
GraphQL APIs: Vorteile, Fallstricke und Anwendungsfälle


GraphQL hat sich von einer Nischenalternative zu REST zu einem pragmatischen Werkzeug für anpassungsfähige, produktfreundliche APIs entwickelt. Teams setzen es ein, um Features schneller zu liefern, ausufernde Backends in den Griff zu bekommen und Clients genau die Daten zu liefern, die sie brauchen. Es ist kein Allheilmittel. Wie jede Architekturentscheidung bringt GraphQL neue operationale, sicherheitsrelevante und caching-bezogene Überlegungen mit sich, die Sie einplanen müssen.
Dieser Leitfaden erklärt, was GraphQL in der Praxis ist, wo es glänzt, wo es problematisch werden kann und wie Sie die Eignung für Ihre Roadmap bewerten. Ausserdem enthält er Implementierungstipps, Migrationsmuster und eine Checkliste für den ersten Tag.
Was GraphQL in der Praxis ist
GraphQL ist eine Abfragesprache und Laufzeitumgebung, die ein stark typisiertes Schema über einen einzigen Endpunkt bereitstellt. Clients fragen genau die Felder an, die sie benötigen, und der Server löst diese Felder aus einer oder mehreren Datenquellen auf. Das Schema dient gleichzeitig als Dokumentation und als Vertrag, den Client und Server mit Zuversicht weiterentwickeln können.
Wenn Sie neu bei GraphQL sind, starten Sie mit dem offiziellen Lernleitfaden auf graphql.org. Für Transportdetails pflegt die Community einen Arbeitsentwurf für GraphQL over HTTP, der gängige Muster wie POST- und GET-Requests sowie Persisted Operations beschreibt.
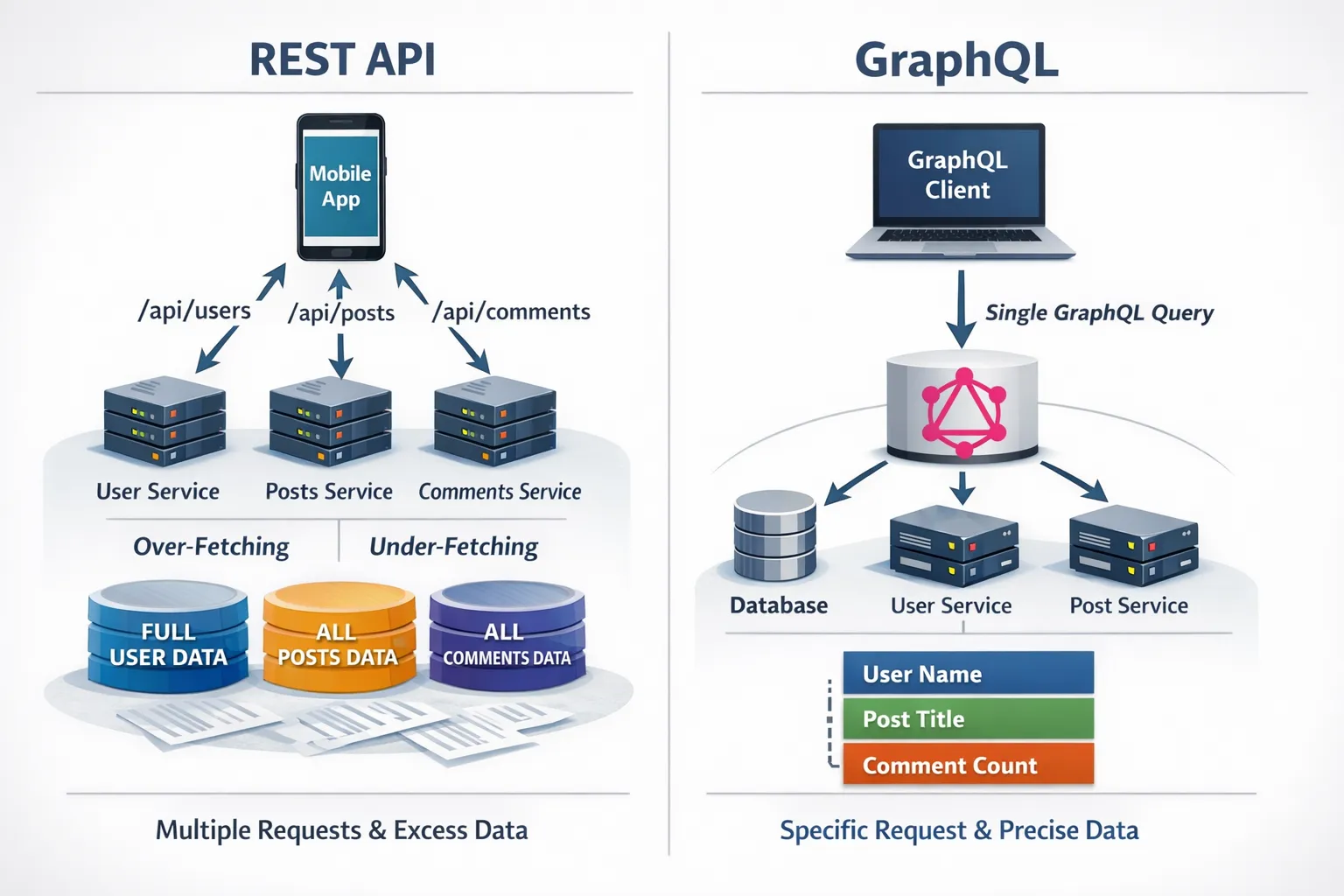
Vorteile, die Teams tatsächlich spüren
Client-gesteuerte Daten, weniger Roundtrips
Mit GraphQL vermeiden Clients fest kodierte Endpunkte und gestalten ihre eigenen Antworten. Das reduziert Overfetching und Underfetching, was besonders wertvoll für mobile Netzwerke und komplexe Dashboards ist.
Stark typisierte Verträge und schnellere Iteration
Das Schema ist die einzige Wahrheitsquelle. Typen, Queries und Mutations sind für Menschen und Tooling gleichermassen klar. Introspection ermöglicht automatisch generierte Dokumentation, typsichere Clients und CI-Checks, sodass Frontend- und Backend-Teams parallel arbeiten können, mit weniger Breaking Changes. Siehe die offiziellen Best Practices für Schema- und Client-Muster auf GraphQL Best Practices.
Eine vereinheitlichende Schicht über fragmentierten Systemen
GraphQL eignet sich hervorragend als Aggregationsschicht. Sie können Daten aus Legacy-Services, Datenbanken und Drittanbieter-APIs zusammenführen, ohne die interne Topologie offenzulegen. Es hilft Teams, sich in Richtung eines produktzentrierten, domänengetriebenen Modells zu bewegen, während sie im Hintergrund modernisieren.
Echtzeit und inkrementelle Auslieferung
GraphQL unterstützt Echtzeit-Updates mit Subscriptions über WebSockets, und viele Server unterstützen mittlerweile inkrementelle Auslieferung mit Direktiven wie defer und stream. Diese Muster ermöglichen eine reaktionsschnelle UX für Live-Dashboards und Kollaborationsfunktionen.
Tooling-Ökosystem
Von GraphiQL-Explorern über Schema-Registries bis hin zu Code-Generatoren verkürzt das GraphQL-Ökosystem Feedback-Schleifen. Normalisierte Caches auf Client-Seite, zum Beispiel in Apollo Client oder Relay, können Apps sofort reagieren lassen.
Fallstricke und wie man sie entschärft
| Risiko | Warum es passiert | Was zu tun ist | Metrik zur Verifikation |
|---|---|---|---|
| N+1-Datenbankaufrufe | Field Resolver fetchen pro Eintrag | Batching und Caching pro Request mit DataLoader oder Äquivalent | P95-Resolver-Latenz, Anzahl Backend-Aufrufe pro Request |
| Teure Queries | Tiefe oder breite Selektionen belasten Backends | Tiefe- und Kostenlimits durchsetzen, Persisted Queries bevorzugen, Timeouts setzen | Ablehnungsanzahl für über-dem-Limit-Queries, durchschn. Querykosten |
| Caching ist schwieriger | Ein Endpunkt und variable Antworten | Persisted GET für CDN nutzen, Client Normalized Cache, Resolver-Level-Caching | CDN-Hit-Rate, Client-Cache-Hit-Rate, Backend-QPS |
| Autorisierungslecks | Feld-Level-Daten erfordern Feld-Level-Auth | Auth-Policies zentral in Resolvern oder Direktiven, Negativtests | Unautorisierte Feldzugriffsversuche, Security-Test-Pass-Rate |
| Schema-Wildwuchs | Unkontrollierte Erweiterungen über die Zeit | Domänen-Ownership, Schema-Linting, Review Gates, Deprecations | Lint-Violations pro PR, Deprecated-Field-Entfernungsrate |
| Federation-Komplexität | Cross-Team-Graph-Komposition | Klares Ownership, Verträge und CI für Subgraphen | Build-Erfolgsrate, Zeit zum Mergen von Subgraph-Änderungen |
| Fehlerambiguität | Clients sehen partielle Daten mit vagen Fehlern | Fehlerformate mit Extensions standardisieren, Client-Handling dokumentieren | Fehlercode-Abdeckung, Client-Error-Handling-Test-Pass-Rate |
| Uploads und Binärdaten | JSON über HTTP ist nicht ideal für große Dateien | Community Multipart Spec oder Pre-Signed URLs verwenden | Upload-Erfolgsrate, Übertragungszeit, Fehlerrate |
Security ist fundamental. Starten Sie mit den OWASP API Security Top 10 und wenden Sie dann GraphQL-spezifische Kontrollen wie Kostenlimits und Operation Allow Lists an.
Wichtige Fallstricke im Detail
-
Performance und das N+1-Problem: Da Resolver pro Feld ausgeführt werden, lösen naive Implementierungen übertrieben viele Backend-Aufrufe aus. Setzen Sie eine Batching-Schicht wie DataLoader ein, um Abfragen pro Schlüssel innerhalb eines Requests zu gruppieren. Kombinieren Sie das mit Connection Pooling und Read Replicas.
-
Caching-Strategie: GraphQL fördert POST-Requests, die CDNs standardmässig nicht cachen können. Für stabile Queries nutzen Sie Persisted Operations und aktivieren GET, um Edge-Caching zu nutzen. Kombinieren Sie das mit clientseitigen normalisierten Caches und kurzlebigen Resolver-Caches für heisse Felder.
-
Query-Kosten und Denial-of-Wallet: Implementieren Sie Query-Tiefe-, Breite- und Komplexitätslimits. Viele Server erlauben es, Kosten pro Feld zu definieren, sodass Sie missbräuchliche Queries schnell ablehnen können. Persisted Queries plus eine Allow List reduzieren das Risiko drastisch.
-
Autorisierung: Einmal authentifizieren, oft autorisieren. Wenden Sie Feld-Level-Prüfungen in Resolvern oder über Direktiven an. Verlassen Sie sich nicht auf Introspection-Toggling für Security, behandeln Sie es nur als Komforteinstellung.
-
Paginierung: Bevorzugen Sie Cursor-basierte Paginierung für Stabilität und Performance. Die Relay Cursor Connections Spec ist eine gute Basis, auch wenn Sie Relay nicht nutzen.
-
Observability: Instrumentieren Sie Resolver mit Tracing und Metriken, damit Sie heisse Felder und langsame Backends sehen können. Das OpenTelemetry-Projekt bietet SDKs für verschiedene Sprachen für verteiltes Tracing und Metriken, siehe opentelemetry.io.
-
Uploads: Für Dateien verwenden Sie entweder die weit verbreitete GraphQL Multipart Request Spec oder Pre-Signed URLs, damit Clients direkt mit Object Storage kommunizieren.
Wann GraphQL eine hervorragende Wahl ist
- Multi-Device- oder bandbreitensensitive Clients, die individuelle Payloads pro Bildschirm benötigen.
- Produktoberflächen mit komplexen Joins über Domänen hinweg, zum Beispiel Marktplatz-Listings, Nutzerprofile und Echtzeit-Status.
- Eine Backend-for-Frontend-Schicht, die Client-Teams vom Microservice-Wandel entkoppelt.
- Eine Modernisierungsfassade, die Legacy-Services vereinheitlicht, während Sie schrittweise Interna refaktorisieren.
- Cross-Team-Schema-Federation, bei der Subdomänen von separaten Teams mit klaren Grenzen verantwortet werden.
Wann Sie GraphQL überspringen oder verschieben sollten
- Einfaches CRUD oder High-Throughput-Content, bei dem CDN-gecachtes REST perfekt funktioniert.
- Großes Binär-Streaming oder Medien-Pipelines, die spezialisierte Protokolle erfordern.
- Extrem latenzsensitive Systeme, bei denen der Resolver-Overhead die Vorteile überwiegt.
- Teams ohne die Kapazität, Kostenkontrolle, Observability und Governance zu implementieren.
Hochwertige Anwendungsfälle und Muster
| Anwendungsfall | Muster | Warum GraphQL hilft |
|---|---|---|
| Mobile Apps mit diversen Screens | BFF-Schicht pro App | Antworten pro Screen massschneidern, weniger Releases für Payload-Änderungen |
| Analytics-Dashboards | Schema mit berechneten Feldern und Verbindungen | Metriken aus mehreren Datenspeichern mit einer Abfrage zusammenführen |
| Marktplätze und Kataloge | Föderierte Subgraphen für Listing, Pricing, Inventar | Domänen-Ownership kapseln, Referenzen am Gateway auflösen |
| Customer-360-Ansicht | Aggregation über CRM, Billing, Support | Backend-Fragmentierung verbergen, konsistente Typen liefern |
| SaaS-Integrations-Hub | Einheitliches Schema über Drittanbieter-APIs | Modelle normalisieren, konsistente Auth und Rate Limits anwenden |
| Legacy-Modernisierung | Strangler-Fassade | Schema stabil halten, während Service für Service migriert wird |
Für Cross-Team-Graphen ist die Apollo-Dokumentation zu Federation eine nützliche Referenz für Konzepte wie Subgraphen und Komposition.
Architektur und Implementierungsoptionen
-
Server-Frameworks: Es gibt ausgereifte Bibliotheken in verschiedenen Ökosystemen. Erkunden Sie die sprachspezifischen Optionen auf der offiziellen GraphQL Code-Seite. Wählen Sie einen Stack, den Ihr Team in der Produktion betreiben kann.
-
Schema-first vs. Code-first: Schema-first macht Verträge explizit und ist leicht zu reviewen. Code-first kann Boilerplate reduzieren und nah an den Typen in stark typisierten Sprachen bleiben. Viele Teams mischen die Ansätze.
-
Transport und Operations: Folgen Sie dem GraphQL over HTTP-Entwurf, um Verhalten zu standardisieren. Erwägen Sie Automatic Persisted Queries, um Payload-Größen zu reduzieren und CDN-Caching zu ermöglichen, siehe APQ.
-
Federation vs. monolithisches Schema: Starten Sie mit einem gut strukturierten monolithischen Schema, um voreilige Komplexität zu vermeiden. Setzen Sie Federation ein, wenn Sie klare Team-Grenzen, operationale Reife und einen Bedarf an skaliertem Ownership haben.
-
Echtzeit: Nutzen Sie Subscriptions über WebSockets für Push-Updates. Für ressourcenbeschränkte Umgebungen können Server-Sent Events eine einfachere Alternative sein.
-
Deployments: GraphQL-Server laufen gut in Containern und Serverless-Umgebungen. Bei Serverless überwachen Sie Cold Starts und wärmen kritische Funktionen vor. Einige Teams platzieren ein leichtgewichtiges GraphQL-Gateway am Edge für Routing und Caching, während die Resolver in der Kernregion bleiben.
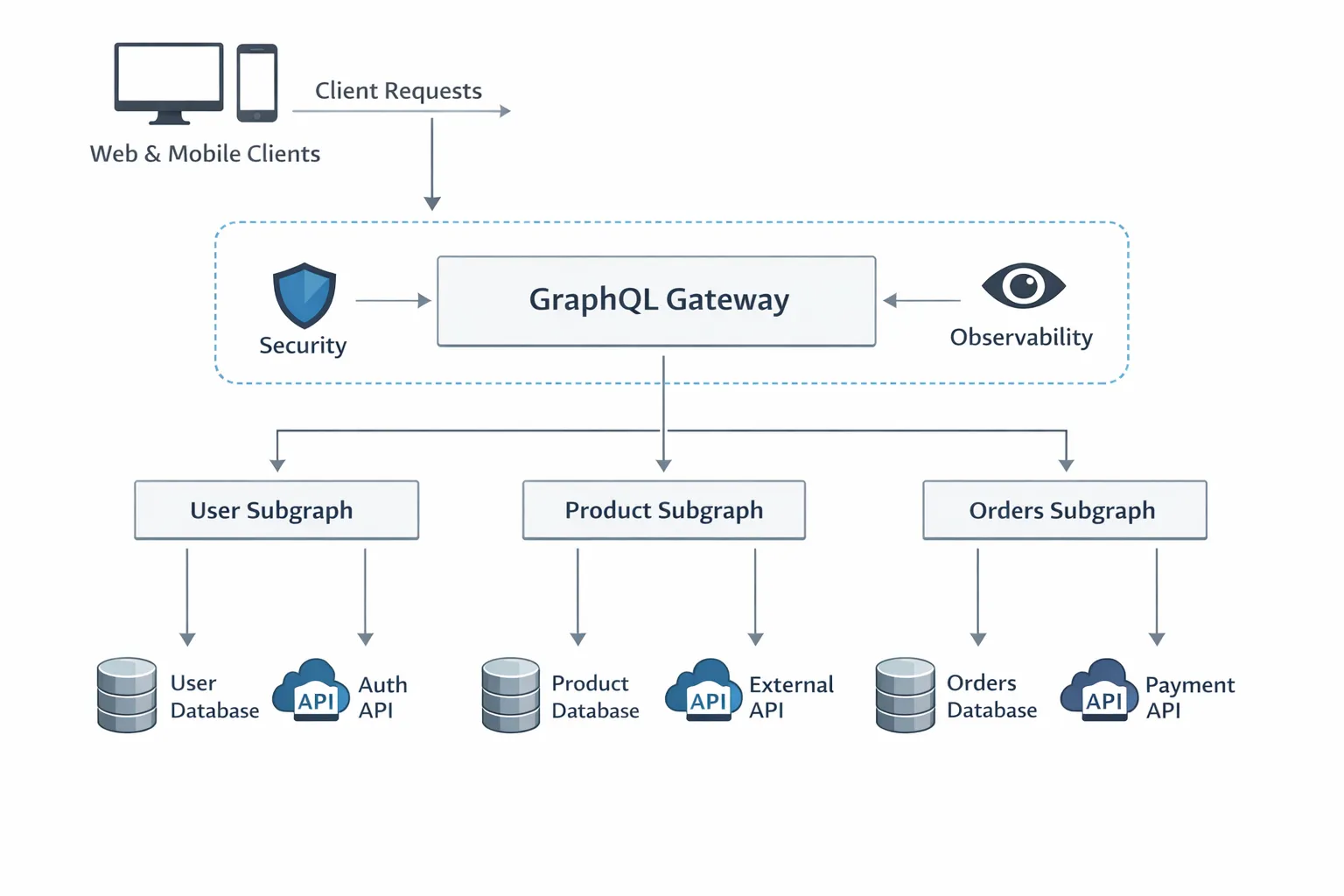
Ein pragmatischer Migrationsplan von REST
- Wählen Sie einen hochwertigen Lese-Anwendungsfall. Definieren Sie Erfolgskriterien wie verbesserte P95-Latenz, weniger Client-Requests pro Screen oder reduzierte Payload-Größe.
- Modellieren Sie ein minimales Schema, das diesen Screen bedient, nicht Ihre gesamte Domäne. Fügen Sie Cursor-Paginierung und klare Fehlercodes von Tag eins an hinzu.
- Implementieren Sie Resolver mit Batching, um N+1 zu eliminieren. Instrumentieren Sie jeden Resolver mit Timing und Backend-Aufrufzählung.
- Rollen Sie Persisted Queries für diesen Anwendungsfall aus und aktivieren Sie GET für cachefähige Lesezugriffe. Fügen Sie Query-Kostenlimits und Timeouts hinzu.
- Erweitern Sie schrittweise. Führen Sie Mutations und Subscriptions erst ein, wenn Lesepfade stabil sind. Etablieren Sie Schema-Review-Normen mit Domänen-Verantwortlichen.
Dieser Ansatz stimmt mit Modernisierungsmustern überein, die wir in unserem Leitfaden zu Modernizing Legacy Systems Without Disrupting Business beschreiben.
Betriebs-Checkliste für Tag eins
- Tiefe- und Kostenlimits durchgesetzt, mit Alerting bei Ablehnungen.
- Batching-Schicht für N+1 vorhanden und Connection Pooling konfiguriert.
- Persisted Queries für gängige Lesezugriffe, CDN aktiviert für GET-Antworten wo sicher.
- Feld-Level-Autorisierungsmuster dokumentiert und getestet.
- Observability in Resolver eingebunden mit Traces, Logs und Metriken-Dashboards.
- Schema-Linting, Review-Prozess, Deprecation-Policy und Changelog.
- GraphiQL in der Produktion deaktiviert oder auf vertrauenswürdige Netzwerke beschränkt.
- Fehlervertrag definiert mit maschinenlesbaren Codes in Extensions.
Für breitere Stack-Entscheidungen und Abwägungen rund um Infrastruktur siehe unseren Leitfaden How to Choose the Right Tech Stack in 2025. Wenn Sie ein Next.js-Frontend bauen, kombinieren Sie diese Muster mit den Rendering- und Caching-Strategien in Next.js Best Practices for Scalable Apps.
Häufig gestellte Fragen
Ist GraphQL schneller als REST? Das hängt vom Workload ab. GraphQL kann Netzwerk-Roundtrips und Payload-Größe reduzieren, was die vom Nutzer wahrgenommene Geschwindigkeit verbessert, besonders auf Mobilgeräten. Wenn Resolver zusätzliche Backend-Aufrufe auslösen oder Sie nicht richtig batchen, kann es serverseitig langsamer sein. Messen Sie Ende-zu-Ende-Latenz und Backend-Aufrufzahlen.
Brauche ich Versionierung mit GraphQL? Viele Teams verzichten auf explizite Versionierung. Sie können Felder hinzufügen, alte deprecaten und Typen weiterentwickeln, ohne Clients zu brechen. Für Breaking Changes nutzen Sie einen neuen Feld- oder Typnamen und unterstützen beide Pfade während eines Deprecation-Fensters.
Wie cached man GraphQL? Kombinieren Sie Techniken. Nutzen Sie Persisted Queries und GET für cachefähige Lesezugriffe am CDN, setzen Sie auf clientseitige normalisierte Caches für sofortige UI und fügen Sie Resolver-Level-Caches für heisse Felder hinzu. Cache-Invalidierung kann tag-basiert oder eventgesteuert sein.
Wie sichere ich eine GraphQL API? Starten Sie mit den OWASP API Security Top 10. Fügen Sie Authentifizierung und Feld-Level-Autorisierung hinzu, setzen Sie Query-Kosten- und Tiefenlimits durch, bevorzugen Sie Persisted Queries mit einer Allow List, validieren Sie Eingaben und überwachen Sie Anomalien.
Was ist mit Datei-Uploads? Entweder implementieren Sie die GraphQL Multipart Request Spec oder verwenden Pre-Signed URLs, um Dateien direkt an Object Storage zu senden.
Wie funktionieren Subscriptions? Subscriptions laufen typischerweise über WebSockets, damit der Server Updates an Clients pushen kann. Sie definieren eine Subscription im Schema und veröffentlichen Events auf dem Server, wenn sich Daten ändern.
Sollten wir mit Federation starten? In der Regel nein. Beginnen Sie mit einem einzelnen Schema, das modular und gut verantwortet ist. Wechseln Sie zu Federation, wenn Team-Grenzen und Skalierungsanforderungen die zusätzliche Komplexität rechtfertigen. Für die Konzepte siehe Apollo Federation.
Welchen Server oder welche Sprache sollten wir verwenden? Wählen Sie, was Ihr Team gut in der Produktion betreiben kann. Das Ökosystem hat ausgereifte Optionen in Node, Java, .NET, Python, Go und mehr, siehe graphql.org/code.
Wie Wolf-Tech helfen kann
GraphQL kann ein Kraftmultiplikator sein, wenn es diszipliniert umgesetzt wird. Wenn Sie eine zweite Meinung zu Schema-Design, Query-Performance, Security-Kontrollen oder einem risikoarmen Migrationspfad wünschen, kann unser Team helfen. Wolf-Tech bringt Full-Stack-Entwicklung, Code-Quality-Consulting, Legacy-Optimierung sowie Datenbank- und API-Expertise mit, um Ihre GraphQL-Adoption zu beschleunigen und sicher und wartbar zu halten.
Sprechen Sie mit uns über Ihren Anwendungsfall und Ihre Rahmenbedingungen unter Wolf-Tech. Wir helfen Ihnen, den richtigen Ansatz zu wählen, die Delivery zu entrisiken und Ergebnisse zu erzielen, die für Ihr Produkt und Ihr Geschäft zählen.