
Performance-Software-Tuning: Ein messbasierter Workflow


Die meisten Performance-Arbeiten scheitern aus demselben Grund: Teams beginnen Code zu ändern, bevor sie messen können, was Nutzer tatsächlich erleben.
Ein messbasierter Workflow dreht diese Reihenfolge um. Sie definieren zunächst, was „schnell genug" bedeutet, erstellen eine Baseline, lokalisieren den Engpass mit Belegen, nehmen eine kleine, wirkungsstarke Änderung vor und messen dann erneut. Das Ergebnis: weniger riskante Neuentwicklungen, weniger Placebo-Optimierungen und ein System, das Sie langfristig schnell halten können.
Was „Performance" in Performance-Software wirklich bedeutet
Wenn jemand sagt „die App ist langsam", meint er meist eines der folgenden:
- Latenz: wie lange eine Anfrage oder Nutzerinteraktion dauert (p95 und p99 beobachten, nicht Durchschnittswerte).
- Durchsatz: wie viele Jobs, Anfragen oder Events pro Sekunde verarbeitet werden können.
- Ressourceneffizienz: CPU, Arbeitsspeicher, Datenbanklast, Netzwerkegress, Warteschlangentiefe.
- Wahrgenommene Reaktionsfähigkeit: Seitenladezeiten und Interaktionsmetriken (für Web: Core Web Vitals).
Der praktische Fehler besteht darin, Performance als eine einzige Zahl zu behandeln. In der Realität hat jede Nutzerreise ihren eigenen kritischen Pfad und ihr eigenes akzeptables „Budget".
Für Web-Apps sind Googles Core Web Vitals eine gängige nutzerorientierte Baseline. Die Definitionen und aktuelle Leitlinien finden Sie auf web.dev. Für React-spezifisches Tuning ist Wolf-Techs Leitfaden zum Beheben von LCP, CLS und TTFB in React eine gute Ergänzung.
Schritt 0: Erfolgskriterien mit SLIs, SLOs und einem Performance-Budget definieren
Bevor Sie irgendetwas profilieren, machen Sie das Ziel explizit.
- SLI (Service Level Indicator): was Sie messen (Beispiel: „HTTP-Anfragedauer für GET /checkout").
- SLO (Service Level Objective): der Schwellenwert (Beispiel: „p95 < 400 ms").
- Budget: wie viel Latenz, CPU oder Client-JS Sie „ausgeben" können, bevor das Erlebnis oder die Kosten inakzeptabel werden.
Ein einfaches SLO-Set, das für viele B2B-SaaS- und Transaktionssysteme funktioniert:
| Nutzerreise oder API | Primärer SLI | Empfohlene Sicht | Beispiel-SLO-Ziel (illustrativ) | Hinweise |
|---|---|---|---|---|
| Login + initialer App-Load | TTFB, LCP (Web) | p75 Feldmetriken | LCP im Web-Vitals-„gut"-Bereich | Felddaten verwenden, da echte Geräte und Netzwerke relevant sind. |
| „Suche/Liste"-Ergebnisse | API-Latenz | p95 und p99 | p95 < 300–600 ms | Listenendpunkte sind oft DB-gebunden und datenwachstumssensibel. |
| „Checkout/Absenden"-Aktion | End-to-End-Transaktionszeit | p95 | p95 < 1–2 s | Externe Abhängigkeiten einschließen (Zahlungen, E-Mail, Betrugschecks), wenn Nutzer wartet. |
| Hintergrundverarbeitung | Warteschlangenverzögerung, Job-Dauer | p95 | Verzögerung < X Minuten | Definieren, was „frisch genug" für das Unternehmen bedeutet. |
Wenn Sie bereits operative Ziele veröffentlichen (oder möchten), passt dies gut zu einem Zuverlässigkeitsmodell mit SLIs und Fehlerbudgets. Wolf-Techs Backend-Zuverlässigkeits-Best-Practices behandeln diese Denkweise.
Schritt 1: Eine Baseline erstellen (Feld zuerst, Labor zweite)
Sie benötigen zwei Baselines, da sie unterschiedliche Fragen beantworten.
Feld-Baseline (echte Nutzer)
Feldmessung zeigt, was Kunden tatsächlich erleben – auf echten Geräten, Netzwerken, in verschiedenen Regionen und mit unterschiedlichen Caches.
Was zu erfassen ist:
- RUM (Real User Monitoring) für Web: LCP, CLS, INP, TTFB, Route-Übergänge, JS-Fehler.
- Server-Metriken: Anfragedauer-Histogramme, Fehlerraten, Sättigung (CPU, Arbeitsspeicher), Warteschlangentiefe.
- Distributed Traces: End-to-End-Spans über API-Gateway, Services, Datenbanken und Drittanbieter.
Wenn Sie die Observability standardisieren, ist OpenTelemetry der gängigste herstellerunabhängige Pfad für Traces, Metriken und Logs. Die offizielle Dokumentation finden Sie unter opentelemetry.io.
Labor-Baseline (kontrollierte Reproduktion)
Labormessung (synthetische Checks, Lighthouse, Lasttests, Profiling in Staging) ermöglicht die schnelle Reproduktion von Problemen und Validierung von Fixes.
Der Schlüssel sind repräsentative Workloads:
- Repräsentative Datengröße (ein „großes" Kundenkonto, kein leerer Dev-Mandant)
- Repräsentative Gleichzeitigkeit
- Repräsentative Integrationen (oder realistische Stubs)
Wenn Ihr Labortest zu sauber ist, optimieren Sie für eine Welt, in der Ihre Nutzer nicht leben.
Schritt 2: Den Engpass mit einer Systemkarte lokalisieren
Wenn Sie eine Baseline haben, erstellen Sie eine schnelle „Performance-Karte" des kritischen Pfads. Sie versuchen zu beantworten: Wo geht die Zeit tatsächlich hin?
Ein praktischer, evidenzbasierter Ansatz ist die Kategorisierung von Symptomen in:
- Arbeit: zu viel Berechnung oder zu viel I/O
- Warten: Konkurrenz, Lock-Wartezeiten, Thread-Pool-Starvation, Warteschlangen-Rückstau
- Verschwendete Arbeit: wiederholte Queries, Over-Fetching, unnötiges Rendern, doppelte API-Aufrufe
Ein nützliches Denkmodell ist Brendan Greggs USE-Methode (Utilization, Saturation, Errors) zur schnellen Erkennung von Ressourcenengpässen. Sein Artikel ist verfügbar unter brendangregg.com.
In dieser Phase: Widerstand gegen „Fix-Ideen" leisten. Ihr Ziel ist eine hochkonfidente Aussage wie:
Die p95-Latenz ist gestiegen, weil die DB-Zeit für Query X nach Datenwachstum zugenommen hat und die Anwendung seriell auf drei Round-Trips pro Anfrage wartet.
Diese Aussage ist mehr wert als eine Woche spekulativer Refactorings.
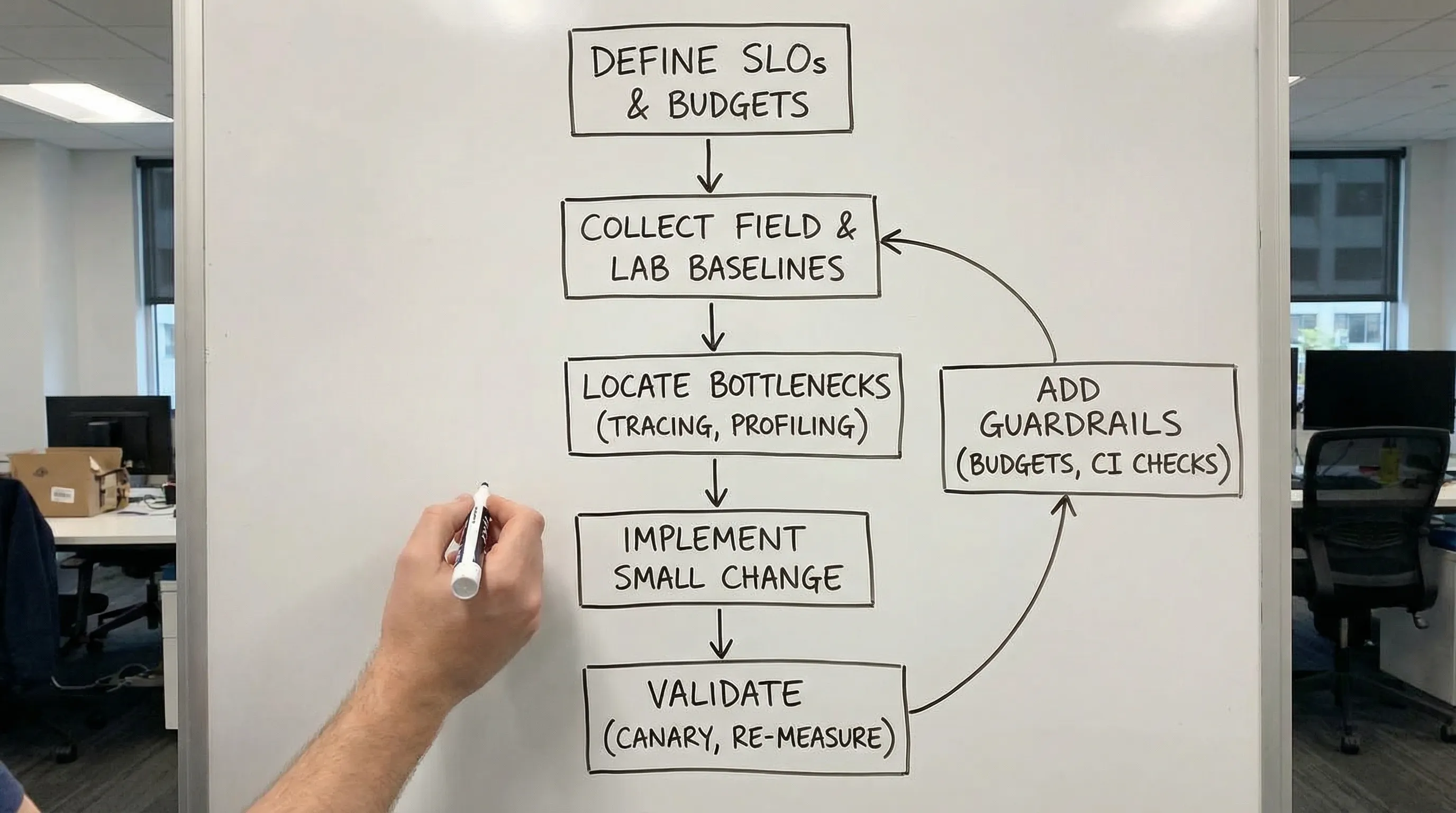
Schritt 3: Reproduzieren und isolieren (Profiling, Tracing und Query-Pläne)
Verschiedene Engpässe erfordern verschiedene Werkzeuge. Der Workflow ist konsistent, aber das „Mikroskop" ändert sich.
Wenn der Engpass in der Datenbank liegt
Hochsignifikante Belege umfassen meist:
- Slow-Query-Logs
- Query-Plan-Analyse (und ob Indizes genutzt werden)
- N+1-Muster (viele ähnliche Queries pro Anfrage)
- Lock-Konkurrenz und lange Transaktionen
Isolationstaktik: Einen repräsentativen Endpunkt nehmen, einen Trace erfassen und Spans mit dem genauen SQL und seinem Plan abgleichen. Wenn Sie Traces nicht mit spezifischen Queries verbinden können, zuerst Instrumentierung hinzufügen.
Wenn der Engpass in der Backend-Anwendung liegt
Meist sucht man nach:
- Hot Methods in CPU-Profilen
- Übermäßigen Allokationen und GC-Druck
- Thread-Pool- oder Async-Executor-Starvation
- Serialisierungs- und Validierungsoverhead in Hot Paths
Isolationstaktik: Profile von „schnellen" vs. „langsamen" Läufen unter gleicher Last vergleichen, nicht zwei verschiedene Umgebungen.
Wenn der Engpass im Frontend liegt
Belege umfassen meist:
- Lange Tasks und Main-Thread-Blockierungen
- Hydrations- oder Renderingkosten
- Bundle-Größe und Code-Splitting-Fehler
- Wasserfallmäßige Datenabrufe
Isolationstaktik: Route-Level-Übergänge messen und identifizieren, welche Anfragen oder JS-Chunks die Interaktivität blockieren. Wolf-Techs Next.js Performance Tuning Leitfaden taucht tiefer in diesen Pfad für Next.js-Apps ein.
Schritt 4: Eine kleine Änderung vornehmen und neu messen (Experimentdesign)
Performance-Tuning ist Ingenieurswesen, keine Kunst. Behandeln Sie jede Änderung wie ein Experiment.
Eine gute Performance-Änderung hat:
- Eine Hypothese: „Das Entfernen eines Netzwerk-Round-Trips wird p95 um 120 ms reduzieren."
- Eine primäre Metrik: der SLI, den Sie bewegen möchten.
- Einen Rollback-Plan: Feature-Flag, Konfigurationsschalter oder ein sauberes Revert.
- Eine Blast-Radius-Kontrolle: Canary-Releases, prozentualer Rollout oder mandantenbasierter Rollout.
Wenn Sie fünf Dinge gleichzeitig ändern, werden Sie nicht lernen, welche gewirkt hat, und Sie werden keine wiederholbare Tuning-Fähigkeit aufbauen.
Wirkungsstarke Fixes (die, die meist den Unterschied machen)
Sobald Sie einen bewiesenen Engpass haben, liefern diese Fix-Familien tendenziell die größten Gewinne in Performance-Software-Systemen.
1) Round-Trips und Serialisierungs-Overhead reduzieren
Typische Gewinne:
- Chatty Request-Muster in weniger Aufrufe zusammenfassen
- Lese- und Schreiboperationen batchen
- Vermeiden, bereits bekannte Daten erneut abzurufen
Round-Trips sind Latenzmultiplikatoren. Tail-Latenz wird besonders schmerzhaft, wenn mehrere Abhängigkeiten im selben kritischen Pfad gestapelt werden.
2) Datenzugriff vorhersehbar machen
Typische Gewinne:
- Indizes basierend auf realen Query-Mustern hinzufügen oder korrigieren
- N+1-Queries entfernen
- „Flexible, aber langsame" Queries in explizite, gut begrenzte umschreiben
Hier liegt auch der Ursprung vieler „es hat in Staging funktioniert"-Fehler: Produktionsdatenverteilungen verändern alles.
3) Arbeit vom kritischen Pfad nehmen
Typische Gewinne:
- Hintergrundjobs für nicht wesentliche Arbeit verwenden (E-Mails, Berichte, schwere Berechnungen)
- Asynchrone Verarbeitungsmuster verwenden, wo der Nutzer keinen synchronen Abschluss benötigt
- Streaming oder progressives Rendering wo angemessen (Web)
Das Ziel ist nicht, alles asynchron zu machen. Das Ziel ist, den wartenden Pfad des Nutzers kurz und zuverlässig zu halten.
4) Caching gezielt einsetzen, mit betreibbaren Invalidierungsregeln
Caching kann ein bedeutender Beschleuniger oder eine langfristige Quelle von Korrektheitsproblemen sein. Machen Sie es explizit:
- Was gecacht wird (Schlüssel- und Wertform)
- TTL und Eviction-Verhalten
- Invalidierungs-Trigger
- Wie Sie Cache-Trefferrate und Auswirkung auf p95 messen
5) Verschwendete Arbeit eliminieren
Das ist die „stille Killer"-Kategorie:
- Teure Validierung zweimal durchführen
- UI rendern, die sofort ersetzt wird
- Drittanbieter-Scripts laden, die den Main-Thread blockieren
- Logging- oder Debug-Features, die versehentlich in Hot Paths aktiv gelassen wurden
Wolf-Techs Artikel zu wirkungsstarken Code-Optimierungen jenseits von Mikro-Optimierungen ist auf diese Kategorien ausgerichtet, aber der Schlüssel ist: Den Fix nur nach Bestätigung des Engpasses durch Messung auswählen.
Schritt 5: Regressionen verhindern (Performance als Produktfähigkeit)
Das „Tuning" ist nicht der schwierige Teil. Die Performance durch konstante Veränderung stabil zu halten, ist es.
Performance-Budgets hinzufügen
Budgets verwandeln Performance von „einer Sorge" in eine durchsetzbare Einschränkung. Beispiele:
- Maximale JS-Größe auf Route-Ebene
- Maximale Anzahl von Queries pro Anfrage
- Maximaler p95-Wert für einen kritischen Endpunkt unter definierter Last
Checks in CI integrieren
Gute CI-Checks sind schnell und wiederholbar. Optionen:
- Ein fokussierter Lasttest für die Top-3-Endpunkte
- Ein Route-Level-Lighthouse-Check für Schlüsselseiten
- Ein Regressionsschwellenwert auf serverseitigen p95-Werten in einer kontrollierten Umgebung
Releases in Observability markieren
Wenn Sie eine Regression nicht mit einem Deployment korrelieren können, verschwenden Sie Zeit. Stellen Sie sicher, dass jede Metrik und jeder Trace nach folgenden Kriterien gefiltert werden kann:
- Service
- Version / Commit-SHA
- Umgebung
- Mandant (wenn anwendbar)
Das ist eine der einfachsten Möglichkeiten, Performance-Arbeit in eine stetige operative Praxis zu verwandeln, anstatt in eine wiederkehrende Feuerlösch-Übung.
Ein praktischer 10-Tage-Messbasierter-Tuning-Sprint
Wenn Sie eine leichtgewichtige Möglichkeit benötigen, dies schnell umzusetzen, ist hier eine pragmatische Sprint-Struktur, die in die meisten Teams passt.
| Zeitrahmen | Ziel | Verifizierbare Ergebnisse |
|---|---|---|
| Tage 1–2 | Ziele und Baseline definieren | SLIs/SLOs, Dashboards, Liste der langsamsten Reisen/Endpunkte, Baseline p95/p99 |
| Tage 3–4 | Engpass lokalisieren | 1–2 Traces, die die dominante Zeitsenke zeigen, in Labor oder Staging reproduziert |
| Tage 5–7 | Kleinsten wirkungsstarken Fix implementieren | Eine Änderung hinter einem Flag, klares Rollback, Vor-/Nachher-Messungen |
| Tage 8–9 | Sicher in Produktion validieren | Canary-Rollout-Ergebnisse, Fehlerauswirkung geprüft, Kostenauswirkung geprüft |
| Tag 10 | Leitplanken hinzufügen | Budget, CI/Smoke-Check, Alert-Schwellenwerte, Runbook-Notizen |
Beachten Sie, was fehlt: ein breites Refactoring. Wenn der beste Fix wirklich strukturell ist, werden Sie das mit Belegen herausfinden und es als Produktinvestition planen können, nicht als Panik-Neuentwicklung.
Wann eine externe Performance-Überprüfung sinnvoll ist
Holen Sie sich eine externe Performance-Überprüfung, wenn:
- Sie keine vertrauenswürdige Observability haben und schnell eine saubere Baseline benötigen
- Tail-Latenz Umsatz oder Kundenbindung beeinträchtigt und Sie den Engpass nicht isolieren können
- Das System legacy-lastig ist und Änderungen hohes Release-Risiko tragen
- Ihr Team ständig „tuned", aber Regressionen immer wiederkehren
Wolf-Tech hilft Teams beim Aufbau und Tuning von Performance-Software-Systemen im gesamten Stack, von Observability-Baselines und Legacy-Optimierung bis hin zu sicheren Rollout-Strategien. Wenn Sie einen messbasierten Performance-Plan für Ihre Architektur und Einschränkungen wünschen, starten Sie unter wolf-tech.io.