungspraktiken verursacht.
Basis-Erwartungen:
- Keine langlebigen Secrets in Repositories
- Klare Trennung zwischen menschlichen und Workload-Identitäten
- Least-Privilege-IAM mit reviewbaren Policy-Änderungen
- Rotationen und einsatzbereite Revocation-Verfahren
5) Drift wird gemessen und behandelt
Drift ist in der Realität unvermeidlich (Hotfixes, Konsolen-Änderungen, Incident-Aktionen). Reife Teams erkennen ihn und haben eine Reaktionspolitik.
Übliche Optionen:
- Bei Drift alarmieren und Änderungen über PRs erzwingen
- Temporären Drift mit explizitem Ablauf erlauben (dokumentierte Ausnahmen)
- Drift für bestimmte Ressourcenkategorien automatisch reconcilen
Das fehlende Stück: State Management (und warum IaC-Projekte scheitern)
Wenn Sie Terraform oder ähnliche Tools einführen, wird State zentral. State beantwortet: „Was glaubt das Tool, dass existiert?"
Wenn State Management schwach ist, sehen Sie:
- Konflikte zwischen Teams (zwei Pipelines, die dieselben Ressourcen verwalten)
- Überraschende Löschungen oder Ersetzungen
- Unfähigkeit, bestehende Infrastruktur sicher zu importieren
- Lähmende Angst,
applyauszuführen
Praktische Hinweise, die meist funktionieren:
- Remote, gelockten State verwenden (keine lokalen Dateien)
- State nach Komponente und Umgebung aufteilen
- Kontrollieren, wer Änderungen anwenden darf, und wie
- State-Moves und Imports als produktionsreife Operationen mit Peer-Review behandeln
Ein Migrationspfad: von Skripten zu IaC, ohne die Auslieferung zu stoppen
Die meisten Organisationen können die Auslieferung nicht für ein „großes IaC-Rewrite" einfrieren. Der sicherere Ansatz ist inkrementell.
Mit einer Bestandsaufnahme und klaren Grenzen beginnen
Bevor Sie Tools auswählen, kartieren Sie:
- Was Sie haben (Accounts, Netzwerke, Cluster, Datenbanken)
- Wer was besitzt (Teams, Domänen)
- Was sich am häufigsten ändert (die besten ersten Automatisierungs-Ziele)
- Was das höchste Risiko trägt (wo Guardrails am wichtigsten sind)
Das ist auch der Punkt, an dem Sie entscheiden, ob Sie ein Plattform-Team, gemeinsam genutzte Module oder ein einfacheres Modell brauchen.
Eine dünne, funktionierende Slice bauen
Eine dünne Slice ist eine kleine End-to-End-Implementierung, die den Workflow beweist – nicht nur die Syntax.
Eine gute dünne Slice umfasst typischerweise:
- Eine Komponente (zum Beispiel die Infrastruktur eines Services oder eine gemeinsame Umgebungs-Fähigkeit)
- Eine Umgebung (zuerst Dev)
- CI, das Checks ausführt und einen Plan erstellt
- Einen kontrollierten Apply-Schritt
- Minimale Dokumentation, damit andere Engineers sie ausführen können
Sobald diese Slice funktioniert, wird das Skalieren zu Engineering – nicht zu Raten.
„Strangler"-Taktiken für Infrastruktur anwenden
Genau wie bei Anwendungs-Modernisierung profitiert Infrastruktur-Modernisierung von Strangler-Mustern:
- Bestehende Ressourcen schrittweise importieren, statt alles neu zu bauen
- Zuerst neue Ressourcen automatisieren, dann bestehende nachziehen
- Manuelle Prozesse einen Workflow nach dem anderen durch Pipelines ersetzen
Das Ziel ist stetige Risikoreduktion bei gleichzeitiger fortgesetzter Auslieferung.
Governance hinzufügen, wenn es weh tut
Zu frühe Governance bremst Teams aus. Zu späte Governance führt zu Cloud-Sprawl und Audit-Versagen.
Ein praktischer Auslöser: Wenn mehrere Teams wöchentlich Änderungen ausliefern, brauchen Sie Policy-Checks, Review-Standards und ein wiederholbares Promotion-Modell.
Tool-Auswahl: Kriterien, die mehr zählen als Markennamen
Die meisten IaC-Tools sind „gut genug". Der Unterschied liegt im Fit zu Ihrem Operating Model.
Hier sind Entscheidungskriterien, die konsequent zählen:
| Kriterium | Worauf zu achten ist | Warum es wichtig ist |
|---|---|---|
| Cloud-Abdeckung | Erstklassige Unterstützung für Ihre Cloud-Ressourcen | Lücken erzwingen brüchige Skripte und Handarbeit |
| Team-Workflow | Starke Diff/Plan-, Review-Flows und Environment Promotion | Hält Änderungen auditierbar und sicher |
| State- und Drift-Modell | Klares State-Handling und Drift-Erkennung | Verhindert „Apply-Angst" und Vorfälle |
| Policy-Integration | Funktioniert mit Policy-as-Code-Tooling und CI | Ermöglicht Guardrails ohne Bürokratie |
| Modularität und Reuse | Module/Komponenten, die zu Ihren Org-Grenzen passen | Reduziert Duplikation und Inkonsistenzen |
| Skill-Abgleich | Passt zu Sprache und Debug-Vorlieben Ihres Teams | Adoption scheitert, wenn niemand es warten kann |
Häufige IaC-Fallstricke (und wie Sie sie vermeiden)
„Ein Repo, sie alle zu beherrschen", das niemand ändern kann
Ein monolithisches Infrastruktur-Repo kann zu einem einzigen Engpass werden.
Streben Sie stattdessen an:
- Klare Verantwortungsgrenzen
- Wiederverwendbare gemeinsame Module (mit Versionierung)
- Separater State für unabhängige Komponenten
Automatisieren ohne Operability
Bereitstellung ist nicht das Ziel. Wenn Ihre Automatisierung Infrastruktur erzeugt, die nicht beobachtet, aktualisiert oder wiederhergestellt werden kann, haben Sie nur zukünftigen Schmerz automatisiert.
Stellen Sie sicher, dass Ihre Baseline Folgendes umfasst:
- Logging und Metriken für zentrale Services
- Backup/Restore- oder Recovery-Verfahren, wo nötig
- Klare SLO-relevante Abhängigkeiten (Datenbanken, Queues, Identität)
Überprivilegierte Automatisierung
Automatisierung läuft oft mit mächtigen Credentials. Sind diese zu weitreichend, haben Sie ein Sicherheitsrisiko mit hoher Wirkung geschaffen.
Ein besserer Ansatz:
- Least Privilege für Pipelines
- Gescoped Roles pro Umgebung
- Manuelle Genehmigungs-Gates nur für wirklich risikoreiche Änderungen
Erfolg messen: was zu verfolgen ist
Infrastruktur-Automatisierung ist erst dann „fertig", wenn sie Ergebnisse verbessert. Metriken helfen Ihnen zu vermeiden, ein schönes System zu bauen, das das Geschäft nicht voranbringt.
Eine praktische Scorecard:
- Provisioning Lead Time: Anfrage bis bereitstehende Umgebung/Ressource
- Change Failure Rate: wie oft Infrastruktur-Änderungen Vorfälle oder Rollbacks verursachen
- MTTR-Beitrag: ob Automatisierung die Wiederherstellungszeit reduziert
- Drift Rate: wie oft die Realität vom Code abweicht
- Kostenvarianz: unerwartete Kostenspitzen nach Infrastruktur-Änderungen
Wenn Sie bereits Delivery- und Reliability-Metriken verfolgen, ergänzen Sie die Infrastruktur-Sicht im selben Dashboard. Ziel ist eine Geschichte, nicht getrennte Berichte.
Häufig gestellte Fragen
Ist Infrastructure as Code nur für Cloud-Infrastruktur? IaC wird am häufigsten für Cloud-Ressourcen eingesetzt, doch die Idee gilt überall, wo Sie einen Soll-Zustand definieren können (On-Premise-Virtualisierung, Kubernetes, Networking, sogar manche SaaS-Konfigurationen). Der Wert kommt aus Versionierung, Reviewbarkeit und Wiederholbarkeit, nicht aus der Cloud selbst.
Brauchen wir nach der IaC-Einführung noch Skripte? Ja. Skripte bleiben nützlich für Glue-Aufgaben, Datenmigrationen und Incident Response. Der Unterschied: Skripte sollten nicht mehr der primäre Mechanismus sein, um langlebige Infrastruktur bereitzustellen und zu steuern.
Was ist der Unterschied zwischen IaC und GitOps? IaC ist die Art, wie Sie Infrastruktur als Code definieren und verwalten. GitOps ist ein Operating Model, in dem Git die Single Source of Truth ist und automatisierte Agents Umgebungen mit den genehmigten Änderungen reconcilen. Sie können IaC ohne GitOps nutzen, aber GitOps macht IaC im großen Maßstab oft sicherer.
Wie verhindern wir, dass IaC zum Engpass für Teams wird? Wirkungsradius reduzieren (modulares Design und separater State), wiederverwendbare Module schaffen, Checks in CI automatisieren und klare Verantwortung definieren. Ziel ist Self-Service mit Guardrails – kein zentrales Team, das jede kleine Änderung absegnen muss.
Was sind die ersten Anzeichen, dass wir Skripten entwachsen sind? Wiederkehrende Inkonsistenzen zwischen Umgebungen, häufige „funktioniert nur im Staging"-Probleme, lange Onboarding-Zeiten, riskante manuelle Änderungen während Vorfällen und Schwierigkeiten beim Bestehen von Audits sind häufige Signale, dass Skripte nicht mehr ausreichen.
Wollen Sie von Ad-hoc-Automatisierung zu skalierbarem IaC wechseln?
Wolf-Tech unterstützt Teams beim Design und der Implementierung von Infrastruktur-Automatisierung, die echte Liefergeschwindigkeit und Zuverlässigkeit ermöglicht – nicht nur einen Tool-Rollout. Wenn Sie Legacy-Umgebungen modernisieren, Governance verschärfen oder ein wiederholbares Wachstumsfundament aufbauen, unterstützen wir mit Tech-Stack-Strategie, Cloud- und DevOps-Expertise sowie hands-on Full-Stack-Lieferung.
Erkunden Sie Wolf-Tech auf wolf-tech.io oder beginnen Sie mit einem praktischen, roadmap-orientierten Beitrag: Application Development Roadmap for Growing Teams.