
Individualsoftware-Outsourcing: Risiken und Best Practices


Individualsoftware-Outsourcing kann ein echter Hebel sein. Es kann aber auch der teuerste Weg werden, um zu lernen, dass Ihre Anforderungen unscharf, Ihr Qualitätsanspruch implizit und Ihre Risikokontrollen eher angenommen als umgesetzt waren.
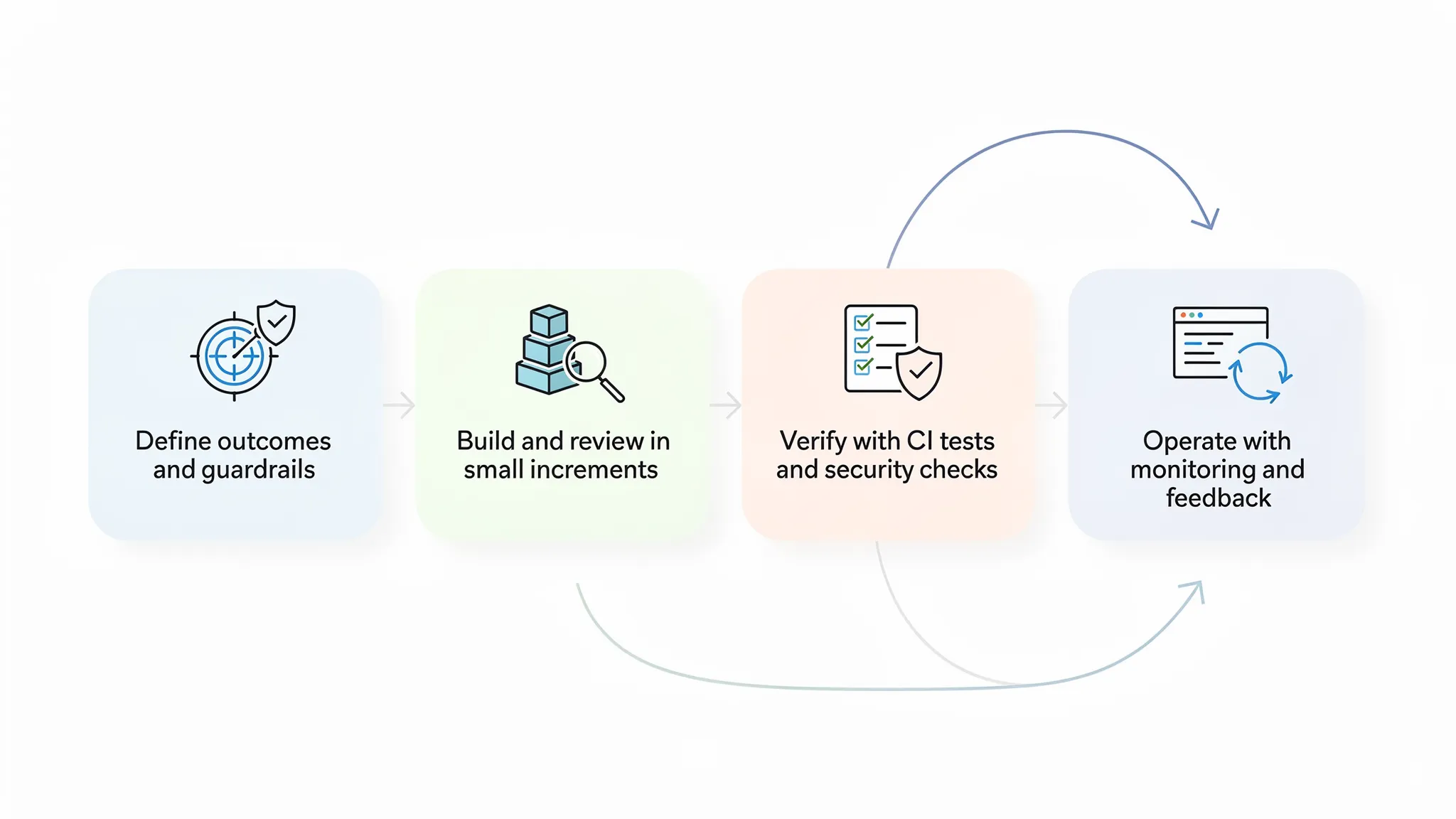
2026 dreht sich Outsourcing-Risiko weniger um „Zeitzonen" und mehr um den Betrieb eines verteilten Auslieferungssystems: Outcomes ausrichten, die richtige Schnittstelle zwischen Teams gestalten und Sicherheit, Qualität und Betreibbarkeit von Woche eins an messbar machen.
Was „Individualsoftware-Outsourcing" tatsächlich umfasst
Die meisten Teams meinen mit „Outsourcing" eines von drei Modellen (und sie ohne Klarheit zu mischen, ist der Anfang vieler Probleme):
- Projekt-Auslieferung: Der Dienstleister verantwortet die Auslieferung eines definierten Scopes, mit geteilter Produktverantwortung.
- Team-Augmentation: Externe Engineers kommen in Ihr Team, Sie verantworten Auslieferung und Architekturentscheidungen.
- Hybrid / Capability-basiert: Ein abgegrenzter Bereich (zum Beispiel Payments-Integration, Datenpipeline, Mobile App) wird mit expliziten Verträgen und Schnittstellen ausgelagert.
Das richtige Modell hängt davon ab, wie gut definiert das Problem ist, wie kritisch das System ist und wie viel interne Führung Sie realistisch bereitstellen können.
Eine nützliche Faustregel: Je geschäftskritischer und mehrdeutiger die Arbeit, desto mehr wollen Sie interne Produkt- und Architekturverantwortung, selbst wenn die Umsetzung extern erfolgt.
Die echten Risiken von Individualsoftware-Outsourcing (und wie sie sichtbar werden)
Outsourcing-Risiken sind vorhersagbar. Der Fehler ist, sie als „Dienstleister-Probleme" zu behandeln statt als Designfragen des Systems. Die folgende Tabelle ordnet typischen Versagensmustern konkrete Gegenmaßnahmen und die Belege zu, die Sie einfordern sollten.
| Risikokategorie | Wie es sich in echten Projekten zeigt | Best-Practice-Maßnahme | Belege, die Sie verlangen sollten |
|---|---|---|---|
| Fehlausrichtung der Outcomes | Velocity sieht gut aus, aber die Geschäftswirkung ist unklar, ständige Roadmap-Änderungen, dauerhafte Nacharbeit | Messbare Outcomes definieren und „Definition of Done", die Qualität und Betreibbarkeit einschließt | Einseitiges Outcome-Brief, Akzeptanzkriterien, Release-Gates |
| Anforderungslücke | „Fertig" bedeutet für jeden etwas anderes, Edge Cases übersehen, UAT wird zur Spezifikationsphase | Zeitlich begrenzte Discovery und ein dünner vertikaler Slice vor der Skalierung | Discovery-Ergebnisse, Demo des vertikalen Slice, aktualisiertes Backlog |
| Architektur-Drift | Inkonsistente Patterns, brüchige Kopplungen, Performance-Regressionen, schwer veränderbarer Code | Architektur-Leitplanken (ADRs, Referenzpatterns, Review-Checkpoints) | ADR-Log, Referenz-Repo, Architektur-Review-Notizen |
| Qualitätsschulden | Bugs sammeln sich an, QA wird zum Engpass, Releases verlangsamen sich | CI mit automatisierten Tests, Code-Review-Standards, Qualitätsmetriken | CI-Pipeline, Coverage-Ansatz, statische Analyse, PR-Policy |
| Sicherheitslücken | Späte „Penetration-Test-Panik", Secrets im Repo, schwache Autorisierung | Security-by-Design entlang anerkannter Standards | Notizen zum Secure SDLC, Threat Model, OWASP-Plan, Dependency-Scanning |
| Supply-Chain-Risiko | Ungeprüfte Abhängigkeiten, kompromittierte Pakete, intransparente Builds | SBOM, Provenance, signierte Artefakte wo angemessen | SBOM-Ansatz, SCA-Tooling, Build-Provenance-Plan |
| Vendor-Lock-in | Nur der Dienstleister kann deployen, Doku ist dünn, Schlüsselwissen lebt in Slack | Eigentumsregeln, Doku-Mindeststandards, Runbooks, Pairing | Runbooks, Onboarding-Doku, „Sie können es deployen"-Test |
| Kostenüberschreitung | Scope wächst, Change Requests eskalieren, Sie zahlen für Unsicherheit | Inkrementelle Finanzierung mit meilensteinbasierten Checkpoints | Meilensteinplan, Burn-up/Burn-down, Change Control |
| Compliance-/Regulatorik-Lücke | Audit-Anfragen werden zu Last-Minute-Feuerlöschaktionen | Controls früh mappen (Logging, Aufbewahrung, Zugriff, SDLC-Belege) | Control-Mapping-Doku, Zugriffslogs, audit-fähige SDLC-Artefakte |
Für Sicherheits- und Anwendungsrisiken hilft es, Ihre Erwartungen an weit verbreiteten Referenzen wie den OWASP Top 10 und das NIST Secure Software Development Framework (SSDF) zu verankern. Sie brauchen keine schwergewichtige Bürokratie, aber Sie brauchen explizite Controls.
Best Practices vor der Unterschrift (wo das meiste Risiko entschieden wird)
1) Schreiben Sie ein Outcome-Brief, keine Feature-Wunschliste
Ein starkes Outsourcing-Engagement startet mit einem kurzen Dokument, das beantwortet:
- Welches Geschäftsergebnis treiben wir, und wie messen wir es?
- Was sind die nicht-funktionalen Anforderungen (Verfügbarkeit, Latenz, Datenschutz, Audit-Fähigkeit, RTO/RPO)?
- Welche Integrationen, Datenquellen und betrieblichen Rahmenbedingungen existieren heute?
Wenn Sie tiefer in Scoping und Wertschöpfung einsteigen wollen, ist Wolf-Techs Leitfaden zur Übersetzung von Anforderungen in Outcomes ein guter Begleiter: Business Software Development: From Requirements to Value.
2) Wählen Sie ein Engagement-Modell, das zur Unsicherheit passt
Die häufigste Diskrepanz ist eine festpreisorientierte Vertragsstruktur für ein Problem mit hoher Unsicherheit. Wenn Sie die Lösung noch entdecken, optimieren Sie auf Lernen und Steuerbarkeit.
Ein praxisnaher Ansatz:
- Nutzen Sie Time and Materials für Discovery und frühe Iterationen.
- Führen Sie meilensteinbasierte Checkpoints ein, sobald die Unsicherheit sinkt.
- Halten Sie einen klaren Change-Control-Mechanismus bereit, der beide Seiten schützt.
Wenn Sie Budgetierungs-Hilfe brauchen, siehe: Custom Software Development: Cost, Timeline, ROI.
3) Führen Sie einen bezahlten Pilot durch, der echte Engineering-Arbeit enthält
Foliendecks sagen die Auslieferung nicht voraus. Ein kurzer Pilot (oft 2 bis 4 Wochen) sollte beweisen, dass der Dienstleister:
- In Ihrem Repo und Toolchain arbeiten kann (oder eines sauber aufsetzt)
- Einen dünnen vertikalen Slice mit CI, Tests und Review-Praktiken ausliefert
- Klar kommuniziert und Risiken früh sichtbar macht
Wenn Sie Dienstleister strukturiert evaluieren wollen, ohne daraus eine monatelange Beschaffungsübung zu machen, können Sie den Ansatz aus How to Vet Custom Software Development Companies wiederverwenden.
4) Klären Sie IP, Daten und KI-Nutzungsregeln explizit
2026 sollten Sie davon ausgehen, dass KI-gestützte Entwicklung irgendwo in der Kette stattfindet. Das ist nicht automatisch schlecht, aber es muss geregelt sein.
Klären Sie schriftlich:
- Welche Daten dürfen in KI-Tools verwendet werden (und welche nicht)
- Wie proprietärer Code und Kundendaten behandelt werden
- Wer das Arbeitsergebnis besitzt, einschließlich generierter Artefakte
- Wie Drittanbieter-Lizenzen verwaltet werden
Wenn Ihre Organisation reguliert ist oder sensible Daten verarbeitet, brauchen Sie zusätzlich Controls für Modellzugriff, Prompt-Logging und Aufbewahrung.
Best Practices während der Auslieferung (Kontrolle behalten ohne Mikromanagement)
Etablieren Sie eine schlanke Governance-Kadenz
Outsourcing funktioniert, wenn Entscheidungen schnell sind, Prioritäten stabil genug für Auslieferung sind und Risiken früh sichtbar werden.
Ein praxisnahes Governance-Setup sieht so aus:
| Meeting / Artefakt | Frequenz | Zweck | Output |
|---|---|---|---|
| Delivery-Sync | 2 bis 3 Mal pro Woche | Arbeit entblocken, Abhängigkeiten koordinieren | Aktualisierte Tasks, Risikoliste |
| Produkt-Review / Demo | Wöchentlich | Outcomes validieren, Fehlentwicklung verhindern | Aufgezeichnete Demo, Akzeptanznotiz |
| Architektur- und Qualitäts-Review | Zweiwöchentlich | Konsistenz halten und technisches Risiko steuern | ADRs, Action Items |
| Security- und Compliance-Check | Monatlich (oder pro Release) | Sicherstellen, dass Controls real, nicht aspirational sind | Belege, Fixes in der Queue |
| Steering-Checkpoint | Monatlich | ROI und Richtung auf Executive-Ebene bestätigen | Decision-Log, Roadmap-Update |
Entscheidend ist, dass Entscheidungen dokumentiert sind (kurz) und das Backlog diese Entscheidungen widerspiegelt.
Machen Sie Qualität messbar (und gemeinsam getragen)
Ein Dienstleister kann „Qualität wichtig finden" nicht herbeizaubern. Sie brauchen ein Auslieferungssystem, das Qualität sichtbar macht.
Mindestens sollten Sie verlangen:
- Pull-Request-Reviews mit expliziten Standards (kleine PRs, Test-Erwartungen, Security-Review-Trigger)
- CI, das auf jede Änderung läuft
- Eine Teststrategie mit Unit-Tests plus höhergradigen Tests, wo es zählt (Integration/Contract)
- Einen Release-Prozess, der Rollback und Incident-Verantwortung umfasst
Eine kleine Reihe von Auslieferungsmetriken zu verfolgen, hilft Ihnen, Probleme früh zu sehen. DORA-Style-Metriken (Lead Time, Deploy-Frequenz, Change Failure Rate, Time to Restore) sind eine bewährte Basis und bei DORA dokumentiert.
Behandeln Sie Sicherheit als Build-Feature, nicht als Phase
Sicherheit „am Ende" ist die Stelle, an der Outsourcing-Engagements scheitern: verzögerte Launches, teure Nacharbeit und Schuldzuweisungen.
Definieren Sie stattdessen Sicherheitsanforderungen vorab und setzen Sie sie kontinuierlich um:
- Threat Modeling für kritische Flows (Auth, Payments, Admin-Aktionen, Datenexport)
- Dependency-Scanning und Patch-Policy
- Secrets-Management (keine Secrets im Code oder in CI-Logs)
- Sichere Defaults für AuthN/AuthZ und Datenzugriff
Für die Integrität der Software-Supply-Chain können Sie Build- und Dependency-Praktiken an SLSA-Konzepten ausrichten, auch wenn Sie nicht das gesamte Framework übernehmen.
Betreibbarkeit gehört zu „Done"
Viele ausgelagerte Builds scheitern nicht, weil der Code „falsch" ist, sondern weil das System nicht sicher betrieben werden kann.
Nehmen Sie Betreibbarkeit in die Akzeptanz auf:
- Strukturierte Logs, Metriken und Tracing für die wichtigsten User Journeys
- SLOs (zum Beispiel Verfügbarkeits- und Latenzziele) und Alerting
- Runbooks für gängige Failure-Szenarien
- Eine getestete Deployment- und Rollback-Prozedur
Wenn Zuverlässigkeit kritisch ist, können Sie tiefer in Wolf-Techs Reliability-Playbook einsteigen: Backend Development Best Practices for Reliability.
Vertragliche und kommerzielle Leitplanken (praxisnah, nicht juristisch)
Verträge erzeugen kein Vertrauen, aber sie verhindern vorhersehbare Streitigkeiten. Das Ziel ist, dass die Arbeitsbeziehung die Verhaltensweisen erzwingt, die Sie brauchen.
| Bereich | Was Sie klären sollten | Warum es wichtig ist |
|---|---|---|
| Liefergegenstände und Abnahme | Klare Akzeptanzkriterien einschließlich nicht-funktionaler und betrieblicher Anforderungen | Verhindert „Es läuft auf meiner Maschine"-Streit |
| IP-Eigentum | Übertragungsklauseln für Code, Dokumente und Designs sowie Lizenzgrenzen | Reduziert künftiges rechtliches Risiko und Abhängigkeitsrisiko |
| Sicherheitspflichten | Erwartungen an Secure SDLC, Fristen für Vulnerability-Behebung, Meldung bei Verletzungen | Macht Sicherheit zur geteilten Verantwortung |
| Subunternehmer und Staffing | Offenlegung von Subkontraktierung, Schlüsselpersonen-Abhängigkeiten, Ersatzpolitik | Vermeidet Überraschungs-Teamwechsel und versteckte Dritte |
| Datenhandhabung | Zugriffskontrollen, Umgebungen, Anonymisierungsregeln, Aufbewahrung | Verhindert versehentliche Datenoffenlegung |
| Exit und Übergang | Übergabezeitraum, Doku-Liefergegenstände, Zugriffsübertragung, Escrow falls nötig | Stellt sicher, dass Sie ohne Unterbrechung weitermachen können |
| Change Control | Wie Scope-Änderungen vorgeschlagen, geschätzt und freigegeben werden | Verhindert Kostenexplosionen und Frust |
Praxistipp: Nehmen Sie einen Transition-Readiness-Test als Meilenstein auf, etwa „Ihr internes Team kann mit nur unterstützender Hilfe des Dienstleisters deployen und Probleme beheben". Das erzwingt kontinuierlichen Wissenstransfer statt panischer Endwoche.
Vendor-Lock-in vermeiden ohne Bürokratie-Overkill
„Lock-in" entsteht oft, weil der Dienstleister das einzige Team wird, das weiß, wie alles funktioniert, und das einzige Team mit den Schlüsseln.
Sie können das mit ein paar einfachen Regeln reduzieren:
- Ihre Organisation besitzt die Source-Repositories, Cloud-Accounts und CI/CD-Identität (mit Least-Privilege-Zugriff für den Dienstleister).
- Dokumentation ist Teil der Auslieferung (Runbooks, Architekturnotizen, Onboarding-Schritte).
- Verwenden Sie ADRs für wesentliche Entscheidungen, damit künftige Engineers verstehen, warum Entscheidungen getroffen wurden.
- Rotieren Sie Pairing-Sessions zwischen Dienstleister-Engineers und internen Engineers, besonders bei Deployment, On-Call-Themen und kritischer Domänenlogik.
Hier geht es nicht um Misstrauen, sondern um den Entwurf eines belastbaren Betriebsmodells.
Frühwarnsignale, dass Ihr Outsourcing-Engagement abdriftet
Die meisten Outsourcing-Misserfolge sind ab Woche 3 bis 6 sichtbar, aber Teams rationalisieren die Signale weg.
Achten Sie auf:
- Demos, die UI-Fortschritt zeigen, aber End-to-End-Flows, echte Daten oder produktionsähnliche Bedingungen meiden
- „Tests fügen wir später hinzu" oder „härten wir später" als wiederkehrendes Muster
- Große PRs mit langen Review-Zyklen und unklarer Verantwortung
- Wiederholte Nacharbeit, weil Akzeptanzkriterien unterschiedlich interpretiert werden
- Unklare Release-Bereitschaft (kein Rollback-Plan, kein Monitoring, kein Incident-Prozess)
Wenn Sie das sehen, springen Sie nicht direkt zum Dienstleisterwechsel. Korrigieren Sie zuerst das System: Akzeptanzkriterien schärfen, Batch-Größe verringern, CI-Gates erzwingen und Rollen sowie Entscheidungsbefugnisse zurücksetzen.
Ein pragmatischer 30-Tage-Kickstart-Plan für Outsourcing
So starten Sie mit Steuerbarkeit statt Chaos:
| Zeitfenster | Fokus | Konkrete Outputs |
|---|---|---|
| Woche 1 | Ausrichtung | Outcome-Brief, initiales Backlog, nicht-funktionale Anforderungen, Zugriffsmodell |
| Woche 2 | Fundament | Repo-Setup, CI-Pipeline, Coding-Standards, Umgebungsplan, initiale ADRs |
| Woche 3 | Vertikaler Slice | Ein dünner End-to-End-Flow unter produktionsähnlichen Bedingungen, einfaches Monitoring |
| Woche 4 | Skalierungsentscheidung | Pilot-Ergebnisse reviewen, Engagement-Modell anpassen, nächste Meilensteine festzurren |
Wenn das Team im ersten Monat keinen glaubwürdigen vertikalen Slice mit gesundem Engineering-Hygiene-Niveau liefern kann, skaliert ein größeres Team meist nur das Problem.
Wann Sie eine dritte Partei einbinden sollten (auch wenn Sie den Dienstleister behalten)
Manchmal ist der beste Schritt nicht „Dienstleister feuern", sondern „einen unabhängigen Checkpoint einziehen". Eine kurze Bewertung kann derisken:
- Legacy-Code und Modernisierungspläne
- Architektur- und Skalierbarkeitsentscheidungen
- CI/CD und Release-Zuverlässigkeit
- Code-Qualität und Wartbarkeit
- Sicherheits- und Compliance-Belege
Wolf-Tech unterstützt Teams mit Full-Stack-Entwicklung und Code-Quality-Consulting, einschließlich Legacy-Optimierung und Modernisierung. Wenn Sie eine zweite Meinung zu einem Outsourcing-Setup wollen (Dienstleisterauswahl, Pilotdesign, Architektur-Leitplanken oder Auslieferungssystem), starten Sie mit einer fokussierten Bewertung über wolf-tech.io.