
Agile That Ships: Rituals, Metrics, and Anti-Patterns


Most teams don’t fail at agile development because they skip ceremonies. They fail because their agile system does not reliably turn ideas into safe production changes.
If you want “agile development that ships,” treat shipping as a capability with three parts:
- Rituals that force clarity, slicing, and fast feedback.
- Metrics that measure flow and production outcomes (not activity).
- Anti-pattern detection that prevents agile from quietly turning into mini-waterfall.
Below is a pragmatic playbook you can implement with a single team first, then scale.
What “ships” actually means (and why most teams miss it)
A surprising amount of delivery dysfunction comes from a fuzzy definition of “done.” In shipping teams, “done” is not “merged” and not “QA approved.” It is usable in production (or safely releasable), observable, and reversible.
A practical way to align stakeholders is to define levels of done explicitly.
| Level | What people say | What it really means | Risk you’re carrying |
|---|---|---|---|
| Done-0 | “It’s coded” | Local build passes | Unknown integration risk |
| Done-1 | “It’s in a PR” | Review started | Queue time and context churn |
| Done-2 | “Merged” | Main branch green | Release risk is accumulating |
| Done-3 | “Deployed” | Running in prod behind a flag | Low, if monitoring exists |
| Done-4 | “Shipped” | Exposed to users with telemetry | You can learn and iterate |
If your org celebrates Done-2, you will feel busy and still ship slowly.
A strong Definition of Done usually includes:
- Automated checks (tests, linting, security baseline as appropriate)
- Deployment path proven (even if gated by approvals)
- Observability in place for the change (logs/metrics/traces or at least targeted monitoring)
- Rollback plan (or safe rollout strategy)
This aligns with the core idea of the Agile Manifesto (working software) and the operational discipline popularized by SRE and modern delivery research.
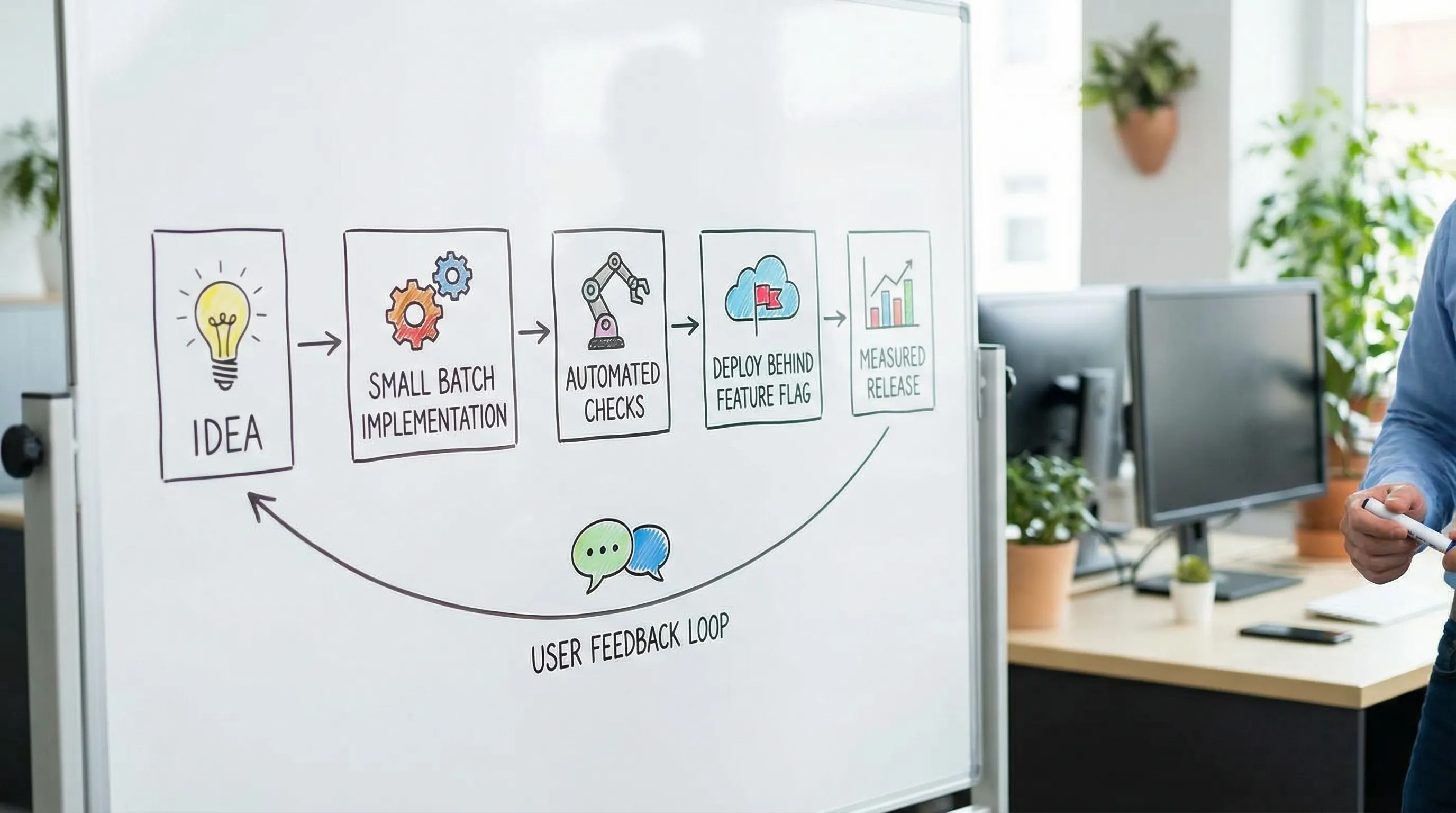
Rituals that create shipping momentum (without bureaucracy)
Rituals are not meetings. They are repeating constraints that prevent work from becoming too big, too vague, or too risky.
The best rituals share one trait: they produce an artifact or decision that makes shipping easier.
1) Weekly Outcome Review (30 minutes)
Purpose: keep product, engineering, and stakeholders aligned on outcomes and trade-offs.
Agenda:
- What did we ship that moved a measurable outcome?
- What did we learn (from production data or users)?
- What is the next biggest risk (scope, performance, reliability, security, integration)?
- What decision is needed this week (and who owns it)?
This prevents the common drift where agile becomes “sprint execution” detached from business impact.
2) Backlog Refinement as “Slicing + Risk Burn-down”
If refinement is only rewriting tickets, it becomes theater.
High-signal refinement produces:
- A thin vertical slice that can reach production quickly
- Named risks with a test plan (integration, performance budget, data migration, permissions)
- Clear acceptance criteria that match real states (errors, empty data, latency, roles)
A useful rule: if a story cannot be deployed independently (even behind a feature flag), it is probably too big or too coupled.
3) Planning that commits to learning, not guesses
Planning should create a delivery plan for the next iteration and expose uncertainty early.
What works well in practice:
- Plan around the smallest shippable increments.
- Call out “discovery work” explicitly (spikes, prototypes, thin vertical slice) instead of hiding it inside estimates.
- Keep the plan adjustable, but don’t keep it vague.
If you need estimates, use them as risk signals, not performance targets.
4) Daily Sync that protects flow
A daily standup should be a control loop for flow, not a status report.
Use three questions that map to shipping:
- What is the oldest piece of work in progress?
- What is blocking it from reaching production?
- What coordination is needed today to keep batch size small?
This simple shift reduces WIP creep, long-lived branches, and late surprises.
5) Demo that proves “potentially shippable”
A demo is valuable only if it proves reality.
High-signal demo defaults:
- Demo from a production-like environment (or production behind a flag)
- Show error states and permissions, not just happy paths
- Include one operational proof when relevant (latency, logs, alert, dashboard)
This forces engineering and product to align on what “works” means.
6) Retro that ends with one measurable experiment
Retros fail when they produce insights but no changes.
A practical retro output:
- One improvement experiment
- One owner
- One expected measurable effect within 1 to 2 weeks
Example: “Reduce PR cycle time by limiting PR size to X files or Y lines (soft limit) and introducing pairing for risky refactors.”
7) The missing ritual: Change Review (15 minutes, twice a week)
Many teams have sprint rituals but no release ritual.
A lightweight Change Review:
- What is ready to deploy now?
- What is blocked on rollout or approvals?
- What is the rollout plan (flag, canary, phased release)?
- What is the monitoring signal we’ll watch?
This is where agile turns into shipping.
Suggested cadence (example)
| Cadence | Ritual | Output |
|---|---|---|
| Weekly | Outcome review | Decision log, next risks |
| Weekly | Refinement | Thin slices ready |
| Bi-weekly (or weekly) | Planning | Shippable plan |
| Daily | Flow sync | Blockers removed, WIP controlled |
| 1 to 2x/week | Change review | Releases happening |
| Bi-weekly | Retro | One measurable experiment |
Metrics that predict shipping (and which ones lie)
Metrics are not for reporting. They are for steering.
A good shipping metric is:
- Close to production reality
- Hard to game
- Actionable within days, not quarters
The core: DORA metrics (use them as a system)
The most widely adopted delivery performance measures are the four DORA metrics, popularized by the research behind Accelerate and maintained by the DevOps Research and Assessment program (now under Google Cloud). A clear overview is available on Google Cloud’s DORA resources.
| Metric | What it tells you | What usually breaks when it’s bad |
|---|---|---|
| Deployment frequency | How often value reaches users | Releases are painful, too manual |
| Lead time for changes | How fast code goes from commit to prod | Big batches, slow reviews, brittle pipeline |
| Change failure rate | How often changes cause incidents/rollback | Weak testing, risky releases, hidden coupling |
| Time to restore service (MTTR) | How fast you recover | Poor observability, unclear ownership, no runbooks |
Important: treat these as a balanced set. Optimizing one in isolation can create harm (for example, higher deploy frequency without safety can spike change failure rate).
Add flow metrics to find the bottleneck
DORA tells you “how you’re doing.” Flow metrics help you understand “where time is going.”
Track these per team (weekly trend, not daily noise):
- WIP (work in progress): too high means long cycle times and hidden queues.
- PR cycle time: time from PR opened to merged, often your biggest controllable delay.
- Work item age: how long the oldest in-progress item has been sitting.
These are especially effective when paired with one rule: finish work before starting more work.
Quality and reliability: measure what users feel
If you ship often but users suffer, you are not truly shipping.
Two practical additions:
- Defect escape rate: bugs found after release versus before release.
- Service reliability via SLIs/SLOs (availability, latency, error rate), a discipline described in Google’s Site Reliability Engineering book.
If you are not ready for formal SLOs, start with one “golden signal” per critical user journey (login, checkout, search, core workflow).
A lightweight “Shipping Scorecard” you can review weekly
| Area | Metric | Healthy question |
|---|---|---|
| Flow | Lead time for changes | “What is slowing commit-to-prod?” |
| Flow | PR cycle time | “Where are we waiting, review or CI?” |
| Throughput | Deployment frequency | “Can we release smaller increments?” |
| Safety | Change failure rate | “Which change types are risky and why?” |
| Recovery | MTTR | “Do we detect issues fast and know what to do?” |
| Product | One outcome metric | “Did shipping change user behavior?” |
Metrics that commonly backfire
Use these carefully, or not at all:
- Velocity / story points as productivity: incentivizes bigger estimates, not better flow.
- Utilization: drives more WIP, queues, and burnout.
- Lines of code: rewards output, not outcomes.
If you need a deeper, code-centric measurement approach, align it with shipping outcomes rather than vanity. (Wolf-Tech has a dedicated guide on code quality metrics that matter.)
Anti-patterns that stop agile from shipping (and what to do instead)
Most agile failures are predictable. Here are the ones that show up repeatedly in scaling teams.
Anti-pattern 1: “Sprint = mini-waterfall”
Symptoms: planning up front, build for 10 days, QA at the end, spillover every sprint.
Fix: make work slices deployable independently. Use feature flags and ship continuously inside the sprint. Treat testing and operability as part of the slice.
Anti-pattern 2: Definition of Done stops at merge
Symptoms: sprint ends, then a release train starts. “Done” piles up.
Fix: update Definition of Done so work is either deployed or demonstrably releasable (flagged) with monitoring. Add a twice-weekly Change Review.
Anti-pattern 3: Long-lived branches and late integration
Symptoms: painful merges, unpredictable regressions, “integration sprint.”
Fix: prefer trunk-based development, small PRs, and CI that runs fast. If you cannot merge daily, your batch size is too large.
(If your CI/CD path is the constraint, see Wolf-Tech’s guide on CI/CD technology.)
Anti-pattern 4: Estimation becomes a performance contract
Symptoms: teams inflate estimates to hit commitments, avoid risk, or game predictability.
Fix: separate planning from performance evaluation. Use forecasts based on historical throughput and manage risk explicitly.
Anti-pattern 5: Backlog bloat and “maybe someday” work
Symptoms: hundreds of stale items, constant reprioritization, no shared clarity.
Fix: enforce a “backlog hygiene” rule. If an item has no clear outcome, owner, and time window, archive it.
Anti-pattern 6: Handoffs everywhere (product to design to dev to QA to ops)
Symptoms: slow cycle time, miscommunication, local optimization.
Fix: move toward cross-functional ownership for a slice. Even partial shifts help, for example pairing QA with dev during implementation rather than after.
Anti-pattern 7: Retros without change
Symptoms: recurring complaints, no experiments, cynicism.
Fix: one experiment per retro, one owner, one expected measurable effect. Track it next retro.
A quick mapping from anti-pattern to measurable signal
| Anti-pattern | Typical metric signal |
|---|---|
| Mini-waterfall | Lead time spikes near sprint end |
| Done at merge | Low deploy frequency, high batch size |
| Late integration | High change failure rate, long CI times |
| Estimation theater | Stable “velocity,” unstable delivery outcomes |
| Backlog bloat | High context switching, low throughput |
| Too many handoffs | PR waits, long cycle time |
| Retro theater | No sustained metric movement |
A 30-day reset: how to move from agile motions to shipping
You do not need a reorg to improve shipping. You need a focused pilot and a measurable baseline.
| Timeframe | What to change | What to measure |
|---|---|---|
| Week 1 | Define “ships” and update Definition of Done. Pick one team and one product area. | Baseline DORA, PR cycle time |
| Week 2 | Introduce Change Review (2x/week). Reduce WIP (explicit limit). | Deploy frequency, work item age |
| Week 3 | Make slices thinner. Add one release safety mechanism (flag or canary). | Change failure rate |
| Week 4 | Add one operational proof to demos (monitoring, logs, alert, SLI). Run one retro experiment. | MTTR trend, defect escape rate |
The goal is not perfection in 30 days. The goal is a visible shift toward smaller batches, faster feedback, and safer releases.
Where Wolf-Tech can help (without adding process weight)
If your agile rituals exist but shipping is still slow, the constraint is usually technical and systemic: CI/CD friction, unclear architecture seams, legacy risk, missing observability, or an unrealistic Definition of Done.
Wolf-Tech helps teams build shipping capability through full-stack delivery and focused consulting, including code quality, legacy optimization, and delivery system improvements.
If you want a structured way to diagnose what is actually blocking shipping, these resources may help:
- Build Stack: A Simple Blueprint for Modern Product Teams
- Software Project Kickoff: Scope, Risks, and Success Metrics
- Software Building: A Practical Process for Busy Teams
Or, if you’d rather compress the learning curve, you can reach out via Wolf-Tech for a delivery and shipping capability assessment focused on rituals, metrics, and the anti-patterns most likely affecting your teams.
