
Anwendungsentwicklungs-Roadmap für wachsende Teams


Schnell liefern ist nicht dasselbe wie gut skalieren. Mit wachsendem Personalbestand steigen Koordinationskosten, die Qualität bricht an den Rändern ein und der Release-Zug beginnt zu wackeln. Eine klare Anwendungsentwicklungs-Roadmap gibt wachsenden Teams ein gemeinsames Betriebsmodell, sodass Geschwindigkeit sich potenziert statt unter Komplexität zusammenzubrechen.
Dieser Leitfaden beschreibt eine pragmatische 12-Monats-Roadmap für Engineering-Verantwortliche, die von einer Handvoll Entwicklern zu mehreren crossfunktionalen Teams wachsen. Der Fokus liegt auf Ergebnissen, Leitplanken und der minimalen Menge an Praktiken, die nachhaltige Velocity ermöglichen.
Warum wachsende Teams eine Roadmap brauchen
Ohne Plan führt Wachstum zu versteckten Warteschlangen und Reibung. Onboarding verlangsamt sich, weil jedes Repo anders ist, Releases staün sich, weil Umgebungen Snowflakes sind, und dringende Refactorings stehlen Feature-Zeit. Eine Roadmap richtet Entscheidungen über Architektur, Delivery, Security und Teamdesign hinweg aus, sodass jedes Inkrement zukünftige Routinearbeit reduziert.
Der Ertrag ist messbar. Teams, die auf kleine Batch-Änderungen, Trunk-basierte Entwicklung und Continuous-Delivery-Praktiken standardisieren, verbessern konsistent Lead Time, Deployment-Frequenz, Change Failure Rate und Time to Restore Service. Das sind die weithin genutzten DORA-Metriken, dokumentiert durch Branchenforschung bei dora.dev.
Leitprinzipien für nachhaltige Geschwindigkeit
- Starten Sie von Geschäftsergebnissen, wählen Sie dann Technologie und Prozesse, die ihnen dienen.
- Bevorzugen Sie einfache Architektur, bis Sie Schmerz spüren, dann modularisieren Sie entlang echter Domänennähte.
- Standardmässig kleine, umkehrbare Änderungen, Trunk-basierte Entwicklung und signalstarke Reviews.
- Automatisieren Sie, was schmerzt, besonders Tests, Builds, Umgebungen und Security-Checks.
- Security und Zuverlässigkeit sind Features, integrieren Sie sie in die tägliche Arbeit.
- Messen Sie, was zählt, teilen Sie Dashboards und verbessern Sie das System, nicht die Menschen.
- Optimieren Sie die Developer Experience, denn Time to First Commit und Time to Safe Release bestimmen den Durchsatz.
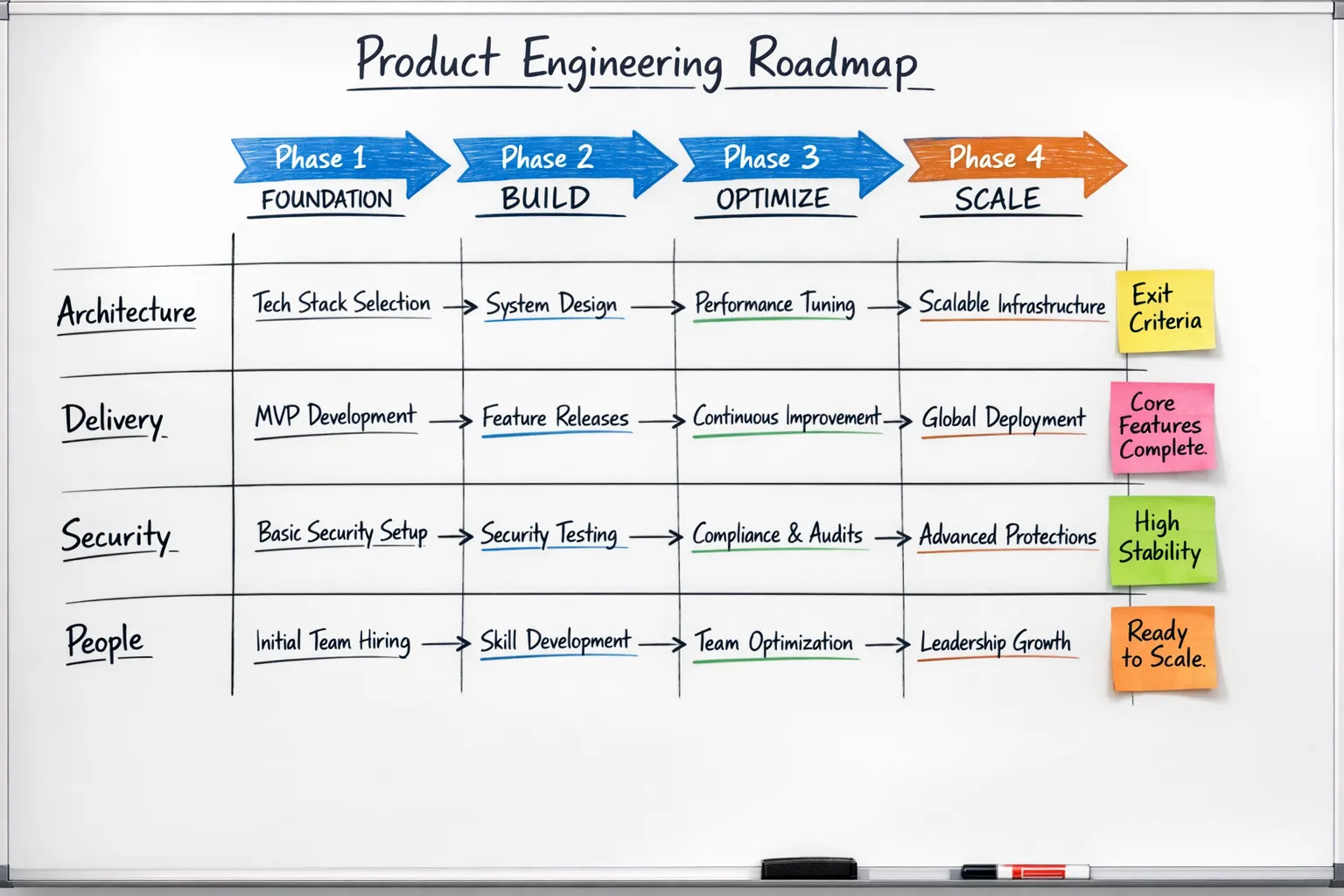
Eine 12-Monats-Anwendungsentwicklungs-Roadmap
Diese Roadmap ist in Phasen strukturiert. Zeitpläne sind Richtwerte. Wenn Sie bereits Teile implementiert haben, wenden Sie die Exit-Kriterien an und gehen Sie weiter.
Phase 1: Fundament, 0 bis 90 Tage
Legen Sie die Baseline, damit Entwickler zuversichtlich und konsistent liefern können.
Architektur und Code
- Wählen Sie eine architektonische Baseline, die Koordination minimiert, oft ein modularer Monolith mit klaren Domänengrenzen und Schnittstellen.
- Etablieren Sie ein einzelnes Repo oder eine begrenzte Anzahl mit konsistenten Projektgerüsten, Build-Skripten und Namenskonventionen.
- Führen Sie Architecture Decision Records ein, damit Abwägungen mit dem Wachstum dokumentiert sind.
Delivery und Qualität
- Setzen Sie Trunk-basierte Entwicklung mit kurzlebigen Branches ein, verlangen Sie grüne CI vor dem Merge und halten Sie Pull Requests klein.
- Richten Sie CI für Build, Lint, Unit-Tests und Dependency-Scanning ein. Behandeln Sie fehlschlagende Pipelines als Stoppschilder.
- Definieren Sie eine praktische Testpyramide. Streben Sie schnelle Unit- und Komponententests an, ergänzt durch eine Handvoll gezielter End-to-End-Checks.
Umgebungen und Betrieb
- Kodifizieren Sie Infrastruktur und Umgebungen. Mindestens Development, Staging und Production, erstellt mit IaC.
- Fügen Sie Basis-Observability hinzu: Zentralisierte Logs, Request-Metriken und Fehlerüberwachung mit Alerting bei nutzersichtbaren Fehlern.
Security und Compliance
- Implementieren Sie Secret Management und verhindern Sie, dass Secrets in die Versionskontrolle gelangen.
- Fügen Sie Software Composition Analysis hinzu und beginnen Sie mit der SBOM-Generierung. Richten Sie Ihre Security-Stories an OWASP ASVS-Levels aus, die zu Ihrem Risikoprofil passen.
Menschen und Arbeitsweisen
- Definieren Sie Definition of Ready und Definition of Done, Code-Review-Standards und Incident-Übergaben.
- Erstellen Sie ein leichtgewichtiges Onboarding-Playbook und ein Golden-Project-Template.
Exit-Kriterien
- Neue Entwickler können von Laptop zu erstem gemergtem, deployed Change in unter einem Tag gelangen.
- Jede Änderung durchläuft eine grüne CI-Pipeline und ist zu einem Ticket oder ADR nachverfolgbar.
- Staging und Production werden aus Code gebaut und sind umgebungsparitätisch kompatibel.
- Secrets werden verwaltet, Dependencies gescannt und grundlegende Monitoring-Alerts funktionieren.
Phase 2: Beschleunigung, 90 bis 180 Tage
Reduzieren Sie Batch-Größen, erhöhen Sie Feedback und eliminieren Sie Übergaben.
Architektur und Code
- Formalisieren Sie Domänengrenzen. Führen Sie interne Module oder Packages mit veröffentlichten Schnittstellen ein. Nutzen Sie Contract Tests, um Grenzen ehrlich zu halten.
- Wenden Sie Performance Budgets und Profiling auf die heissesten Pfade an. Baün Sie eine einfache Caching-Strategie auf.
Delivery und Qualität
- Führen Sie ephemere Preview-Umgebungen pro Pull Request ein, damit Reviewer echtes Verhalten sehen.
- Wechseln Sie zu Continuous Delivery. Automatisieren Sie Deployment auf Staging beim Merge, dann eine kontrollierte, risikoarme Promotion in die Produktion hinter Feature Flags.
- Erweitern Sie Test-Suites. Fügen Sie Integrations- und Contract Tests für APIs und wichtige Workflows hinzu. Starten Sie synthetisches Monitoring.
Betrieb und Zuverlässigkeit
- Definieren Sie Service Level Objectives für nutzersichtbare Latenz, Fehlerrate und Verfügbarkeit. Koppeln Sie Alerts an Error Budget Burn, nicht an rohe CPU-Werte.
- Fügen Sie Blü-Green- oder Canary-Deploys für Kernservices hinzu, mit automatischem Rollback bei fehlgeschlagenen Health Checks.
Security und Supply Chain
- Erweitern Sie Checks um statische Analyse, IaC-Scanning und Container-Image-Scanning.
- Etablieren Sie eine sichere Pipeline orientiert an NIST SP 800-218 SSDF. Fordern Sie Code Owners und obligatorische Reviews für sensible Bereiche.
Metriken und Produktfeedback
- Instrumentieren Sie DORA-Metriken und veröffentlichen Sie sie wöchentlich. Kombinieren Sie sie mit einigen Produktmetriken wie Aktivierung und Aufgabenabschlussrate.
Exit-Kriterien
- Jeder gemergte Change hat eine Preview, eine grüne Test-Suite und deployed automatisch auf Staging.
- Produktions-Releases sind Routine und drama-arm. Rollbacks sind per Knopfdruck und schnell.
- SLOs existieren für Schlüssel-Flows, mit Dashboards und On-Call-Runbooks.
Phase 3: Skalierung, 6 bis 12 Monate
Bereiten Sie sich auf Multi-Team-Delivery und höhere Einsätze vor.
Architektur und Plattform
- Führen Sie eine kleine Plattform-Fähigkeit ein, die einen vorgezeichneten Weg für Teams kuratiert. Bieten Sie Templates, Starter Repos und ein einfaches internes Entwicklerportal, das Golden Paths dokumentiert.
- Trennen Sie unabhängig skalierbare oder schnell ändernde Domänen nur heraus, wenn Daten dies rechtfertigen. Halten Sie gemeinsame Datenmodelle und Verträge stabil.
- Nutzen Sie Eventing oder eine zuverlässige Outbox für Cross-Domain-Kommunikation bei Bedarf. Halten Sie die operationale Komplexität proportional zum Wert.
Zuverlässigkeit und Kosten
- Verwalten Sie Kapazität proaktiv. Setzen Sie Autoscaling, Rate Limiting und Graceful Degradation ein. Berechnen Sie teure Operationen vor oder cachen Sie sie.
- Fügen Sie Kostensichtbarkeit pro Team und Produktschnitt hinzu. Tracken Sie Unit-Kosten wie Kosten pro tausend Requests oder pro aktivem Nutzer.
Security und Compliance
- Heben Sie die Messlatte bei der Supply-Chain-Integrität. Fügen Sie Provenance und signierte Artefakte hinzu. Richten Sie Builds am SLSA-Framework aus.
- Führen Sie Threat Modeling für kritische Flows durch. Erweitern Sie Security-Tests in der CI und fügen Sie Runtime-Schutz hinzu, wo angemessen.
Menschen und Betriebsmodell
- Wechseln Sie zu einem von Team Topologies inspirierten Modell. Stream-Aligned Teams verantworten Produktscheiben, ein Enabling Team beschleunigt die Übernahme von Praktiken, und eine schlanke Plattform-Fähigkeit beseitigt Reibung.
- Veröffentlichen Sie ein Engineering-Handbuch und Tech Radar. Lehren Sie, wie man den Golden Path nutzt, nicht nur was er ist.
Exit-Kriterien
- Teams können einen neuen Service oder eine App auf dem vorgezeichneten Weg in unter einer Stunde erstellen, mit CI/CD, Observability, Security-Scans und Templates vorverkabelt.
- Die meiste Arbeit findet in Stream-Aligned Teams statt, die unabhängig mit minimaler Koordination liefern können.
- Das Plattformteam agiert als Produkt, mit Backlog, SLAs und Adoptionsmetriken.
Phase 4: Multi-Team-Betriebsmodell, jenseits von 12 Monaten
An diesem Punkt wird die Roadmap zyklisch. Sie entwickeln die Plattform weiter, beschneiden Komplexität und bauen Führungskapazität auf. Fokusthemen umfassen:
- Cross-Team-API-Governance und Versionierung mit klaren Deprecation-Richtlinien.
- Objektive Entscheidungsgates für die Einführung neuer Services oder Technologien.
- Regelmäßige Architecture Fitness Functions, die nicht-funktionale Anforderungen testen.
- Security-Postur-Reviews orientiert an OWASP ASVS und Pipeline-Kontrollen orientiert an NIST SSDF.
- Kapazitätsplanung, Incident-Analyse und Zuverlässigkeits-Game-Days. Behandeln Sie Incidents als Gelegenheiten zur Verbesserung sozio-technischer Systeme.
Phasen-Exit-Kriterien auf einen Blick
| Phase | Primäre Ziele | Wichtige Exit-Kriterien |
|---|---|---|
| Fundament | Konsistente, sichere Baseline für Delivery schaffen | Onboarding unter 1 Tag, grüne CI ist Pflicht, Umgebungen kodifiziert, grundlegendes Monitoring und Secret Management vorhanden |
| Beschleunigung | Feedback erhöhen und Batch-Größe reduzieren | Preview-Umgebungen auf PRs, CD auf Staging, Flags für sicheres Release, SLOs definiert, wöchentliche DORA-Sichtbarkeit |
| Skalierung | Golden Paths bauen und dort aufteilen, wo es sich lohnt | IDP oder Portal mit Templates, Kosten- und Zuverlässigkeits-Leitplanken, begrenzte und begrundete Service-Grenzen, signierte Artefakte |
| Multi-Team | Steuern ohne Teams zu verlangsamen | API-Governance, Plattform als Produkt, regelmäßige Fitness-Checks, sich entwickelnde Security- und Zuverlässigkeitspraktiken |
Architekturentscheidungen, die gut altern
- Bevorzugen Sie zu Beginn einen modularen Monolithen mit klaren Domänengrenzen, Abhängigkeitsregeln und Build-Isolation. Verschieben Sie eine Grenze nur heraus, wenn es klare Flow- oder Skalierungsvorteile bringt.
- Halten Sie Verträge stabil. Versionieren Sie APIs, unterstützen Sie mindestens eine deprecated Version für einen festgelegten Zeitraum und veröffentlichen Sie Changelogs.
- Behandeln Sie die Datenbank als Teil der Systemschnittstelle. Nutzen Sie Zero-Downtime-Migrationsmuster und eine Outbox für zuverlässige Events.
- Integrieren Sie betriebliche Belange früh. Health Checks, Idempotenz, Backpressure und vorhersagbare Timeouts verhindern kaskadierende Ausfälle.
- Nutzen Sie 12-Factor-Prinzipien für Konfiguration, zustandslose Services und Parität zwischen Dev und Prod. Siehe The Twelve-Factor App.
Für Frontend-Webanwendungen und BFFs richten Sie Rendering und Caching an Produktbedürfnissen aus. Wenn Ihr Team moderne React-Laufzeiten und Server-Rendering-Strategien erkundet, taucht unser Leitfaden zu Next.js Best Practices tiefer ein.
Delivery- und DevEx-Leitplanken
Kleine, konsistente Praktiken erzeugen zusammengesetzten Hebel.
- Halten Sie Pull Requests klein und die Review-Zeit kurz. Fördern Sie Pairing oder Mobbing für komplexe Änderungen.
- Automatisieren Sie Preview-Umgebungen für visülles und funktionales Review. Das reduziert Nacharbeit.
- Cachen Sie Builds und Tests, um Feedback schnell zu halten. Optimieren Sie die längsten 10 Prozent der Pipelines zuerst.
- Standardisieren Sie Lint, Formatierung, Typenprüfung und Commit-Konventionen. Erzwingen Sie in der CI, um Stildiskussionen zu vermeiden.
- Dokumentieren Sie Run-Skripte, Umgebungsvariablen und lokales Dev-Setup im Repo. Streben Sie einen Ein-Befehl-Start an.
Bei der Auswahl oder Verfeinerung Ihres Stacks richten Sie ihn an nicht-funktionalen Anforderungen und Betriebsrealitäten aus. Wenn Sie dafür einen strukturierten Weg brauchen, siehe unseren Leitfaden How to Choose the Right Tech Stack in 2025.
Testing und Zuverlässigkeit: richtig dimensioniert
- Fokussieren Sie auf schnelle Unit- und Komponententests, fügen Sie dann eine dünne Schicht Integration und einige Ende-zu-Ende-Flows hinzu.
- Investieren Sie in Contract Tests an Domänen- und API-Grenzen. Sie verhindern versehentliche Kopplung, wenn Teams sich vermehren.
- Fügen Sie synthetische Checks für kritische Journeys hinzu und nutzen Sie sie als Canary-Signale während Deploys.
- Definieren Sie SLOs, die die Nutzererfahrung widerspiegeln, nicht Server-Interna. Koppeln Sie Alerts an Error Budget Burn, damit Teams Zuverlässigkeitsarbeit priorisieren können.
Für Modernisierungsszenarien wählen Sie Muster, die Störungen vermeiden. Unser Playbook zu Modernizing Legacy Systems Without Disrupting Business behandelt Strangler Fig, Feature Flags und Rollout-Strategien.
Security by Design für wachsende Teams
Die Sicherheitspostur sollte sich als natürliches Ergebnis von Delivery-Praktiken verbessern.
- Integrieren Sie Secret Scanning, SAST, SCA, IaC- und Container-Scanning in die CI. Blockieren Sie Builds bei kritischen Problemen und tracken Sie die Zeit bis zur Behebung.
- Generieren Sie SBOMs für jedes Release und speichern Sie sie neben Artefakten. Das beschleunigt die Reaktion auf Upstream-Schwachstellen.
- Wenden Sie Least Privilege für Services und Menschen an. Zentralisieren Sie Identität und Zugriff und rotieren Sie Credentials automatisch.
- Führen Sie Threat Modeling für Hochrisiko-Flows durch und erstellen Sie gezielte Abuse Cases und Tests. Richten Sie Ihre Verifikationsstufen an OWASP ASVS aus.
- Richten Sie Pipeline-Kontrollen und sichere Entwicklungspraktiken an NIST SSDF aus. Für Software-Supply-Chain-Härtung prüfen Sie die SLSA-Stufen und übernehmen Sie, was zu Ihrem Kontext passt.
Metriken, die steuern, nicht bestrafen
Wählen Sie einen kleinen, ausgewogenen Satz von Ergebnis- und Gesundheitskennzahlen und machen Sie sie sichtbar.
- Delivery-Gesundheit: Lead Time for Changes, Deployment-Frequenz, Change Failure Rate und Mean Time to Restore Service. Das sind die DORA-Metriken.
- Produktergebnisse: Aktivierung, Funnel-Conversion, Aufgabenabschluss und Retention für Ihre Schlüssel-Journeys.
- Zuverlässigkeit: SLOs und Error Budget Burn plus Incident-Häufigkeit und Time to Detect.
- Developer Experience: Time to First Commit, Time to First Deploy, CI-Dauer und Flaky-Test-Rate.
- Finanzen: Unit-Kosten nach Schlüsseldimension, zum Beispiel pro 1.000 Requests oder pro aktivem Nutzer, und Gesamt-Cloud-Ausgaben gegen ein Budget.
Veröffentlichen Sie diese in einem gemeinsamen Dashboard. Besprechen Sie sie in wöchentlichen Engineering-Foren, um die Diskussion auf Systemverbesserung zu fokussieren.
Teamdesign, das mit Autonomie skaliert
Organisationsdesign ist Teil der Architektur. Mit wachsendem Umfang entwickeln Sie sich in Richtung klarem Ownership und schlanker, zweckmässiger Plattformen.
- Stream-Aligned Teams verantworten kohäsive Scheiben des Produkts. Sie haben die Fähigkeiten zu entwerfen, bauen, releasen und ihre Scheibe zu betreiben.
- Ein Enabling Team beschleunigt die Übernahme neuer Fähigkeiten und Praktiken.
- Eine kleine Plattform-Fähigkeit behandelt die interne Entwicklerplattform als Produkt, mit Dokumentation, SLAs und Feedback-Schleife.
Dieses Modell wird durch Team Topologies populär gemacht. Der Schlüssel ist, für weniger Übergaben und schnelleres Lernen zu gestalten.
Eine kompakte Checkliste für den Start in diesem Quartal
- Schreiben Sie Exit-Kriterien für Ihre nächste Phase auf und teilen Sie den Plan in einem Engineering-Forum.
- Erstellen oder aktualisieren Sie das Golden-Path-Template, damit neue Services produktiv und sicher starten.
- Instrumentieren Sie DORA-Metriken und SLOs und platzieren Sie sie auf einem teamweit sichtbaren Dashboard.
- Fügen Sie ephemere Previews auf Pull Requests und ein Feature-Flag-System für sichere Releases hinzu.
- Setzen Sie ADRs für Architektur-Abwägungen ein und fordern Sie sie für querschnittliche Änderungen.
Wenn Sie gerade am Anfang Ihrer Reise stehen, kann unser Primer zu Web App Development helfen, ein hochgehebeltes MVP zu scopen und frühe Fallstricke zu vermeiden.

Wie Wolf-Tech helfen kann
Wolf-Tech arbeitet mit Unternehmen zusammen, um pragmatische Roadmaps wie die obige zu entwerfen und umzusetzen. Wir bringen Full-Stack-Entwicklung, Cloud- und DevOps-Expertise, Code-Qualität und Legacy-Optimierung, Datenbank- und API-Lösungen sowie Branchenerfahrung mit. Ob Sie Ihren Golden Path kodifizieren, eine Modernisierung entrisiken oder eine Plattform-Fähigkeit aufbauen, wir können Ihnen helfen, schneller mit Zuversicht voranzukommen.
Wenn Sie eine massgeschneiderte Anwendungsentwicklungs-Roadmap für Ihr Team wünschen, zusammen mit praktischem Delivery-Support und messbaren Meilensteinen, melden Sie sich bei wolf-tech.io.
Weiterführende Artikel von Wolf-Tech
- Next.js Best Practices for Scalable Apps
- How to Choose the Right Tech Stack in 2025
- Modernizing Legacy Systems Without Disrupting Business
- Refactoring Legacy Software: From Creaky to Contemporary
Referenzen
- DORA-Metriken und Forschung bei dora.dev
- OWASP ASVS
- NIST SP 800-218 SSDF
- SLSA-Framework
- The Twelve-Factor App