
Backend vs. Frontend: Grenzen, APIs und Verantwortung


Die meisten Teams liefern nicht langsamer, weil sie „den falschen Stack gewählt" haben. Sie liefern langsamer, weil die Grenze zwischen Frontend und Backend unscharf ist, APIs nicht wie Verträge behandelt werden und die Verantwortung über „alle" verteilt ist – was meist „niemand" bedeutet. Das Ergebnis ist vorhersehbar: UI-Nacharbeit, brüchige Integrationen, überraschende Latenz und Produktions-Incidents, die zwischen Teams hin- und herspringen.
Dieser Artikel rahmt Backend vs. Frontend so, dass es Ihnen beim Liefern wirklich hilft: indem Grenzen explizit gemacht, APIs als durchsetzbare Verträge gestaltet und klare Verantwortlichkeiten zugewiesen werden, die zum tatsächlichen Arbeitsfluss passen.
Backend vs. Frontend in 2026: über Verantwortung definieren, nicht über das Framework
Die traditionellen Definitionen sind einfach:
- Frontend: der Code, der am nächsten am Nutzer läuft, die UI rendert, Interaktion verwaltet und Nutzerabsicht in Requests übersetzt.
- Backend: der Code, der Geschäftsregeln durchsetzt, Daten und Integrationen koordiniert und vielen Clients stabile Fähigkeiten bereitstellt.
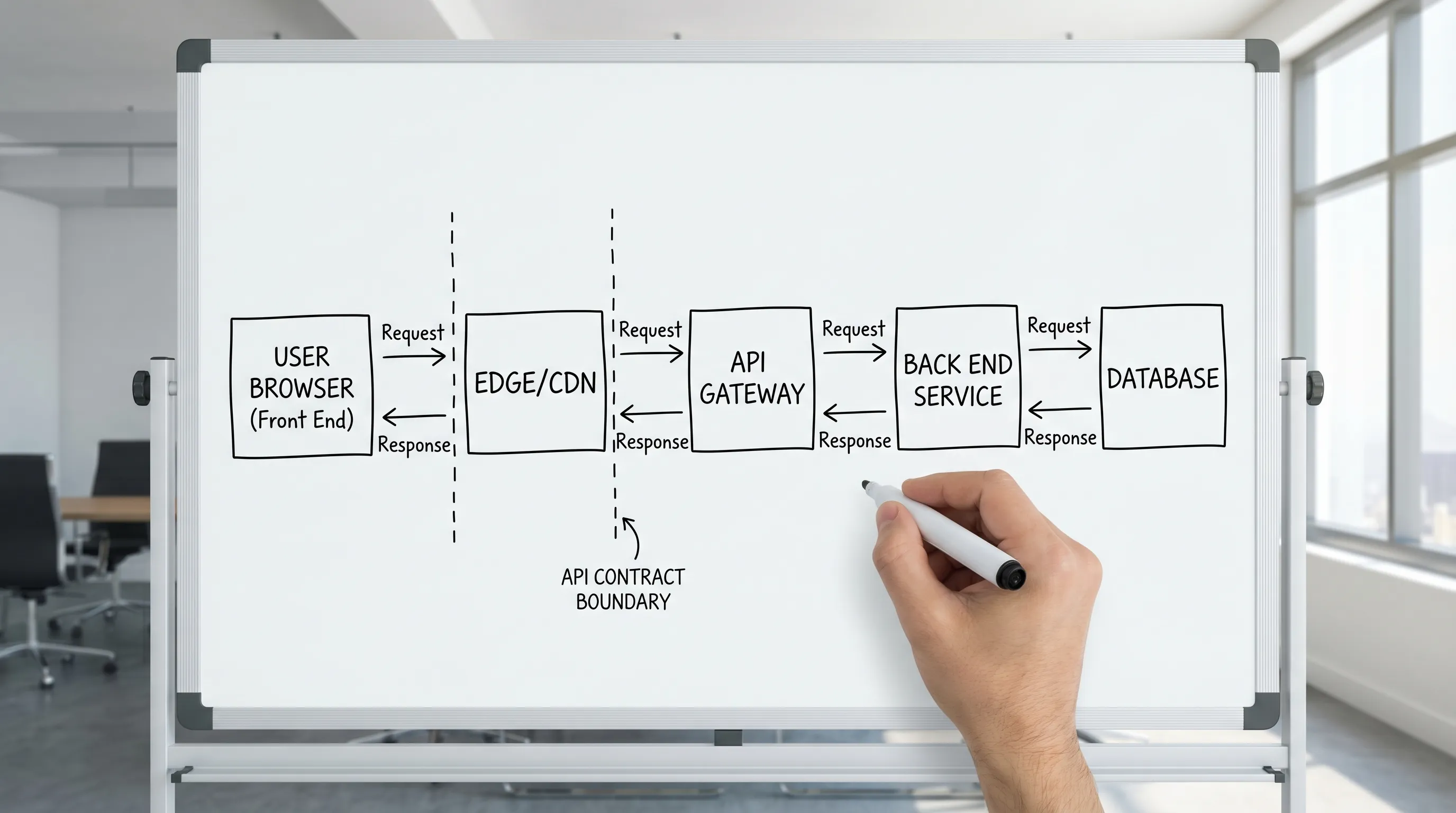
Moderne Stacks verwischen die Laufzeit-Platzierung (SSR, Edge-Rendering, „Full-Stack"-Frameworks, Server Components), aber die Grenze existiert weiterhin. Sie verschiebt sich nur.
Eine praktische Definition, die sich über React-SPAs, Next.js, Mobile-Apps und B2B-Portale hinweg bewährt, lautet:
- Das Frontend verantwortet die Nutzerreise (Zustände, Übergänge, UX-Regeln, Barrierefreiheit, wahrgenommene Performance).
- Das Backend verantwortet die geschäftliche Wahrheit (Autorisierungsentscheidungen, Invarianten, Datenkorrektheit, Seiteneffekte, Integrationssicherheit).
- Die API ist der Handschlag zwischen beiden, und sie muss spezifisch genug sein, um testbar zu sein.
Wenn Sie ein breiteres mentales Modell für Grenzen wünschen (über UI und API hinaus), passt die Perspektive von Wolf-Tech in Software-Systeme 101: Grenzen, Verträge und Verantwortung gut zu diesem Thema.
Wo Grenzen in realen Projekten scheitern (und wie sich das zeigt)
Wenn Teams „Frontend vs. Backend" sagen, ist das eigentliche Problem meist eines davon:
1) Die UI kodiert Geschäftsregeln, die serverseitig gehören
Symptome:
- Verschiedene Clients verhalten sich unterschiedlich (Web vs. Mobile vs. Admin-Portal).
- Das Beheben eines Preis- oder Berechtigungs-Bugs erfordert das erneute Deployment von UI-Clients.
- Sicherheitslücken verstecken sich hinter „die UI lässt das nicht zu".
Faustregel: Wenn es Geld, Berechtigungen, gesetzliche Compliance oder Datenintegrität betrifft, muss das Backend die Quelle der Wahrheit sein.
2) Das Backend lässt Domänenkomplexität in die UI durchsickern
Symptome:
- Die UI muss 5 Endpunkte nacheinander aufrufen (Wasserfälle, brüchige Screens).
- Die UI baut Geschäftsobjekte aus Low-Level-Tabellen zusammen.
- Jede UI-Änderung erzwingt Backend-Refactorings, weil das Modell nicht stabil ist.
Lösung: Stellen Sie fähigkeitsorientierte APIs bereit, die zu Nutzeraufgaben passen, nicht zur Datenbankstruktur.
3) „API" bedeutet Endpunkte, aber keinen Vertrag
Symptome:
- Breaking Changes schleichen sich als „kleine Refactorings" ein.
- Fehlerbehandlung ist inkonsistent (mal 404, mal 200 mit
{ ok:false }). - Pagination, Sortierung, Idempotenz und Rate-Limits sind undokumentiert, also raten Clients.
Lösung: Behandeln Sie die API als Produkt mit Schema, Kompatibilitätsregeln und Tests.
4) Verantwortung ist unklar, also werden Incidents zum Ping-Pong
Symptome:
- Das Frontend beschuldigt „Backend-Latenz", das Backend beschuldigt „zu viele Requests".
- Niemand verantwortet das End-to-End-SLO (zum Beispiel p95-Seitenladezeit oder p95-Checkout).
- Änderungen gehen live, aber Regressionen werden von Kunden entdeckt.
Lösung: Definieren Sie Verantwortung für Reisen und Verträge, nicht nur für Repositories.
Grenzen, die zählen: Laufzeit-, Daten- und Entscheidungsgrenzen
Eine hilfreiche Art, die Linie zu ziehen, ist die Unterscheidung dreier Grenztypen.
Laufzeitgrenze: wo Code ausgeführt wird
Sie müssen weiterhin entscheiden, was wo laufen muss:
- Im Browser (Interaktion, sofortiges Feedback, offline-fähiger Zustand)
- Auf dem Server (sensible Logik, Aggregation, langlaufende Aufgaben)
- Am Edge (latenzkritische Personalisierung, Caching-Gateways)
Das ist ein Implementierungsdetail, beeinflusst aber Sicherheit und Performance.
Datengrenze: wer was schreiben darf
Eine saubere Datengrenze ist oft der Unterschied zwischen „wir können sicher weiterentwickeln" und „alles ist gekoppelt". Verbreitete sichere Voreinstellungen:
- Das Backend verantwortet Schreibvorgänge auf System-of-Record-Daten.
- Das Frontend darf flüchtigen UI-Zustand und lokale Caches verantworten.
- Jeder „Schreibvorgang" vom Frontend ist eine Anfrage an das Backend, einen validierten Zustandsübergang durchzuführen.
Entscheidungsgrenze: wer entscheidet, was erlaubt ist
Autorisierung ist die klassische Entscheidungsgrenze:
- Das Frontend darf Aktionen aus UX-Gründen verbergen oder deaktivieren.
- Das Backend muss die Zugriffskontrolle durchsetzen, unabhängig vom UI-Verhalten.
Für Sicherheits-Baselines und häufige Fehlermodi lohnt es sich, sich an Ressourcen wie den OWASP Top 10 zu orientieren – besonders, wenn Sie Geschäftsregeln nur im Client-Code implementiert sehen.
APIs: der Vertrag, der die Grenze definiert
Eine API ist nicht „wie die UI den Server aufruft". Sie ist ein Vertrag, der unabhängige Änderung erlaubt.
Ein starker Vertrag umfasst typischerweise:
- Schema: Request/Response-Form (OpenAPI für REST, Schema für GraphQL, AsyncAPI für Events).
- Semantik: was Felder bedeuten, was optional ist, Standardverhalten.
- Fehlermodell: konsistente Fehlercodes, Validierungsformat, Retry-Hinweise.
- Kompatibilitätsregeln: was als Breaking gilt, wie Versionierung funktioniert.
- Nicht-funktionale Erwartungen: Latenzbudgets, Rate-Limits, Pagination-Limits.
- Sicherheitserwartungen: Auth-Methode, Scopes/Rollen, Mandanten-Isolationsregeln.
Wenn Sie GraphQL nutzen, ist das Schema eine natürliche Vertragsoberfläche, aber Sie brauchen trotzdem operative Regeln (Query-Kosten, Caching-Strategie, Autorisierungsmodell). Der Deep Dive von Wolf-Tech in GraphQL-APIs: Vorteile, Fallstricke und Anwendungsfälle ist eine gute Ergänzung.
Die häufigste API-Vertragslücke: „nur der Happy Path"
Teams einigen sich oft auf die Erfolgsantwort und ignorieren alles andere. Die UI erfindet dann Verhalten für:
- Teilausfälle
- Veraltete Daten
- Berechtigungsänderungen mitten in der Session
- Rate-Limits und Timeouts
- Hintergrundverarbeitung (angenommen vs. abgeschlossen)
Genau hier entsteht Nacharbeit.
Eine praktische Lösung ist, „Zustandsrealismus" zum Teil des Vertrags zu machen – ähnlich dem „UX-zu-Architektur-Handschlag"-Ansatz, der in Webanwendung gestalten: Der UX-zu-Architektur-Handschlag beschrieben wird.
Verantwortung: die fehlende Hälfte von „Grenzen und APIs"
Sie können gut gezogene Grenzen haben und trotzdem scheitern, wenn niemand den Vertrag end-to-end verantwortet.
Verantwortung sollte beantworten:
- Wer genehmigt Änderungen an diesem API-Vertrag?
- Wer wird alarmiert, wenn das SLO verletzt wird?
- Wer pflegt Client-SDKs oder generierte Typen?
- Wer aktualisiert Doku und Migrationshinweise?
Hier geht es weniger um Organigramme als darum, Koordinationskosten zu senken.
Ein einfaches Verantwortungsmodell, das skaliert
Viele Teams kommen mit drei expliziten Verantwortlichen gut zurecht:
- Reise-Verantwortliche/r (Frontend-Lead): verantwortet Nutzererfahrung, Zustände und wahrgenommene Performance.
- Fähigkeits-Verantwortliche/r (Backend-Lead): verantwortet Geschäftsregeln, Korrektheit und Integrationssicherheit.
- Vertrags-Verantwortliche/r (benannt, manchmal geteilt): verantwortet die API-Oberfläche und Kompatibilität, einschließlich Tests.
Der/die Vertrags-Verantwortliche fehlt oft. Wenn er fehlt, werden „kleine Änderungen" zu Ausfällen.
Wenn Zuverlässigkeit Priorität hat, lassen sich die in Backend-Entwickler: Fähigkeiten, die Ausfälle verhindern beschriebenen Gewohnheiten direkt auf API-Verantwortung übertragen (Fehlermodellierung, Vertragsdenken, Observability und Änderungssicherheit).
Was wohin gehört: eine praktische Verantwortungsaufteilung
Es geht nicht darum, starre Silos zu schaffen. Es geht darum, Entscheidungen vorhersehbar zu machen.
| Anliegen | Frontend verantwortet typischerweise | Backend verantwortet typischerweise | Geteilte Vertragsoberfläche |
|---|---|---|---|
| UX-Flows und -Zustände | Screens, Übergänge, Optimistic UI, Loading-/Empty-/Error-UX | State-Machine-Constraints, Async-Job-Zustände | Zustandsmodell und Status-Semantik |
| Validierung | Inline-UX-Validierung, Feldhinweise | Maßgebliche Validierung, Constraints, Deduplizierung | Validierungs-Fehlerformat |
| Autorisierung | Sichtbare Berechtigungen (was zu zeigen ist) | Durchgesetzte Berechtigungen (was erlaubt ist) | Auth-Scopes, Fehlercodes |
| Performance | Bundle-Größe, Rendering, Caching auf dem Client | Query-Effizienz, Caching, Concurrency-Limits | Latenzbudgets und Payload-Größen |
| Datenformung | View-Modelle für das Rendering | Domänenmodelle, Aggregation, Integrationslogik | Stabilität der Response-Form |
| Observability | Frontend-Logs, RUM-Signale, User-Impact-Traces | Logs/Metriken/Traces, Incident-Runbooks | Correlation-IDs, Trace-Kontext |
Zwei Anmerkungen, die häufige Fehler verhindern:
-
Duplizierte Logik ist nicht automatisch schlecht. Manche Duplizierung ist beabsichtigt (zum Beispiel UI-Validierung für die Bedienbarkeit, Server-Validierung für die Korrektheit). Entscheidend ist, den Server maßgeblich zu machen.
-
„Das Backend liefert rohe DB-Entitäten" ist meist ein Geruch. Es koppelt Ihre UI an die interne Struktur und macht Refactorings teuer.
Grenz-Patterns, die Koordinationskosten senken
Pattern 1: BFF (Backend for Frontend)
Ein BFF gibt der UI einen Vertrag, der zu ihren Bedürfnissen passt, und schützt gleichzeitig die Kern-Domänen-Services vor Churn. Es ist besonders nützlich, wenn:
- Sie mehrere Clients haben (Web, Mobile, Partner).
- Ihre Domänen-APIs stabil sind, sich die UI-Anforderungen aber häufig ändern.
- Sie Aggregation benötigen, um geschwätzige UIs zu vermeiden.
Ein BFF ist kein Allheilmittel. Es benötigt dieselbe Vertragsdisziplin plus gute Observability.
Pattern 2: Contract-First-Entwicklung (mit automatisierten Prüfungen)
Contract-First bedeutet nicht „eine riesige Spezifikation im Voraus schreiben". Es bedeutet:
- Den Vertrag früh explizit machen (OpenAPI, GraphQL-Schema oder typisierte Endpunkte).
- Wo sinnvoll Clients generieren.
- Contract-Tests und Kompatibilitätsprüfungen zur CI hinzufügen.
Das ist eine der wirkungsvollsten Methoden, um „lokal hat es funktioniert"-Integrationsfehler zu verhindern.
Pattern 3: Kompatibilitätsregeln (damit Sie unabhängig liefern können)
Mindestens sollten Teams sich einigen, was Breaking ist:
- Felder zu entfernen ist Breaking.
- Bedeutung zu ändern ist Breaking.
- Validierung zu verschärfen ist meist Breaking.
Dann entscheiden Sie, wie Sie mit Breaking Changes umgehen: Versionierung, rein additive Weiterentwicklung oder explizite Deprecation-Fenster.
Das Mindestset an Artefakten, das Grenzen real macht
Grenzen bleiben Absichten, bis Sie sie in Artefakte überführen, die überprüft und getestet werden können.
| Artefakt | Was es verhindert | Hauptverantwortliche/r |
|---|---|---|
| API-Schema (OpenAPI/GraphQL) | Rätselraten und undokumentierte Änderungen | Vertrags-Verantwortliche/r |
| Fehlermodell-Spezifikation (mit Beispielen) | UI-spezifische Fehler-Hacks | Vertrags-Verantwortliche/r |
| Contract-Tests in CI | Breaking Changes, die in Releases rutschen | Vertrags-Verantwortliche/r + beide Teams |
| Reise-Zustandsmodell | „Unbehandelter Zustand"-Bugs und UX-Nacharbeit | Reise-Verantwortliche/r |
| SLOs/SLIs für Schlüssel-Flows | Performance-Debatten ohne Daten | Geteilt (Reise + Fähigkeit) |
| Runbook für Top-Incidents | Langsame Wiederherstellung und unklare Eskalation | Fähigkeits-Verantwortliche/r |
Dieser „Beweise statt Versprechen"-Ansatz ist konsistent mit der Liefer-Philosophie von Wolf-Tech über Service-Seiten und Checklisten hinweg, zum Beispiel Frontend-Entwicklungsdienstleistungen: Lieferergebnisse, die zählen.
Eine schnelle Kickoff-Checkliste für die Frontend-Backend-Abstimmung
Wenn Sie teuren Grenz-Churn vermeiden wollen, nutzen Sie diese schlanke Checkliste beim Kickoff (oder wenn ein Feature anfängt auszuufern).
- Definieren Sie die wichtigsten 1 bis 3 Nutzerreisen und Erfolgskennzahlen (nicht nur „Screens").
- Entscheiden Sie, welche Schreibvorgänge das Frontend auslösen kann und was die maßgeblichen Zustandsübergänge sind.
- Spezifizieren Sie den API-Vertrag einschließlich Fehlerfällen und Zuständen langlaufender Workflows.
- Einigen Sie sich auf Performance-Budgets (Payload-Größe, p95-Latenz) für die Reisen.
- Benennen Sie Verantwortliche für die Reise, die Fähigkeit und den Vertrag.
- Entscheiden Sie, wie Breaking Changes funktionieren, einschließlich Deprecation-Regeln.
Für Organisationen, die eine messbare Lieferverbesserung wollen, können Sie diese Entscheidungen auch an Liefermetriken (Lead Time, Change Failure Rate, MTTR) ausrichten, die durch DORA populär wurden. Googles DORA-Forschung ist ein nützlicher Ausgangspunkt, um Engineering-Praktiken mit Ergebnissen zu verknüpfen.
Wann externe Hilfe sinnvoll ist
Grenzprobleme sind für Teams oft „unsichtbar", weil sich alle an die Reibung gewöhnt haben. Eine externe Überprüfung ist am wertvollsten, wenn:
- Frontend- und Backend-Teams sich in jedem Sprint gegenseitig blockieren.
- Sie ein Legacy-System modernisieren und sichere Nahtstellen benötigen (APIs, Verträge, Strangler-Slices).
- Incidents sich wiederholen, die Ursache aber ständig zwischen UI, API und Daten wechselt.
- Sie ein neues Full-Stack-Framework einführen und Klarheit über die Verantwortung brauchen.
Wolf-Tech unterstützt Teams mit Architektur- und Vertragsreviews, Legacy-Code-Optimierung und Full-Stack-Entwicklung. Wenn Sie einen zweiten Blick auf Ihre Grenzen und API-Verträge wünschen, starten Sie bei wolf-tech.io und nutzen Sie die Blog-Ressourcen, um sich auf die Artefakte und Nachweise abzustimmen, bevor Sie den Build skalieren.