
Full-Stack-Entwicklung: Was CTOs wissen sollten


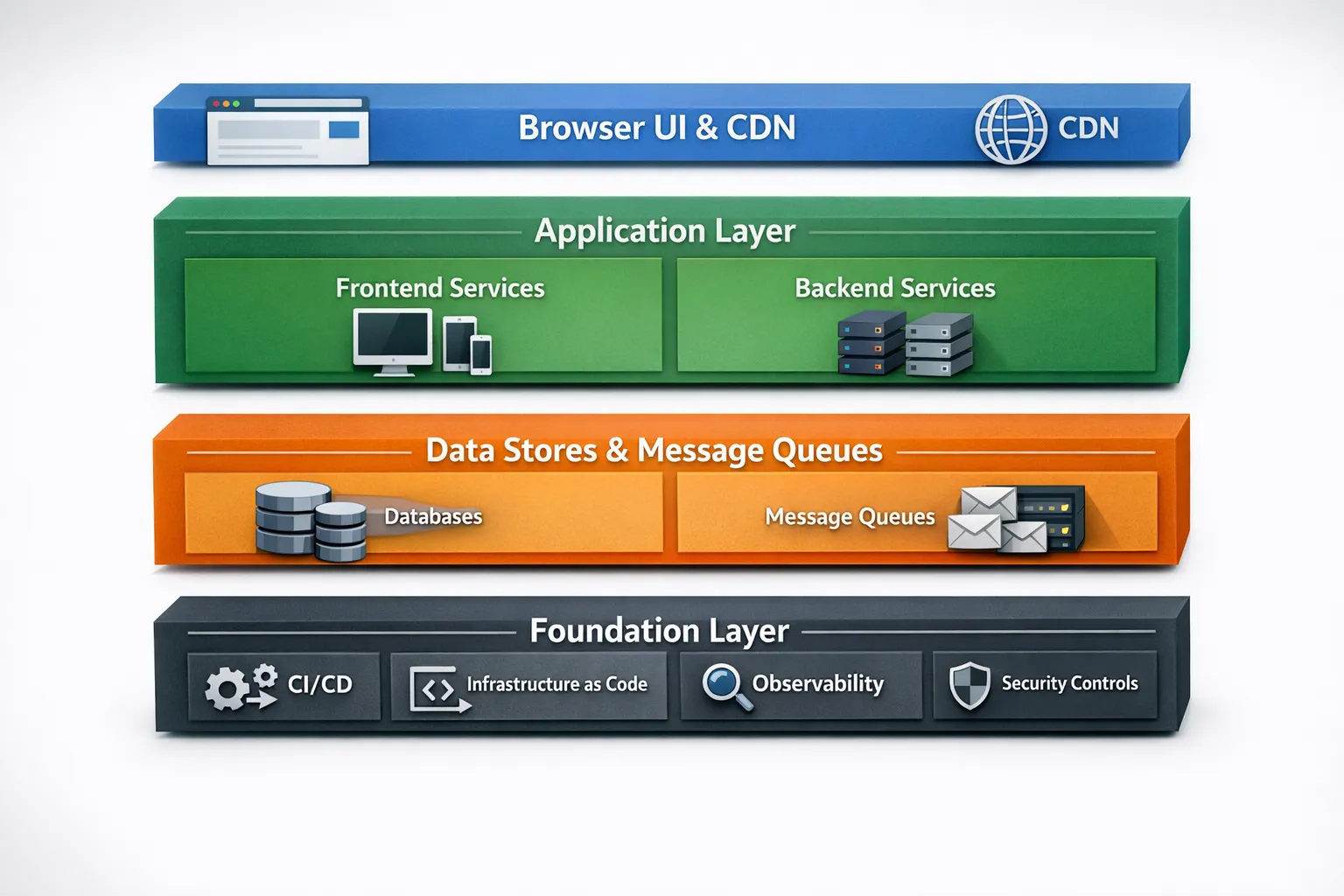
Full-Stack-Entwicklung ist zur Standarderwartung an die moderne Produktauslieferung geworden, doch der Begriff wird oft schwammig verwendet. Für CTOs lautet die praktische Frage nicht „machen wir Full-Stack", sondern „wie strukturieren wir End-to-End-Verantwortung so, dass wir schneller liefern, ohne versteckte Risiken anzuhäufen". 2026 bedeutet das, Frontend, Backend, Daten, Cloud und DevOps zu einem stimmigen Auslieferungssystem mit klaren Schnittstellen, messbarer Zuverlässigkeit und vorhersehbarem Wandel auszurichten.
Was „Full-Stack-Entwicklung" auf CTO-Ebene bedeuten sollte
Auf CTO-Ebene geht es bei Full-Stack-Entwicklung weniger um einzelne Personen, die alles können, sondern vielmehr um Teams, die ein Kundenergebnis end-to-end ausliefern. Dazu gehören:
- Produkt-UI- und UX-Implementierung (Web, Mobile, Accessibility, Performance)
- Backend-Services und APIs (Kontrakte, Autorisierung, Skalierungseigenschaften)
- Datenschicht (Schema-Design, Migrationen, Query-Performance, Lifecycle-Richtlinien)
- Cloud und Auslieferung (CI/CD, IaC, Umgebungen, Secrets, Observability)
- Qualitäts- und Sicherheitskontrollen (Tests, Code-Review, Dependency-Hygiene, Auditierbarkeit)
Ein nützlicher Test ist: Kann ein Team ein Feature von einem PRD in Produktion bringen, es betreiben und auf Basis von Metriken verbessern, ohne kritische Arbeit an drei andere Teams abzugeben?
Wenn die Antwort „ja" lautet, haben Sie Full-Stack-Fähigkeit. Lautet die Antwort „kommt darauf an, wer verfügbar ist", haben Sie heroischen Mehraufwand.
Full-Stack vs. Spezialistenteams: der Trade-off, den die meisten CTOs tatsächlich treffen
Viele CTOs formulieren die Wahl als Generalisten gegen Spezialisten. In der Praxis bauen die meisten leistungsstarken Organisationen ein T-förmiges Modell:
- Produktteams enthalten Engineers, die über Grenzen hinweg arbeiten können (Frontend zu API, API zu Daten)
- Spezialisten (Sicherheit, Plattform, SRE, Data Engineering) liefern Leitplanken, wiederverwendbare Primitive und hochwirksame Unterstützung
Das Risiko, „alle müssen Full-Stack sein" zu fordern, besteht darin, dass Sie versehentlich eine flache Organisation schaffen, in der:
- Frontend-Performance und Accessibility regredieren
- Datendesign zur Nebensache wird, was später teuer wird
- Auslieferungs-Pipelines fragil sind, weil „DevOps" als Nebentätigkeit behandelt wird
Das Risiko von Hyper-Spezialisierung ist das Gegenteil:
- Hand-offs vervielfachen sich
- Verantwortung wird unklar
- Lead Time steigt, selbst wenn Teams besetzt sind
Das CTO-Ziel ist schneller Flow bei begrenztem Risiko, keine ideologische Reinheit.
Die CTO-Checkliste: Was Sie klären sollten, bevor Sie Full-Stack-Auslieferung skalieren
1) Definieren Sie den „Stack" geschäftlich, nicht werkzeuggetrieben
Bevor Sie Frameworks diskutieren, richten Sie sich darauf aus, was das Unternehmen vom System braucht:
- Verfügbarkeits- und Wiederherstellungsziele (SLOs, RTO/RPO)
- Datensensibilität und Compliance-Verpflichtungen
- Spitzen-Trafficmuster und Latenzbudgets
- Integrationsfläche (Partner, interne Plattformen, Datenexporte)
- Release-Erwartungen (tägliche Iteration vs. quartalsweise Change-Windows)
Tooling folgt aus diesen Rahmenbedingungen. Wenn Sie ein tieferes Entscheidungs-Framework für die Technologieauswahl wünschen, ist Wolf-Techs Leitfaden zu Den richtigen Tech-Stack in 2025 wählen ein solider Begleiter, doch Ihr erster Schritt bleiben Ergebnisse und Rahmenbedingungen.
2) Entscheiden Sie, wo Sie starke Grenzen wollen
„Full-Stack" sollte nicht „verflochten" bedeuten. CTOs sollten Grenzen explizit setzen, etwa:
- Domänengrenzen (was gehört in welchen Service oder welches Modul)
- API-Grenzen (Kontrakte, Versionierung, Deprecation-Policy)
- Datengrenzen (Verantwortung für Tabellen, Events und Migrationen)
- Operative Grenzen (wer betreut On-Call, Dashboards, Runbooks)
Bleiben Grenzen implizit, ziehen Teams sie unter Druck neu, und Sie zahlen mit Incidents und Verlangsamungen.
3) Behandeln Sie operative Bereitschaft als Teil des Stacks
Ein Feature ist nicht „fertig", wenn es gemerged wird. Es ist fertig, wenn es beobachtbar und betreibbar ist.
Full-Stack-Entwicklung auf CTO-Ebene umfasst:
- Strukturiertes Logging und Trace-Kontext
- Service-Level-Indicators (Latenz, Fehlerquote, Auslastung)
- Alerting, das auf Nutzerwirkung abbildet
- Runbooks und sichere Rollout-Pattern
Wenn Sie eine neutrale Basis für Reliability-Sprache suchen, sind Googles SRE-Konzepte nach wie vor der meistreferenzierte Startpunkt für SLO-Denken (siehe Googles SRE-Ressourcen).
Wo Full-Stack-Projekte gelingen oder scheitern (und was Sie prüfen sollten)
Die Misserfolgsmuster sind bemerkenswert konsistent. Die folgende Tabelle ist eine praktische Methode, Full-Stack-Fähigkeit zu prüfen, ohne sich in Buzzwords zu verlieren.
| Stack-Bereich | Was ein Full-Stack-Team entscheiden muss | Häufiger Misserfolgsmodus | CTO-Check, der ihn verhindert |
|---|---|---|---|
| Frontend | Rendering-Strategie, Caching, Accessibility, Performance-Budgets | Langsame UX, inkonsistente UI, nicht zugängliche Flows | Lighthouse- und Core-Web-Vitals-Ziele fordern, Design-System-Nutzung durchsetzen |
| APIs | Kontraktform, AuthZ/AuthN, Fehlersemantik, Versionierung | Brechende Clients, inkonsistente Auth, „mysteriöse 500er" | API-Standards (OpenAPI/GraphQL-Schema) durchsetzen, Contract-Tests |
| Daten | Schema-Verantwortung, Migrationen, Indexe, Aufbewahrung | Langsame Queries, fragile Migrationen, unklare Verantwortung | Migrations-Playbooks, Query-Reviews, Datenlebenszyklus-Richtlinie verlangen |
| Auslieferung | CI/CD-Flow, Umgebungsstrategie, Secrets, Release-Sicherheit | Manuelle Schritte, Snowflake-Umgebungen, riskante Deploys | Mindest-CI-Gates, IaC für Umgebungen, progressive Delivery |
| Observability | Logs, Metriken, Traces, Alert-Schwellen | Alert-Fatigue, blinde Incident-Reaktion | SLO-basierte Alerts, On-Call-Runbooks, Incident-Reviews |
| Sicherheit | Dependency-Policy, Secrets-Handling, Threat-Modeling | Leakende Secrets, anfällige Dependencies, schwache Auth | OWASP-Leitlinien und SSDF-artige Kontrollen folgen, Checks automatisieren |
Für Anwendungssicherheits-Baselines ist OWASPs ASVS eine praktische Referenz, um zu definieren, wie „gut" aussieht, ohne jede Diskussion zu einer Meinungsfrage werden zu lassen.
Wie Sie für Full-Stack-Auslieferung einstellen und strukturieren (ohne Einhörner zu suchen)
Ein häufiger Fehler ist, Stellenbeschreibungen zu schreiben, die Senior-Expertise auf jeder Schicht verlangen. Das führt entweder dazu, dass:
- der Kandidatenkreis auf eine winzige Gruppe teurer Hires schrumpft, oder
- Mismatches entstehen, weil Kandidaten in einer Schicht stark sind und anderswo unzureichend vorbereitet
Definieren Sie stattdessen, was „Full-Stack" für Ihren Kontext bedeutet.
Definieren Sie die Mindest-Querschnittskompetenz
Für die meisten CTOs ist eine gute Basis:
- Engineers können ein Feature mit Anleitung von UI über API bis Persistenz bringen
- Engineers können Produktionsprobleme mit Logs und Traces debuggen
- Engineers verstehen grundlegende Cloud-Primitive, auch wenn sie keine Plattform-Spezialisten sind
Entscheiden Sie dann, wo Sie tiefe Spezialisten brauchen (Beispiele: High-Scale-Performance-Engineering, Security-Engineering, komplexe Dateninfrastruktur).
Nutzen Sie eine Team-Topologie, die den Flow schützt
Sie brauchen keinen organisatorischen Umbau, um Full-Stack-Auslieferung zu verbessern, aber Sie brauchen klare Verantwortlichkeiten. Bewährte Muster:
- Stream-aligned Produktteams mit End-to-End-Verantwortung für eine Geschäftsdomäne
- Eine kleine Plattform- oder Enabling-Funktion, die befestigte Pfade baut (CI-Templates, Deployment-Patterns, Observability-Defaults)
- Eingebettete Sicherheits- und Qualitätspraktiken (keine Gatekeeper-Teams, die nur „nein" sagen)
Interviewen Sie auf Systemdenken, nicht auf Tool-Trivia
Gute Full-Stack-Engineers zeigen konsistent:
- Fähigkeit, Trade-offs abzuwägen (Latenz vs. Kosten, Flexibilität vs. Konsistenz)
- Komfort beim Lesen unbekannten Codes und sicheren Verbessern
- Pragmatisches Debugging (hypothesengetrieben, mit Instrumentation)
- Kommunikation, die Annahmen klärt
Eine einfache Methode dafür ist eine „Feature-Erweiterungs"-Aufgabe: Geben Sie eine kleine App vor und bitten Sie die Kandidatin, eine querschnittliche Fähigkeit hinzuzufügen (Autorisierungsregel plus UI-Verhalten plus Migration), während sie testbar bleibt.
Die Auslieferungspraktiken, die Full-Stack-Teams wirkungsvoll machen
1) Liefern Sie schmale vertikale Slices
Full-Stack-Auslieferung glänzt, wenn Teams ein schmales Feature end-to-end ausliefern und in Produktion validieren können.
Schmale Slices erzwingen frühe Integration und reduzieren das Risiko später Überraschungen bei:
- Authentifizierung und Autorisierung
- Performance-Engpässen
- Datenmodellierungsfehlern
- Release- und Rollback-Themen
Hier erhalten Engineering-Leitende auch die verlässlichsten Zeitsignale.
2) Machen Sie Qualität beobachtbar, nicht aspirational
Qualitätsprobleme in Full-Stack-Systemen entstehen selten aus einer einzigen schlechten Entscheidung. Sie ergeben sich aus kleinen Kompromissen, die sich anhäufen.
Leitplanken auf CTO-Ebene, die durchgängig helfen:
- Trunk-based oder kurzlebige Branches mit verpflichtendem Code-Review
- Automatisierte Tests, die Verhaltensänderungen auf der richtigen Ebene abdecken
- Statische Checks, die schnell genug sind, um bei jedem PR zu laufen
- Eine klare Definition of Done, die Observability und Rollout-Sicherheit einschließt
DORA-Metriken werden häufig zur Quantifizierung der Auslieferungsleistung verwendet (Deployment-Frequenz, Lead Time for Changes, Change Failure Rate, Time to Restore). Das Forschungsprogramm wird vielfach über die DORA-Website referenziert, und die Metriken sind nützlich, gerade weil sie bei ehrlicher Umsetzung schwer zu manipulieren sind.
3) Standardisieren Sie die langweiligen Teile
Full-Stack-Teams werden langsamer, wenn jedes Projekt Folgendes neu erfindet:
- Auth- und Berechtigungs-Patterns
- API-Response-Konventionen
- Logging- und Tracing-Setup
- Deployment-Pipelines
Standardisierung bedeutet nicht, alle in ein Framework zu zwingen. Sie bedeutet, Defaults und Templates zu schaffen, damit Teams Zeit für Produktwert verwenden.
Full-Stack-Entwicklung in der Realität: Legacy-Code und Modernisierung
CTOs dürfen selten auf der grünen Wiese bauen. Full-Stack-Entwicklung wird zum strategischen Asset, wenn sie hilft, sicher zu modernisieren und gleichzeitig weiterhin Features zu liefern.
Der praktische Ansatz besteht darin, Legacy-Modernisierung als End-to-End-Produkt zu behandeln: das System verbessern, während es weiterläuft.
Ein Full-Stack-Team im Legacy-Bereich sollte in der Lage sein:
- Tests hinzuzufügen, die Verhalten festschreiben, bevor das Innere geändert wird
- Nahtstellen einzuziehen (Schnittstellen, Adapter), um den Blast Radius zu reduzieren
- Module inkrementell zu verbessern, ohne Integrationskontrakte zu brechen
- Auslieferungssicherheit zu erhöhen (Feature-Flags, Canary-Releases) vor großen Refactorings
Wenn Sie ein tiefergehendes Modernisierungs-Playbook brauchen, hat Wolf-Tech detaillierte Leitfäden zu Code-Modernisierungstechniken und zum Modernisieren von Legacy-Systemen ohne den Geschäftsbetrieb zu stören.
Marktsignale für Full-Stack-Prioritäten nutzen
CTOs verfügen oft über gute interne Telemetrie (Produktanalytik, Support-Tickets, Incident-Reviews), aber über schwächere externe Telemetrie (was Interessenten und Wettbewerber sagen). Für viele B2B-Produkte ist Reddit ein überraschend signalstarker Kanal für:
- Feature-Vergleichs-Threads
- „Wie löse ich X?"-Schmerzpunkte
- Migrations- und Tooling-Diskussionen
Wann Sie einen externen Full-Stack-Partner einbinden (und wie ohne Reue)
Selbst starke interne Teams stoßen an Kapazitätsgrenzen, besonders bei:
- Launch einer neuen Produktlinie
- Legacy-Modernisierungsinitiative mit strengen Kontinuitätsanforderungen
- Plattform-Migration (Cloud, Datenschicht, Identity)
- Sicherheits- oder Zuverlässigkeits-Push, bei dem Zeitpläne entscheidend sind
Ein Partner kann Hebel liefern, aber nur, wenn die Zusammenarbeit so strukturiert ist, dass sie nachhaltige Fähigkeit erzeugt, nicht nur Output.
CTO-Leitlinien, die Enttäuschungen verhindern:
- Verlangen Sie eine kurze Discovery, die in konkrete Artefakte mündet (Architekturnotizen, Risiken, Thin-Slice-Plan)
- Beginnen Sie mit einem produktionsreifen vertikalen Slice, nicht mit Slideware
- Bestehen Sie ab Tag eins auf operativer Bereitschaft (Dashboards, Runbooks, On-Call-Erwartungen)
- Machen Sie Wissenstransfer explizit (Pairing, dokumentierte Entscheidungen, reproduzierbare Umgebungen)
Wenn Sie Anbieter evaluieren, liefert Wolf-Techs Leitfaden zu Wie man Anbieter für individuelle Softwareentwicklung prüft eine strukturierte Methode, um Belege statt Versprechen zu fordern.
Ein pragmatischer 30-60-90-Tage-Plan für CTOs, die Full-Stack-Fähigkeit ausbauen
Tage 1-30: Realität abbilden
Erfassen Sie ohne Wertung, wo Sie stehen:
- Bilden Sie Ihren Auslieferungs-Flow von der Idee bis zur Produktion ab und identifizieren Sie die größten Wartezustände
- Wählen Sie 1 oder 2 Schlüsselservices und dokumentieren Sie deren Verantwortungsgrenzen (Domäne, API, Daten)
- Etablieren Sie initiale Metriken (DORA-Metriken plus 1 oder 2 nutzerbezogene SLOs)
Tage 31-60: Leitplanken einbauen, die das Tempo erhöhen
Konzentrieren Sie sich auf Änderungen, die Reibung beseitigen:
- Mindest-CI/CD-Gates (Tests, Linting, Dependency-Checks)
- Observability-Defaults (Logs, Traces, Dashboards) in Templates
- Eine standardisierte API- und Error-Handling-Konvention
Tage 61-90: Beweisen Sie es mit einem schmalen Slice
Wählen Sie ein bedeutendes Feature und liefern Sie es end-to-end:
- Hinter einem Flag ausliefern und progressiv ausrollen
- Performance- und Zuverlässigkeitsergebnisse messen
- Ein kurzes Retro durchführen, fokussiert auf Flow, nicht auf Schuld, und Standards aktualisieren
So entsteht ein wiederholbares System, kein einmaliger Erfolg.
Wie Wolf-Tech CTOs beim Aufbau von Full-Stack-Fähigkeit unterstützt
Wolf-Tech ist auf Full-Stack-Entwicklung und technisches Wachstum spezialisiert, mit über 18 Jahren Erfahrung in der Unterstützung von Teams über moderne Stacks und Branchen hinweg. Engagements zentrieren sich typischerweise auf den Bau, die Optimierung und die Skalierung realer Systeme, einschließlich:
- Full-Stack-Entwicklung für Webanwendungen und Plattformen
- Code-Quality-Consulting und Engineering-Standards
- Legacy-Code-Optimierung und Modernisierungsplanung
- Cloud, DevOps, Datenbanken und API-Lösungen
- Tech-Stack-Strategie und Begleitung der digitalen Transformation
Wenn Sie Ihren aktuellen Ansatz auf den Prüfstand stellen wollen, ist ein wirkungsvoller Startpunkt eine kurze Bestandsaufnahme, die die größten Engpässe für End-to-End-Auslieferung identifiziert (Architektur, Auslieferungs-Pipeline, Qualitäts-Gates, Zuverlässigkeit, Team-Topologie) und sie in einen Thin-Slice-Umsetzungsplan überführt. Mehr über Wolf-Tech erfahren Sie unter wolf-tech.io.