
Scaling Across Diverse Industries: Reusable Architecture Wins


Scaling a product is hard. Scaling a product line across diverse industries is harder, because every new domain introduces “special cases” that pressure your codebase, your delivery system, and your team’s cognitive load.
The good news is that most successful cross-industry platforms do not win by copying projects. They win by building a reusable architecture: a stable core of capabilities that stays boring and dependable, plus well-defined extension points where industry-specific rules can evolve without forking the whole system.
This article explains what “reusable architecture” actually means in practice, the patterns that make it work, and a pragmatic playbook to implement it without turning your team into an internal framework company.
What “reusable architecture” means (and what it does not)
Reusable architecture is not “a shared repo with a few utilities.” It is also not “one mega-platform that every product must use.”
A reusable architecture is a repeatable blueprint for building and operating software that shares:
- Stable building blocks (identity, permissions, audit logging, notifications, workflows, data access patterns)
- Standard interfaces (API contracts, events, integration boundaries)
- Production guardrails (CI/CD, security baselines, observability conventions)
- A clear customization model (configuration, plugins, domain modules, or separate bounded contexts)
The goal is simple: ship new industry variants faster with fewer regressions, while keeping optionality for future change.
Why reusable architecture wins across industries
When you serve multiple industries, your constraints multiply:
- Different compliance regimes and audit expectations
- Different workflow shapes (human-in-the-loop approvals vs straight-through processing)
- Different data lifecycles (retention, deletion, lineage)
- Different integration landscapes (ERPs, CRMs, payment providers, LMS, listing feeds)
A reusable architecture helps because it reduces the parts that must change and hardens the parts that must not.
The compounding effect: reuse improves both speed and safety
Reuse is not only about developer velocity. It also creates operational consistency, which is often the real scaling bottleneck.
If every industry solution has its own auth pattern, logging format, deployment process, and incident workflow, you do not have 5 products, you have 5 different operating models.
A shared architecture turns hard-won lessons into defaults.
The hidden cost you avoid: “parallel reinvention”
Cross-industry teams commonly repeat the same expensive work:
- Re-implementing RBAC and tenant boundaries
- Re-learning how to do safe schema migrations
- Rebuilding audit trails and export pipelines
- Recreating observability from scratch
Those are not differentiators. They are table stakes. A reusable architecture makes them boring.
The main trap: over-generalization (and how to avoid it)
The failure mode is familiar: a team tries to design a “universal platform,” then ships nothing for months. Or worse, ships a rigid framework that teams work around, producing forks.
A practical rule:
Standardize what must be consistent, and modularize what must vary.
This means you invest in reusable architecture when you can name:
- The stable “core” capabilities you will use repeatedly
- The extension points where differences are expected
- The governance that prevents uncontrolled divergence
If you cannot name those, you are not ready for reuse. You are still doing discovery.
A simple model: Core vs Edge (stable vs variable)
Think of every cross-industry product as:
- Core: capabilities that are the same everywhere (or should be)
- Edge: industry-specific rules, workflows, integrations, and compliance overlays
A strong architecture makes the core easy to reuse and the edge easy to replace.
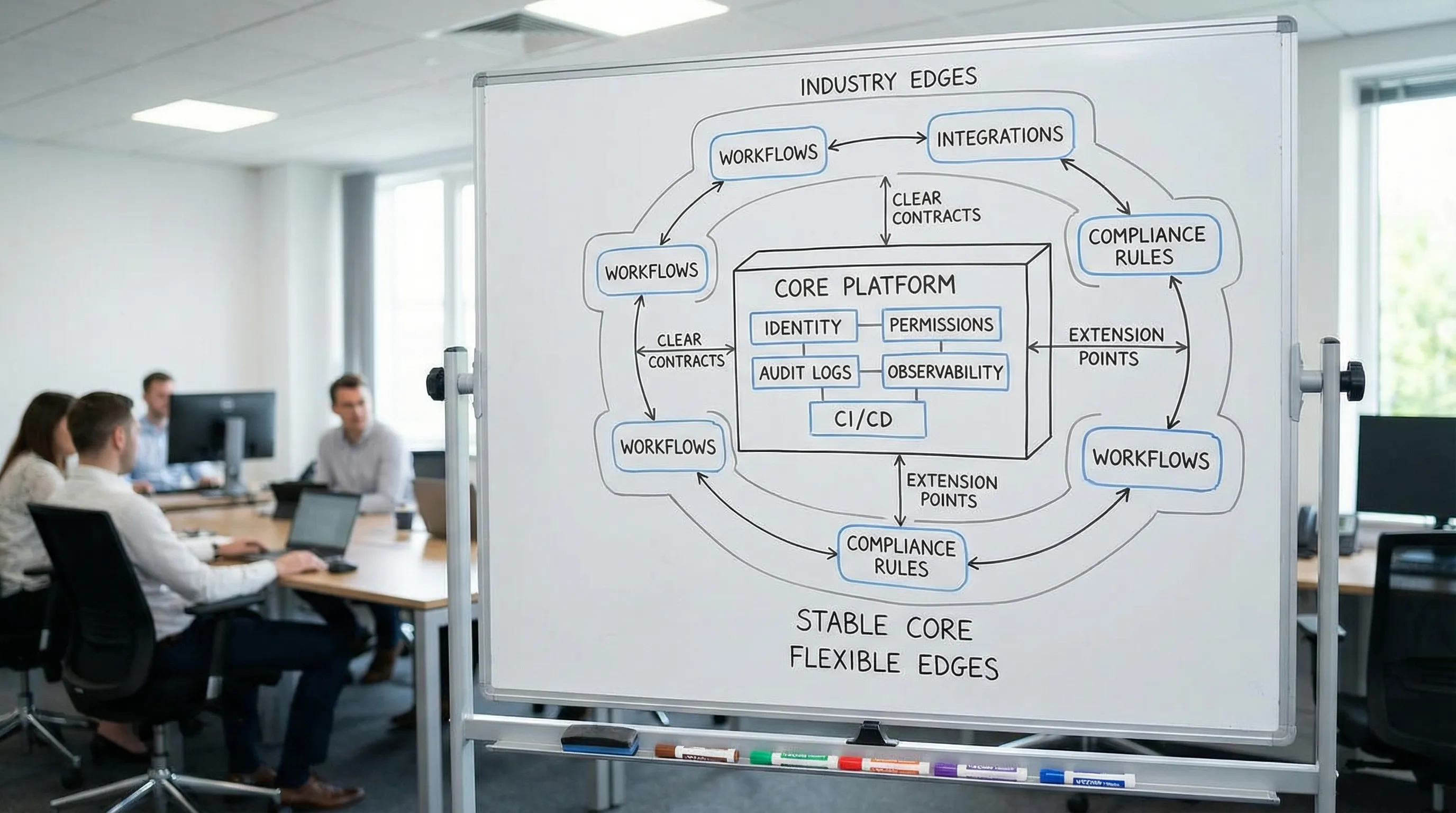
Where teams usually draw the line incorrectly
- They put business rules into the “shared core,” making every change political.
- They allow each product to implement “core” concerns independently, creating operational chaos.
A better split is:
- Core owns cross-cutting concerns and technical guardrails.
- Domain modules (or bounded contexts) own business rules.
This aligns well with pragmatic Domain-Driven Design and architecture guardrails you can enforce.
The reusable architecture stack (what to standardize first)
If you want reuse that pays off, you need consistency across more than code. Here is a practical stack you can standardize across products.
| Layer | What you standardize | What varies by industry |
|---|---|---|
| Product capabilities | Identity, tenant model, roles/permissions, audit logging, notification patterns, file handling | Domain workflows, entity rules, approval chains |
| API & integration | API conventions, versioning, event schemas, idempotency, rate limits | Specific providers, data mappings, partner constraints |
| Data & governance | Migration approach, encryption defaults, data access patterns, retention hooks | Data classifications, audit fields, reporting requirements |
| Platform & delivery | CI/CD patterns, environment strategy, observability, incident readiness | Traffic shape, latency targets, deployment constraints |
If you already have a “build stack” concept internally, this is the cross-industry version of it. (Wolf-Tech has a deeper blueprint on this idea in Build Stack: A Simple Blueprint for Modern Product Teams.)
Patterns that make reuse real (without forcing a rewrite)
Below are patterns that consistently work across domains, from B2B SaaS to regulated environments.
1) Prefer a modular monolith for the reusable core
For many teams, a modular monolith is the best unit of reuse early on:
- One deployment, consistent observability, fewer distributed failure modes
- Clear internal module boundaries (packages) and explicit dependencies
- Easier refactoring and governance
You can still evolve to services later where it is justified by scaling constraints, not by fashion. If you want a broader view on true scale mechanics, see Developing Software Solutions That Actually Scale.
2) Design extension points, not exceptions
Cross-industry variation should not be implemented as scattered if (industry == X) conditions.
Better options include:
- A policy layer (rule evaluation) that can change without rewriting the domain
- A workflow orchestration layer for approvals, handoffs, async processing
- An adapter layer for external integrations (anti-corruption boundaries)
- A plugin model where industry modules register handlers, validators, or mappers
The key is that the core calls an interface, and industry modules implement it.
3) Use configuration for behavior, but keep configuration bounded
Configuration is powerful until it becomes a programming language.
Practical guardrails:
- Allow configuration for thresholds, feature exposure, mappings, and templates
- Avoid configuration for core invariants like authorization models
- Require schema validation and versioning for configs
If config changes can break production, treat configs as deployable artifacts with review, testing, and rollback.
4) Make multi-tenancy a first-class architectural decision
Even if you are not multi-tenant today, cross-industry offerings often become multi-tenant tomorrow.
Key questions to resolve early:
- Tenant isolation level (shared DB, shared schema, separate schemas, separate DBs)
- Tenant-aware caching and background jobs
- Tenant-aware observability (logs and traces that include tenant context)
This is not about one “right answer,” it is about choosing deliberately and making it consistent across products.
5) Standardize “non-negotiables”: security, delivery, and operability
Cross-industry work increases your blast radius. Your reusable core should include the boring but critical baselines:
- A secure delivery pipeline with supply chain controls (see NIST SSDF for a widely used baseline)
- Threat modeling and secure-by-default patterns (OWASP guidance is a good starting point, for example the OWASP Application Security Verification Standard)
- Observability conventions (structured logging, metrics naming, tracing propagation)
On the Wolf-Tech blog, several articles go deeper on related guardrails, including CI/CD Technology: Build, Test, Deploy Faster and Backend Development Best Practices for Reliability.
A capability map you can reuse across most industries
Across “industry-specific” products, many capabilities repeat. Treat them as reusable modules, not bespoke implementations.
| Cross-industry capability | Why it is reusable | What must be extensible |
|---|---|---|
| Identity and access (RBAC) | Same primitives everywhere | Role models, permission sets, tenant segmentation |
| Audit logging | Compliance and support depend on it | Event taxonomy, retention rules, export formats |
| Notifications | Common user expectation | Channels, templates, escalation rules |
| File and document handling | Upload, scan, export are universal | Classification, watermarking, retention |
| Reporting exports | Stakeholders want data out | Field-level access, compliance filters, scheduling |
| Integration framework | Everything integrates | Provider-specific adapters and mappings |
This table is intentionally capability-focused. It helps you avoid the common mistake of standardizing around a specific tool rather than a stable requirement.
The playbook: implementing reusable architecture in 6 pragmatic moves
Start with evidence: where are you already repeating yourself?
Before you “platform,” gather proof:
- Which modules have been re-implemented 2 or more times?
- Which incidents keep recurring across products?
- Which integrations create the most rework?
Look for hotspots in code, and hotspots in operations.
If you want a structured lens for reviewing architecture evidence, Wolf-Tech outlines a practical scorecard in What a Tech Expert Reviews in Your Architecture.
Define a reference architecture, then enforce it lightly
A reference architecture is not a 60-page document. It is a small set of decisions that reduce ambiguity:
- Module boundaries and dependency rules
- API conventions and versioning rules
- Data access patterns and migration approach
- Observability and error-handling conventions
Capture these decisions as Architecture Decision Records (ADRs) so they evolve with context.
Build the “golden path” in the delivery system
Reusable architecture fails when the default path is painful.
Make the paved road the easiest road:
- One standard CI pipeline template
- One approach to preview environments
- One release strategy (feature flags, canary, blue/green as appropriate)
This is where architecture meets delivery reality. It is also how you reduce cross-team friction.
Create extension points first, then migrate code toward them
Do not rewrite everything.
- Identify one high-churn variability zone (pricing rules, approval workflows, document requirements)
- Define an interface and contract tests
- Move one industry implementation behind the interface
- Add a second industry implementation to prove the extension point is real
When the extension point works twice, it is not a one-off.
Treat reuse as a product (with versioning and ownership)
Reusable components need owners, release notes, compatibility rules, and deprecation policies.
Without this, “shared” becomes “stuck,” and teams fork to escape.
Measure outcomes, not reuse vanity metrics
“Lines of code reused” is not the goal.
Track what the business feels:
| Outcome | Practical metric you can track |
|---|---|
| Faster shipping | Lead time for changes (DORA-style) |
| Safer releases | Change failure rate, rollback rate |
| Faster recovery | MTTR, incident recurrence |
| Less rework | Defect escape rate, duplicate implementation count |
For teams scaling delivery maturity, the DORA framework is widely used and well-documented (see the DORA research program).

When reusable architecture is worth it (and when it is not)
Reusable architecture is a leverage play. It has an upfront cost, and it pays back when you truly have repetition.
It is usually worth it when:
- You expect 2 or more industry variants, or multiple clients with similar needs
- You have stable cross-cutting requirements (security, audit, multi-tenant)
- You have a roadmap that will repeatedly touch the same platform areas
It is usually not worth it when:
- You are still validating product-market fit and requirements are volatile
- Each “industry” project is actually a bespoke one-off with no real reuse
- You lack the delivery hygiene (tests, CI/CD, observability) to safely share components
In those cases, start by improving change safety and delivery consistency first. Standardization is a force multiplier, but only if you can ship reliably.
How Wolf-Tech approaches cross-industry scaling
Wolf-Tech specializes in full-stack development and consulting that helps teams build, optimize, and scale technology across multiple contexts. In practice, that often means:
- Defining an architecture baseline that supports reuse without locking teams into a rigid framework
- Hardening delivery and operational guardrails so shared components stay safe
- Modernizing legacy areas that prevent modularization and clean extension points
If your starting point includes legacy constraints, it is often possible to introduce reuse incrementally through refactoring, seams, and strangler-style patterns. (Related reading: Taming Legacy Code: Strategies That Actually Work.)
Frequently Asked Questions
What is reusable architecture in software development? Reusable architecture is a repeatable blueprint that standardizes core capabilities (security, identity, observability, delivery) while allowing industry-specific variation through clear extension points.
Is reusable architecture the same as building an internal platform? Not necessarily. A platform can be part of it, but reuse also includes module boundaries, contracts, shared operational patterns, and governance. Many teams succeed with a modular monolith plus shared delivery standards.
How do you prevent “shared core” code from becoming a bottleneck? Keep business rules in domain modules, not in the core. Version shared components, define ownership, and create explicit extension points so teams can evolve industry variants without forking.
How do you handle different compliance requirements across industries? Standardize audit logging, identity, and data governance primitives, then layer industry-specific policies (retention, approvals, export formats) via configuration or policy modules that are tested and versioned.
Should we use microservices to scale across industries? Only if you have clear scaling constraints that justify the operational cost. Many teams scale cross-industry faster with a modular monolith first, then extract services where boundaries and load patterns demand it.
What is the fastest way to start building reusable components? Identify a repeated capability (RBAC, audit logs, integration adapters), define an interface and contract tests, implement it in one product, then prove it works in a second product before expanding.
Want to scale across industries without forking your codebase?
If you are seeing repeated implementations, inconsistent delivery patterns, or growing friction between industry variants, Wolf-Tech can help you design a reusable architecture baseline and implement it incrementally, without betting the company on a rewrite.
Explore Wolf-Tech at wolf-tech.io and reach out to discuss an architecture review, legacy optimization, or full-stack delivery support.