
Agile Entwicklung, die liefert: Rituale, Metriken und Anti-Muster


Die meisten Teams scheitern bei der agilen Entwicklung nicht, weil sie Zeremonien auslassen. Sie scheitern, weil ihr agiles System Ideen nicht zuverlässig in sichere Produktionsänderungen umwandelt.
Wer „agile Entwicklung, die liefert" anstrebt, sollte Lieferung als Fähigkeit mit drei Komponenten betrachten:
- Rituale, die Klarheit, Zerschneidung und schnelles Feedback erzwingen.
- Metriken, die Flow und Produktionsergebnisse messen (keine Aktivitätsmetriken).
- Anti-Muster-Erkennung, die verhindert, dass Agile still zu Mini-Wasserfall wird.
Nachfolgend ein pragmatisches Playbook, das zunächst mit einem einzelnen Team eingeführt und dann skaliert werden kann.
Was „Liefern" wirklich bedeutet (und warum die meisten Teams es verfehlen)
Ein überraschend großer Teil von Lieferdysfunktionen entsteht durch eine unscharfe Definition von „fertig". In liefernden Teams bedeutet „fertig" nicht „gemerged" und nicht „QA-freigegeben". Es bedeutet in Produktion nutzbar (oder sicher releasebar), beobachtbar und umkehrbar.
Ein praktischer Weg, um Stakeholder zu alignen, ist die explizite Definition von Fertig-Stufen.
| Stufe | Was Leute sagen | Was es wirklich bedeutet | Risiko, das man trägt |
|---|---|---|---|
| Fertig-0 | „Es ist kodiert" | Lokaler Build läuft durch | Unbekanntes Integrationsrisiko |
| Fertig-1 | „Es ist in einem PR" | Review gestartet | Queue-Zeit und Kontext-Churn |
| Fertig-2 | „Gemerged" | Main Branch grün | Release-Risiko akkumuliert sich |
| Fertig-3 | „Deployed" | Läuft in Prod hinter einem Flag | Gering, wenn Monitoring vorhanden |
| Fertig-4 | „Shipped" | Nutzer ausgesetzt mit Telemetrie | Man kann lernen und iterieren |
Wenn eine Organisation Fertig-2 feiert, fühlt man sich beschäftigt und liefert trotzdem langsam.
Eine starke Definition of Done umfasst in der Regel:
- Automatisierte Prüfungen (Tests, Linting, Sicherheits-Baseline)
- Deployment-Pfad bewiesen (auch wenn durch Approvals gegatest)
- Observability für die Änderung vorhanden (Logs/Metriken/Traces oder zumindest gezieltes Monitoring)
- Rollback-Plan (oder sichere Rollout-Strategie)
Dies entspricht der Kernidee des Agile Manifesto (funktionierende Software) und der operativen Disziplin, die durch SRE und moderne Delivery-Forschung populär wurde.
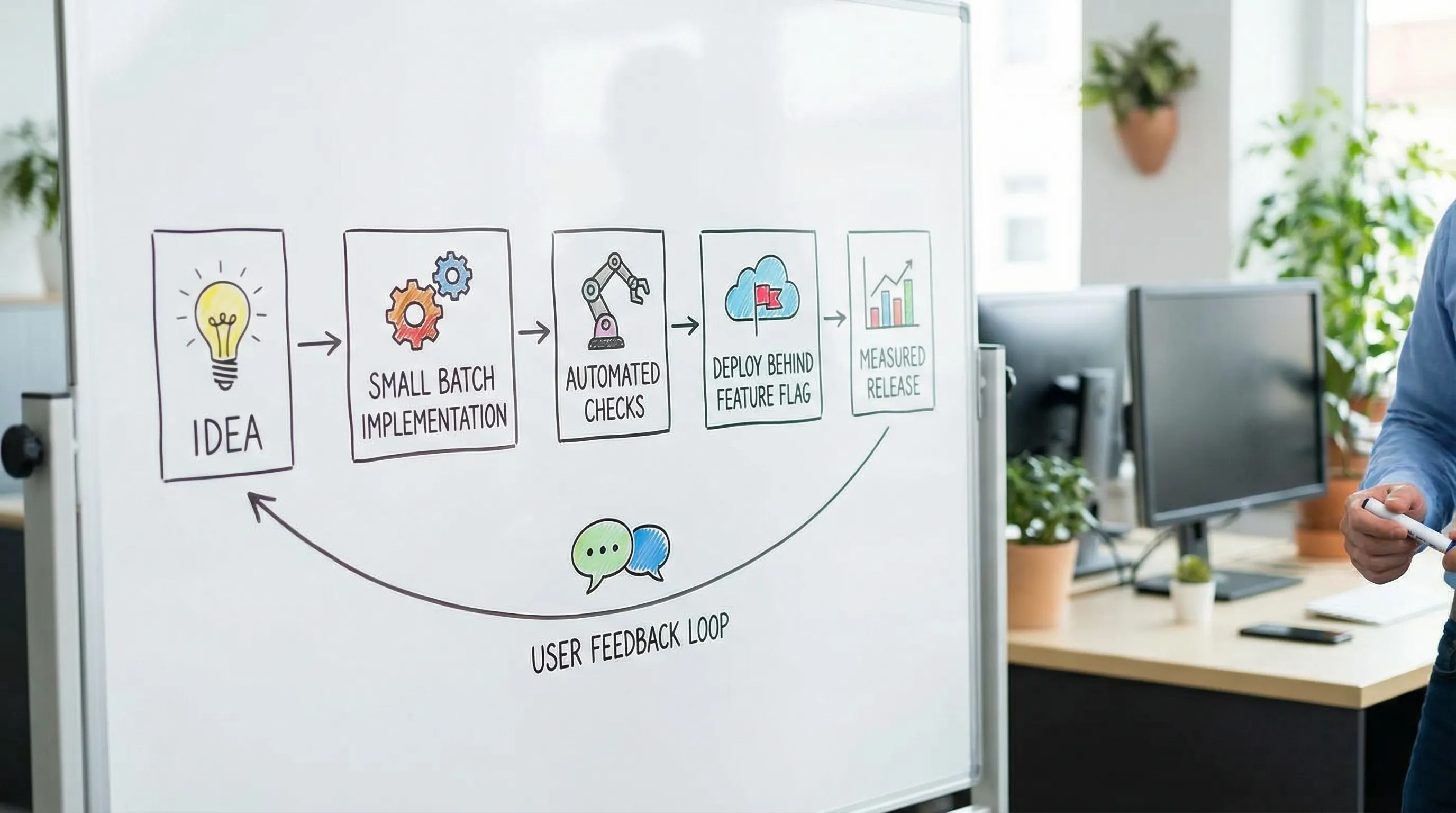
Rituale, die Liefermomentum erzeugen (ohne Bürokratie)
Rituale sind keine Meetings. Sie sind wiederkehrende Einschränkungen, die verhindern, dass Arbeit zu groß, zu vage oder zu riskant wird.
Die besten Rituale teilen ein Merkmal: Sie produzieren ein Artefakt oder eine Entscheidung, die das Liefern erleichtert.
1) Wöchentliches Outcome-Review (30 Minuten)
Zweck: Product, Engineering und Stakeholder auf Outcomes und Trade-offs aligned halten.
Agenda:
- Was haben wir geliefert, das ein messbares Outcome bewegt hat?
- Was haben wir gelernt (aus Produktionsdaten oder Nutzern)?
- Was ist das nächste größte Risiko (Umfang, Performance, Zuverlässigkeit, Sicherheit, Integration)?
- Welche Entscheidung wird diese Woche benötigt (und wer besitzt sie)?
Das verhindert das häufige Abdriften, bei dem Agile zu „Sprint-Ausführung" wird, losgelöst von Geschäftsauswirkungen.
2) Backlog Refinement als „Slicing + Risikoabbau"
Wenn Refinement nur das Umschreiben von Tickets ist, wird es zum Theater.
Signalstarkes Refinement erzeugt:
- Einen dünnen vertikalen Slice, der schnell die Produktion erreichen kann
- Benannte Risiken mit einem Testplan (Integration, Performance-Budget, Datenmigration, Berechtigungen)
- Klare Akzeptanzkriterien, die reale Zustände abbilden (Fehler, leere Daten, Latenz, Rollen)
Eine nützliche Regel: Wenn eine Story nicht unabhängig deployed werden kann (auch nicht hinter einem Feature Flag), ist sie wahrscheinlich zu groß oder zu stark gekoppelt.
3) Planning, das Lernen verpflichtet, keine Schätzungen
Planning sollte einen Delivery-Plan für die nächste Iteration erstellen und Unsicherheit frühzeitig aufzeigen.
Was in der Praxis gut funktioniert:
- Rund um die kleinsten lieferbaren Inkremente planen.
- „Discovery-Arbeit" explizit benennen (Spikes, Prototypen, dünner vertikaler Slice), anstatt sie in Schätzungen zu verstecken.
- Den Plan anpassbar halten, aber nicht vage.
Wenn Schätzungen benötigt werden, sollten sie als Risikoignale verwendet werden, nicht als Performance-Ziele.
4) Daily Sync, der den Flow schützt
Ein Daily Standup sollte eine Kontrollschleife für den Flow sein, kein Statusbericht.
Drei Fragen verwenden, die auf Lieferung abbilden:
- Was ist das älteste laufende Arbeitselement?
- Was hindert es daran, die Produktion zu erreichen?
- Welche Koordination ist heute erforderlich, um die Batch-Größe klein zu halten?
Diese einfache Umstellung reduziert WIP-Schleicherei, langlebige Branches und späte Überraschungen.
5) Demo, die „potenziell lieferbar" beweist
Eine Demo ist nur dann wertvoll, wenn sie die Realität beweist.
Hochwertige Demo-Defaults:
- Demo aus einer produktionsähnlichen Umgebung (oder Produktion hinter einem Flag)
- Fehlerzustände und Berechtigungen zeigen, nicht nur Happy Paths
- Einen operativen Nachweis einbeziehen, wenn relevant (Latenz, Logs, Alert, Dashboard)
Das zwingt Engineering und Product dazu, sich auf die Bedeutung von „funktioniert" zu einigen.
6) Retro, das mit einem messbaren Experiment endet
Retros scheitern, wenn sie Erkenntnisse, aber keine Änderungen produzieren.
Ein praktischer Retro-Output:
- Ein Verbesserungsexperiment
- Ein Eigentümer
- Ein erwarteter messbarer Effekt innerhalb von 1 bis 2 Wochen
Beispiel: „PR-Durchlaufzeit reduzieren, indem PR-Größe auf X Dateien oder Y Zeilen (Soft Limit) begrenzt wird und Pairing für riskante Refactorings eingeführt wird."
7) Das fehlende Ritual: Change Review (15 Minuten, zweimal pro Woche)
Viele Teams haben Sprint-Rituale, aber kein Release-Ritual.
Ein leichtgewichtiges Change Review:
- Was ist jetzt bereit zum Deployment?
- Was ist durch Rollout oder Approvals blockiert?
- Was ist der Rollout-Plan (Flag, Canary, Phasen-Release)?
- Welches Monitoring-Signal werden wir beobachten?
Hier verwandelt sich Agile in Lieferung.
Empfohlene Kadenz (Beispiel)
| Kadenz | Ritual | Output |
|---|---|---|
| Wöchentlich | Outcome Review | Entscheidungsprotokoll, nächste Risiken |
| Wöchentlich | Refinement | Dünne Slices bereit |
| Zweiwöchentlich (oder wöchentlich) | Planning | Lieferbarer Plan |
| Täglich | Flow Sync | Blockaden entfernt, WIP kontrolliert |
| 1 bis 2x/Woche | Change Review | Releases passieren |
| Zweiwöchentlich | Retro | Ein messbares Experiment |
Metriken, die Lieferung vorhersagen (und welche lügen)
Metriken sind nicht zum Berichten da. Sie sind zum Steuern da.
Eine gute Liefermetrik ist:
- Nah an der Produktionsrealität
- Schwer zu manipulieren
- Innerhalb von Tagen, nicht Quartalen umsetzbar
Der Kern: DORA-Metriken (als System verwenden)
Die am weitesten verbreiteten Lieferperformance-Metriken sind die vier DORA-Metriken, populär gemacht durch die Forschung hinter Accelerate und gepflegt durch das DevOps Research and Assessment Program (jetzt unter Google Cloud). Eine klare Übersicht findet sich in den Google Cloud DORA-Ressourcen.
| Metrik | Was sie zeigt | Was typischerweise kaputt ist, wenn sie schlecht ist |
|---|---|---|
| Deployment-Frequenz | Wie oft Wert die Nutzer erreicht | Releases sind schmerzhaft, zu manuell |
| Lead Time für Änderungen | Wie schnell Code von Commit zu Prod gelangt | Große Batches, langsame Reviews, spröde Pipeline |
| Change Failure Rate | Wie oft Änderungen Vorfälle/Rollback verursachen | Schwache Tests, riskante Releases, versteckte Kopplung |
| Zeit zur Wiederherstellung (MTTR) | Wie schnell man sich erholt | Schlechte Observability, unklare Eigentümerschaft, keine Runbooks |
Wichtig: Diese als ausgewogenes Set behandeln. Die Optimierung eines einzelnen Werts kann Schaden anrichten (z.B. höhere Deploy-Frequenz ohne Safety kann die Change Failure Rate ansteigen lassen).
Flow-Metriken hinzufügen, um den Engpass zu finden
DORA sagt, „wie man performt". Flow-Metriken helfen zu verstehen, „wo Zeit vergeht".
Diese pro Team verfolgen (wöchentlicher Trend, kein tägliches Rauschen):
- WIP (Work in Progress): Zu hoch bedeutet lange Durchlaufzeiten und versteckte Warteschlangen.
- PR-Durchlaufzeit: Zeit von PR-Eröffnung bis Merge, oft die größte kontrollierbare Verzögerung.
- Arbeitselement-Alter: Wie lange das älteste laufende Element bereits wartet.
Diese sind besonders effektiv in Kombination mit einer Regel: Arbeit abschließen, bevor neue begonnen wird.
Qualität und Zuverlässigkeit: messen, was Nutzer fühlen
Wenn man häufig liefert, aber Nutzer leiden, liefert man nicht wirklich.
Zwei praktische Ergänzungen:
- Defekt-Escape-Rate: Fehler, die nach dem Release gefunden werden, versus davor.
- Service-Zuverlässigkeit via SLIs/SLOs (Verfügbarkeit, Latenz, Fehlerrate), eine Disziplin, die im Site Reliability Engineering Buch von Google beschrieben wird.
Wer noch nicht bereit für formale SLOs ist, sollte mit einem „Golden Signal" pro kritischer Nutzer-Journey beginnen (Login, Checkout, Suche, Kern-Workflow).
Ein leichtgewichtiges „Shipping Scorecard", das wöchentlich überprüft werden kann
| Bereich | Metrik | Gesunde Frage |
|---|---|---|
| Flow | Lead Time für Änderungen | „Was verlangsamt Commit-zu-Prod?" |
| Flow | PR-Durchlaufzeit | „Wo warten wir, Review oder CI?" |
| Durchsatz | Deployment-Frequenz | „Können wir kleinere Inkremente releasen?" |
| Sicherheit | Change Failure Rate | „Welche Änderungstypen sind riskant und warum?" |
| Wiederherstellung | MTTR | „Erkennen wir Probleme schnell und wissen, was zu tun ist?" |
| Product | Eine Outcome-Metrik | „Hat das Liefern das Nutzerverhalten verändert?" |
Metriken, die häufig nach hinten losgehen
Diese vorsichtig verwenden oder gar nicht:
- Velocity / Story Points als Produktivität: Belohnt größere Schätzungen, nicht besseren Flow.
- Auslastung: Treibt mehr WIP, Warteschlangen und Burnout.
- Lines of Code: Belohnt Output, nicht Outcomes.
Für einen tieferen, code-zentrischen Messansatz sollte dieser mit Lieferoutcomes statt mit Vanity-Metriken verknüpft werden. (Wolf-Tech hat einen dedizierten Leitfaden zu Code-Quality-Metriken, die zählen.)
Anti-Muster, die Agile am Liefern hindern (und was stattdessen zu tun ist)
Die meisten agilen Misserfolge sind vorhersehbar. Hier sind diejenigen, die in skalierenden Teams immer wieder auftauchen.
Anti-Muster 1: „Sprint = Mini-Wasserfall"
Symptome: Planung im Voraus, 10 Tage bauen, QA am Ende, Überlauf jeden Sprint.
Fix: Arbeitsscheiben unabhängig deploybar machen. Feature Flags verwenden und kontinuierlich innerhalb des Sprints liefern. Tests und Operierbarkeit als Teil der Scheibe behandeln.
Anti-Muster 2: Definition of Done endet beim Merge
Symptome: Sprint endet, dann beginnt ein Release-Zug. „Fertig" häuft sich an.
Fix: Definition of Done so aktualisieren, dass Arbeit entweder deployed oder demonstrierbar releasebar ist (geflaggt) mit Monitoring. Ein zweimal wöchentliches Change Review hinzufügen.
Anti-Muster 3: Langlebige Branches und späte Integration
Symptome: Schmerzhafte Merges, unvorhersehbare Regressionen, „Integrations-Sprint".
Fix: Trunk-basierte Entwicklung bevorzugen, kleine PRs und CI, das schnell läuft. Wenn man nicht täglich mergen kann, ist die Batch-Größe zu groß.
(Wenn CI/CD der Engpass ist, findet sich Wolf-Techs Leitfaden zu CI/CD-Technologie hier.)
Anti-Muster 4: Schätzung wird zum Performance-Vertrag
Symptome: Teams inflationieren Schätzungen, um Commitments einzuhalten, Risiken zu vermeiden oder Vorhersehbarkeit zu spielen.
Fix: Planning von der Performance-Evaluation trennen. Prognosen auf Basis historischen Durchsatzes verwenden und Risiken explizit managen.
Anti-Muster 5: Backlog-Aufblähung und „Vielleicht irgendwann"-Arbeit
Symptome: Hunderte veralteter Einträge, ständige Repriorisierung, keine gemeinsame Klarheit.
Fix: Eine „Backlog-Hygiene"-Regel durchsetzen. Wenn ein Eintrag kein klares Outcome, keinen Eigentümer und kein Zeitfenster hat, archivieren.
Anti-Muster 6: Übergaben überall (Product zu Design zu Dev zu QA zu Ops)
Symptome: Langsame Durchlaufzeit, Fehlkommunikation, lokale Optimierung.
Fix: Auf cross-funktionale Eigentümerschaft für einen Slice hinarbeiten. Auch partielle Verschiebungen helfen – zum Beispiel QA mit Dev während der Implementierung pairen, anstatt danach.
Anti-Muster 7: Retros ohne Veränderung
Symptome: Wiederkehrende Beschwerden, keine Experimente, Zynismus.
Fix: Ein Experiment pro Retro, ein Eigentümer, ein erwarteter messbarer Effekt. Beim nächsten Retro verfolgen.
Eine schnelle Zuordnung von Anti-Muster zu messbarem Signal
| Anti-Muster | Typisches Metriksignal |
|---|---|
| Mini-Wasserfall | Lead Time steigt gegen Sprint-Ende |
| Fertig beim Merge | Niedrige Deploy-Frequenz, große Batch-Größe |
| Späte Integration | Hohe Change Failure Rate, lange CI-Zeiten |
| Schätzungs-Theater | Stabile „Velocity", instabile Delivery-Outcomes |
| Backlog-Aufblähung | Hoher Kontextwechsel, niedriger Durchsatz |
| Zu viele Übergaben | PR-Wartezeiten, lange Durchlaufzeit |
| Retro-Theater | Keine anhaltende Metrikbewegung |
Ein 30-Tage-Reset: Vom agilen Durchführen zum wirklichen Liefern
Kein Reorg ist nötig, um das Liefern zu verbessern. Es braucht einen fokussierten Piloten und eine messbare Baseline.
| Zeitrahmen | Was zu ändern ist | Was zu messen ist |
|---|---|---|
| Woche 1 | „Liefert" definieren und Definition of Done aktualisieren. Ein Team und einen Produktbereich auswählen. | Baseline DORA, PR-Durchlaufzeit |
| Woche 2 | Change Review einführen (2x/Woche). WIP reduzieren (explizites Limit). | Deploy-Frequenz, Arbeitselement-Alter |
| Woche 3 | Scheiben dünner machen. Einen Release-Sicherheitsmechanismus hinzufügen (Flag oder Canary). | Change Failure Rate |
| Woche 4 | Einen operativen Nachweis zu Demos hinzufügen (Monitoring, Logs, Alert, SLI). Ein Retro-Experiment durchführen. | MTTR-Trend, Defekt-Escape-Rate |
Das Ziel ist keine Perfektion in 30 Tagen. Das Ziel ist eine sichtbare Verschiebung hin zu kleineren Batches, schnellerem Feedback und sichereren Releases.
Wo Wolf-Tech helfen kann (ohne Prozessgewicht hinzuzufügen)
Wenn agile Rituale vorhanden sind, das Liefern aber trotzdem langsam ist, liegt der Engpass meist an technischen und systemischen Faktoren: CI/CD-Reibung, unklare Architekturnaht, Legacy-Risiko, fehlende Observability oder eine unrealistische Definition of Done.
Wolf-Tech hilft Teams dabei, Lieferfähigkeit durch Full-Stack-Delivery und fokussiertes Consulting aufzubauen, einschließlich Code-Qualität, Legacy-Optimierung und Verbesserungen des Delivery-Systems.
Für einen strukturierten Ansatz zur Diagnose, was das Liefern wirklich blockiert, können diese Ressourcen hilfreich sein:
- Build Stack: Ein einfacher Blueprint für moderne Produktteams
- Software-Projekt-Kickoff: Umfang, Risiken und Erfolgskennzahlen
- Software bauen: Ein praxisnaher Prozess für vielbeschäftigte Teams
Oder, wer die Lernkurve verkürzen möchte, kann sich über Wolf-Tech für ein Delivery- und Lieferfähigkeits-Assessment melden, das sich auf Rituale, Metriken und die Anti-Muster konzentriert, die das Team am wahrscheinlichsten betreffen.
