
Next.js-Entwicklung: Performance-Tuning-Leitfaden


Performance-Probleme in einer Next.js-App entstehen selten aus einer einzelnen „langsamen" Codezeile. Sie sind in der Regel das Ergebnis kleiner Ineffizienzen, die sich über Rendering, Datenfetching, Bilder, JavaScript-Ausführung, Drittanbieter-Skripte und Infrastruktur summieren. Die gute Nachricht: Next.js bietet starke Primitive, um jede Ebene zu verbessern — solange Sie Tuning als messgetriebenen Workflow angehen.
Dieser Leitfaden konzentriert sich auf praktisches Performance-Tuning für reale Next.js-Entwicklung: wie Sie den Engpass identifizieren, welche Hebel Core Web Vitals bewegen und wie Sie Regressionen verhindern, sobald die Dinge besser sind.
Mit der Definition von „schnell" beginnen (und Ziele setzen)
Wenn Sie Erfolg nicht definieren, können Sie nicht verlässlich tunen. Für die meisten Produktteams ist Erfolg eine Kombination aus nutzerseitig wahrgenommener Geschwindigkeit und Betriebskosten.
Googles Core Web Vitals sind eine pragmatische Baseline, weil sie stark mit wahrgenommener Performance korrelieren:
- LCP (Largest Contentful Paint): Wie schnell der Hauptinhalt sichtbar wird
- CLS (Cumulative Layout Shift): Visuelle Stabilität
- INP (Interaction to Next Paint): Reaktivität unter realer Interaktion
Googles Referenz-Schwellen sind der häufigste Ausgangspunkt. Aktuelle Definitionen und Anleitungen finden Sie auf web.dev/vitals.
| Metrik | „Gutes" Ziel (häufig genutzt) | Was es in Next.js-Apps üblicherweise widerspiegelt |
|---|---|---|
| LCP | ≤ 2,5 s | TTFB, Bildoptimierung, CSS/Fonts, Above-the-fold-Rendering |
| CLS | ≤ 0,1 | Bildgrößen, spät ladende UI, Font-Swapping, Layout-Thrash |
| INP | ≤ 200 ms | JS-Bundle-Größe, Hydrationskosten, teure Event-Handler, Drittanbieter-Skripte |
| TTFB (kein CWV, aber kritisch) | ≤ 0,8 s (Faustregel) | Server-Render-Zeit, Cold Starts, Cache-Misses, langsame APIs/DB |
Zwei wichtige Klarstellungen:
- Lab-Scores sind nicht Nutzererlebnis. Lighthouse ist nützlich, aber ein synthetischer Lauf auf einem bestimmten Maschinen-/Netzwerkprofil.
- Sie brauchen sowohl Field- als auch Lab-Daten. Field-Daten sagen, was reale Nutzer fühlen; Lab-Daten zeigen, wo Sie graben sollten.
Eine Mess-Baseline aufbauen (bevor Sie Code anfassen)
Field-Metriken (RUM) nutzen, um nicht „das Falsche zu optimieren"
Real User Monitoring (RUM) beantwortet: „Welche Routen sind für reale Nutzer auf realen Geräten langsam?"
Erfassen Sie mindestens:
- Route/Pfad
- LCP, CLS, INP
- TTFB (oder Server-Timing-Daten)
- Geräteklasse (mobile/desktop), wenn verfügbar Netzwerk-Hints
- Release/Version (damit Sie Regressionen erkennen)
Wenn Sie das schnell umsetzen wollen, liefert die web-vitals-Bibliothek die Rohmetriken — Sie können sie an Ihren eigenen Endpoint weiterleiten.
Lab-Tools nutzen, um den Engpass zu lokalisieren
Für die Diagnose wollen Sie wiederholbare, handlungsorientierte Traces:
- Chrome DevTools Performance-Panel: Main-Thread-Arbeit, Long Tasks, Layout-Thrash
- Lighthouse: schnelle Checks, CI-tauglich, gut für Regressionen
- WebPageTest: Detail auf Wasserfall-Ebene, hervorragend für TTFB vs. Asset-Loading
- React DevTools Profiler: Komponenten-Re-Render-Kosten
Eine einfache, aber effektive Praxis ist es, einen „Golden"-Test auf den 3 bis 5 wichtigsten Routen zu fahren und diese Profile als Referenzen zu sichern.
Ein praktischer Tuning-Workflow für Next.js
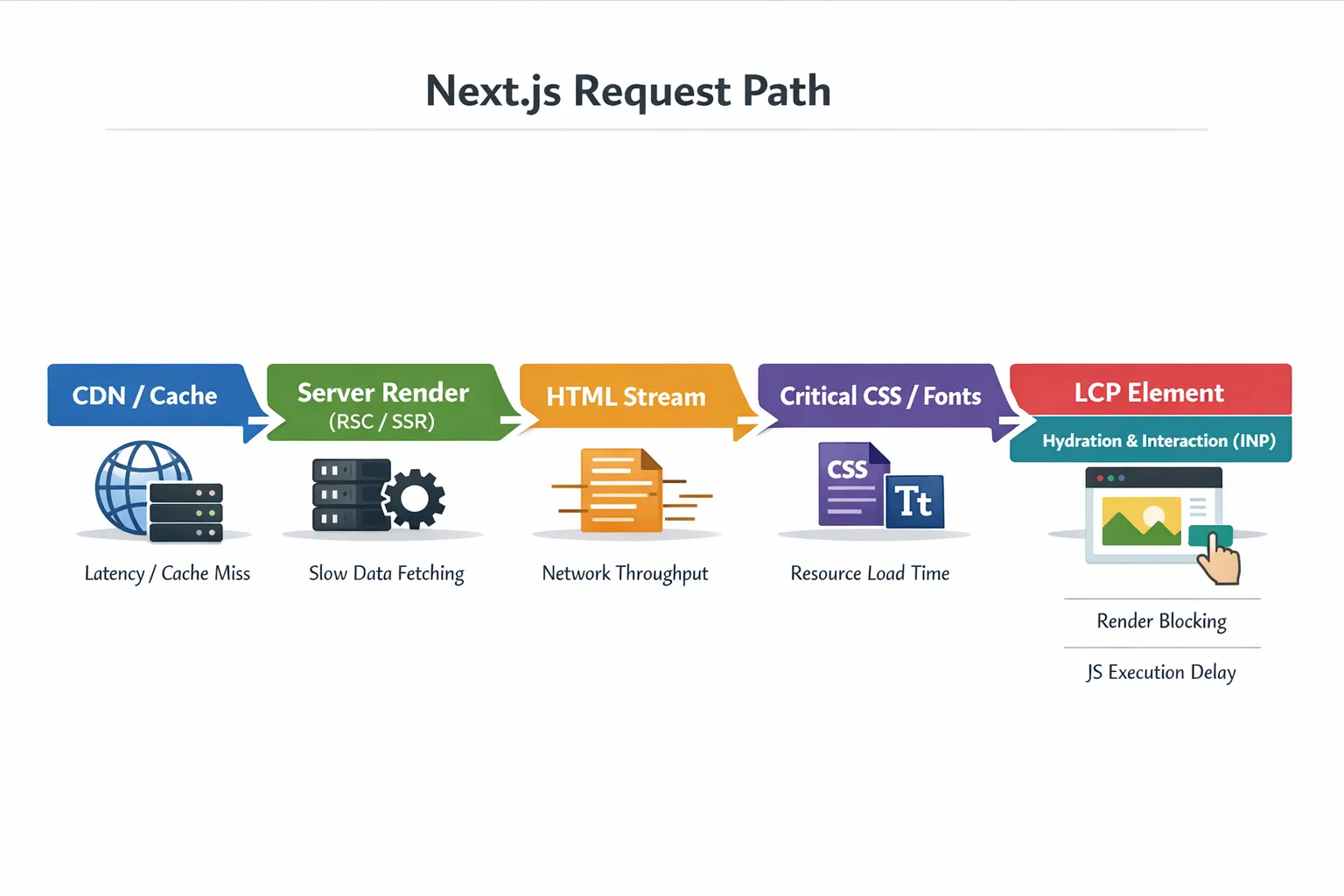
1) Bestimmen, welche Phase langsam ist: Server, Netzwerk oder Browser
Die meisten Next.js-Performance-Probleme zeigen sich in einem der folgenden Muster:
| Symptom | Wie bestätigen | Typische Ursachen | Hebelreiche Fixes |
|---|---|---|---|
| Hoher TTFB | WebPageTest-Wasserfall, Server-Logs | Cache-Misses, langsame DB/API, schwere SSR, Cold Starts | Caching, Server-Arbeit reduzieren, Queries optimieren, Arbeit vom Request-Pfad nehmen |
| LCP langsam, TTFB ok | Lighthouse, Filmstrip | großes Hero-Bild, render-blocking CSS, Fonts | Bilder/Fonts optimieren, Critical CSS reduzieren, richtige Assets preloaden |
| INP schlecht | RUM + DevTools Long Tasks | zu viel Client-JS, schwere Hydration, Drittanbieter-Skripte | Client-Bundles verkleinern, Skripte deferieren, Re-Renders reduzieren |
| CLS schlecht | Lighthouse + Layout-Shift-Regionen | fehlende Bildmaße, späte UI-Insertion, Font-Swapping | Größen/Aspect-Ratio setzen, stabile Skeletons, Font-Strategie |
Treffen Sie diese Entscheidung zuerst. Wenn Sie raten, „fixen" Sie häufig etwas, das Ihre echten Metriken nicht bewegt.
2) Client-seitiges JavaScript reduzieren (meist der größte INP-Gewinn)
Im modernen Next.js kommen die konsistentesten Performance-Gewinne daraus, weniger JavaScript auszuliefern und weniger Arbeit im Main-Thread zu erledigen.
Häufige Ursachen für übermäßiges Client-JS:
- Zu viele Komponenten mit
"use client"markiert - Schwere UI-Bibliotheken, die auf jeder Route geladen werden
- Große JSON-Payloads, die an den Client übergeben werden
- Drittanbieter-Analytics, Chat-Widgets, A/B-Testing-Skripte
Praktische Tuning-Schritte:
- Halten Sie Client-Komponenten dünn; verschieben Sie Datenformung und Formatierung auf den Server.
- Splitten Sie nicht-kritische UI per dynamic Import. Beispiel für einen schweren Editor oder Chart:
import dynamic from "next/dynamic";
const Chart = dynamic(() => import("./Chart"), {
ssr: false,
loading: () => <div style={{ minHeight: 240 }} />,
});
- Auditieren Sie route-level Bundles. Suchen Sie nach „immer geladenen" Dependencies, die hinter Routen-Grenzen verschoben werden könnten.
- Vermeiden Sie es, große Objekte an den Client zu senden. Wenn Sie nur 5 Felder brauchen, serialisieren Sie nicht 50.
Wenn Sie eine tiefere begleitende Lektüre zu React-seitigen Patterns wollen, die Re-Render-Arbeit reduzieren, lesen Sie den Wolf-Tech-Leitfaden zu React-Patterns für Enterprise-UIs.
3) LCP fixen, indem der Hero-Pfad als Produktfeature behandelt wird
LCP wird oft von einer kleinen Menge an Assets und Layout-Entscheidungen oberhalb des Folds entschieden.
Hebelreiche Checks, die leicht übersehen werden:
- Ihr LCP-Element ist häufig das Hero-Bild, die Headline oder eine große Banner-Komponente.
- Wenn das Hero ein Bild ist, stellen Sie sicher, dass Sie
next/imagekorrekt einsetzen. - Stellen Sie sicher, dass width/height (oder eine Aspect-Ratio-Strategie) stabil sind, damit der Browser früh Platz reservieren kann.
Ein praktisches Mentalmodell: Alles, was den ersten meaningful paint blockiert, ist Teil Ihres „Critical Rendering Paths". Halten Sie ihn bewusst klein.
4) Layout-Shifts an der Quelle stoppen (CLS)
CLS-Verbesserungen sind oft unkompliziert, sobald Sie das verschobene Element identifizieren.
Häufige Fixes in Next.js-Projekten:
- Reservieren Sie immer Platz für Bilder und Embeds (explizite Maße oder stabile Aspect-Ratio-Container).
- Vermeiden Sie es, Banner/Tooltips nach dem Laden oben einzublenden. Wenn Sie es müssen, reservieren Sie einen Slot.
- Seien Sie vorsichtig mit Font-Swapping. Nutzen Sie wo möglich Next.js' Font-Tooling und vermeiden Sie späte Font-Loads, die große Textblöcke neu fließen lassen.
5) Datenfetching planbar machen: cachen, deduplizieren und Wasserfälle beseitigen
Langsame Seiten sind häufig „schnelle UI, langsame Daten". Die größte Performance-Verschiebung passiert, wenn Sie Cache-Misses und Request-Wasserfälle beseitigen.
Praktische Taktiken:
- Wasserfälle beseitigen: Wenn Sie A holen, dann B holen, B aber nur eine ID braucht, die Sie bereits haben — refactorn Sie. Parallelisieren Sie, wo möglich.
- Stabile Daten cachen: Produktkataloge, Navigation, Permissions und Feature Flags brauchen häufig keine Pro-Request-Berechnung.
- Teure Aggregation vom Request-Pfad nehmen: vorberechnen, denormalisieren oder berechnete Views cachen.
Das überschneidet sich mit architektonischen Best Practices, aber das Tuning-Mindset ist anders: Sie wählen nicht theoretisch eine Rendering-Strategie, sondern schauen auf die gemessene TTFB der Route und die Cache-Hit-Rate und machen sie langweilig und wiederholbar.
Für eine breitere skalierungsorientierte Perspektive (Rendering-Strategie-Entscheidungen, Caching-Patterns und operative Defaults) ist Wolf-Techs Next.js Best Practices für skalierbare Apps eine nützliche Ergänzung.
6) Drittanbieter-Skripte als Performance-Schulden behandeln (denn das sind sie)
Drittanbieter-Skripte können INP dominieren und LCP verzögern. Selbst „kleine" Tags fügen häufig hinzu:
- zusätzliche Netzwerkverbindungen
- lange Main-Thread-Tasks
- Layout-Shifts durch eingefügte UI
Laden Sie in Next.js Drittanbieter-Skripte bewusst (nicht „einfach ins Layout pasten") und prüfen Sie:
- Muss es vor der Interaktivität laufen?
- Kann es nach Nutzerinteraktion laden?
- Können Sie es auf bestimmte Routen begrenzen?
Next.js bietet next/script mit verschiedenen Lade-Strategien. Die richtige Wahl hängt davon ab, was das Skript tut, aber das Tuning-Prinzip ist universell: Lassen Sie Drittanbieter standardmäßig nicht im Critical Path ausführen.
Server- und Infrastruktur-Tuning, das TTFB bewegt
Client-seitige Optimierung hilft nur begrenzt, wenn Ihr Serverpfad langsam oder inkonsistent ist.
Cold Starts und Runtime-Overhead reduzieren
Wenn Sie eine „spitze" TTFB-Verteilung sehen, in der p50 ok ist, aber p95 schlecht, haben Sie häufig eines davon:
- Cold Starts
- ungleiche Cache-Hit-Raten
- Noisy-Neighbor-Ressourcenkonflikte
- langsame externe Abhängigkeiten
Fixes hängen von Hosting und Architektur ab, fallen aber meist in:
- Erhöhung der Cache-Hit-Rate (Vollseite, Datenebene oder CDN)
- schwere Arbeit aus dem Request-Pfad entfernen
- Infrastruktur-Kapazität und Concurrency tunen
Hier zahlt sich eine reife DevOps- und SRE-Praxis aus.
Den Backend-Pfad optimieren (DB und APIs)
Wenn das Server-Rendering auf langsame APIs oder Queries wartet, sieht Ihre Next.js-App „langsam" aus, egal wie optimiert die UI ist.
Hebelreiche Backend-Fixes, die routinemäßig die Next.js-TTFB verbessern:
- Den fehlenden Index für eine Top-Query hinzufügen.
- N+1-Query-Patterns in Ihrer API-Schicht entfernen.
- Teure Joins/Aggregationen cachen.
- Timeouts, Retries und Circuit Breaker einsetzen, damit eine degradierte Abhängigkeit nicht jede Seite herunterzieht.
Wenn Sie ein zuverlässigkeitsfokussiertes Playbook wollen, das gut zu Performance-Arbeit passt (denn langsam ist oft eine Form von Fehler), ist Wolf-Techs Backend-Reliability-Best-Practices eine solide Referenz.
Performance-Verbesserungen halten (CI, Budgets und Guardrails)
Die schnellsten Teams sind nicht die mit einem heroischen Performance-Sprint. Es sind die, die verhindern, dass Performance schlechter wird, während das Produkt wächst.
Performance-Budgets, die zur Nutzererfahrung passen
Budgets sollten an Nutzer-Impact gebunden sein, nicht an Vanity-Zahlen. Beispiele, die gut funktionieren:
| Budget-Typ | Beispiel-Schwelle | Warum es Regressionen verhindert |
|---|---|---|
| Route-Level LCP | Darf Baseline um nicht mehr als 10 % übersteigen | Erfasst echte UX-Degradation |
| Client-JS pro Route | Unter einer vereinbarten Grenze halten | Verhindert schleichende Hydration und INP |
| Long Tasks | Keine Long Tasks über 200 ms in Schlüsselflüssen | Verbessert direkt die Reaktivität |
| Bildgewicht above the fold | Hero-Bild unter einer festen Größe | Verhindert LCP-Regressionen |
Sie können Budgets in CI mit Lighthouse (oder Lighthouse CI) für eine kleine Menge kritischer Routen erzwingen und in der Produktion mit RUM validieren.
Releases mit „vorher vs. nachher"-Vergleichen instrumentieren
Ein praktischer Ansatz:
- RUM-Metriken mit einem Build-SHA oder einer Version taggen.
- p75-Metriken für Schlüsselrouten zwischen Releases vergleichen.
- Bei anhaltender Regression alarmieren — nicht bei einzelnen Spikes.
So wird Performance-Tuning zur operativen Fähigkeit, nicht zur einmaligen Aufgabe.

Wann Sie Expertenhilfe holen sollten
Wenn Sie nach grundlegendem Tuning feststecken, sitzt der Engpass meist an einer Grenze:
- eine Route, die unerwartet zwischen statisch und dynamisch wechselt
- eine Backend-Abhängigkeit, die zeitweise langsam ist
- ein Client-Bundle, das klein wirkt, bis Sie Drittanbieter-Skripte einrechnen
- eine Caching-Strategie, die korrekt ist, aber keine konsistenten Hit-Raten erzielt
Wolf-Tech kann unterstützen, indem ein strukturiertes Performance-Audit (RUM plus Lab-Profiling) gefahren wird, der spezifische Engpass pro Schlüsselroute identifiziert wird und Fixes ausgeliefert werden, die Core Web Vitals verbessern, ohne Ihre Architektur zu destabilisieren. Wenn Sie bereits eine Next.js-Codebase skalieren, liefert die Kombination mit einem Code-Quality- und Delivery-Review oft die schnellsten Gesamtgewinne.
Wenn Sie das in einen wiederholbaren Plan überführen wollen, wählen Sie Ihre Top-3-User-Journeys, sammeln Sie eine Woche Field-Metriken und führen Sie dann einen gezielten Tuning-Sprint mit Fokus auf die größte Engpass-Kategorie (TTFB, LCP, INP oder CLS). Performance-Tuning ist am wirksamsten, wenn Sie es als Schleife behandeln: messen, eine Variable ändern, verifizieren — und mit Guardrails fixieren.