
GraphQL APIs: Benefits, Pitfalls, and Use Cases


GraphQL has matured from a niche alternative to REST into a pragmatic tool for building adaptable, product-friendly APIs. Teams adopt it to ship features faster, tame sprawling backends, and give clients just the data they need. It is not a silver bullet. Like any architectural choice, GraphQL introduces new operational, security, and caching considerations that you need to plan for.
This guide explains what GraphQL is in practical terms, where it shines, where it can bite, and how to evaluate fit for your roadmap. It also includes implementation tips, migration patterns, and a checklist you can use on day one.
What GraphQL is, in practice
GraphQL is a query language and runtime that exposes a strongly typed schema over a single endpoint. Clients ask for exactly the fields they need and the server resolves those fields from one or more data sources. The schema doubles as documentation and a contract that client and server can evolve with confidence.
If you are new to GraphQL, start with the official learn guide at graphql.org. For transport details, the community maintains a working draft for GraphQL over HTTP, which captures common patterns such as POST and GET requests and persisted operations.
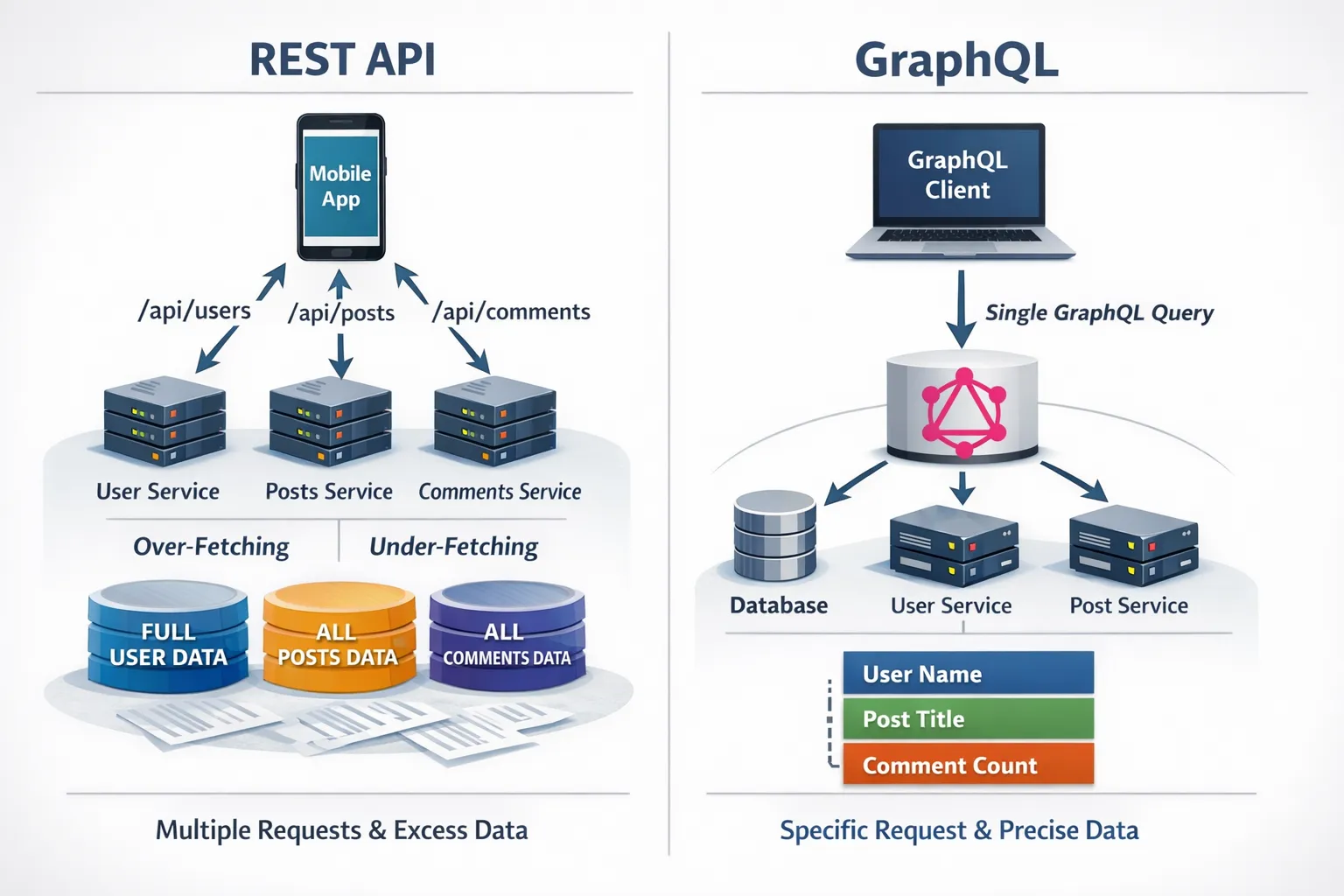
Benefits teams actually feel
Client-driven data, fewer round trips
With GraphQL, clients avoid hard-coded endpoints and shape their own responses. This reduces overfetching and underfetching, which is valuable for mobile networks and complex dashboards.
Strongly typed contracts and faster iteration
The schema is the source of truth. Types, queries, and mutations are clear to both humans and tooling. Introspection enables auto-generated docs, type-safe clients, and CI checks, so front-end and back-end teams move in parallel with fewer breaking changes. See the official best practices for schema and client patterns on GraphQL Best Practices.
A unifying layer over fragmented systems
GraphQL excels as an aggregation layer. You can compose data from legacy services, databases, and third-party APIs without exposing internal topology. It helps teams move toward a product-centric, domain-driven model while modernizing behind the scenes.
Real-time and incremental delivery
GraphQL supports real-time updates with subscriptions over WebSockets, and many servers now support incremental delivery with directives like defer and stream. These patterns unlock responsive UX for live dashboards and collaboration features.
Tooling ecosystem
From GraphiQL explorers to schema registries and code generators, GraphQL’s ecosystem shortens feedback loops. Normalized caches on the client side, for example in Apollo Client or Relay, can make apps feel instant.
Pitfalls and how to mitigate them
| Risk | Why it happens | What to do | Measure to verify |
|---|---|---|---|
| N+1 database calls | Field resolvers fetch per item | Batch and cache per-request with DataLoader or equivalent | P95 resolver latency, number of backend calls per request |
| Expensive queries | Deep or wide selections stress backends | Enforce depth and cost limits, prefer persisted queries, set timeouts | Rejection count for over-limit queries, average query cost |
| Caching is trickier | Single endpoint and variable responses | Use persisted GET for CDN, client normalized cache, resolver-level caching | CDN hit rate, client cache hit rate, backend QPS |
| Authorization leaks | Field-level data requires field-level auth | Centralize auth policies in resolvers or directives, test negative cases | Unauthorized field access attempts, security test pass rate |
| Schema sprawl | Unreviewed additions over time | Domain ownership, schema linting, review gates, deprecations | Lint violations per PR, deprecated field removal rate |
| Federation complexity | Cross-team graph composition | Adopt clear ownership, contracts, and CI for subgraphs | Build success rate, time to merge subgraph changes |
| Error ambiguity | Clients see partial data with vague errors | Standardize error shapes with extensions, doc client handling | Error code coverage, client error handling test pass rate |
| Uploads and binaries | JSON over HTTP is not ideal for large files | Use the community multipart spec or pre-signed URLs | Upload success rate, transfer time, error rate |
Security is foundational. Start with the OWASP API Security Top 10, then apply GraphQL-specific controls like cost limits and operation allow lists.
Key pitfalls explained
-
Performance and the N+1 problem: Because resolvers execute per field, naive implementations trigger excessive backend calls. Adopt a batching layer such as DataLoader to group loads by key within a request. Combine with connection pooling and read replicas.
-
Caching strategy: GraphQL encourages POST requests that CDNs cannot cache by default. For stable queries, use persisted operations and enable GET to leverage edge caching. Pair that with client-side normalized caches and short-lived resolver caches for hot fields.
-
Query cost and denial-of-wallet: Implement query depth, breadth, and complexity limits. Many servers let you define a cost per field so you can reject abusive queries quickly. Persisted queries plus an allow list dramatically reduce risk.
-
Authorization: Authenticate once, authorize often. Apply field-level checks in resolvers or via directives. Avoid relying on introspection toggling for security, treat it only as a convenience setting.
-
Pagination: Favor cursor-based pagination for stability and performance. The Relay Cursor Connections spec is a good baseline even if you do not use Relay.
-
Observability: Instrument resolvers with tracing and metrics so you can see hot fields and slow backends. The OpenTelemetry project provides language SDKs for distributed tracing and metrics, see opentelemetry.io.
-
Uploads: For files, either adopt the widely used GraphQL multipart request spec or use pre-signed URLs to let clients talk to object storage directly.
When GraphQL is a great fit
- Multi-device or bandwidth-sensitive clients that need custom payloads per screen.
- Product surfaces with complex joins across domains, for example marketplace listings, user profiles, and real-time status.
- A backend-for-frontend layer that decouples client teams from microservice churn.
- A modernization façade that unifies legacy services while you incrementally refactor internals.
- Cross-team schema federation where subdomains are owned by separate teams with clear boundaries.
When to skip or defer GraphQL
- Simple CRUD or high-throughput content where CDN-cached REST works perfectly.
- Large binary streaming or media pipelines that suit specialized protocols.
- Extremely latency-sensitive systems where resolver overhead outweighs benefits.
- Teams without the bandwidth to implement cost controls, observability, and governance.
High-value use cases and patterns
| Use case | Pattern | Why GraphQL helps |
|---|---|---|
| Mobile apps with diverse screens | BFF layer per app | Tailor responses per screen, fewer releases to change payloads |
| Analytics dashboards | Schema with computed fields and connections | Compose metrics from multiple data stores with a single query |
| Marketplaces and catalogs | Federated subgraphs for listing, pricing, inventory | Encapsulate domain ownership, resolve references at the gateway |
| Customer 360 view | Aggregation over CRM, billing, support | Hide backend fragmentation, deliver consistent types |
| SaaS integrations hub | Unified schema over third-party APIs | Normalize models, apply consistent auth and rate limits |
| Legacy modernization | Strangler façade | Keep the schema stable while migrating service by service |
For cross-team graphs, Apollo’s documentation on Federation is a useful reference for concepts like subgraphs and composition.
Architecture and implementation options
-
Server frameworks: There are mature libraries across ecosystems. Explore the language-specific options on the official GraphQL Code page. Choose a stack your team can support in production.
-
Schema-first vs code-first: Schema-first makes contracts explicit and is easy to review. Code-first can reduce boilerplate and stay close to types in strongly typed languages. Many teams mix approaches.
-
Transport and operations: Follow the GraphQL over HTTP draft to standardize behavior. Consider Automatic Persisted Queries to reduce payload sizes and enable CDN caching, see APQ.
-
Federation vs monolith schema: Start with a well-factored monolithic schema to avoid premature complexity. Adopt federation when you have clear team boundaries, operational maturity, and a need to scale ownership.
-
Real time: Use subscriptions over WebSockets for push updates. For resource-constrained environments, Server-Sent Events can be a simpler alternative.
-
Deployments: GraphQL servers run well in containers and serverless environments. For serverless, monitor cold starts and warm critical functions. Some teams place a lightweight GraphQL gateway at the edge for routing and caching while keeping resolvers in the core region.
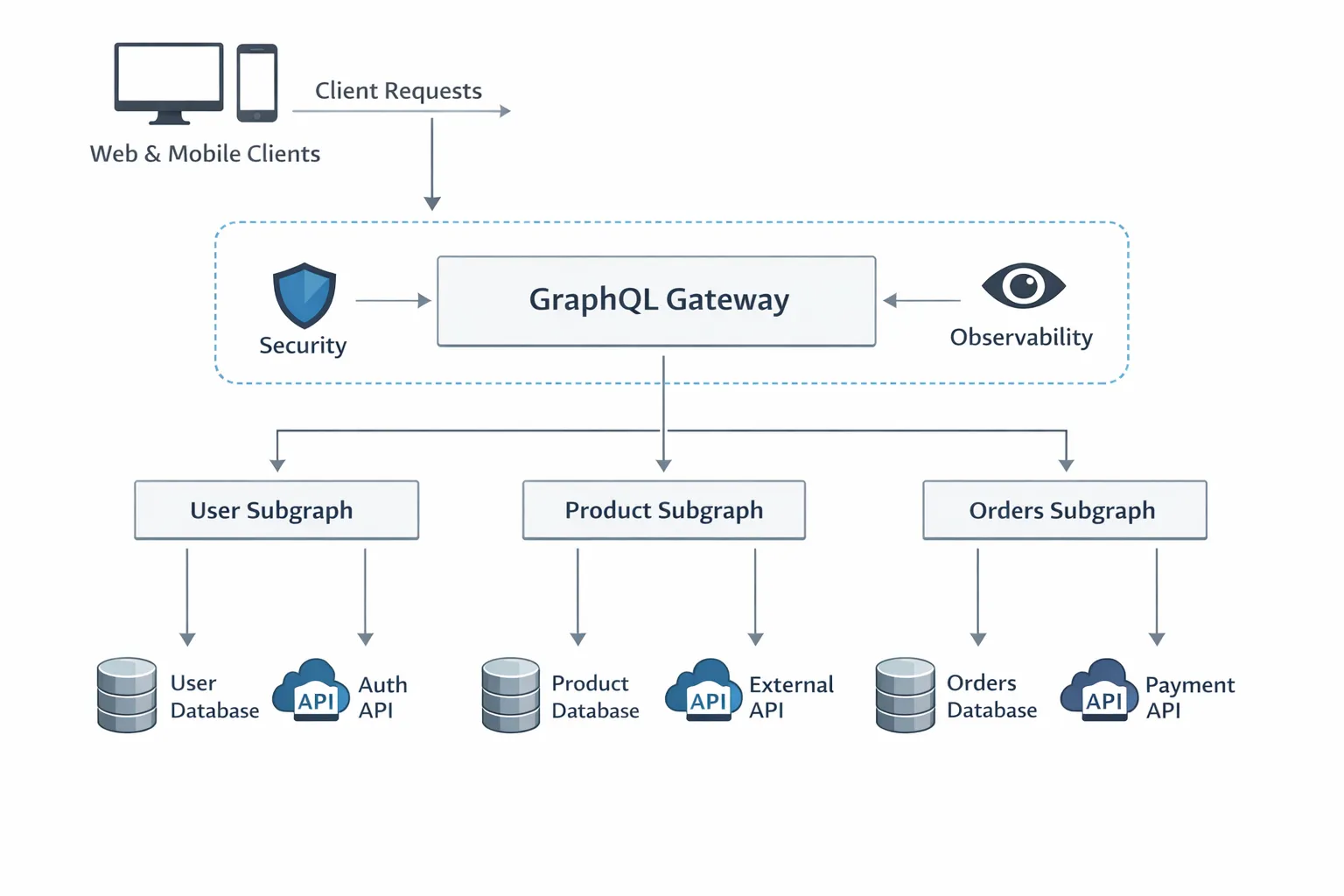
A pragmatic migration plan from REST
- Pick one high-value read use case. Define success criteria such as improved P95 latency, fewer client requests per screen, or reduced payload size.
- Model a minimal schema that serves that screen, not your entire domain. Add cursor pagination and clear error codes from day one.
- Implement resolvers with batching to eliminate N+1. Instrument each resolver with timing and backend call counts.
- Roll out persisted queries for that use case and enable GET for cacheable reads. Add query cost limits and timeouts.
- Expand gradually. Introduce mutations and subscriptions only after read paths are stable. Socialize schema review norms with domain owners.
This approach aligns with modernization patterns we describe in our guide on Modernizing Legacy Systems Without Disrupting Business.
Day-one operational checklist
- Depth and cost limits enforced, with alerting on rejections.
- Batch layer in place for N+1 and connection pooling configured.
- Persisted queries for common reads, CDN enabled for GET responses where safe.
- Field-level authorization patterns documented and tested.
- Observability wired into resolvers with traces, logs, and metrics dashboards.
- Schema linting, review process, deprecation policy, and change log.
- GraphiQL disabled in production or limited to trusted networks.
- Error contract defined with machine-readable codes in extensions.
For broader stack decisions and trade-offs around infrastructure, see our guide on How to Choose the Right Tech Stack in 2025. If you are building a Next.js front end, pair these patterns with the rendering and caching strategies in Next.js Best Practices for Scalable Apps.
Frequently Asked Questions
Is GraphQL faster than REST? It depends on the workload. GraphQL can reduce network round trips and payload size, which improves user-perceived speed, especially on mobile. If resolvers trigger extra backend calls or you do not batch properly, it can be slower on the server. Measure end-to-end latency and backend call counts.
Do I need versioning with GraphQL? Many teams avoid explicit versioning. You can add fields, deprecate old ones, and evolve types without breaking clients. For breaking changes, use a new field or type name, and support both paths during a deprecation window.
How do you cache GraphQL? Combine techniques. Use persisted queries and GET for cacheable reads at the CDN, rely on client-side normalized caches for instant UI, and add resolver-level caches for hot fields. Cache invalidation can be tag based or event driven.
How do I secure a GraphQL API? Start with the OWASP API Security Top 10. Add authentication and field-level authorization, enforce query cost and depth limits, prefer persisted queries with an allow list, validate inputs, and monitor anomalies.
What about file uploads? Either implement the GraphQL multipart request spec or use pre-signed URLs to send files directly to object storage.
How do subscriptions work? Subscriptions typically run over WebSockets so the server can push updates to clients. You define a subscription in the schema and publish events on the server when data changes.
Should we start with federation? Usually no. Begin with a single schema that is modular and well owned. Move to federation when team boundaries and scaling needs justify the extra moving parts. For the concepts, see Apollo Federation.
Which server or language should we use? Pick what your team can run well in production. The ecosystem has mature options in Node, Java, .NET, Python, Go, and more, see graphql.org/code.
How Wolf-Tech can help
GraphQL can be a force multiplier when it is done with discipline. If you want a second set of eyes on schema design, query performance, security controls, or a low-risk migration path, our team can help. Wolf-Tech brings full-stack development, code quality consulting, legacy optimization, and database and API expertise to accelerate your GraphQL adoption and keep it safe and maintainable.
Talk to us about your use case and constraints at Wolf-Tech. We will help you choose the right approach, de-risk delivery, and get results that matter for your product and your business.