
Back End vs Front End: Boundaries, APIs, and Ownership


Most teams don’t ship slower because they “picked the wrong stack.” They ship slower because the boundary between front end and back end is fuzzy, APIs aren’t treated like contracts, and ownership is spread across “everyone,” which usually means “no one.” The result is predictable: UI rework, brittle integrations, surprise latency, and production incidents that bounce between teams.
This article frames Back End vs Front End in a way that actually helps you deliver: by making boundaries explicit, designing APIs as enforceable contracts, and assigning clear ownership that matches how work really flows.
Back end vs front end in 2026: define it by responsibility, not by framework
Traditional definitions are simple:
- Front end: the code that runs closest to the user, rendering UI, managing interaction, and translating user intent into requests.
- Back end: the code that enforces business rules, coordinates data and integrations, and provides stable capabilities to many clients.
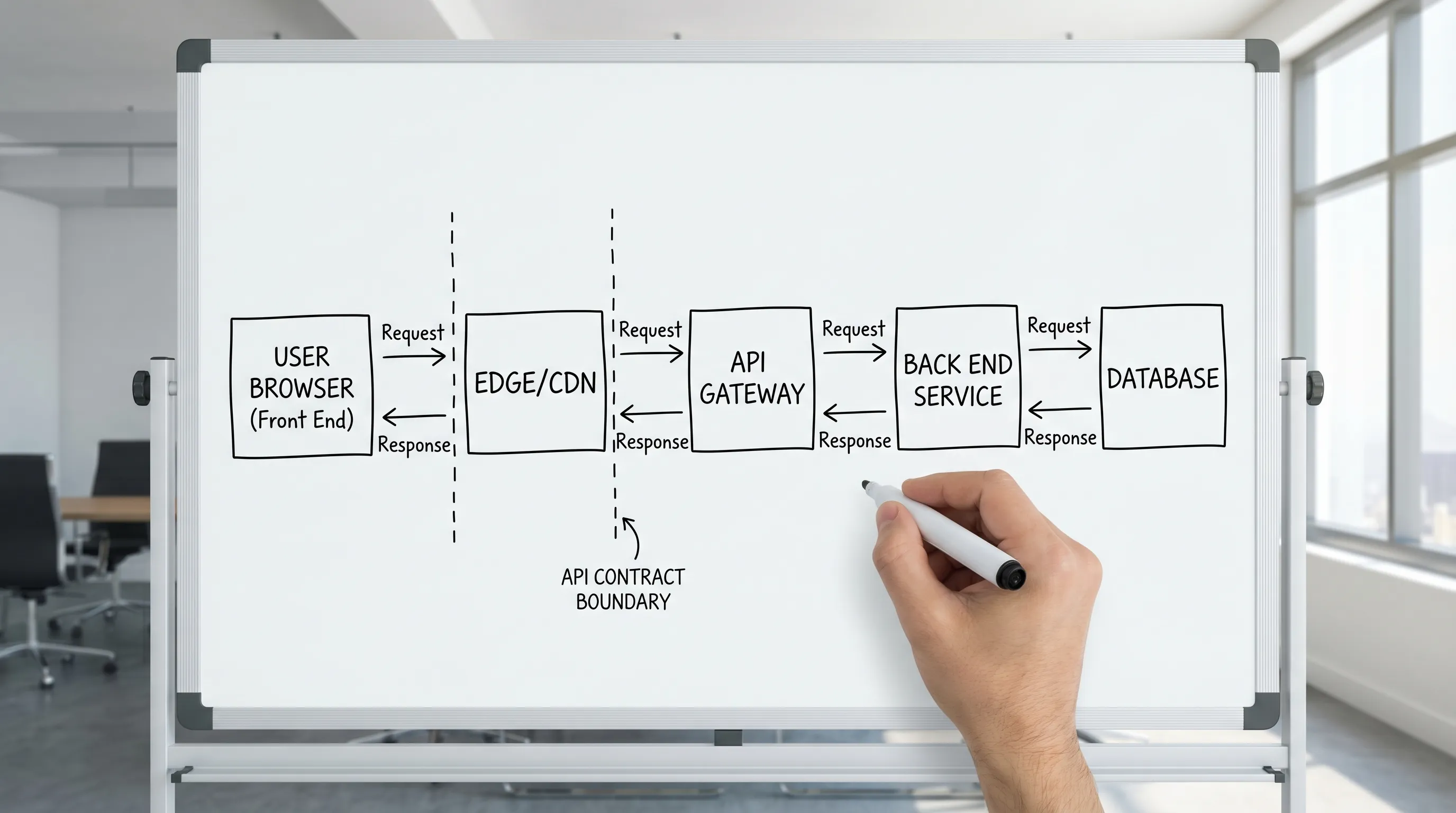
Modern stacks blur runtime placement (SSR, edge rendering, “full-stack” frameworks, server components), but the boundary still exists. It just moves.
A practical definition that holds up across React SPAs, Next.js, mobile apps, and B2B portals is:
- Front end owns the user journey (states, transitions, UX rules, accessibility, perceived performance).
- Back end owns the business truth (authorization decisions, invariants, data correctness, side effects, integration safety).
- The API is the handshake between them, and it must be specific enough to test.
If you want a broader boundary mental model (beyond UI and API), Wolf-Tech’s perspective in Software Systems 101: Boundaries, Contracts, and Ownership maps well to this topic.
Where boundaries fail in real projects (and how it shows up)
When teams say “front end vs back end,” the real problem is usually one of these:
1) The UI encodes business rules that should be server-side
Symptoms:
- Different clients behave differently (web vs mobile vs admin portal).
- Fixing a pricing or permissions bug requires redeploying UI clients.
- Security bugs hide behind “the UI doesn’t let you do that.”
Rule of thumb: if it affects money, permissions, legal compliance, or data integrity, the back end must be the source of truth.
2) The back end leaks domain complexity into the UI
Symptoms:
- The UI needs to call 5 endpoints in sequence (waterfalls, fragile screens).
- The UI assembles business objects out of low-level tables.
- Every UI change forces back end refactors because the model is not stable.
Fix: provide capability-oriented APIs that match user tasks, not database structure.
3) “API” means endpoints, but not a contract
Symptoms:
- Breaking changes slip in as “small refactors.”
- Error handling is inconsistent (sometimes 404, sometimes 200 with
{ ok:false }). - Pagination, sorting, idempotency, and rate limits are undocumented, so clients guess.
Fix: treat the API as a product with a schema, compatibility rules, and tests.
4) Ownership is unclear, so incidents become ping-pong
Symptoms:
- Front end blames “backend latency,” back end blames “too many requests.”
- Nobody owns the end-to-end SLO (for example, p95 page load or p95 checkout).
- Changes ship, but regressions are discovered by customers.
Fix: define ownership for journeys and contracts, not just repos.
Boundaries that matter: runtime, data, and decision boundaries
A helpful way to draw the line is to separate three boundary types.
Runtime boundary: where code executes
You still need to decide what must run:
- In the browser (interaction, instant feedback, offline-friendly state)
- On the server (sensitive logic, aggregation, long-running tasks)
- On the edge (latency-sensitive personalization, caching gateways)
This is an implementation detail, but it impacts security and performance.
Data boundary: who can write what
A clean data boundary is often the difference between “we can evolve safely” and “everything is coupled.” Common safe defaults:
- Back end owns writes to system-of-record data.
- Front end may own ephemeral UI state and local caches.
- Any “write” from the front end is a request for the back end to perform a validated state transition.
Decision boundary: who decides what is allowed
Authorization is the classic decision boundary:
- The front end may hide or disable actions for UX.
- The back end must enforce access control regardless of UI behavior.
For security baselines and common failure modes, it’s worth aligning with resources like the OWASP Top 10, especially when you see business rules implemented only in client code.
APIs: the contract that defines the boundary
An API is not “how the UI calls the server.” It is a contract that allows independent change.
A strong contract typically includes:
- Schema: request/response shape (OpenAPI for REST, schema for GraphQL, AsyncAPI for events).
- Semantics: what fields mean, what is optional, default behavior.
- Error model: consistent error codes, validation format, retry guidance.
- Compatibility rules: what counts as breaking, how versioning works.
- Non-functional expectations: latency budgets, rate limits, pagination limits.
- Security expectations: auth method, scopes/roles, tenant isolation rules.
If you use GraphQL, the schema is a natural contract surface, but you still need operational rules (query cost, caching strategy, authorization model). Wolf-Tech’s deep dive in GraphQL APIs: Benefits, Pitfalls, and Use Cases is a good companion.
The most common API contract gap: “happy path only”
Teams often align on the success response and ignore everything else. The UI then invents behavior for:
- Partial failures
- Stale data
- Permission changes mid-session
- Rate limits and timeouts
- Background processing (accepted vs completed)
This is where rework happens.
A practical fix is to make “state realism” part of the contract, similar to the “UX to architecture handshake” approach described in Web Application Designing: UX to Architecture Handshake.
Ownership: the missing half of “boundaries and APIs”
You can have well-drawn boundaries and still fail if nobody owns the contract end-to-end.
Ownership should answer:
- Who approves changes to this API contract?
- Who gets paged if the SLO is breached?
- Who maintains client SDKs or generated types?
- Who updates docs and migration notes?
This is less about org charts and more about reducing coordination cost.
A simple ownership model that scales
Many teams do well with three explicit owners:
- Journey owner (front end lead): owns the user experience, states, and perceived performance.
- Capability owner (back end lead): owns business rules, correctness, and integration safety.
- Contract owner (named, sometimes shared): owns the API surface and compatibility, including tests.
The contract owner is often missing. When it’s missing, “small changes” become outages.
If reliability is a priority, the habits described in Back End Software Developer: Skills That Prevent Outages map directly onto API ownership (failure modeling, contract thinking, observability, and change safety).
What belongs where: a practical responsibility split
The point is not to create rigid silos. The point is to make decisions predictable.
| Concern | Front end typically owns | Back end typically owns | Shared contract surface |
|---|---|---|---|
| UX flows and states | Screens, transitions, optimistic UI, loading/empty/error UX | State machine constraints, async job states | State model and status semantics |
| Validation | Inline UX validation, field hints | Authoritative validation, constraints, deduplication | Validation error format |
| Authorization | Visible permissions (what to show) | Enforced permissions (what is allowed) | Auth scopes, error codes |
| Performance | Bundle size, rendering, caching on client | Query efficiency, caching, concurrency limits | Latency budgets and payload sizes |
| Data shaping | View models for rendering | Domain models, aggregation, integration logic | Response shape stability |
| Observability | Front end logs, RUM signals, user-impact traces | Logs/metrics/traces, incident runbooks | Correlation IDs, trace context |
Two notes that prevent common mistakes:
-
Duplicated logic is not automatically bad. Some duplication is intentional (for example, UI validation for usability, server validation for correctness). The key is making the server authoritative.
-
“Back end returns raw DB entities” is usually a smell. It couples your UI to internal structure and makes refactors expensive.
Boundary patterns that reduce coordination cost
Pattern 1: BFF (Backend for Frontend)
A BFF gives the UI a contract that matches its needs, while protecting core domain services from churn. It is especially useful when:
- You have multiple clients (web, mobile, partners).
- Your domain APIs are stable, but UI needs change frequently.
- You need aggregation to avoid chatty UIs.
BFF is not a silver bullet. It needs the same contract discipline, plus good observability.
Pattern 2: Contract-first development (with automated checks)
Contract-first does not mean “write a huge spec up front.” It means:
- Make the contract explicit early (OpenAPI, GraphQL schema, or typed endpoints).
- Generate clients where appropriate.
- Add contract tests and compatibility checks to CI.
This is one of the highest leverage ways to prevent “it worked locally” integration failures.
Pattern 3: Compatibility rules (so you can ship independently)
At minimum, teams should agree on what is breaking:
- Removing fields is breaking.
- Changing meaning is breaking.
- Tightening validation is usually breaking.
Then decide how you handle breaking changes: versioning, additive-only evolution, or explicit deprecation windows.
The minimum set of artifacts to make boundaries real
Boundaries are intentions until you put them into artifacts that can be reviewed and tested.
| Artifact | What it prevents | Primary owner |
|---|---|---|
| API schema (OpenAPI/GraphQL) | Guesswork and undocumented changes | Contract owner |
| Error model spec (examples included) | UI-specific error hacks | Contract owner |
| Contract tests in CI | Breaking changes slipping into releases | Contract owner + both teams |
| Journey state model | “Unhandled state” bugs and UX rework | Journey owner |
| SLOs/SLIs for key flows | Performance debates without data | Shared (journey + capability) |
| Runbook for top incidents | Slow recovery and unclear escalation | Capability owner |
This “proof over promises” approach is consistent with Wolf-Tech’s delivery philosophy across service pages and checklists, for example Front End Development Services: Deliverables That Matter.
A quick kickoff checklist for front end and back end alignment
If you want to prevent expensive boundary churn, use this lightweight checklist at kickoff (or when a feature starts to sprawl).
- Define the top 1 to 3 user journeys and success metrics (not just “screens”).
- Decide which writes the front end can trigger, and what the authoritative state transitions are.
- Specify the API contract including error cases and long-running workflow states.
- Agree on performance budgets (payload size, p95 latency) for the journeys.
- Name owners for the journey, the capability, and the contract.
- Decide how breaking changes work, including deprecation rules.
For organizations that want measurable delivery improvement, you can also align these decisions with delivery metrics (lead time, change failure rate, MTTR) popularized by DORA. Google’s DORA research is a useful starting point for tying engineering practices to outcomes.
When to bring in outside help
Boundary problems are often “invisible” to teams because everyone has adapted to the friction. External review is most valuable when:
- Front end and back end teams are blocked on each other every sprint.
- You are modernizing a legacy system and need safe seams (APIs, contracts, strangler slices).
- Incidents repeat, but root cause keeps shifting between UI, API, and data.
- You are adopting a new full-stack framework and need clarity on ownership.
Wolf-Tech supports teams with architecture and contract reviews, legacy code optimization, and full-stack development execution. If you want a second set of eyes on your boundaries and API contracts, start at wolf-tech.io and use the blog resources to align on the artifacts and proofs before you scale the build.