
Skalierung über diverse Branchen: Wiederverwendbare Architektur als Erfolgsfaktor


Ein Produkt zu skalieren ist schwierig. Eine Produktlinie über diverse Branchen hinweg zu skalieren ist noch schwieriger, denn jede neue Domäne bringt „Sonderfälle" mit, die den Quellcode, das Liefersystem und die kognitive Last des Teams unter Druck setzen.
Die gute Nachricht: Die meisten erfolgreichen branchenübergreifenden Plattformen gewinnen nicht dadurch, dass sie Projekte kopieren. Sie gewinnen, indem sie eine wiederverwendbare Architektur aufbauen: einen stabilen Kern von Fähigkeiten, der zuverlässig und unaufgeregt bleibt, plus klar definierte Erweiterungspunkte, an denen branchenspezifische Regeln weiterentwickelt werden können, ohne das gesamte System zu forken.
Dieser Artikel erklärt, was „wiederverwendbare Architektur" in der Praxis bedeutet, welche Muster sie funktionieren lassen und wie ein pragmatisches Playbook zur Umsetzung aussieht – ohne das Team in eine interne Framework-Fabrik zu verwandeln.
Was „wiederverwendbare Architektur" bedeutet (und was nicht)
Wiederverwendbare Architektur ist kein „gemeinsames Repository mit ein paar Hilfsfunktionen". Und auch keine „eine Mega-Plattform, die jedes Produkt nutzen muss".
Eine wiederverwendbare Architektur ist ein wiederholbarer Blueprint für den Aufbau und Betrieb von Software, der folgendes teilt:
- Stabile Bausteine (Identität, Berechtigungen, Audit-Logging, Benachrichtigungen, Workflows, Datenzugriffsmuster)
- Standardisierte Schnittstellen (API-Verträge, Events, Integrationsgrenzen)
- Produktions-Leitplanken (CI/CD, Sicherheits-Baselines, Observability-Konventionen)
- Ein klares Anpassungsmodell (Konfiguration, Plugins, Domänen-Module oder separate Bounded Contexts)
Das Ziel ist einfach: neue Branchenvarianten schneller mit weniger Regressionen ausliefern, während die Optionalität für zukünftige Änderungen erhalten bleibt.
Warum wiederverwendbare Architektur branchenübergreifend gewinnt
Wenn man mehrere Branchen bedient, multiplizieren sich die Anforderungen:
- Unterschiedliche Compliance-Regime und Audit-Erwartungen
- Unterschiedliche Workflow-Formen (Human-in-the-Loop-Genehmigungen vs. Straight-Through-Processing)
- Unterschiedliche Daten-Lebenszyklen (Aufbewahrung, Löschung, Herkunft)
- Unterschiedliche Integrations-Landschaften (ERPs, CRMs, Zahlungsanbieter, LMS, Listing-Feeds)
Eine wiederverwendbare Architektur hilft, weil sie die Teile reduziert, die sich ändern müssen, und die Teile verhärtet, die es nicht dürfen.
Der Compounding-Effekt: Wiederverwendung verbessert sowohl Geschwindigkeit als auch Sicherheit
Wiederverwendung geht nicht nur um Entwicklergeschwindigkeit. Sie schafft auch operative Konsistenz, die oft der echte Skalierungs-Engpass ist.
Wenn jede branchenspezifische Lösung ihr eigenes Auth-Muster, ihr eigenes Logging-Format, ihren eigenen Deployment-Prozess und ihren eigenen Incident-Workflow hat, hat man nicht 5 Produkte – man hat 5 verschiedene Betriebsmodelle.
Eine gemeinsame Architektur verwandelt mühsam erlernte Lektionen in Standardeinstellungen.
Die versteckten Kosten, die man vermeidet: „parallele Neuerfindung"
Branchenübergreifende Teams wiederholen dieselbe teure Arbeit häufig:
- RBAC und Tenant-Grenzen neu implementieren
- Erneut lernen, wie man sichere Schema-Migrationen durchführt
- Audit-Trails und Export-Pipelines neu aufbauen
- Observability von Grund auf neu erstellen
Das sind keine Differenzierungsmerkmale. Das sind Grundvoraussetzungen. Eine wiederverwendbare Architektur macht sie langweilig.
Die Hauptfalle: Übergeneralisierung (und wie man sie vermeidet)
Das Versagens-Muster ist bekannt: Ein Team versucht, eine „universelle Plattform" zu entwerfen, liefert dann monatelang nichts. Oder schlimmer: liefert ein starres Framework, das Teams umgehen, und produziert so Forks.
Eine praktische Regel:
Standardisiere, was konsistent sein muss, und modularisiere, was variieren muss.
Das bedeutet: man investiert in wiederverwendbare Architektur, wenn man benennen kann:
- Die stabilen „Kern"-Fähigkeiten, die man wiederholt verwenden wird
- Die Erweiterungspunkte, an denen Unterschiede erwartet werden
- Die Governance, die unkontrollierte Divergenz verhindert
Wenn man das nicht benennen kann, ist man noch nicht bereit für Wiederverwendung – man befindet sich noch in der Discovery-Phase.
Ein einfaches Modell: Kern vs. Rand (stabil vs. variabel)
Jedes branchenübergreifende Produkt lässt sich so betrachten:
- Kern: Fähigkeiten, die überall gleich sind (oder sein sollten)
- Rand: branchenspezifische Regeln, Workflows, Integrationen und Compliance-Overlays
Eine starke Architektur macht den Kern leicht wiederverwendbar und den Rand leicht austauschbar.
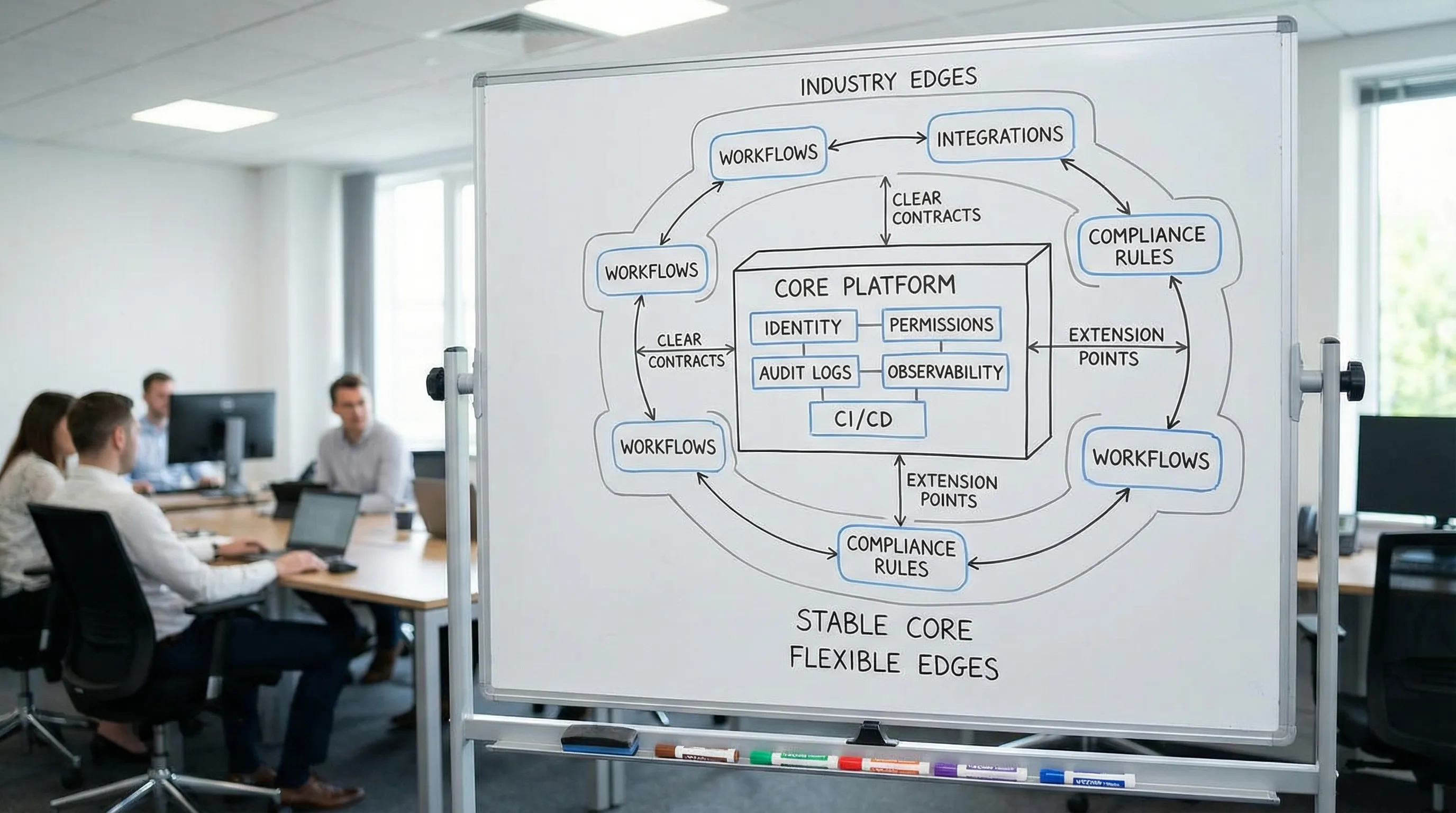
Wo Teams die Grenze typischerweise falsch ziehen
- Sie packen Geschäftsregeln in den „gemeinsamen Kern", was jede Änderung politisch macht.
- Sie erlauben es jedem Produkt, „Kern"-Belange eigenständig zu implementieren, was operatives Chaos erzeugt.
Eine bessere Aufteilung:
- Der Kern besitzt Querschnittsbelange und technische Leitplanken.
- Domain-Module (oder Bounded Contexts) besitzen Geschäftsregeln.
Dies deckt sich gut mit pragmatischem Domain-Driven Design und Architektur-Leitplanken, die sich durchsetzen lassen.
Der Stack für wiederverwendbare Architektur (was zuerst standardisieren)
Wenn man Wiederverwendung anstrebt, die sich auszahlt, braucht man Konsistenz über mehr als nur Code. Hier ist ein praktischer Stack, den man produktübergreifend standardisieren kann.
| Schicht | Was man standardisiert | Was sich je nach Branche unterscheidet |
|---|---|---|
| Produktfähigkeiten | Identität, Tenant-Modell, Rollen/Berechtigungen, Audit-Logging, Benachrichtigungsmuster, Dateihandling | Domänen-Workflows, Entitätsregeln, Genehmigungsketten |
| API & Integration | API-Konventionen, Versionierung, Event-Schemas, Idempotenz, Rate-Limits | Spezifische Anbieter, Datenmappings, Partner-Einschränkungen |
| Daten & Governance | Migrationsstrategie, Verschlüsselungs-Defaults, Datenzugriffsmuster, Aufbewahrungs-Hooks | Datenklassifikationen, Audit-Felder, Reporting-Anforderungen |
| Plattform & Lieferung | CI/CD-Muster, Umgebungsstrategie, Observability, Incident-Bereitschaft | Traffic-Form, Latenz-Ziele, Deployment-Einschränkungen |
Wenn man intern bereits ein „Build Stack"-Konzept hat, ist dies die branchenübergreifende Version davon. (Wolf-Tech hat einen tieferen Blueprint zu dieser Idee in Build Stack: Ein einfacher Blueprint für moderne Produktteams.)
Muster, die Wiederverwendung real machen (ohne einen Rewrite zu erzwingen)
Im Folgenden finden sich Muster, die domänenübergreifend konsistent funktionieren – von B2B-SaaS bis hin zu regulierten Umgebungen.
1) Den modularen Monolith als wiederverwendbaren Kern bevorzugen
Für viele Teams ist ein modularer Monolith die beste Wiederverwendungseinheit in der frühen Phase:
- Ein Deployment, konsistente Observability, weniger verteilte Fehlerquellen
- Klare interne Modulgrenzen (Packages) und explizite Abhängigkeiten
- Einfacheres Refactoring und Governance
Man kann später zu Services übergehen, wo es durch Skalierungsbeschränkungen gerechtfertigt ist – nicht durch Mode. Für einen breiteren Blick auf echte Skalierungsmechaniken: Softwarelösungen entwickeln, die wirklich skalieren.
2) Erweiterungspunkte entwerfen, keine Ausnahmen
Branchenübergreifende Variation sollte nicht als verstreute if (branche == X)-Bedingungen implementiert werden.
Bessere Optionen:
- Eine Policy-Schicht (Regelauswertung), die sich ändern lässt, ohne die Domäne neu zu schreiben
- Eine Workflow-Orchestrierungs-Schicht für Genehmigungen, Übergaben, asynchrone Verarbeitung
- Eine Adapter-Schicht für externe Integrationen (Anti-Corruption-Grenzen)
- Ein Plugin-Modell, bei dem Branchenmodule Handler, Validatoren oder Mapper registrieren
Der Schlüssel: Der Kern ruft ein Interface auf, und Branchenmodule implementieren es.
3) Konfiguration für Verhalten verwenden – aber begrenzt halten
Konfiguration ist mächtig, bis sie zu einer Programmiersprache wird.
Praktische Leitplanken:
- Konfiguration für Schwellenwerte, Feature-Expositionen, Mappings und Templates erlauben
- Konfiguration für Kern-Invarianten wie Autorisierungsmodelle vermeiden
- Schema-Validierung und Versionierung für Konfigurationen vorschreiben
Wenn Konfigurationsänderungen die Produktion beschädigen können, sind Konfigurationen als deploybare Artefakte mit Review, Tests und Rollback zu behandeln.
4) Multi-Tenancy als erstklassige Architekturentscheidung betrachten
Auch wenn man heute noch kein Multi-Tenant-System hat: Branchenübergreifende Angebote werden morgen oft zu Multi-Tenant-Systemen.
Frühzeitig zu klärende Schlüsselfragen:
- Tenant-Isolationslevel (geteilte DB, gemeinsames Schema, separate Schemas, separate DBs)
- Tenant-bewusstes Caching und Hintergrundprozesse
- Tenant-bewusste Observability (Logs und Traces mit Tenant-Kontext)
Es gibt keine eine „richtige Antwort" – es geht darum, bewusst zu wählen und es produktübergreifend konsistent zu halten.
5) „Nicht-Verhandelbare" standardisieren: Sicherheit, Lieferung und Betreibbarkeit
Branchenübergreifende Arbeit erhöht den Blast-Radius. Der wiederverwendbare Kern sollte die langweiligen, aber kritischen Baselines beinhalten:
- Eine sichere Lieferpipeline mit Supply-Chain-Kontrollen (siehe NIST SSDF als weit verbreitete Baseline)
- Threat-Modeling und Secure-by-Default-Muster (OWASP-Leitlinien sind ein guter Ausgangspunkt, z. B. der OWASP Application Security Verification Standard)
- Observability-Konventionen (strukturiertes Logging, Metriken-Benennung, Tracing-Propagation)
Auf dem Wolf-Tech-Blog gehen mehrere Artikel tiefer auf verwandte Leitplanken ein, darunter CI/CD-Technologie: Schneller bauen, testen, deployen und Backend-Entwicklung: Best Practices für Zuverlässigkeit.
Eine Fähigkeits-Map, die sich über die meisten Branchen wiederverwenden lässt
Bei „branchenspezifischen" Produkten wiederholen sich viele Fähigkeiten. Sie sollten als wiederverwendbare Module behandelt werden, nicht als maßgeschneiderte Implementierungen.
| Branchenübergreifende Fähigkeit | Warum sie wiederverwendbar ist | Was erweiterbar sein muss |
|---|---|---|
| Identität und Zugriff (RBAC) | Dieselben Grundbausteine überall | Rollenmodelle, Berechtigungssets, Tenant-Segmentierung |
| Audit-Logging | Compliance und Support hängen davon ab | Event-Taxonomie, Aufbewahrungsregeln, Exportformate |
| Benachrichtigungen | Gemeinsame Nutzererwartung | Kanäle, Templates, Eskalationsregeln |
| Datei- und Dokumenten-Handling | Upload, Scan, Export sind universal | Klassifikation, Wasserzeichen, Aufbewahrung |
| Reporting-Exporte | Stakeholder wollen Daten heraus | Feldebenen-Zugriff, Compliance-Filter, Zeitplanung |
| Integrationsframework | Alles integriert | Anbieterspezifische Adapter und Mappings |
Diese Tabelle ist bewusst fähigkeitsorientiert. Sie hilft dabei, den häufigen Fehler zu vermeiden, um ein bestimmtes Tool herum zu standardisieren, anstatt um eine stabile Anforderung.
Das Playbook: Wiederverwendbare Architektur in 6 pragmatischen Schritten umsetzen
Mit Evidenz beginnen: Wo wiederholt man sich bereits?
Bevor man „platformt", sollte man Beweise sammeln:
- Welche Module wurden 2 oder mehr Mal neu implementiert?
- Welche Incidents wiederholen sich produktübergreifend?
- Welche Integrationen verursachen den meisten Rework?
Man sucht nach Hotspots im Code und in Betriebsabläufen.
Für eine strukturierte Perspektive zur Überprüfung von Architektur-Evidenz bietet Wolf-Tech eine praktische Scorecard in Was ein Tech-Experte in Ihrer Architektur prüft.
Eine Referenzarchitektur definieren und leicht durchsetzen
Eine Referenzarchitektur ist kein 60-seitiges Dokument. Es ist ein kleiner Satz von Entscheidungen, der Mehrdeutigkeit reduziert:
- Modulgrenzen und Abhängigkeitsregeln
- API-Konventionen und Versionierungsregeln
- Datenzugriffsmuster und Migrationsansatz
- Observability- und Fehlerbehandlungs-Konventionen
Diese Entscheidungen werden als Architecture Decision Records (ADRs) festgehalten, damit sie sich mit dem Kontext weiterentwickeln.
Den „Golden Path" im Liefersystem aufbauen
Wiederverwendbare Architektur scheitert, wenn der Standardweg schmerzhaft ist.
Man macht den gepflasterten Weg zum einfachsten Weg:
- Eine Standard-CI-Pipeline-Vorlage
- Ein Ansatz für Preview-Umgebungen
- Eine Release-Strategie (Feature-Flags, Canary, Blue/Green nach Bedarf)
Hier trifft Architektur auf die Lieferrealität – und so reduziert man die Reibung zwischen Teams.
Erst Erweiterungspunkte erstellen, dann Code dazu migrieren
Nicht alles neu schreiben.
- Eine Variabilitätszone mit hohem Churn identifizieren (Preisregeln, Genehmigungsworkflows, Dokumentenanforderungen)
- Ein Interface und Contract-Tests definieren
- Eine Branchenimplementierung hinter das Interface verschieben
- Eine zweite Branchenimplementierung hinzufügen, um zu beweisen, dass der Erweiterungspunkt real ist
Wenn der Erweiterungspunkt zweimal funktioniert, ist er kein Einzelfall.
Wiederverwendung als Produkt behandeln (mit Versionierung und Ownership)
Wiederverwendbare Komponenten brauchen Eigentümer, Release-Notes, Kompatibilitätsregeln und Deprecation-Policies.
Ohne das wird „geteilt" zu „feststeckend", und Teams forken, um zu entkommen.
Ergebnisse messen, keine Wiederverwendungs-Eitelkeitsmetriken
„Wiederverwendete Code-Zeilen" sind nicht das Ziel.
Man verfolgt, was das Unternehmen spürt:
| Ergebnis | Praktische Metrik, die man verfolgen kann |
|---|---|
| Schnelleres Ausliefern | Lead Time for Changes (DORA-Stil) |
| Sicherere Releases | Change Failure Rate, Rollback-Rate |
| Schnellere Erholung | MTTR, Incident-Wiederholungsrate |
| Weniger Rework | Defect Escape Rate, Zahl doppelter Implementierungen |
Für Teams, die ihre Delivery-Reife skalieren, ist das DORA-Framework weit verbreitet und gut dokumentiert (siehe das DORA-Forschungsprogramm).

Wann wiederverwendbare Architektur sich lohnt (und wann nicht)
Wiederverwendbare Architektur ist ein Hebel-Spiel. Sie hat Vorabkosten und zahlt sich aus, wenn man echte Wiederholung hat.
Es lohnt sich in der Regel, wenn:
- Man 2 oder mehr Branchenvarianten erwartet oder mehrere Kunden mit ähnlichen Anforderungen
- Stabile Querschnittsanforderungen vorliegen (Sicherheit, Audit, Multi-Tenant)
- Eine Roadmap existiert, die wiederholt dieselben Plattformbereiche berühren wird
Es lohnt sich in der Regel nicht, wenn:
- Man noch den Product-Market-Fit validiert und Anforderungen volatil sind
- Jedes „Branchen"-Projekt eigentlich ein maßgeschneidertes Einzelstück ohne echten Wiederverwendungsbedarf ist
- Die Delivery-Hygiene fehlt (Tests, CI/CD, Observability), um Komponenten sicher zu teilen
In diesen Fällen sollte man zunächst die Änderungssicherheit und Delivery-Konsistenz verbessern. Standardisierung ist ein Kraft-Multiplikator – aber nur, wenn man zuverlässig liefern kann.
Wie Wolf-Tech branchenübergreifende Skalierung angeht
Wolf-Tech ist auf Full-Stack-Entwicklung und Beratung spezialisiert, die Teams hilft, Technologie über mehrere Kontexte hinweg zu bauen, zu optimieren und zu skalieren. In der Praxis bedeutet das häufig:
- Eine Architektur-Baseline definieren, die Wiederverwendung unterstützt, ohne Teams in ein starres Framework einzusperren
- Delivery- und operative Leitplanken verhärten, damit gemeinsame Komponenten sicher bleiben
- Legacy-Bereiche modernisieren, die Modularisierung und saubere Erweiterungspunkte verhindern
Wenn der Ausgangspunkt Legacy-Einschränkungen beinhaltet, ist es oft möglich, Wiederverwendung inkrementell durch Refactoring, Seams und Strangler-Muster einzuführen. (Weiterführende Lektüre: Legacy-Code zähmen: Strategien, die wirklich funktionieren.)
Häufig gestellte Fragen
Was ist wiederverwendbare Architektur in der Softwareentwicklung? Wiederverwendbare Architektur ist ein wiederholbarer Blueprint, der Kernfähigkeiten standardisiert (Sicherheit, Identität, Observability, Lieferung) und gleichzeitig branchenspezifische Variation durch klare Erweiterungspunkte ermöglicht.
Ist wiederverwendbare Architektur dasselbe wie der Aufbau einer internen Plattform? Nicht unbedingt. Eine Plattform kann Teil davon sein, aber Wiederverwendung umfasst auch Modulgrenzen, Verträge, gemeinsame operative Muster und Governance. Viele Teams gelingen mit einem modularen Monolith plus gemeinsamen Delivery-Standards.
Wie verhindert man, dass „geteilter Kern"-Code zum Engpass wird? Geschäftsregeln in Domain-Modulen belassen, nicht im Kern. Gemeinsame Komponenten versionieren, Eigentümerschaft definieren und explizite Erweiterungspunkte schaffen, damit Teams Branchenvarianten weiterentwickeln können, ohne zu forken.
Wie geht man mit unterschiedlichen Compliance-Anforderungen in verschiedenen Branchen um? Audit-Logging, Identitäts- und Daten-Governance-Primitive standardisieren, dann branchenspezifische Policies (Aufbewahrung, Genehmigungen, Exportformate) über Konfiguration oder Policy-Module schichten, die getestet und versioniert sind.
Sollte man Microservices verwenden, um über Branchen zu skalieren? Nur wenn klare Skalierungsbeschränkungen die Betriebskosten rechtfertigen. Viele Teams skalieren branchenübergreifend schneller mit einem modularen Monolith zuerst, und extrahieren dann Services, wo Grenzen und Last-Muster es verlangen.
Was ist der schnellste Weg, um wiederverwendbare Komponenten zu erstellen? Eine wiederholte Fähigkeit identifizieren (RBAC, Audit-Logs, Integrations-Adapter), ein Interface und Contract-Tests definieren, es in einem Produkt implementieren und dann beweisen, dass es in einem zweiten Produkt funktioniert, bevor man es ausweitet.
Über diverse Branchen skalieren, ohne den Code zu forken?
Wenn man wiederholte Implementierungen, inkonsistente Delivery-Muster oder wachsende Reibung zwischen Branchenvarianten beobachtet, kann Wolf-Tech dabei helfen, eine wiederverwendbare Architektur-Baseline zu entwerfen und inkrementell umzusetzen – ohne darauf zu wetten, dass ein kompletter Rewrite gelingt.
Wolf-Tech erkunden unter wolf-tech.io – oder Kontakt aufnehmen, um einen Architektur-Review, Legacy-Optimierung oder Full-Stack-Delivery-Support zu besprechen.