
Build Stack: A Simple Blueprint for Modern Product Teams


Modern product teams don’t fail because they picked the “wrong framework.” They fail because they don’t have a build stack that turns ideas into safe, measurable production changes, repeatedly.
In this article, “build stack” means the end-to-end blueprint that connects:
- Product intent (what outcome we’re driving)
- Engineering reality (how we build it)
- Operational truth (how it behaves in production)
If you can describe those connections clearly, you can ship faster, with fewer surprises, and you can scale your product and team without reinventing your process every quarter.
What a “build stack” includes (it’s bigger than a tech stack)
Most teams already have a tech stack (frontend, backend, database, cloud). The build stack adds the pieces that determine whether that tech stack is actually usable under real constraints.
A practical build stack covers five capability areas:
- Product and decision inputs (outcomes, users, constraints, non-functional requirements)
- Architecture baseline (boundaries, data ownership, integration style, key trade-offs)
- Delivery system (CI/CD, environments, release strategy, rollback)
- Quality and security baseline (testing approach, code quality gates, supply chain controls)
- Operability (observability, incident response basics, performance budgets, cost visibility)
This is why two teams using the same cloud and framework can have completely different results.
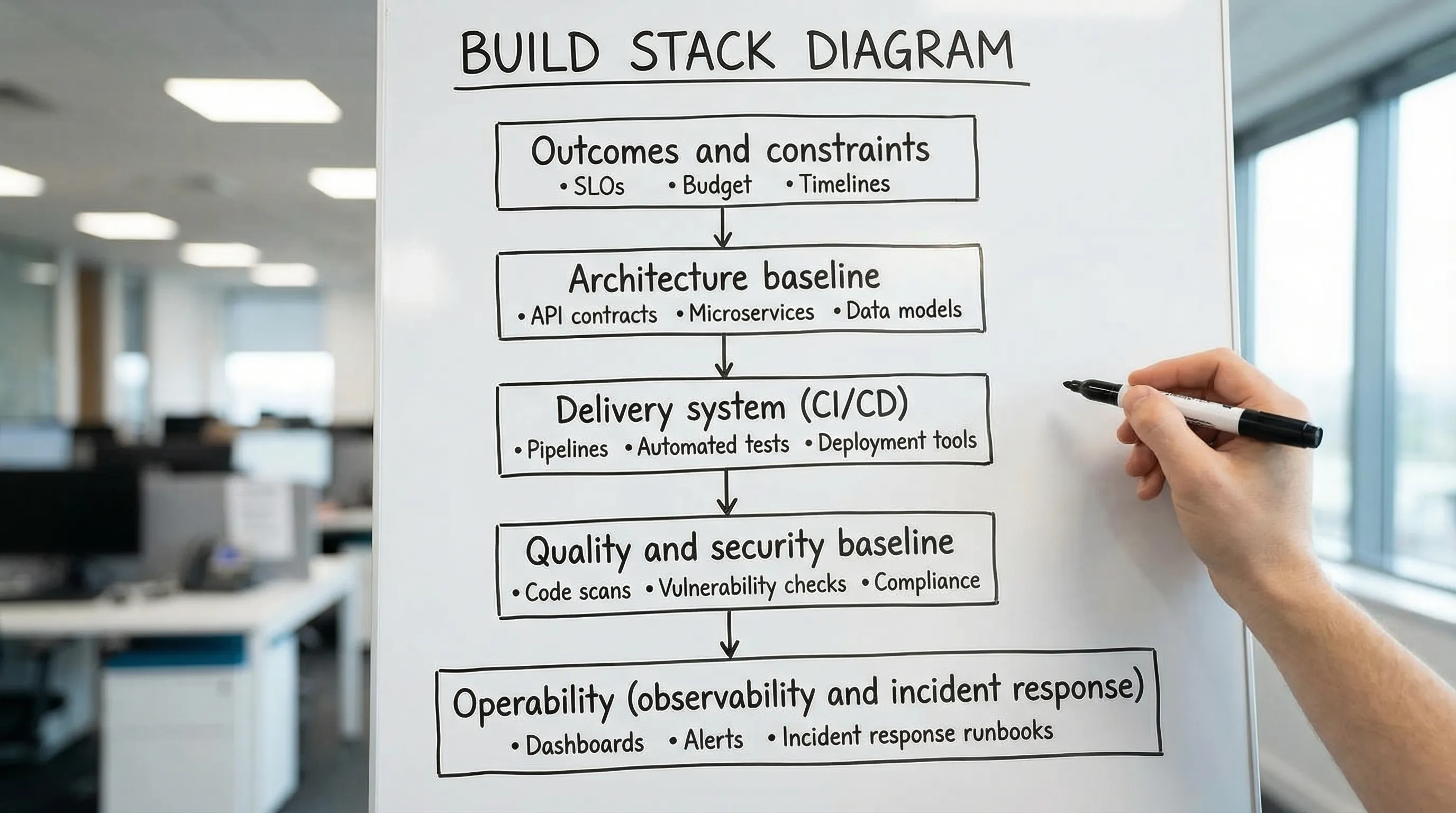
The Build Stack Blueprint (a simple one-page model)
The goal is not to document everything. It’s to make the most important choices explicit, and to define what “good” looks like using observable evidence.
Use the table below as a one-page build stack canvas. Fill it in during a short workshop with product, engineering, and whoever owns operations (even if that’s “the devs”).
| Build stack area | The decision you must make | “Good” evidence (what you can point at) |
|---|---|---|
| Outcomes and constraints | What are we optimizing for in the next 90 days (and what are we not)? What are the top 3 non-functional requirements (NFRs)? | A short outcome brief, 3 measurable NFRs (latency, uptime, compliance, cost), and a clear “won’t do” list |
| Architecture baseline | What are the main boundaries, data ownership rules, and integration style? | A lightweight architecture diagram, key ADRs, and at least one thin vertical slice in prod |
| Delivery system | How do changes flow from commit to production, safely and repeatedly? | Working CI pipeline, automated deploy to a non-prod env, and a reversible production release path |
| Quality and security baseline | What do we automatically prevent, and what do we review? | Tests in CI, code quality checks, dependency scanning, secret handling, and a Definition of Done |
| Operability | How do we know it’s healthy, and how do we recover when it’s not? | Dashboards/alerts for key user flows, structured logs, traces where needed, and a basic on-call or incident routine |
If this feels like “a lot,” note that each row can be implemented at a minimum viable level first. The blueprint is about coverage and clarity, not gold-plating.
Step 1: Start with outcomes and measurable constraints (not features)
If you skip this, everything downstream becomes opinion-based.
A useful format is:
- Outcome: what changes for the business or user
- Leading indicator: what you can measure weekly
- Guardrails: what cannot regress (security, reliability, performance, cost)
Example constraints that matter in 2026 product delivery:
- Performance targets tied to real UX (Core Web Vitals for web apps)
- Reliability targets expressed as SLOs and error budgets
- Security controls aligned to your risk level (for some teams, baseline OWASP practices are enough; for regulated teams, you will need evidence-driven controls)
If you want a deeper method for translating UX needs into architecture constraints, Wolf-Tech’s “handshake” model is a strong complement: UX to architecture handshake.
Step 2: Define an architecture baseline that preserves optionality
Your build stack needs a default architectural shape so teams can ship without re-litigating fundamentals.
For many product teams, the most pragmatic baseline is:
- A modular monolith early (clear internal boundaries, one deployable)
- Explicit API contracts (even inside the monolith)
- Clear data ownership rules per bounded context
This is not anti-microservices. It’s pro-evidence. You can move toward services when you can prove you need independent scaling, deployment autonomy, or isolation.
A simple “baseline package” is:
- A context and container diagram (C4-style is fine)
- 3–7 architecture decision records (ADRs)
- A thin vertical slice that touches UI, API, data, auth, and deployment
If you want a reference for what an expert looks for, align this baseline with: What a tech expert reviews in your architecture.
Step 3: Treat CI/CD as part of the build stack, not a DevOps afterthought
Modern teams win by shortening feedback loops and reducing deployment risk. That’s delivery system work.
Your minimum viable delivery system should support:
- Fast, repeatable builds
- Automated tests and quality gates
- Artifact versioning
- Automated deploy to a test environment
- A production deploy path with rollback (or forward-fix) built in
The reason is simple: if releases are scary, learning stops.
If you need a practical breakdown of the building blocks and a 0–90 day adoption plan, see: CI/CD technology: build, test, deploy faster.
For teams that want a research-backed measurement model, the DORA metrics (deploy frequency, lead time, change failure rate, time to restore) are a useful lens. Google’s DevOps Research and Assessment (DORA) work is summarized here: DORA research.
Step 4: Set a quality baseline that scales with team size
Quality is not “more tests.” It’s the combination of practices that keep changes safe as the codebase and team grow.
A pragmatic baseline usually includes:
- A clear testing strategy (unit, integration, and at least one end-to-end critical path)
- Small pull requests and predictable review latency
- Automated checks for formatting, linting, and static analysis
- A “no broken windows” rule for flaky tests
Choose metrics that drive action, not vanity. A helpful starting point is: Code quality metrics that matter.
Security baseline (keep it proportionate, keep it real)
Security in the build stack is about preventing obvious failures and producing evidence appropriate to your risk level.
A minimal baseline often includes:
- Dependency scanning and patch hygiene
- Secrets management (no secrets in repos, short-lived credentials where possible)
- Secure defaults for auth and session handling
- Threat modeling for your top user flows (even a 60-minute workshop helps)
If you operate in a regulated environment, anchor your process to recognized guidance like the NIST Secure Software Development Framework (SSDF).
Step 5: Make operability a first-class feature
Operability is what turns “we deployed” into “we can run this product confidently.”
Your build stack should define:
- The key user journeys and their health signals
- What gets logged (and what must not, such as sensitive data)
- How you detect and respond to incidents
- Performance budgets that prevent slow creep
A simple starting point:
- 3 dashboards: traffic, errors, latency (per critical flow)
- 3 alerts: availability, error spikes, and a “something is broken” synthetic check
- A lightweight incident template: what happened, impact, detection, mitigation, follow-ups
If reliability engineering is a priority, you can complement this with the defensive patterns in: Backend development best practices for reliability.
A practical “minimum viable build stack” for a new product team
You can get a working build stack without a platform team or months of tooling.
Here’s a realistic baseline that fits most early-stage product efforts:
| Capability | Minimum viable default | What to avoid |
|---|---|---|
| Architecture | Modular monolith, clear modules, documented boundaries | Starting with distributed microservices because “we’ll scale later” |
| Delivery | One CI pipeline, automated tests, one-click deploy, reversible release | Manual deployments and environment snowflakes |
| Quality | Unit + integration tests, 1–2 E2E critical flows, PR size guardrails | Chasing 90% coverage while incidents keep happening |
| Security | Dependency scanning, secret hygiene, basic threat model, least privilege | Bolting on security after you integrate payments or PII |
| Operability | Logs, metrics, basic tracing, dashboards for top journeys, SLO draft | Waiting for the first outage to add observability |
This baseline is intentionally simple. It creates leverage: faster iteration today, and fewer rewrites when you grow.
How to choose tools without getting stuck in analysis paralysis
Tool choices matter, but they should be downstream of capabilities.
A practical selection approach:
- Pick tools that match your team’s skills for the next 12–24 months
- Prefer boring defaults where the ecosystem is strong
- Validate with a thin vertical slice, then commit
If your team is currently debating frameworks or cloud services, you can anchor the conversation with: Apps technologies: choosing the right stack for your use case.
A 30-day rollout plan to implement your build stack blueprint
You can implement the blueprint quickly if you timebox it and focus on evidence.
Week 1: Align and define the canvas
Outputs:
- Outcome brief (90-day horizon)
- Top 3 NFRs with measurable targets
- Build stack canvas filled in with owners per row
Week 2: Prove the architecture baseline with a thin slice
Outputs:
- Working vertical slice (UI to data) running in a non-prod environment
- First ADRs (boundaries, data ownership, integration style)
- A simple system diagram that matches reality
Week 3: Wire CI/CD and quality gates
Outputs:
- CI pipeline with tests and basic quality checks
- Automated deploy to a preview or test environment
- Clear Definition of Done (including security and operability checks)
Week 4: Add production readiness and operability
Outputs:
- Instrumentation for key user journeys (dashboards, alerts)
- Release strategy documented (rollback, canary, feature flags as appropriate)
- First SLO draft and an incident routine (even if informal)
For teams that want a broader process wrapper around this, Wolf-Tech also publishes a lightweight delivery process that pairs well with the build stack concept: Software building: a practical process for busy teams.

Common build stack failure modes (and the fix)
Failure mode: “We picked a modern stack, why is delivery still slow?”
Usually the delivery system is missing. Slow reviews, flaky tests, manual releases, and unclear environments kill throughput.
Fix: treat CI/CD and quality gates as product infrastructure, measure lead time and failure rate, and remove the biggest bottleneck first.
Failure mode: “Architecture debates never end.”
That often means there’s no shared set of constraints or no proof via a thin slice.
Fix: write down NFRs, pick a baseline, and validate with a vertical slice that includes deployment and observability.
Failure mode: “Production incidents keep surprising us.”
This is an operability gap, not just a code quality gap.
Fix: define health signals for top user journeys, instrument them, and establish a basic incident workflow.
When it makes sense to bring in outside help
A build stack is simplest when you’re starting fresh. It’s harder when you have:
- A legacy system with unclear boundaries and fragile releases
- Multiple teams shipping into the same runtime without shared standards
- Regulatory requirements that demand audit-ready evidence
Wolf-Tech helps teams design and implement pragmatic build stacks across full-stack development, delivery systems, modernization, and code quality consulting. If you want a second set of eyes on your blueprint (or you want help executing it), start here: Wolf-Tech.