
React Website Performance: LCP, CLS und TTFB verbessern


Wenn Ihre React-Website auf Ihrem Rechner einwandfrei läuft, Nutzer aber Ruckler, langsames Hero-Rendering oder schwankende Lighthouse-Werte erleben, kämpfen Sie meist gegen drei verschiedene Probleme unter einem vagen Begriff: „Performance." Der schnellste Weg voranzukommen besteht darin, sie klar zu trennen:
- LCP (Largest Contentful Paint): Wie schnell der Hauptinhalt sichtbar wird.
- CLS (Cumulative Layout Shift): Wie stabil die Seite während des Ladens ist.
- TTFB (Time to First Byte): Wie schnell Server und Netzwerk mit der Antwort beginnen.
Googles Leitfaden zu Core Web Vitals benennt klare Schwellenwerte und Messmethoden: Priorisieren Sie Felddaten, nutzen Sie dann Lab-Tools zur Reproduktion und Fehlersuche (web.dev zu Core Web Vitals). Dieser Artikel liefert ein praxisnahes, React-spezifisches Playbook zur Diagnose und Behebung jeder Metrik – ohne blinde Optimierungen.
Was LCP, CLS und TTFB wirklich messen (und warum React-Teams sie verwechseln)
React-Apps verwischen oft die Grenzen zwischen „Server langsam", „Frontend langsam" und „Daten langsam", weil Rendering häufig von JavaScript und API-Calls abhängt. Beginnen Sie mit klaren Definitionen.
| Metrik | Was sie misst | „Gut"-Zielwert (Google) | Häufige Ursachen bei React-Websites |
|---|---|---|---|
| LCP | Wann das größte Element im Viewport sichtbar wird | ≤ 2,5s | Schwere Hero-Bilder, render-blockierendes CSS/JS, Hydration-Kosten, Daten-Waterfalls |
| CLS | Visuelle Stabilität, unerwartete Layout-Verschiebungen | ≤ 0,1 | Bilder ohne Abmessungen, spät geladene Banner, Font-Swaps, Skeletons mit abweichender Höhe |
| TTFB | Zeit bis zum ersten HTML-Byte | ≤ 0,8s (gut), sonst ggf. | Kein CDN-Caching, langsame SSR/Datenbankabfragen, Cold Starts, zu viele Weiterleitungen |
Zwei wichtige Klarstellungen:
- TTFB bedeutet nicht „React ist langsam." Wenn das HTML schnell ankommt, die Seite aber leer bleibt, bis JS geladen wurde und Daten zurückgekehrt sind, ist das typischerweise ein LCP- und Main-Thread-Problem, kein TTFB-Problem.
- CLS ist selten ein einzelner Bug. Es handelt sich meist um viele kleine „nicht reservierte Flächen" bei Bildern, Komponenten und späten UI-Elementen.
Schritt 1: Richtig messen (Felddaten zuerst, Lab-Daten danach)
Performance-Arbeit wird politisch, wenn Sie sich nicht auf eine Basislinie einigen können. Nutzen Sie einen einfachen Mess-Stack, der Antworten liefert wie: „p75 LCP auf Produktdetailseiten in Deutschland auf Mobilgeräten."
Felddaten (was Nutzer erleben)
Nutzen Sie mindestens eine der folgenden Quellen:
- Chrome UX Report (CrUX) via PageSpeed Insights oder BigQuery für reale Core Web Vitals (CrUX-Dokumentation).
- RUM (Real User Monitoring) über Ihren Observability-Anbieter oder eigenes Beaconing.
- Die schlanke
web-vitals-Bibliothek zur Erfassung von LCP, CLS und INP in der Produktion (GitHub: web-vitals).
Ein minimales „nicht überdenken"-Instrumentierungsbeispiel:
import { onCLS, onLCP, onTTFB } from 'web-vitals'
function sendToAnalytics(metric: { name: string; value: number; id: string }) {
navigator.sendBeacon(
'/rum',
JSON.stringify({
name: metric.name,
value: metric.value,
id: metric.id,
path: location.pathname,
})
)
}
onCLS(sendToAnalytics)
onLCP(sendToAnalytics)
onTTFB(sendToAnalytics)
Wenn Sie nur eine Sache tun: Taggen Sie Metriken nach Route/Template (Startseite, Kategorie, Detailseite, Checkout, Marketing-Landingpage). Durchschnittswerte verbergen die wichtigen Seiten.
Lab-Daten (zur Reproduktion und Fehlersuche)
- Lighthouse und PageSpeed Insights für wiederholbare Audits.
- Chrome DevTools Performance-Panel zur Anzeige von Main-Thread-Arbeit, Layout-Shifts, langen Tasks und dem LCP-Element.
- React Profiler für komponentenbezogene Render-Kosten.
Lab-Daten sind keine absolute Wahrheit, aber der schnellste Weg, die eigentliche Ursache zu finden, sobald die Felddaten zeigen, welche Seite versagt.
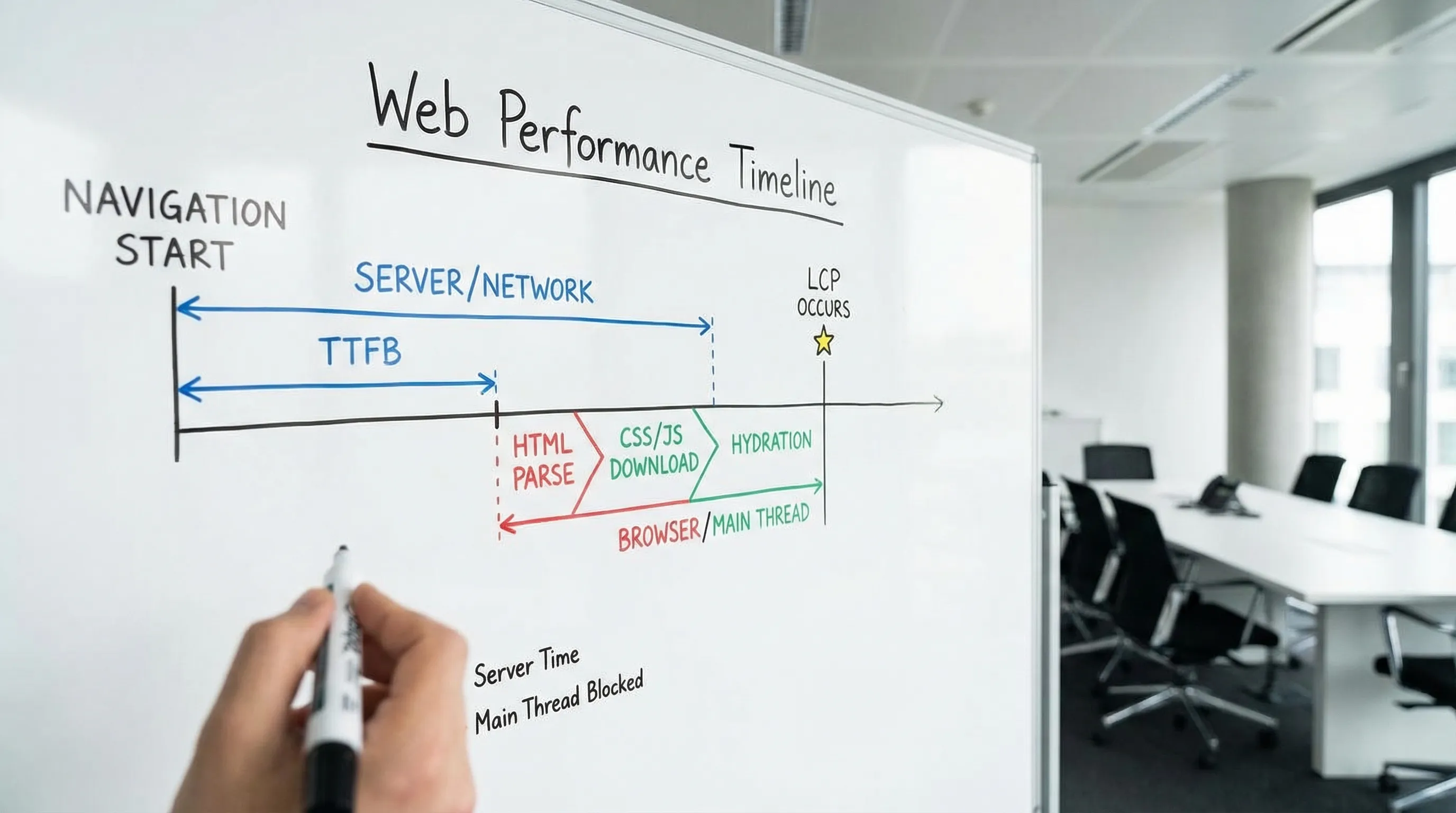
Schritt 2: LCP in einer React-Website beheben (den Hero-Pfad als Produkt-Feature behandeln)
LCP ist meist „das Wichtigste, das Nutzer auf der Seite sehen": Hero-Bild, Produktfoto, Überschriftenblock oder eine große Karte.
LCP-Element identifizieren und verstehen, warum es zu spät kommt
In Chrome DevTools (Performance oder Lighthouse Details) sehen Sie das LCP-Element und seine Timing-Aufschlüsselung. Häufige Muster:
- Das LCP-Element ist ein Bild, das zu langsam lädt.
- Das LCP-Element ist Text, der durch Fonts, CSS oder JS verzögert wird.
- Das LCP-Element hängt von Daten ab, die erst nach einem oder mehreren clientseitigen Waterfalls ankommen.
Wirkungsvolle LCP-Fixes (React-spezifisch)
1) Die LCP-Ressource früher laden (meist Bilder)
Wenn der LCP ein Bild ist, ist das erste Ziel, sicherzustellen, dass der Browser es sofort entdeckt und eine angemessen große Datei herunterlädt.
- Responsive Images verwenden (
srcset,sizes), damit Mobile nicht Desktop-Assets lädt. - Moderne Formate bevorzugen (AVIF/WebP), wo die Pipeline dies unterstützt.
- Vermeiden, dass das Hero-Bild erst nach der Auflösung von clientseitigem Routing-Status geliefert wird.
- Das Hero-Bild vorausladen, wenn es zur Build-Zeit bekannt ist.
Wenn Ihr Stack SSR/SSG unterstützt, stellen Sie sicher, dass die Hero-Bild-URL im initialen HTML vorhanden ist, damit die Entdeckung nicht von der Hydration abhängt.
2) Render-blockierende Arbeit vor dem ersten Hero-Paint reduzieren
React-Websites verzögern LCP oft, weil zu viel JavaScript ausgeführt werden muss, bevor aussagekräftiger Inhalt erscheint.
Praktische Taktiken für SPA- und SSR-Setups:
- Route-Level Code Splitting mit
React.lazy()und dynamischen Imports, damit Ihre Marketing-Route nicht die gesamte App herunterlädt. - Nicht kritische Skripte (Analytics, Chat-Widgets) entfernen oder aufschieben, bis nach dem ersten Paint.
- Abhängigkeiten prüfen, die Bundles aufblähen (Datumsbibliotheken, Editor-Toolkits, Charting-Libs), und sie auf die Routen beschränken, die sie benötigen.
Bundle-Analyse ist häufig der schnellste Gewinn. Die meisten Build-Tools können die Chunk-Zusammensetzung visualisieren.
3) Daten-Waterfalls auf dem kritischen Pfad vermeiden
Ein häufiger LCP-Killer in React ist „rendern, dann fetchen, dann erneut rendern, dann mehr fetchen." Dies passiert typischerweise, wenn:
- Komponenten ihre Daten unabhängig voneinander fetchen.
- Auth/Session-Prüfungen Seiten-Daten blockieren.
- Das API-Shape mehrere sequentielle Aufrufe erfordert.
Lösungsansätze:
- Kritische Daten an der Route-Grenze fetchen, nicht tief im Komponentenbaum.
- Unabhängige Aufrufe parallelisieren.
- Einen BFF (Backend for Frontend) oder Aggregations-Endpunkt hinzufügen, wenn die UI ein einziges View-Modell benötigt.
- Server-Antworten für öffentliche Inhalte aggressiv cachen.
Für einen breiteren Architektur-Rahmen für React-Teams hilft Wolf-Techs Leitfaden zu Seams, State-Typen und Grenzen, diese Performance-Fallen zu vermeiden: React Front-End-Architektur für Produktteams.
4) Fonts: Text schnell und vorhersehbar rendern
Wenn LCP eine große Überschrift ist, kann das Laden von Fonts sie verzögern.
- Zu Font-Origins vorverbinden, wenn ein Font-CDN verwendet wird.
font-display: swapverwenden, damit Text sofort gerendert wird.- Wenn Layout-Shifts durch Font-Swapping auftreten, dieses Problem unter CLS (unten) mit Font-Metric-Overrides angehen.
Googles allgemeiner Leitfaden zur LCP-Optimierung betont die Priorisierung kritischer Ressourcen und die Reduzierung render-blockierender Arbeit (LCP optimieren).
Schritt 3: CLS beheben (Stabilität ist ein Design- und Engineering-Vertrag)
CLS wird oft unterschätzt, weil die Seite für Entwickler auf schnellen Verbindungen „gut aussieht". Im Einsatz sehen Nutzer späte Banner, größenverändernde Bilder und UI, die springt, wenn Daten ankommen.
Die CLS-Ursachen, die Sie zuerst prüfen sollten
1) Bilder und Medien ohne reservierten Platz
Wenn Inhalte später in eine Box geladen werden, die keine explizite Größe hatte, muss der Browser die Seite neu layouten.
- Immer
widthundheightbei Bildern angeben oder CSSaspect-ratioverwenden. - Für responsive Layouts mit einem Container mit festem Seitenverhältnis Platz reservieren.
- Embeds (iframes, Videos) genauso behandeln.
2) Skeletons und Platzhalter, die nicht zum endgültigen Layout passen
Skeleton-UIs sind großartig – bis die Skeleton-Höhe vom endgültigen Inhalt abweicht.
- Stabile Platzhalter verwenden, die den endgültigen Komponentenabmessungen entsprechen.
- „Lade-Spinner" vermeiden, die einen Abschnitt kollabieren und dann expandieren lassen.
3) Späte UI, die über bestehendem Inhalt eingefügt wird
Häufige Verursacher:
- Cookie-Zustimmungsleisten, die Inhalt nach unten verschieben.
- Promo-Banner, die nach der Hydration eingefügt werden.
- Formular-Validierungszusammenfassungen, die nach dem Absenden oben erscheinen.
Für späte UI Overlays bevorzugen oder von Anfang an Platz für Banner reservieren.
4) Font-Swaps, die Layout-Shift verursachen
Selbst mit font-display: swap kann der Wechsel zu einer Web-Font die Textbreite und Zeilenumbrüche ändern.
Abhilfemaßnahmen:
- Fallback-Fonts mit ähnlichen Metriken verwenden.
size-adjust,ascent-override,descent-overrideundline-gap-overridein@font-facein Betracht ziehen, um Metriken anzupassen und Verschiebungen zu reduzieren.
Referenz: web.dev zu Layout-Shifts verhindern.
Eine praktische CLS-Checkliste für das Team
- Sicherstellen, dass alle Bilder, iframes und Video-Container Platz reservieren.
- Platz reservieren (oder Overlays verwenden) für Banner und Consent-UI.
- Skeletons dimensionsmäßig konsistent mit den endgültigen Komponenten machen.
- Vermeiden, Inhalt über dem Fold nach dem initialen Render einzufügen.
- Transform-basierte Animationen verwenden (
transform,opacity), keine layout-ändernden Animationen (top,height).
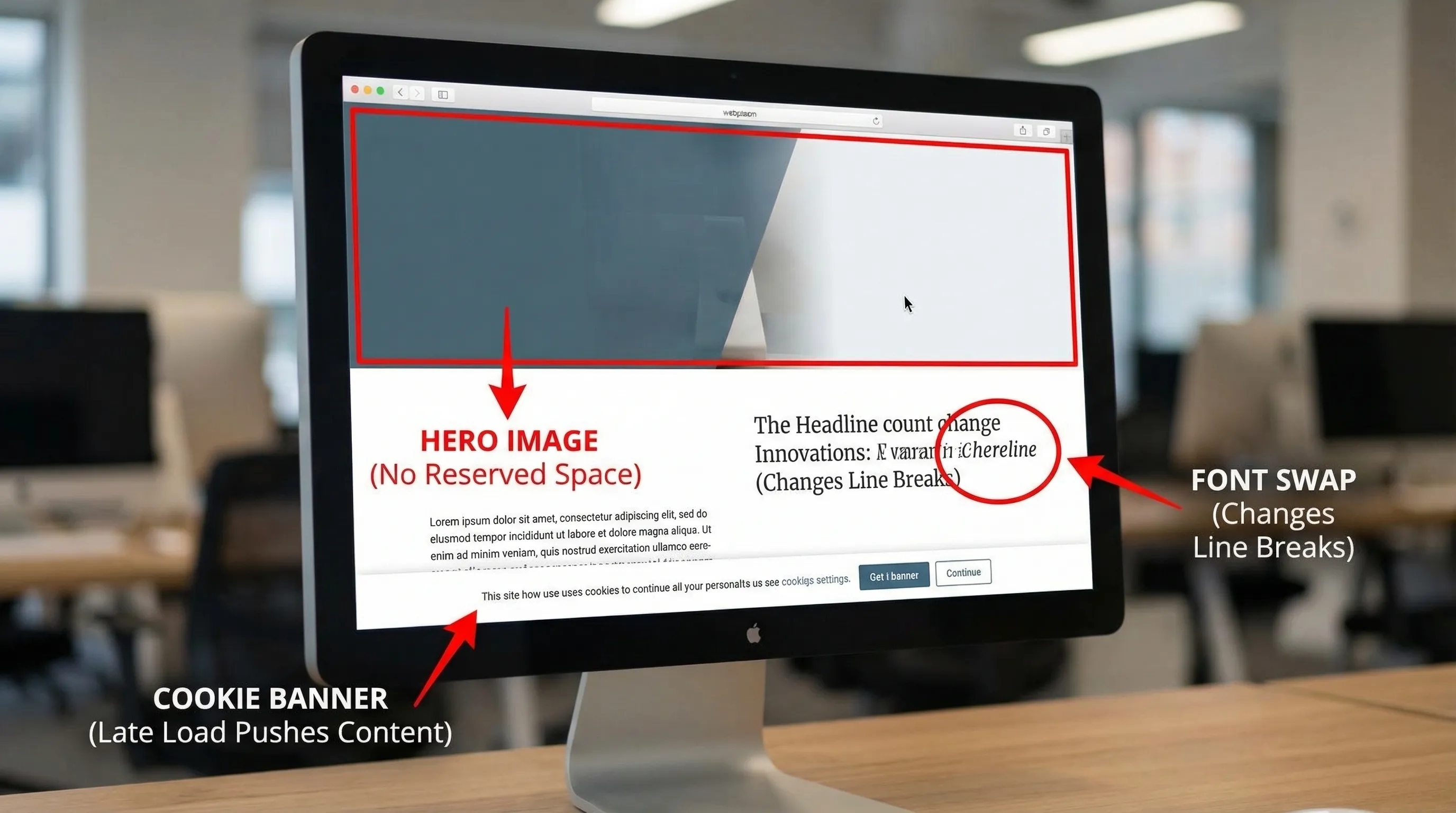
Schritt 4: TTFB beheben (Caching-Probleme von Backend-Latenz trennen)
TTFB ist eine Server- und Delivery-Metrik. Bei einer React-Website hängt sie davon ab, ob Sie statisches HTML, SSR oder eine App-Shell ausliefern.
TTFB mit einer einfachen Aufschlüsselung diagnostizieren
Wenn TTFB hoch ist, liegt es meist an einem dieser Faktoren:
- Zu weit vom Nutzer entfernt (kein CDN, falsche Region, kein Edge-Caching).
- Zu viel Server-Arbeit pro Request (SSR mit schwerem Aufwand, langsame APIs, langsame Datenbankabfragen).
- Cold Starts (Serverless-Funktionen, die aufwachen, neue Container).
- Redirect-Chains (http zu https, www zu Apex, Locale-Weiterleitungen).
Bevor Sie Code ändern, bestätigen Sie den Engpass:
- Server-Timing-Header (
Server-Timing) verwenden, um SSR-Zeit, DB-Zeit, Cache-Hit oder -Miss zu zeigen. - Tracing (OpenTelemetry, APM-Anbieter) nutzen, um zu identifizieren, wo der Request Zeit verbringt.
Wirkungsvolle TTFB-Fixes
1) Das HTML cachen (oder die Generierung per Request vermeiden)
Wenn Ihre „Website"-Seiten überwiegend öffentlich und inhaltsgetrieben sind, bringt das Verschieben in Richtung Static Generation oder gecachtes SSR meist die größten TTFB-Verbesserungen.
- Ein CDN vor den Origin stellen.
- Cache-Header verwenden, die Edge-Caching ermöglichen.
- Sicherstellen, dass personalisierter Inhalt das Caching nicht versehentlich für alle deaktiviert.
2) Server-seitige Waterfalls entfernen
Wenn SSR auf mehrere Backend-Aufrufe wartet, wächst TTFB mit jeder Abhängigkeit.
- Server-seitige Fetches parallelisieren.
- Aggregations-Endpunkte für seitenweite View-Modelle hinzufügen.
- Teure Berechnungen cachen.
3) Backend-Hot-Paths beheben (Datenbank und APIs)
TTFB ist oft ein Symptom langsamen Datenzugriffs.
- Langsame Abfragen identifizieren, die richtigen Indizes hinzufügen und N+1-Muster eliminieren.
- Connection Pooling angemessen verwenden.
- Nicht kritische Arbeit vom Request-Pfad entfernen.
Für eine breitere „system-level"-Optimierungsmentalität (jenseits von Mikro-Tuning) ist dieser Wolf-Tech-Artikel ein guter Begleiter: Code optimieren: Wirkungsvolle Fixes jenseits von Mikro-Optimierungen.
4) Redirect-Chains eliminieren
Weiterleitungen sind leicht zu übersehen und auf Mobilgeräten teuer.
- Mehrere Weiterleitungen zu einer zusammenfassen.
- Kanonischen Host und Protokoll am Edge festlegen.
Schritt 5: Regressionen mit Budgets und Leitplanken verhindern
Ein einmaliger Performance-Sprint hilft, aber Performance verfällt, wenn Sie sie nicht Teil der Delivery machen.
Performance-Budgets hinzufügen, die zu Ihrem Geschäft passen
Sie brauchen kein aufwändiges System. Beginnen Sie mit Budgets, die an das geknüpft sind, was Sie bereits messen:
| Leitplanke | Was sie verhindert | Wie durchsetzen |
|---|---|---|
| LCP- und CLS-Schwellenwerte pro Schlüsselroute | Langsamer Hero-Pfad, Layout-Instabilität | RUM-Alerts, wöchentliche p75-Überprüfung |
| Bundle-Größen-Checks | „Nur noch eine Abhängigkeit"-Wachstum | CI-Schritt, Bundle-Analyzer in PR |
| Drittanbieter-Skript-Richtlinie | Tag-Wildwuchs | Review verlangen, nach Interaktion laden |
| Synthetische Checks für Top-Seiten | Stille Brüche | Geplante Lighthouse-Läufe |
Performance-Verantwortung explizit machen
Das zuverlässigste Muster ist, Performance als cross-funktionalen Vertrag zu behandeln:
- Product definiert, welche Routen umsatzkritisch sind.
- Design verpflichtet sich zu stabilen Layout-Mustern.
- Engineering verpflichtet sich zu Budgets und Durchsetzung.
- Ops verpflichtet sich zu Caching- und Latenz-SLOs.
Wolf-Techs Ansatz zu „testbaren Nachweisen" in der Frontend-Delivery passt gut zu Performance-Arbeit, da er Budgets und Belege zum Bestandteil der Definition of Done macht: Frontend-Entwicklungsdienstleistungen: Lieferergebnisse, die zählen.
Ein pragmatischer 10-Tage-Plan zur Verbesserung einer React-Website
Wenn Sie Momentum wollen, ohne daraus eine quartalslanges Vorhaben zu machen:
Tage 1 bis 2: Basislinie erstellen und Zielrouten auswählen
Fokus auf 2 bis 4 Templates, die Conversions oder Akquisition antreiben.
Tage 3 bis 6: Größte LCP- und CLS-Probleme pro Route beheben
LCP- und CLS-Verbesserungen liefern sich meist in kleinen, überprüfbaren Änderungen: Bildgrößen, Preloads, Entfernen eines blockierenden Skripts, Layoutraum reservieren.
Tage 7 bis 8: TTFB und Caching-Durchgang
Server-Timing hinzufügen, Weiterleitungen beheben, CDN-Verhalten validieren und den langsamsten SSR- oder API-Pfad angehen.
Tage 9 bis 10: Leitplanken einführen
Budgets, CI-Checks und grundlegende RUM-Alerts einführen, damit die Gewinne nicht verloren gehen.
Wann Sie ein externes Performance-Review hinzuziehen sollten
Erwägen Sie ein externes Audit, wenn:
- Felddaten anhaltende p75-Fehler zeigen und Sie diese nicht zuverlässig reproduzieren können.
- Sie ein gemischtes Rendering-Setup haben (SPA plus SSR) und die Verantwortlichkeiten unklar sind.
- Drittanbieter-Skripte politisch schwer zu kontrollieren sind.
- Backend-Latenz und Frontend-Rendering beide als Verdächtige gelten.
Wolf-Tech hilft Teams beim Aufbau, der Optimierung und Skalierung von React- und Full-Stack-Produktionssystemen – einschließlich performance-fokussierter Reviews und Modernisierungsarbeit. Wenn Sie einen messungsorientierten Plan wollen, der LCP, CLS und TTFB mit klaren Nachweisen und Regressions-Leitplanken angeht, beginnen Sie bei Wolf-Tech und wir erarbeiten gemeinsam ein kurzes, signalreiches Engagement.