
PHP Symfony – Performance und Wartbarkeit: Best Practices


Symfony hat seinen Ruf für „ernsthafte" PHP-Anwendungen aus gutem Grund: Es liefert die Grundbausteine, um Systeme zu bauen, die schnell, testbar und weiterentwickelbar sind. Die Kehrseite ist, dass Performance und Wartbarkeit nicht von allein entstehen. Sie sind das Ergebnis einiger bewusster Entscheidungen über Architektur-Grenzen, Laufzeitkonfiguration, Datenzugriffsmuster und die Qualitätsgates, die man in CI durchsetzt.
Dieser Leitfaden konzentriert sich auf praktische PHP Symfony Best Practices, die sowohl Performance (Latenz, Durchsatz, Ressourcenkosten) als auch Wartbarkeit (Änderungssicherheit, Upgradefähigkeit, Onboarding-Geschwindigkeit) verbessern – ohne in vorzeitige Komplexität zu verfallen.
Mit einer Baseline beginnen (sonst optimiert man am falschen Ort)
Bevor man Code verändert, sollte man festlegen, was „gut" bedeutet, und es messen.
3 bis 5 Metriken wählen, die Nutzer- und Geschäftsergebnisse widerspiegeln
Typische Ausgangspunkte:
- p95/p99-Latenz für die wichtigsten Nutzer-Journeys (Login, Checkout, Suche, Back-Office-Aktionen)
- Fehlerrate (nach Route und nach Abhängigkeit)
- Datenbankzeit pro Request (und Anzahl langsamer Abfragen)
- Durchsatz (Requests pro Sekunde) bei bekannter Parallelität
- Kostensignale (CPU, Arbeitsspeicher, Cache-Trefferquote)
Wenn man eine einfache Möglichkeit braucht, „Performance" in Engineering-Constraints zu übersetzen, definiert man Performance-Budgets pro Route (TTFB, gesamte Serverzeit, DB-Zeit) und setzt diese in PR-Reviews durch.
Für einen umfassenderen „Measure-first"-Optimierungsansatz ergänzt Wolf-Techs Leitfaden zu Code-Optimierungstechniken zur Beschleunigung von Apps dieses Symfony-spezifische Playbook.
Die richtigen Werkzeuge in den richtigen Umgebungen einsetzen
- In der Entwicklung den Symfony Profiler verwenden, um schwere Controller, häufige Doctrine-Aufrufe und aufwendiges Twig-Rendering zu identifizieren.
- In der Produktion auf APM + Logs + Metriken setzen (nicht auf die Dev-Toolbar). Trends über Releases hinweg verfolgen.
Eine nützliche Faustregel: Man sollte in der Lage sein, die Frage „Was wurde nach dem letzten Deployment langsamer?" innerhalb von Minuten zu beantworten – nicht erst nach Tagen.
Symfony Performance Best Practices (die sich meist lohnen)
Performance in Symfony geht selten auf eine einzige Wundereinstellung zurück. Es geht darum, verschwendete Arbeit im Request-Lifecycle zu eliminieren und teure Operationen vorhersagbar zu machen.
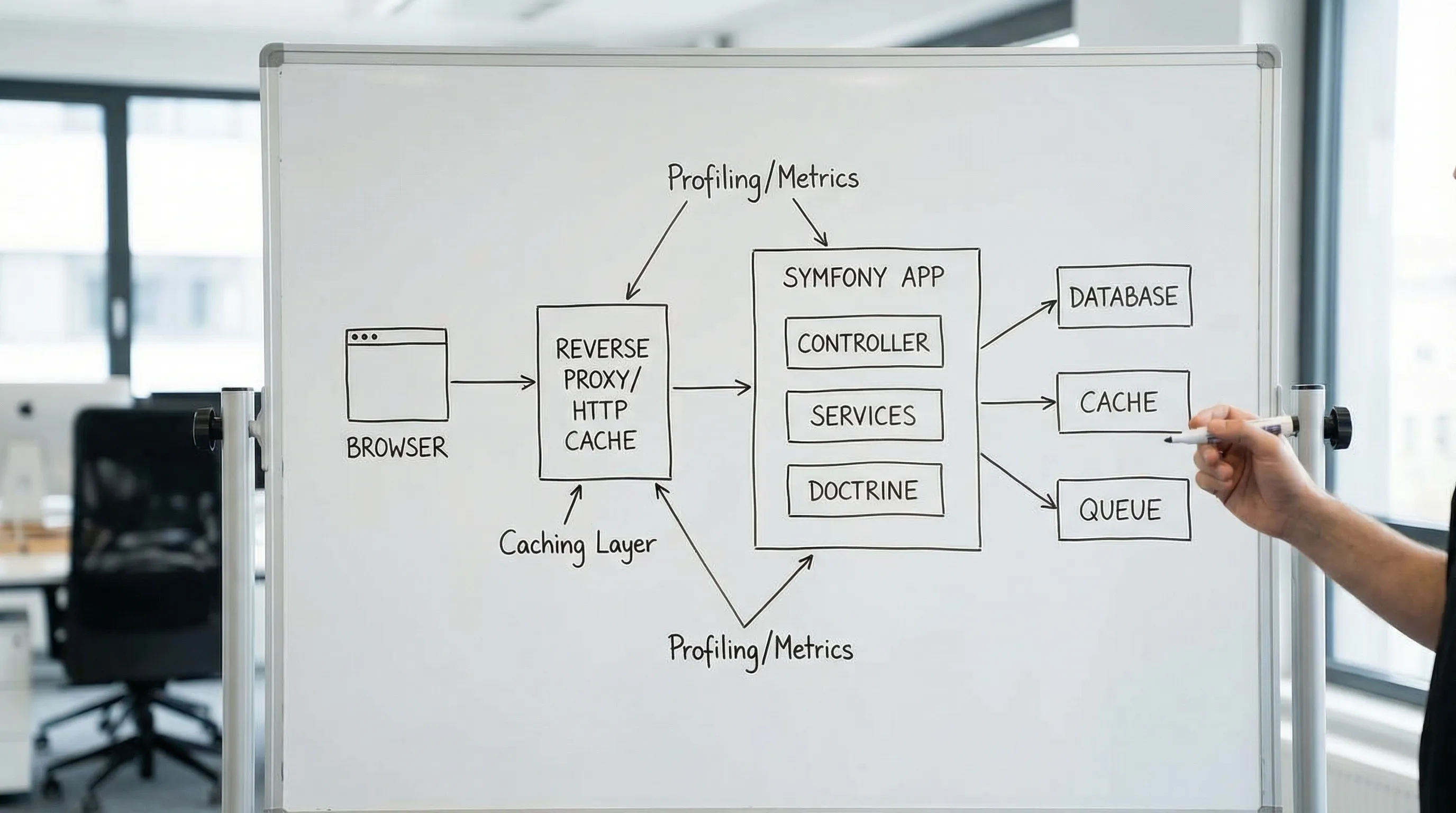
Symfony im echten Produktionsmodus betreiben
Das klingt offensichtlich, doch Performance-Vorfälle lassen sich häufig auf „fast-Prod"-Setups zurückführen.
Wichtige Prüfpunkte:
- Sicherstellen, dass
APP_ENV=produndAPP_DEBUG=0in der Produktion gesetzt sind. - Den Cache während des Deployments vorwärmen (
cache:warmup), damit die ersten Nutzer nicht für die Container-Kompilierung bezahlen. - Laufzeit-Dateischreibvorgänge vermeiden, wo möglich (Container und Cache sollten beim Deployment gebaut werden, nicht unter Last).
Referenz: Symfony-Umgebungen und Debug-Modus.
PHP-Laufzeitkonfiguration als Teil der Performance-Arbeit behandeln
Symfony kann nur so schnell sein wie die PHP-Laufzeit darunter.
Wichtige Punkte zum Überprüfen:
- OPcache aktiviert und korrekt dimensioniert (erheblicher Einfluss auf reale Systeme)
- PHP-FPM-Prozessmanagement auf Traffic- und Speicherprofil abgestimmt
- Angemessene Realpath-Cache-Einstellungen bei vielen Dateien (häufig in Symfony-Apps)
Ist OPcache falsch konfiguriert, kann man perfekt optimierten Code liefern und trotzdem den größten Teil der Vorteile verlieren.
Referenz: PHP OPcache-Dokumentation.
HTTP-Caching als erstklassige Designentscheidung behandeln
Wenn die App Inhalte ausliefert, die gecacht werden können (auch nur für kurze Zeiträume), bietet Symfony ausgezeichnete Werkzeuge:
- Explizite Cache-Control-Header für cachefähige Routen setzen.
- ETag/Last-Modified für bedingte Requests verwenden.
- Bei Einsatz eines Reverse Proxys (z. B. Varnish, Nginx-Caching oder CDN) Responses cache-freundlich gestalten.
In Symfony sind HTTP Cache und Cache-Control-Direktiven einen erneuten Blick wert – besonders wenn derzeit alles auf no-store standardmäßig gesetzt ist.
Wartbarkeitshinweis: Caching ist leichter korrekt zu halten, wenn man explizit definiert, was variiert (Nutzer, Locale, Mandant, Berechtigungen) und das in Headern kodiert, statt es in Ad-hoc-Logik zu vergraben.
Den Cache-Komponenten gezielt einsetzen (nicht als Nachgedanken)
Für Caching auf Anwendungsebene (Daten und Berechnungen) ist Symfonys Cache-Komponente eine solide Standardlösung.
Gängige Best Practices:
- Cache-Pools pro Anliegen verwenden (z. B. „Katalog", „Berechtigungen", „Rate Limits"), um TTLs und Invalidierung zu tunen.
- Begrenzte TTLs und explizite Invalidierungsauslöser bevorzugen anstelle von „Cache forever".
- Trefferquote und Evictions verfolgen. Ein Cache mit 90 % Misses ist reiner Overhead.
Bei Redis oder Memcached sicherstellen, dass auch betriebliche Sichtbarkeit vorhanden ist (Speichernutzung, Eviction-Policy, Persistenzeinstellungen), damit Caching kein Zuverlässigkeitsrisiko wird.
Doctrine dort optimieren, wo es am meisten zählt (Hot Paths)
Doctrine kann schnell sein, wird aber auch teure Operationen ausführen, wenn man es lässt.
Maßnahmen mit hohem Impact für Symfony-Projekte mit Doctrine:
N+1-Abfragen verhindern
- N+1-Muster in Templates und Serializern im Blick behalten.
- Eager Fetching oder maßgeschneiderte Abfragen verwenden, wo angemessen.
Referenz: Doctrine ORM Fetching.
Weniger Zeilen und weniger Spalten abfragen
- Große Objektgraphen nicht laden, wenn nur ein Teil davon benötigt wird.
- DTO-Lesemodelle für List-Endpoints in Betracht ziehen, anstatt vollständige Entities zu hydrieren.
Für die tatsächlich ausgeführten Abfragen indexieren
- Indizes auf Basis echter Abfragemuster aus der Produktion hinzufügen oder anpassen.
- Indizes nach Feature-Arbeiten erneut prüfen (ein neuer Filter verändert oft alles).
Vorsicht mit „cleveren" ORM-Tricks
Second-Level-Caches, schwere Vererbungs-Mappings oder tiefe Lifecycle-Callbacks können die Wartbarkeit beeinträchtigen und Performance schwerer nachvollziehbar machen. Auf Hot Paths Explizitheit bevorzugen.
Langsame Arbeit aus dem Request-Cycle auslagern
Wenn ein Feature das Versenden von E-Mails, das Generieren von PDFs, den Aufruf von Drittanbieter-APIs oder die Datensynchronisierung erfordert, entstehen durch die Ausführung innerhalb eines Web-Requests oft Latenz- und Zuverlässigkeitsprobleme.
Symfony Messenger ist hier eine gängige Lösung:
- Nicht-interaktive Arbeit in eine Queue auslagern.
- Handler idempotent gestalten (sicher wiederherzustellen).
- Dead-Letter-Handling und Observability für Fehler hinzufügen.
Referenz: Symfony Messenger.
Regressionen durch Budgets und CI-Checks verhindern
Der einfachste Performance-Gewinn besteht darin, Performance-Verluste zu vermeiden.
Praktische Optionen:
- Performance-Smoke-Tests für kritische Routen in CI hinzufügen (selbst ein kleiner k6/Gatling/JMeter-Lauf kann gravierende Regressionen erkennen).
- Query-Count-Budgets für Schlüssel-Endpoints durchsetzen.
- Performance-Änderungen pro Release in der Überwachung verfolgen.
Dies passt gut zur Delivery-System-Anleitung in Wolf-Techs CI/CD-Technologie-Leitfaden: In kleineren Batches ausliefern, messen und schnell erholen.
Symfony Wartbarkeits-Best Practices (damit die App veränderbar bleibt)
Wartbarkeit ist das, was „heute schnell" davon abhält, „nächstes Quartal feststeckend" zu werden. Bei Symfony kommt es auf Architektur-Grenzen, Konfigurationsdisziplin und automatisierte Sicherheitsnetze an.
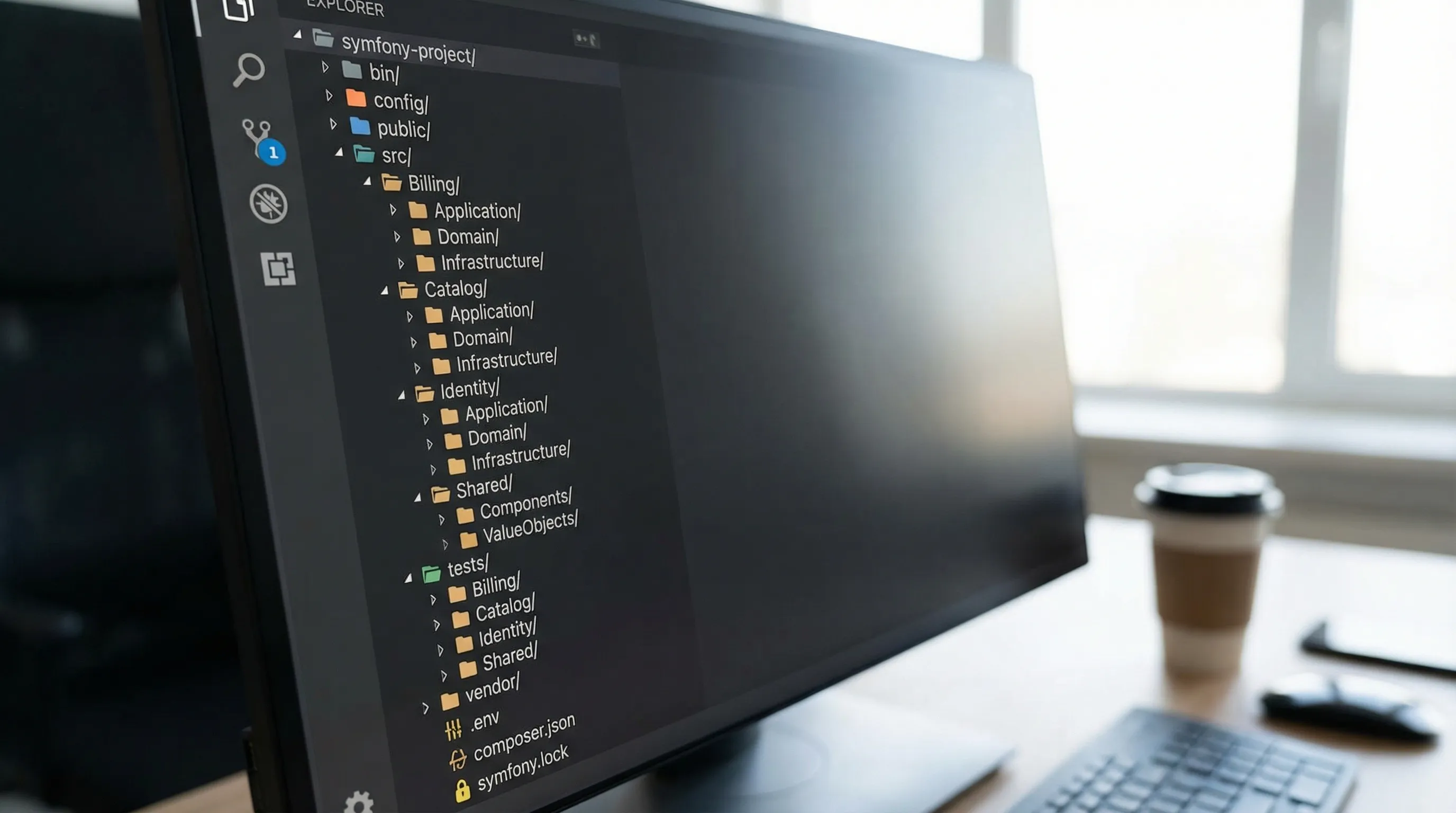
Code nach Geschäftsfähigkeit organisieren (nicht nur nach Framework-Schicht)
Ein häufiger Symfony-Geruch ist ein src/Service-Verzeichnis, das zur Abstellkammer wird.
Stattdessen Feature- oder Domain-Module bevorzugen:
src/Catalog/...src/Billing/...src/Identity/...
Innerhalb jedes Moduls eine klare Trennung beibehalten zwischen:
- Anwendungsschicht (Use Cases, Commands, Orchestrierung)
- Domänenschicht (Geschäftsregeln und -modelle)
- Infrastrukturschicht (Doctrine-Repositories, HTTP-Clients, externe Adapter)
Das erleichtert auch Performance-Arbeit, da Hotspots meist an Fähigkeiten gebunden sind (Suche, Preisgestaltung, Berechtigungen) – nicht an technische Schichten.
Controller schlank und deterministisch halten
Controller sollten hauptsächlich:
- Den Request validieren (oder Validierung delegieren)
- Einen einzigen Use Case / Application Service aufrufen
- Eine Response zurückgeben
Enthält ein Controller verzweigte Geschäftslogik, wird er schwer zu testen, schwer zu optimieren und schwer in CLI-/asynchronen Kontexten wiederverwendbar sein.
Abhängigkeitsrichtung streng einhalten
In wartbaren Systemen gilt:
- Anwendungs- und Domänenlogik hängen nicht von Doctrine-Details ab.
- Infrastruktur hängt von Anwendung/Domäne ab – nicht umgekehrt.
In Symfony-Begriffen bedeutet das oft:
- Interfaces in Services injizieren.
- Doctrine-Entities davon fernhalten, „Alles-Könner"-Objekte zu werden, die überall eingesetzt werden.
Konfiguration als API behandeln
Symfony macht es einfach, Konfiguration hinzuzufügen. Es macht es ebenso leicht, einen Konfigurationsdschungel zu schaffen.
Gute Standardvorgaben:
- Explizites Service-Wiring für wichtige Services und Grenzen verwenden.
- Umgebungsvariablen dokumentiert und minimal halten.
- „Magic Parameters", die überall weitergereicht werden, vermeiden.
Ein Wartbarkeitstrick: Ist ein Wert geschäftsrelevant (z. B. Preisregeln), sollte man erwägen, ihn als Daten zu speichern (admin-verwaltete Konfiguration), anstatt ihn in Umgebungsvariablen zu verstecken.
In automatisierte Qualitätsgates investieren (der Zinseszinseffekt)
Wartbarkeit entsteht nicht durch einmalige Refaktorierungen. Sie entsteht durch das kontinuierliche Ablehnen minderwertiger Änderungen.
Empfohlene Baseline-Gates:
- Unit- und Integrationstests (bei jedem PR ausgeführt)
- Statische Analyse (PHPStan oder Psalm)
- Coding Standards (PHP-CS-Fixer)
- Abhängigkeitsprüfungen (
composer audit)
Wolf-Techs Artikel zu Code-Quality-Metriken, die zählen ist ein guter Begleiter, wenn man eine kleine Menge an Metriken sucht, die mit Liefergeschwindigkeit und Fehlerquoten korrelieren.
Tests nutzen, um „sichere Nahtstellen" für Refaktorierungen zu schaffen
Für Symfony sehen pragmatische Test-Schichten oft so aus:
- Unit-Tests für reine Geschäftsregeln (schnell, günstig)
- Integrationstests für Repositories, Message-Handler und Schlüssel-Services
- Funktionale Tests (Kernel) für kritische Endpoints
Das Ziel ist nicht „alles gleich testen". Das Ziel ist, Verhalten rund um Hotspots und riskante Bereiche zu fixieren, damit man Interna sicher ändern kann.
Bei der Modernisierung einer älteren Symfony-Codebasis lässt sich der inkrementelle Ansatz aus Legacy-Code zähmen gut übertragen: Observability hinzufügen, Nahtstellen schaffen, Verhalten mit Tests sichern, dann refaktorieren.
Symfony-Upgrades von Tag eins einplanen
Symfony ist upgrade-freundlich – wenn man mit dem Ökosystem kooperiert.
Upgrade-Hygiene, die langfristige Kosten senkt:
- Unterstützte Symfony-Versionen bevorzugen (oft die neueste stabile oder LTS-Version je nach Risikobereitschaft).
- Deprecations als Arbeitsaufgaben behandeln, nicht als Rauschen.
- Tiefe Overrides von Framework-Interna vermeiden, es sei denn, man braucht sie wirklich.
Referenz: Symfony-Releases.
Eine kombinierte Checkliste (Performance + Wartbarkeit)
Diese Tabelle als schnelles Review-Werkzeug in Architektur- oder Tech-Lead-Reviews verwenden.
| Bereich | Best Practice | Warum es hilft | Was zu verifizieren ist (Nachweis) |
|---|---|---|---|
| Laufzeit | Prod-Modus (APP_ENV=prod, APP_DEBUG=0) | Vermeidet Debug-Overhead und Dev-only-Verhalten | Env-Vars, Logs zeigen Prod, Profiler nicht aktiv |
| Deployment | Cache-Warmup zum Deployment-Zeitpunkt | Beseitigt Penalty beim ersten Request | Deployment-Logs, warme Cache-Verzeichnisse |
| PHP | OPcache aktiviert und dimensioniert | Großer Durchsatz- und Latenzgewinn | opcache_get_status(), Laufzeitmetriken |
| HTTP | Cache-Control + bedingte Requests | Reduziert Arbeit und Kosten | Response-Header, CDN/Proxy-Trefferquote |
| App-Caching | Cache-Pools mit TTL + Trefferquoten-Tracking | Vorhersagbare Gewinne, sicherere Invalidierung | Cache-Metriken, Schlüssel mit geringer Fluktuation |
| Datenbank | N+1-Prävention, maßgeschneiderte Abfragen | Verhindert amplifizierten DB-Zeitaufwand | Abfrageanzahlen, Slow-Query-Logs |
| Async | Messenger für langsame Nebeneffekte | Schnellere Responses, bessere Resilienz | Queue-Metriken, Retries, DLQ-Verhalten |
| Architektur | Code nach Fähigkeit und Grenzen organisiert | Einfachere Ownership und Refaktorierungen | Modulstruktur, Abhängigkeitsgraph |
| Qualität | CI-Qualitätsgates (Tests, statische Analyse) | Verhindert Schuldenanwachsen | Pipeline-Output, konsistente Schwellenwerte |
Ein pragmatischer 30-Tage-Verbesserungsplan für Symfony-Teams
Für schnelle Verbesserungen ohne großes Aufheben:
Woche 1: Baseline und Sichtbarkeit
- 3 bis 5 kritische Routen auswählen und Budgets definieren.
- Produktions-Dashboards für Latenz, Fehlerrate und DB-Zeit hinzufügen.
- Prod-Modus-Einstellungen und OPcache bestätigen.
Woche 2: Die 2 wichtigsten Hotspots beheben
- Offensichtliche N+1-Abfragen beseitigen.
- Caching für Daten mit hoher Leserate und geringer Änderungsrate hinzufügen.
- Einen langsamen Nebeneffekt in asynchrone Verarbeitung auslagern.
Woche 3: Änderungsrisiko reduzieren
- Tests rund um die Hotspot-Bereiche hinzufügen.
- Statische Analyse und Coding Standards in CI einführen.
Woche 4: Verbesserungen festigen
- Regressionsprüfungen hinzufügen (Query-Count-Budgets oder Performance-Smoke-Tests).
- Modul-Grenzen und „wie wir hier Features bauen" dokumentieren.
Dieser Ansatz spiegelt wider, wie Wolf-Tech üblicherweise Engineering-Fortschritt empfiehlt: messbare Ergebnisse, kleine Batches und Sicherheitsmechanismen.
Häufig gestellte Fragen
Ist Symfony im Vergleich zu anderen Frameworks „langsam"? Symfony kann in der Produktion sehr schnell sein, wenn Debug deaktiviert ist, OPcache konfiguriert wurde und häufige Engpässe vermieden werden (N+1-Abfragen, kein Caching, schwere Arbeit in Requests). Viele Performance-Probleme sind architektonischer oder datenzugriffsbezogener Natur, nicht Framework-bedingt.
Was ist der größte Symfony-Performance-Gewinn in realen Projekten? Verschwendete Arbeit auf Hot Paths eliminieren: N+1-Abfragen beheben, angemessenes Caching hinzufügen (HTTP- und Anwendungs-Caching) und langsame Nebeneffekte in asynchrone Verarbeitung auslagern. Außerdem OPcache und Produktionsmodus-Einstellungen verifizieren.
Wie sollte ich eine Symfony-Codebasis für Wartbarkeit strukturieren? Code nach Geschäftsfähigkeit (Module) organisieren und klare Grenzen zwischen Anwendungs-/Use-Cases, Domänenlogik und Infrastruktur beibehalten. Controller schlank halten und Qualitätsgates in CI durchsetzen, damit Schulden nicht still anwachsen.
Sollte man eine Legacy-Symfony-App refaktorieren oder neu schreiben? Die meisten Teams erzielen bessere risikoadjustierte Ergebnisse mit inkrementeller Modernisierung: Observability hinzufügen, Tests um kritische Pfade einführen, hinter Nahtstellen refaktorieren und Verbesserungen in kleinen Batches ausliefern. Neuentwicklungen sind nur dann angemessen, wenn das bestehende System auch nach gezielter Modernisierung keine Anforderungen erfüllen kann.
Welche Prüfungen gehören in CI für Symfony-Projekte? Mindestens: Tests, statische Analyse (PHPStan/Psalm), Coding Standards und Abhängigkeits-Sicherheitsprüfungen (composer audit). Performance-Regressionsprüfungen für kritische Endpoints hinzufügen, wenn das System wächst.
Benötigen Sie Hilfe bei der Verbesserung der Symfony-Performance ohne Umbau der gesamten Codebasis?
Wolf-Tech hilft Teams dabei, Symfony- und PHP-Systeme mit Fokus auf messbare Ergebnisse zu bauen, zu optimieren und zu skalieren: schnellere Endpoints, sicherere Releases und Codebasen, die mit Team und Produkt wartbar bleiben.
Wenn Sie eine Expertenüberprüfung Ihrer Symfony-Architektur, Performance-Hotspots oder Ihres Modernisierungsplans wünschen, erfahren Sie mehr über Wolf-Techs Arbeit in den Bereichen Full-Stack-Entwicklung, Code-Quality-Consulting und Legacy-Code-Optimierung auf wolf-tech.io.