
React-Muster in der Praxis: State, Effects und Datenabruf


React ist täuschend einfach: eine Funktion, die UI zurückgibt. In echten Produkten schleicht sich die Komplexität durch drei Türen ein: State, Effects und Datenabruf. Wenn diese Belange verschwimmen, entstehen Komponenten, die schwer sicher zu ändern, schwer zu testen und voller „Warum rendert das nochmal?"-Rätsel sind.
Dieser Leitfaden bietet praktische React-Muster, die als Defaults in 2026er Codebases (React 18+) übernommen werden können, egal ob man eine SPA, eine Next.js-App oder etwas dazwischen ausliefert. Das Ziel ist kein Novelty-Faktor, sondern vorhersagbares Verhalten.
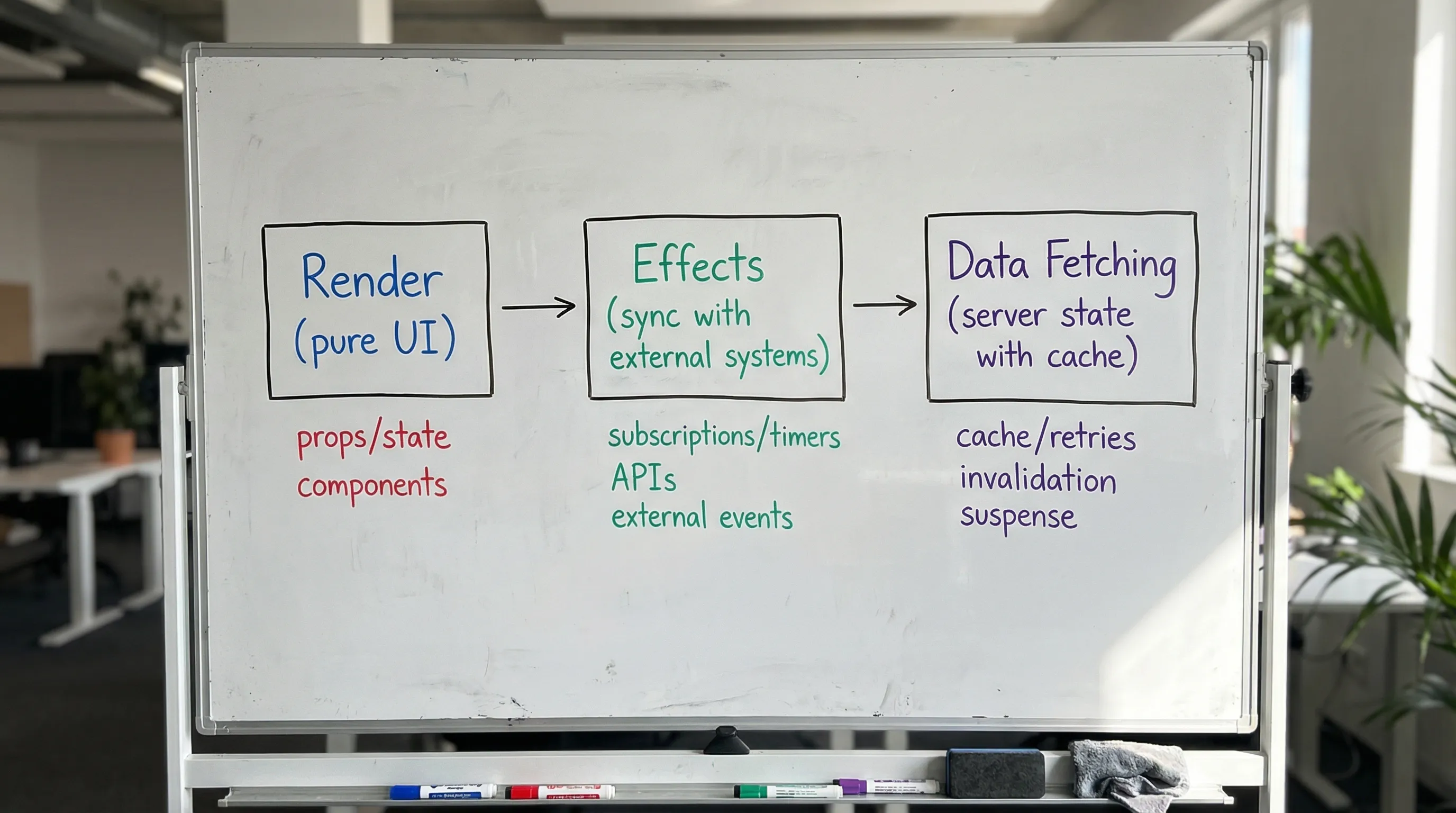
Ein mentales Modell, das skaliert: rendern, dann synchronisieren
Eine nützliche Baseline ist:
- Render sollte eine pure Berechnung von Inputs (Props, State) zu UI sein.
- Effects sollten mit Dingen synchronisieren, die React nicht kontrolliert (Timer, Subscriptions, DOM-APIs, Netzwerk-Seiteneffekte).
- Datenabruf ist nicht „nur ein Effect", er ist Server-State mit Caching, Deduplizierung, Invalidierung, Retries und Konsistenzbelangen.
Reacts eigene Docs beschreiben useEffect als eine API zur Synchronisation mit externen Systemen, nicht als einen allgemeinen „mach etwas nach dem Render"-Notausgang. Es lohnt sich, den Code an dieser Intention auszurichten, weil das unbeabsichtigte Komplexität und Strict-Mode-Überraschungen reduziert.
State-Muster: minimal, lokal und explizit halten
Die meisten React-Codebases scheitern nicht, weil sie State haben, sondern weil sie die falschen Dinge als State speichern oder dasselbe zweimal speichern.
Muster 1: Abgeleitete Werte gegenüber dupliziertem State bevorzugen
Wenn ein Wert aus anderem State oder Props berechnet werden kann, berechne ihn beim Render.
Schlechter Geruch: useEffect aktualisiert State, der von anderem State abgeleitet ist.
const [items, setItems] = useState<Item[]>([])
// Abgeleiteter Wert: nicht separat speichern
const total = items.reduce((sum, i) => sum + i.price, 0)
Wenn die Berechnung aufwändig ist, den abgeleiteten Wert memoizen, nicht die Quelle der Wahrheit.
const total = useMemo(() => items.reduce((sum, i) => sum + i.price, 0), [items])
Muster 2: State so nah wie möglich an seinem Verwendungsort platzieren
Das ist die günstigste Skalierungsstrategie: lokaler State hat weniger unbeabsichtigte Konsumenten.
Ein guter Default:
- Mit komponentenlokalem
useStatebeginnen. - State nur heben, wenn ein konkreter Teilungsbedarf besteht.
- Beim Heben ein enges Interface (Werte + Callbacks) verwenden, anstatt Setter überall weiterzureichen.
Muster 3: useReducer für mehrstufige oder regelintensive UI verwenden
Wenn UI-Übergänge Regeln haben, macht useReducer die Übergänge explizit und testbar.
type State =
| { step: 'idle' }
| { step: 'editing'; name: string }
| { step: 'submitting'; name: string }
| { step: 'done' }
type Action =
| { type: 'START' }
| { type: 'CHANGE_NAME'; name: string }
| { type: 'SUBMIT' }
| { type: 'SUCCESS' }
| { type: 'RESET' }
function reducer(state: State, action: Action): State {
switch (action.type) {
case 'START':
return { step: 'editing', name: '' }
case 'CHANGE_NAME':
return state.step === 'editing' ? { ...state, name: action.name } : state
case 'SUBMIT':
return state.step === 'editing' ? { step: 'submitting', name: state.name } : state
case 'SUCCESS':
return { step: 'done' }
case 'RESET':
return { step: 'idle' }
default:
return state
}
}
Dieses Muster zahlt sich aus, wenn Validierung, Berechtigungen, asynchrone Übermittlung oder Abbruch hinzukommen.
Muster 4: Controlled vs. Uncontrolled – bewusst wählen
Für wiederverwendbare Komponenten (Inputs, Dropdowns, komplexe Widgets) explizit entscheiden, ob eine Komponente:
- Controlled (Elternteil besitzt den Wert, Komponente löst Events aus)
- Uncontrolled (Komponente besitzt den Wert intern)
Eine praktische Regel:
- Controlled verwenden, wenn der Wert an seitenweiter Logik teilnehmen muss (URL-Sync, feldübergreifende Validierung, „Änderungen speichern"-Flows).
- Uncontrolled verwenden, wenn die einfachste Integration gewünscht wird und keine Orchestrierung benötigt wird.
Wolf-Techs Artikel zu Komponentenmustern geht tiefer auf diese Verträge ein: Front End React Patterns for Large, Shared Components.
Muster 5: Context ist für Dependency Injection, nicht für einen globalen Store
React Context ist gut für stabile, app-weite Abhängigkeiten (Theme, i18n, Feature-Flags, aktueller Mandant). Es wird teuer, wenn es als häufig ändernder globaler Store verwendet wird, weil es breite Re-Renders auslösen kann.
Defaults, die standhalten:
- Context-Werte stabil halten (Objekte memoizen).
- Mehrere enge Contexts gegenüber einem „AppContext" bevorzugen.
- Für Server-State eine dedizierte Bibliothek bevorzugen (siehe Datenabruf-Muster unten).
Für eine breitere Architektursicht (Server vs. UI vs. URL vs. Formular) siehe: React Application Architecture: State, Data, and Routing.
Effect-Muster: Seiteneffekte absichtlich gestalten
Wenn State-Muster über „was speichern wir?" sind, sind Effect-Muster über „womit synchronisieren wir?"
Muster 1: Effects nicht für Dinge verwenden, die in Events passieren können
Wenn auf eine Benutzeraktion reagiert wird (Klick, Submit, Änderung), ist meistens ein Event-Handler gewünscht, kein Effect.
function SaveButton() {
const onClick = async () => {
await save()
toast.success('Gespeichert')
}
return <button onClick={onClick}>Speichern</button>
}
Ein Effect dafür zu verwenden führt oft zu extra State ("shouldSave"), Dependency-Bugs und doppelten Ausführungen in der Entwicklung.
Muster 2: Bei Verwendung von useEffect als Lifecycle mit Cleanup behandeln
Effects brauchen Cleanup, wenn sie etwas aufbauen, das abgebaut werden muss.
useEffect(() => {
const id = window.setInterval(() => {
setNow(new Date())
}, 1000)
return () => window.clearInterval(id)
}, [])
Das wird kritisch bei:
- WebSocket-Subscriptions
- DOM-Event-Listenern
AbortControllerfür fetch- Externen SDKs (Maps, Analytics)
Reacts Strict-Mode in der Entwicklung führt bestimmte Lifecycles absichtlich nochmals aus, um unsichere Effects aufzudecken. Wenn ein Effect „manchmal doppelt ausführt", ist das oft ein Zeichen, dass Cleanup fehlt oder er nicht idempotent ist.
Muster 3: Effects nach Verantwortung aufteilen
Ein Effect sollte meistens einen einzigen Grund zum Existieren haben. Das vermeidet verschachtelte Dependency-Arrays und „Fix durch ESLint-Deaktivierung"-Ergebnisse.
Anstatt eines Effects, der subscribed, fetcht und loggt, diese aufteilen.
Muster 4: Refs für veränderliche Werte verwenden, die keine Re-Renders auslösen sollen
Ein häufiges Anti-Pattern ist das Speichern von „letztem Wert" in State, was Re-Renders erzwingt und Schleifen verursachen kann.
useRef ist oft besser geeignet für veränderliche, nicht-UI-Werte wie:
- Timer
- Letzte Request-ID
- Imperativ kontrollierte Instanzen
Für eine kuratierte Liste von React Anti-Patterns (einschließlich Effect-Missbrauch) ist dieser Wolf-Tech-Post ein guter Begleiter: JavaScript React Anti-Patterns That Slow Teams Down.
Datenabruf-Muster: Server-State als erstklassiges System behandeln
Wenn man nur eine Sache aus diesem Artikel mitnimmt: Datenabruf ist kein Seiteneffekt-Detail, er ist ein Produktverhalten.
Es müssen Fragen beantwortet werden wie:
- Wann gelten Daten als frisch oder veraltet?
- Was passiert bei langsamen Netzwerken?
- Was passiert, wenn der Nutzer während eines Requests navigiert?
- Wie werden identische Requests dedupliziert?
- Wie werden Retries, Backoff und Fehlerzustände behandelt?
- Wie werden gecachte Daten nach Mutationen aktualisiert?
Zwei funktionsfähige Defaults (einen wählen und standardisieren)
Default A: Eine Server-State-Bibliothek verwenden (empfohlen für die meisten SPAs)
Bibliotheken wie TanStack Query (React Query) existieren, weil Server-State schwierige Probleme hat, die man nicht pro Komponente neu erfinden möchte.
Ein einfaches Muster ist „API-Modul + Query-Hook + UI".
// api/projects.ts
export async function listProjects(signal?: AbortSignal) {
const res = await fetch('/api/projects', { signal })
if (!res.ok) throw new Error('Projekte konnten nicht geladen werden')
return (await res.json()) as Project[]
}
// hooks/useProjects.ts
export function useProjects() {
return useQuery({
queryKey: ['projects'],
queryFn: ({ signal }) => listProjects(signal),
staleTime: 30_000,
})
}
Das liefert Caching, Abbruch, Request-Deduplizierung und ein gemeinsames Vokabular in der App.
Default B: Framework-Loader/Server-Components verwenden, wenn verfügbar
Wenn ein Framework Route-Loader oder server-first Rendering unterstützt (beispielsweise server-gerenderte Routen mit Caching), Daten an der Routen-Grenze abrufen und nach unten weitergeben. Das hält die meisten Komponenten pur und reduziert Client-Komplexität.
Wolf-Tech behandelt Server- vs. Client-Grenzen ausführlich hier: React Next JS: When to Use Server Components.
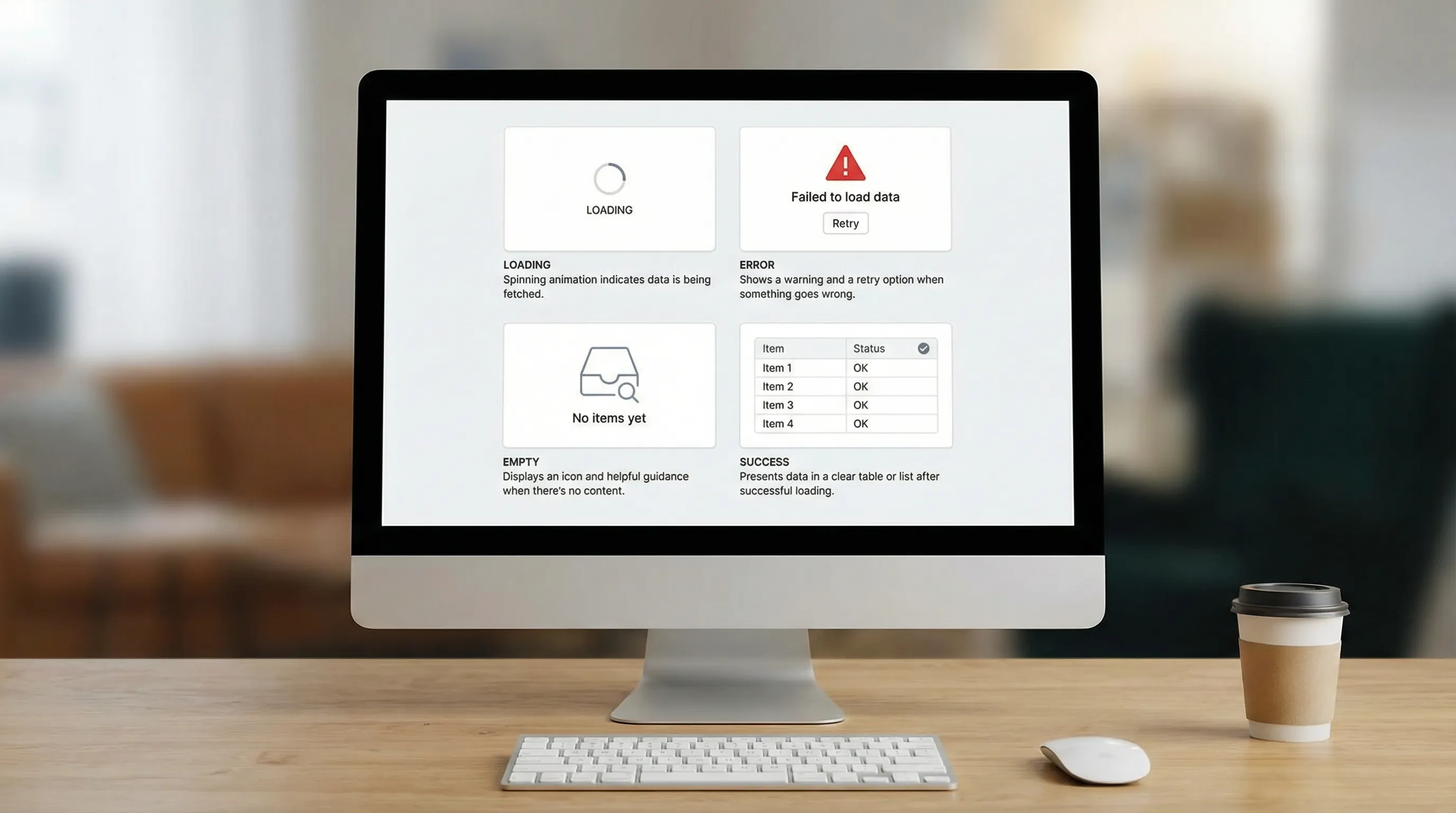
Muster 1: Den Request-Lifecycle in der UI standardisieren
Jeder datengetriebene Screen sollte absichtlich vier Zustände behandeln:
- Laden
- Fehler
- Leer (Erfolg, aber keine Daten)
- Erfolg
Wenn Teams das nicht standardisieren, erleben Nutzer zufällige Spinner, stille Fehler und inkonsistente Leerzustände.
Muster 2: Abbruch immer behandeln (und Race Conditions)
Auch ohne Server-State-Bibliothek sollten laufende Requests beim Unmount oder bei Parameteränderungen abgebrochen werden.
useEffect(() => {
const controller = new AbortController()
;(async () => {
try {
const res = await fetch(`/api/users?query=${encodeURIComponent(q)}`, {
signal: controller.signal,
})
const data = await res.json()
setUsers(data)
} catch (e) {
if ((e as any).name === 'AbortError') return
setError(e)
}
})()
return () => controller.abort()
}, [q])
Das verhindert „setState auf nicht montierter Komponente"-Warnungen und subtile Race-Bugs, bei denen eine langsamere Antwort eine neuere überschreibt.
Muster 3: Entscheiden, wo Datenabruf stattfindet (und es durchsetzen)
Ein häufiger Skalierungsfehler ist „Datenabruf überall". Eine Regel festlegen, zum Beispiel:
- An Routen/Screen-Grenzen abrufen.
- Blatt-Komponenten erhalten Daten via Props und bleiben pur.
- Ausnahmen erfordern Begründung (z.B. ein eigenständiges Autocomplete-Widget).
Das macht Refactors günstiger, weil Datenanforderungen an einer Stelle geändert werden können.
Muster 4: Mutationen brauchen eine explizite Cache-Aktualisierungsstrategie
Für Create/Update/Delete-Operationen eines dieser Muster pro Mutation wählen:
- Invalidieren relevanter Queries und neu abrufen (einfach, oft gut genug)
- Optimistisch aktualisieren des Caches (beste UX, höhere Komplexität)
- Per Response aktualisieren (gecachtes Objekt durch zurückgegebenen kanonischen Wert ersetzen)
In allen Fällen mit dem Backend über Idempotenz und Validierungsfehler abstimmen. Viele „Frontend-State-Probleme" sind eigentlich inkonsistente Backend-Verträge.
Muster 5: Datenverträge explizit machen
Mindestens eine typisierte Grenze aufrechterhalten:
- Antworten validieren (Laufzeit-Validierung für kritische Flows)
- Fehlerformen normalisieren
- Rohe
fetch-Aufrufe nicht durch UI-Code weiterreichen
Für ein End-to-End-Beispiel eines produktionsreifen Slices (Verträge, Hooks, Fehler, Telemetrie) ist dieses Tutorial eine starke Referenzimplementierung: React Tutorial: Build a Production-Ready Feature Slice.
Eine Entscheidungstabelle für Code-Reviews
Diese Tabelle in PR-Reviews nutzen, um zu konsistenten Mustern zu lenken.
| Problem, das gelöst wird | Dieses Muster bevorzugen | Warum es besser skaliert |
|---|---|---|
| UI-Wert wird aus bestehendem Props/State berechnet | Abgeleiteter Wert im Render (optional useMemo) | Vermeidet duplizierten State und Sync-Bugs |
| Mehrstufige UI mit Regeln und Übergängen | useReducer (oder eine State-Machine-Bibliothek) | Macht Übergänge explizit und testbar |
| State in einem kleinen Teilbaum teilen | State zum nächsten gemeinsamen Elternteil heben | Hält Abhängigkeiten lokal |
| Stabile app-weite Abhängigkeiten teilen | Context (eng, memoized) | Vermeidet Prop-Drilling ohne globale Re-Renders |
| Abrufen, Caching, Invalidierung, Retries | Server-State-Bibliothek oder Framework-Loader | Verhindert Per-Komponenten-Neuerfindungen |
| Subscriptions, Timer, imperative APIs | useEffect mit Cleanup | Verhindert Lecks und Strict-Mode-Probleme |
Ein leichtgewichtiger „Team-Standard", der 80% des Chaos verhindert
Wenn ein Team ausgerichtet werden soll, den Standard klein und durchsetzbar halten:
- Verbieten von
useEffectzum „State mit anderem State in Sync halten" (stattdessen ableiten). - Verlangen eines einzigen Orts pro Screen/Route, wo Daten abgerufen werden.
- Verlangen von Lade/Fehler/Leer/Erfolg-UI-Zuständen.
- Verlangen von Abbruch für laufende Requests (oder eine Bibliothek verwenden, die das bereitstellt).
- Bevorzugen von
useReducer, wenn eine Komponente 3+ Boolean-Flags oder „Mode"-Variablen hat.
Für eine vollständigere Standards-Vorlage (Tooling, Tests, Performance-Budgets) ist Wolf-Techs Playbook eine gute Baseline: React Development Playbook: Standards for Teams.
Wann externe Hilfe sinnvoll ist
Wenn sich die React-Codebase schwer ändern lässt, ist der schnellste Weg oft kein Rewrite. Es ist ein Architektur-Pass, der:
- State und Datenflüsse klassifiziert,
- Routen-Grenzen und Fetch-Strategie definiert,
- durchsetzbare Muster einführt (Lint-Regeln, Modul-Grenzen, gemeinsame Utilities),
- und die schlimmsten Hotspots inkrementell entfernt.
Wolf-Tech ist spezialisiert auf Full-Stack-Entwicklung und Legacy-Optimierung. Wenn eine pragmatische Überprüfung des aktuellen State/Effects/Datenabruf-Ansatzes gewünscht wird (und ein inkrementeller Fixplan), kann man über wolf-tech.io Kontakt aufnehmen.