
Software Building: A Practical Process for Busy Teams


Building software while running a business can feel like trying to renovate a house while living in it. You need visible progress every week, but you also need stability, security, and a codebase that will not collapse under its own weight.
This guide lays out a practical software building process for busy teams: a lightweight set of stages, artifacts, and quality gates that help you ship faster without betting the company on a rewrite or a heroic launch.
What “software building” should mean in 2026
For most teams, software building is not “finish a project.” It is continuously turning business outcomes into reliable, measurable product changes.
A good process does three things at once:
- Reduces decision latency (teams do not get stuck waiting for approvals).
- Reduces rework (teams validate assumptions early, with a thin slice).
- Reduces operational risk (changes are observable, reversible, and secure).
If you want a research-backed way to track whether your delivery system is improving, the industry standard is the DORA metrics (deployment frequency, lead time for changes, change failure rate, time to restore). Google’s DORA team publishes ongoing guidance and benchmarks in the State of DevOps research.
The busy-team software building process (7 stages)
The goal is not to add bureaucracy. The goal is to create just enough shared structure so that delivery stays predictable when priorities change, people rotate, or the system grows.
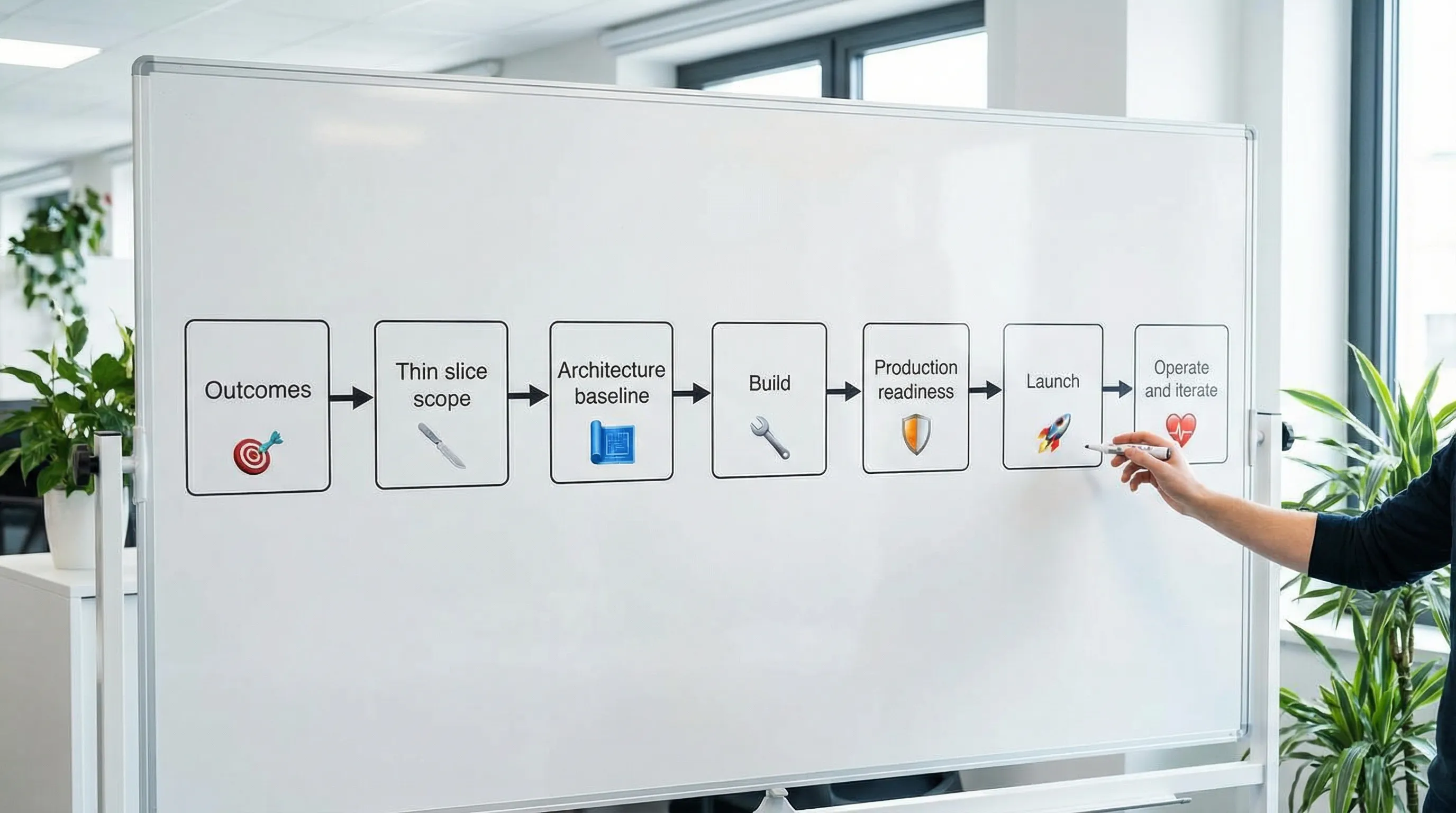
1) Align on outcomes (not feature lists)
Start with a one-page outcome brief that answers:
- What user or business problem are we solving?
- What changes when we succeed (conversion, cycle time, cost, risk, retention)?
- What constraints are non-negotiable (compliance, data residency, uptime expectations)?
This is where many teams accidentally create waste: they skip outcome clarity, then argue for weeks about scope. If you want a practical approach to turning requirements into UI flows and engineering-ready artifacts, Wolf-Tech’s guide on software designing is a strong companion.
2) Define a thin slice that proves value and risk
A thin slice is the smallest end-to-end capability that:
- Delivers a user-visible result, and
- Touches the risky parts (auth, data, integrations, performance constraints)
Thin slices prevent the classic trap: building “easy” UI first, then discovering later that permissions, data quality, or integrations break the whole plan.
3) Set an architecture baseline (lightweight, explicit)
Busy teams do not need a 40-page architecture document. They need a few decisions captured early:
- System shape (often a modular monolith is a safer default than premature microservices)
- Integration style (REST, events, GraphQL where justified)
- Data ownership boundaries and a first-pass domain model
- Deployment target (cloud account structure, environments)
Capture decisions as short ADRs (architecture decision records). The point is not perfection, it is to stop re-litigating the same choices.
4) Build the vertical slice with real quality gates
Build the thin slice end-to-end with production-grade discipline, even if the feature scope is small. That means:
- Automated builds and tests on every change
- Code review rules that keep PRs small
- Basic logging/metrics/tracing so you can debug what you ship
Teams often delay these until “after MVP.” In practice, skipping them creates an MVP you are afraid to release.
If your CI/CD is currently manual or fragile, use this practical baseline: CI/CD technology.
5) Add production readiness incrementally (security, reliability, performance)
Production readiness is not a final phase. It is a checklist you apply continuously as the system grows.
A pragmatic baseline for most web systems:
- Security: secrets management, least privilege, dependency scanning
- Reliability: timeouts, retries, idempotency for critical operations
- Observability: meaningful logs and alerting tied to user impact
- Performance: budgets for user experience and API latency
For secure development guidance, the NIST Secure Software Development Framework (SSDF) is a good reference point, and for web app risk patterns, OWASP Top 10 remains a practical baseline.
6) Launch with reversible releases
Busy teams should avoid “big bang” launches. Use release tactics that reduce blast radius:
- Feature flags for gradual rollout
- Canary releases when feasible
- Blue/green deployments for safer cutovers
The goal is simple: you should be able to undo a risky change quickly without a war room.
7) Operate and iterate (measure what happened)
Once you ship, close the loop:
- Did the outcome metric move?
- Did reliability change (errors, latency, incidents)?
- Did delivery improve (lead time, frequency, failure rate)?
This is where software building becomes a capability, not a project.
One table to keep the process concrete
Use this as a lightweight reference for what “done” looks like at each stage.
| Stage | Goal | Typical artifacts | Exit evidence |
|---|---|---|---|
| Outcomes | Align on value and constraints | Outcome brief, success metrics | Stakeholders agree on success and trade-offs |
| Thin slice | Prove value and reduce unknowns | Thin-slice scope, assumptions list | Slice includes risky integrations/data/permissions |
| Architecture baseline | Prevent churn on key decisions | 3 to 8 ADRs, first domain model | Team can explain system boundaries and data flow |
| Build | Deliver working end-to-end capability | PRs, tests, CI pipeline, environments | Slice runs in a production-like environment |
| Production readiness | Reduce operational and security risk | Runbook draft, alerts, perf budgets | Measurable SLO targets and monitoring in place |
| Launch | Release safely | Release plan, rollback steps | Reversible rollout (flag/canary/blue-green) |
| Operate and iterate | Improve outcomes continuously | Metrics dashboard, incident notes | Post-launch learning feeds next cycle |
The operating rhythm that keeps busy teams moving
A process only works if it fits into the reality of interruptions, meetings, and shifting priorities. A simple rhythm that scales:
Weekly: outcome review and re-plan
Hold a short weekly session that answers:
- What did we ship?
- What did it change (metrics, support tickets, performance)?
- What is the next highest-value slice?
Avoid “status theater.” The output should be decisions: trade-offs, de-scoping, sequencing.
Daily: protect focus and keep work small
You do not need long standups. You need fast alignment:
- Keep work in progress low (too many parallel tasks creates invisible delays).
- Keep PRs small (large PRs slow reviews and increase defects).
- Prefer asynchronous updates when the team is distributed.
Every change: a real Definition of Done
A Definition of Done is valuable only if it prevents predictable failure. A practical DoD for most teams includes:
- Tests run automatically in CI
- Linting/formatting and basic static checks
- Security checks appropriate for your risk (at minimum, dependency and secret scanning)
- Observability hooks for the new behavior (log events or metrics)
If you want a metrics-driven way to evolve this without turning it into a bureaucracy, see code quality metrics that matter.
Common failure modes (and how to avoid them)
Shipping features without non-functional requirements
Teams often treat security, reliability, and performance as “later.” Later becomes never, until an incident forces a rewrite.
Fix: define a few measurable non-functional targets early (for example, error rate, latency, recovery time) and track them from the first slice.
Discovery that never ends
Endless workshops feel safe, but they delay real validation.
Fix: timebox discovery and commit to a thin slice that forces real integration, real data, and real constraints.
Manual deployments and fragile environments
If every release requires a specialist, you have a delivery bottleneck.
Fix: standardize a minimal CI/CD pipeline and make deployments routine. Reliability improves when releases are frequent and boring.
Big rewrites to “clean things up”
Rewrites consume years and often deliver less than incremental modernization.
Fix: modernize incrementally with safe seams, tests, and observability. (If this is your situation, Wolf-Tech’s legacy modernization guidance is a solid next read.)
A practical 30-day plan for busy teams
If you need momentum quickly, this 30-day structure is usually enough to create a visible step-change.
Week 1: Align and create delivery safety
Agree on outcomes and pick a thin slice. Set up or harden the basics: repository standards, CI running tests, and a deployable environment.
Week 2: Build the thin slice end-to-end
Implement the slice with real auth, real data, and the first integration points. Keep scope tight and insist on a releasable path.
Week 3: Add production readiness where it matters
Add the minimum observability, alerting, and runbooks needed to operate what you built. Address the top security and reliability risks that surfaced.
Week 4: Launch safely and learn
Release with a reversible approach (feature flags are often the simplest). Measure the outcome and delivery metrics, then adjust the backlog based on what actually happened.
If you want a more detailed, web-app-specific checklist for this phase, use Build a Web Application: Step-by-Step Checklist.
Frequently Asked Questions
What is software building, exactly? Software building is the ongoing capability to turn business outcomes into shipped, secure, observable software, not just writing code or finishing a one-time project.
How do I choose the right thin slice? Pick the smallest end-to-end capability that touches the biggest risks (auth, data, integrations, performance constraints) and delivers a user-visible result.
Do busy teams really need architecture work up front? Yes, but only a lightweight baseline. A handful of explicit decisions (captured as short ADRs) prevents churn and conflicting assumptions.
What should we automate first in CI/CD? Start with repeatable builds, tests on every change, and automated deployment to at least one environment. Then add security and quality checks incrementally.
How do we know if our process is improving? Track a small set of delivery and reliability indicators, commonly the DORA metrics plus incident rate and customer-impacting errors.
When should we bring in outside help? When you are stuck in delivery bottlenecks (manual releases, slow lead time), facing a risky modernization, or need an experienced partner to accelerate a thin-slice build with production readiness.
Build faster without lowering the bar
If your team needs to ship while juggling legacy constraints, growth pressure, or a complex stack, Wolf-Tech can help with full-stack development, code quality consulting, legacy optimization, cloud and DevOps enablement, and tech stack strategy.
Explore Wolf-Tech at wolf-tech.io or reach out via the site to discuss your roadmap, bottlenecks, and the fastest safe path to measurable outcomes.