
Legacy-Systeme modernisieren ohne Betriebsunterbrechung


Geschäftskritische Systeme am Laufen zu halten, während man sie modernisiert, ist möglich, erfordert aber einen Plan, der Kontinuität als erstklassige Anforderung behandelt. Das Ziel ist nicht nur neue Technologie, sondern Fortschritt ohne Ausfälle, verlorene Bestellungen oder beeinträchtigte Kundenerfahrung. Dieser Leitfaden beschreibt die Muster, Rollout-Praktiken und menschlichen Faktoren, mit denen Sie Legacy-Systeme modernisieren können, ohne den Geschäftsbetrieb zu stören.
Definieren Sie zuerst, was "keine Störung" wirklich bedeutet
Bevor Sie Tools oder Muster wählen, übersetzen Sie "keine Störung" in messbare Ziele, gegen die Sie entwerfen und verifizieren können.
- SLOs gekoppelt an Nutzerreisen: zum Beispiel Checkout p95-Latenz unter 400 ms, 99,9 Prozent Verfügbarkeit während der Geschäftszeiten.
- RTO und RPO: die maximal akzeptable Wiederherstellungszeit und der maximale Datenverlust, falls etwas schiefgeht.
- Blackout-Fenster und Spitzenzeiten: Schützen Sie Gehaltsläufe, Quartalsabschlüsse, Einschreibungszeiträume oder Feiertagsverkehr.
- Error-Budget-Policy: Klare Schwellenwerte, die einen Rollback oder eine Pause des Rollouts auslösen.
Wenn es eine gemeinsame Definition des akzeptablen Risikos gibt, können Engineering- und Business-Verantwortliche fundierte Abwägungen treffen.
Prinzipien für risikoarme Modernisierung
- An Nähten trennen, nicht abreissen und ersetzen. Isolieren Sie ersetzbare Fähigkeiten hinter Schnittstellen und verschieben Sie sie einzeln.
- Additive Änderungen bevorzugen. Fügen Sie neue Endpunkte, Schemata und Services hinzu, während die alten intakt bleiben, bis der Traffic vollständig migriert ist.
- Rollback günstig machen. Jede Änderung sollte einen schnellen, umkehrbaren Weg haben.
- Sicherheit kontinuierlich beweisen. Setzen Sie auf automatisierte Tests, Shadow Traffic und Progressive Delivery statt Big-Bang-Umstellungen.
- Zuerst instrumentieren, dann ändern. Observability ist Teil des Migrationsplans, kein nachträglicher Gedanke.
Architekturmuster, die den Betrieb aufrechterhalten
Das Strangler-Fig-Pattern
Umhüllen Sie die Legacy-Anwendung mit einer Fassade, leiten Sie eine Teilmenge der Anfragen an neue Services und ersetzen Sie schrittweise Funktionalität. Martin Fowlers Beschreibung des Strangler Fig Patterns bleibt die Referenz. In der Praxis implementieren Teams die Fassade oft mit einem API Gateway oder einem Edge-Proxy. Beginnen Sie mit einem schmalen, wertschöpfenden Schnitt und erweitern Sie die Routing-Regeln mit wachsendem Vertrauen.
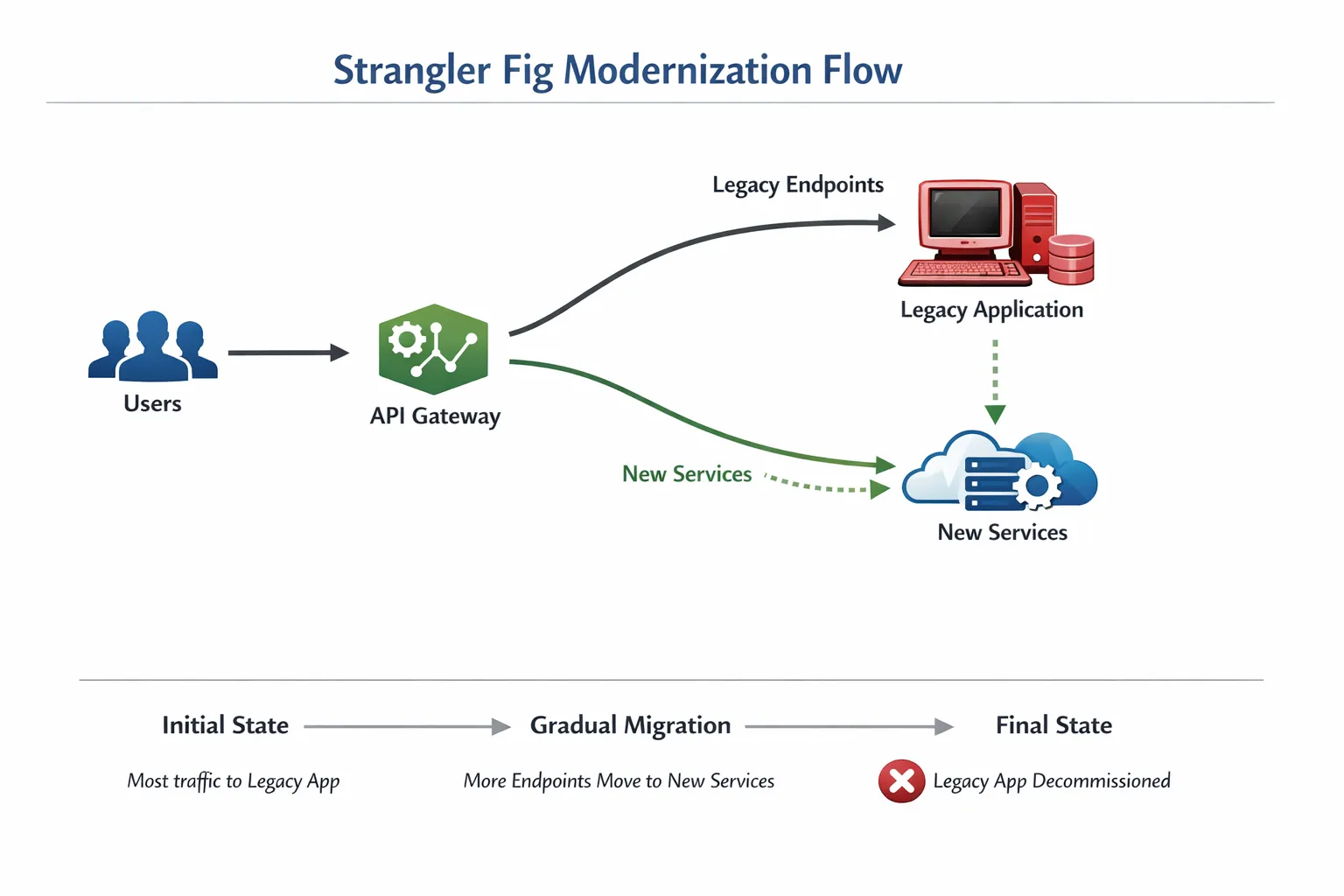
Blü-Green- und Canary-Releases
Halten Sie zwei produktionsbereite Umgebungen vor, Blü und Green, wechseln Sie beim Deploy den Traffic zwischen ihnen und ermöglichen Sie sofortiges Rollback durch Zurückschalten. Fowler dokumentiert auch Blü Green Deployment. Kombinieren Sie dies mit Canary Releases, indem Sie schrittweise 1 Prozent, 5 Prozent, dann 25 Prozent des echten Traffics an die neue Version senden, während Sie Service-Level-Objectives überwachen.
Feature Flags und Progressive Delivery
Feature Toggles ermöglichen es, Code verdeckt zu deployen, bestimmte Features für interne Nutzer zu aktivieren und Rollouts nach Kohorte zu steuern. ThoughtWorks fasst Best Practices für Feature Toggles zusammen. Flags entkoppeln ausserdem Deployments von Releases, was die Mean Time to Recovery verkürzt, weil Sie eine Änderung ohne Re-Deploy deaktivieren können.
Consumer-Driven Contract Testing
Wenn Sie einen Monolithen in Services aufteilen, verlagern sich Ausfälle von Code-Bugs zu Schnittstellen-Inkompatibilitäten. Contract Tests stellen sicher, dass beide Seiten einer Integration sich auf Payloads und Verhalten einigen. Pact ist ein weit verbreitetes Framework dafür. Führen Sie Contract Tests in der CI aus und erzwingen Sie, dass nur Versionen, die die Consumer-Contracts bestehen, in die Produktion gelangen.
Shadow Traffic und Characterization Tests
Senden Sie eine Kopie des Produktions-Traffics an die neue Implementierung, vergleichen Sie die Antworten und gleichen Sie Unterschiede ab, bevor Sie echte Nutzer umschalten. Im Hintergrund nutzen Sie Characterization Tests, um das aktülle Verhalten einschliesslich Randfälle festzuhalten, damit Refactorings keine Ergebnisse ändern, auf die Nutzer sich verlassen.
Für tiefergehende taktische Ratschläge zu Refactoring- und Modernisierungsmechanismen siehe die Wolf-Tech-Leitfäden zu Refactoring Legacy Software und Code Modernization Techniques.
Datenmigration ohne Downtime
Anwendungen sind nur austauschbar, wenn ihre Daten es auch sind. Behandeln Sie Daten als eigenen Arbeitsstrang mit eigenem Sicherheitsnetz.
- Starten Sie mit Read Replicas. Platzieren Sie ein Replikat oder einen Spiegel neben dem neuen Service, um den Blast Radius während des Aufbaus zu reduzieren.
- Bulk-Backfill, dann Deltas streamen. Migrieren Sie historische Datensätze in Batches während schwacher Auslastung, nutzen Sie dann Change Data Capture, um Ziele synchron zu halten. Die Debezium-Dokumentation ist ein solider Einstiegspunkt für CDC-Optionen.
- Dual Writes mit Idempotenz verwenden. Schreiben Sie für eine Übergangszeit in beide Speicher, deduplizieren Sie mit idempotenten Operationen und stabilen Nachrichtenschlüsseln.
- Lesezugriffe zuerst umschalten. Leiten Sie Lesepfade per Flag auf den neuen Speicher, schalten Sie dann Schreibzugriffe um, wenn das Vertrauen hoch ist.
- Kontinuierlich validieren. Vergleichen Sie Zeilenzahlen, Prüfsummen und geschäftliche Invarianten wie Summen und Kontostände. Testen Sie Nutzerreisen stichprobenartig und gleichen Sie Diskrepanzen ab, bevor Sie zum nächsten Schnitt übergehen.
- Parallel Change für Schemata anwenden. Erweitern, migrieren, schrumpfen in drei Schritten, damit Produzenten und Konsumenten während des Übergangs kompatibel bleiben.
Das operationale Rollout-Playbook
Übernehmen Sie Praktiken aus dem Site Reliability Engineering, um jede Änderung in der Produktion langweilig zu machen.
- Pre-Flight: Produktionsähnliches Staging, synthetischer Traffic, Lasttests auf die nächste Potenz des erwarteten Peaks und ein Trockenlauf mit den exakten Release-Schritten.
- Release Gates: Bestehensquoten für Tests und Runbooks, grüne Dashboards, verbleibendes Error Budget und ein expliziter Go-/No-Go-Checkpoint.
- Während des Rollouts: Ein besetzter Kanal, ein verantwortlicher Owner, eine Live-Statusseite und ein Rollback-Verfahren, das in der letzten Woche getestet wurde. Das Google SRE Buch beschreibt praktische Leitplanken.
- Nachsorge: Erhöhtes Monitoring für 24 bis 72 Stunden, Learnings festhalten und Flags abschalten, wenn die Metriken stabil sind.

Governance, Sicherheit und Compliance müssen Sie nicht bremsen
- Leichtgewichtige Change-Advisory-Rituale: Kleine, häufige Änderungen mit vorab vereinbarten Leitplanken und automatisierten Nachweisen sollten Fast-Path-Freigaben erhalten.
- Least Privilege und Secrets-Hygiene: Zugangsdaten rotieren, Blast Radius pro Service isolieren und Audit Trails für jede Produktionsaktion führen.
- Datenschutz: Sensible Daten in niedrigeren Umgebungen maskieren oder tokenisieren und Rechtsgrundlagen sowie Aufbewahrungsregeln während der Migration dokumentieren.
Die menschliche Seite der Modernisierung
Die meisten Modernisierungsvorhaben scheitern an Change-Müdigkeit, nicht an Technologie. Schützen Sie Ihre Teams genauso wie Ihre Systeme.
- Öffentlich kommunizieren: Wöchentliche interne Notizen darüber, was sich geändert hat, was als nächstes kommt und wie man Hilfe anfordern kann.
- Pairing und Cross-Training: Verteilen Sie Legacy-System-Wissen über die wenigen Hüter der Geschichte hinaus.
- In nachhaltigem Tempo arbeiten: Nutzen Sie Release-Fenster, rotieren Sie On-Call und vermeiden Sie langanhaltende Heldentaten.
- Wohlbefinden unterstützen: Fördern Sie Praktiken, die Fokus und Resilienz während langer Transformationen erhalten.
Wie Wolf-Tech Modernisierung ohne Störung liefert
Mit über 18 Jahren Engineering-Erfahrung begleitet Wolf-Tech Sie bei der sicheren Modernisierung, während Ihr Geschäft weiterläuft.
- Full-Stack-Modernisierung und Legacy-Optimierung: Wir identifizieren Nähte, bauen Anti-Corruption-Layer und verschieben kritische Fähigkeiten hinter ein API Gateway.
- Daten- und Integrationsexpertise: Wir planen und führen CDC-basierte Migrationen durch, führen idempotentes Messaging ein und härten Datenbank- und API-Grenzen.
- Cloud- und DevOps-Reife: Wir etablieren Blü-Green- oder Canary-Release-Pipelines, Feature Flagging und produktionsbereite Observability.
- Code-Qualität und Testing: Wir fügen Characterization Tests und Contract Tests hinzu, um jede Änderung verifizierbar zu machen.
- Strategie und Delivery: Wir richten die Roadmap an Ergebnissen und SLOs aus und liefern dann Wert in kurzen, umkehrbaren Inkrementen.
Wenn Sie Stack-Entscheidungen als Teil der Reise evaluieren, kann unser Leitfaden zur Wahl des richtigen Tech Stacks in 2025 helfen, Ihre Entscheidungen in geschäftlichen Begriffen zu rahmen.
Schnelles Entscheidungsframework
Nutzen Sie diese Tabelle, um die richtige Taktik pro Fähigkeit zu wählen. Die besten Programme kombinieren mehrere dieser Ansätze.
| Ansatz | Was es ist | Downtime-Risiko | Wann einsetzen | Hinweise |
|---|---|---|---|---|
| Strangler-Fassade + inkrementeller Ersatz | Ausgewählte Endpunkte an neue Services leiten und mit der Zeit erweitern | Sehr niedrig | Kundenorientierte Flows und APIs | Erfordert solides Routing und Observability |
| UI-Rewrite über Legacy-APIs | Frontend ersetzen, bestehende Backend-Verträge beibehalten | Niedrig bis mittel | Wenn UX der primäre Schmerzpunkt ist und APIs stabil sind | Contract Tests hinzufügen, um API-Verhalten zu sichern |
| Replattformierung (Lift and Shift) | Workloads auf neue Laufzeitumgebung oder Cloud verschieben mit minimaler Codeänderung | Niedrig wenn gut geprobt | Legacy-Infrastruktur am Lebensende, Elastizität oder Zuverlässigkeit schnell nötig | Mit Autoscaling und Managed Services kombinieren |
| Kritischen Service neu architekturieren | Einen Hotspot als separaten, gut abgegrenzten Service neu gestalten | Mittel | Performance- oder Zuverlässigkeitsprobleme sind lokalisiert | Canary und Shadow Traffic nutzen, Daten isolieren |
| Big-Bang-Rewrite | Vollständigen Ersatz bauen vor der Umstellung | Hoch | Selten, nur für kleine Systeme mit geringer Kopplung | Schwer zu validieren und rechtzeitig zurückzurollen |
Ein praktischer 90-Tage-Plan zum Einstieg
- Wochen 1 bis 2, Baseline: SLOs und Error Budgets definieren, kritische Nutzerreisen kartieren, Nähte identifizieren und minimale Observability aufsetzen.
- Wochen 3 bis 6, erster Schnitt: Fassade implementieren, Characterization Tests um die Zielfähigkeit hinzufügen, Daten backfillen und den ersten Canary hinter einem Flag ausliefern.
- Wochen 7 bis 10, erweitern: Traffic stufenweise hochfahren, Contract Tests mit vor- und nachgelagerten Konsumenten hinzufügen und Lesezugriffe auf den neuen Datenspeicher umschalten.
- Wochen 11 bis 12, konsolidieren: Den ersetzten Codepfad ausser Betrieb nehmen, Learnings dokumentieren und den nächsten Schnitt wählen.
Messen Sie wöchentlich, was zählt: Change Failure Rate, Mean Time to Recovery, p95-Latenz für die betroffene Journey, Error Budget Burn und Nutzerzufriedenheit. Das sind die Modernisierungs-KPIs, die das Programm ehrlich halten.
Vorwärts kommen, ohne das Geschäft zu pausieren
Modernisierung ohne Betriebsunterbrechung ist kein Mythos, sondern eine Engineering- und Delivery-Disziplin. Beginnen Sie mit klaren SLOs, fügen Sie Sicherheitsnetze vor Änderungen hinzu, migrieren Sie in dünnen Schnitten und kümmern Sie sich um die Menschen, die die Arbeit leisten. Wenn Sie einen Partner wollen, der das quer durch Stacks und Branchen getan hat, kann Wolf-Tech Ihnen helfen, einen Zero-Downtime-Plan zu entwerfen und Ende-zu-Ende umzusetzen.
Bereit, Ihren sichersten Weg von Legacy-Einschränkungen zu erkunden? Wenden Sie sich an Wolf-Tech für ein Modernisierungs-Readiness-Gespräch und lassen Sie uns Ihnen helfen, mit Zuversicht zu bauen, zu optimieren und zu skalieren.