
Software bauen: Ein Praxisprozess für vielbeschäftigte Teams


Software zu bauen, während man ein Geschäft betreibt, kann sich anfühlen, als würde man ein Haus renovieren, während man darin wohnt. Sie brauchen wöchentlich sichtbaren Fortschritt, aber Sie brauchen auch Stabilität, Sicherheit und eine Codebase, die nicht unter ihrem eigenen Gewicht zusammenbricht.
Dieser Leitfaden legt einen praxistauglichen Software-Bauprozess für vielbeschäftigte Teams dar: ein leichtgewichtiges Set aus Phasen, Artefakten und Quality Gates, das Ihnen hilft, schneller auszuliefern, ohne das Unternehmen auf einen Rewrite oder einen heroischen Launch zu wetten.
Was „Software bauen" 2026 bedeuten sollte
Für die meisten Teams bedeutet Software bauen nicht „ein Projekt fertigstellen". Es heißt kontinuierlich Geschäftsergebnisse in zuverlässige, messbare Produktänderungen zu überführen.
Ein guter Prozess macht drei Dinge gleichzeitig:
- Reduziert Entscheidungslatenz (Teams hängen nicht in Genehmigungen fest).
- Reduziert Rework (Teams validieren Annahmen früh, mit einem schmalen Slice).
- Reduziert operatives Risiko (Änderungen sind beobachtbar, reversibel und sicher).
Wenn Sie eine forschungsbasierte Möglichkeit suchen, zu tracken, ob Ihr Auslieferungssystem besser wird, ist der Industriestandard die DORA-Metriken (Deployment-Frequenz, Lead Time for Changes, Change Failure Rate, Time to Restore). Googles DORA-Team veröffentlicht laufende Leitlinien und Benchmarks in der State of DevOps-Forschung.
Der Software-Bauprozess für vielbeschäftigte Teams (7 Phasen)
Das Ziel ist nicht, Bürokratie hinzuzufügen. Das Ziel ist, gerade genug geteilte Struktur zu schaffen, damit die Auslieferung vorhersehbar bleibt, wenn sich Prioritäten ändern, Personen rotieren oder das System wächst.
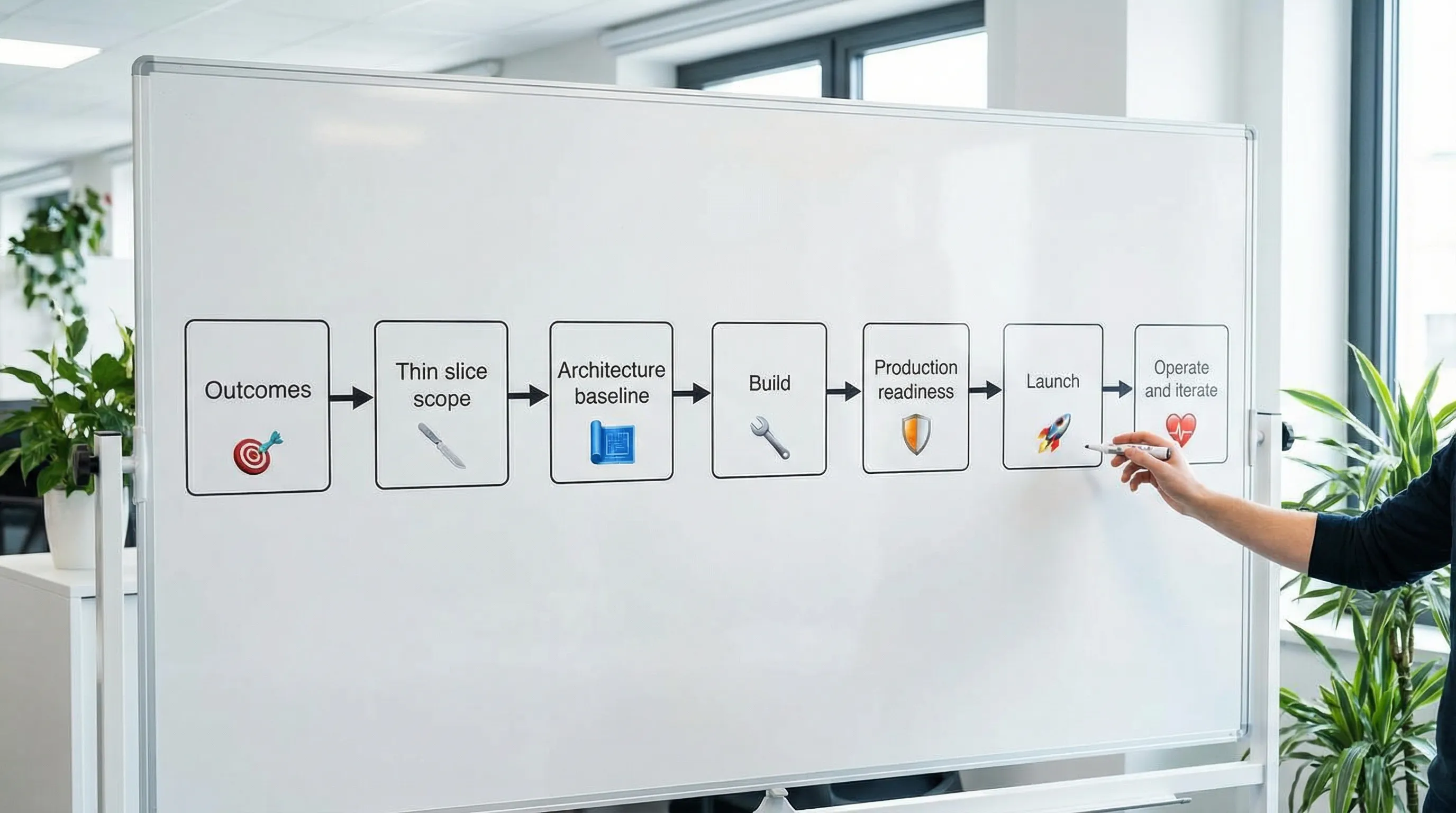
1) Auf Ergebnisse ausrichten (keine Feature-Listen)
Starten Sie mit einem einseitigen Ergebnis-Brief, der beantwortet:
- Welches Nutzer- oder Geschäftsproblem lösen wir?
- Was ändert sich, wenn wir Erfolg haben (Conversion, Durchlaufzeit, Kosten, Risiko, Retention)?
- Welche Constraints sind nicht verhandelbar (Compliance, Datenresidenz, Uptime-Erwartungen)?
Hier erzeugen viele Teams unbeabsichtigt Verschwendung: Sie überspringen die Ergebnis-Klarheit und streiten dann wochenlang über Scope. Wenn Sie einen praxistauglichen Ansatz suchen, Anforderungen in UI-Flows und Engineering-fertige Artefakte zu überführen, ist Wolf-Techs Leitfaden zu Software-Design ein starker Begleiter.
2) Einen Thin Slice definieren, der Wert und Risiko belegt
Ein Thin Slice ist die kleinste End-to-End-Fähigkeit, die:
- Ein für den Nutzer sichtbares Ergebnis liefert, und
- Die riskanten Teile berührt (Auth, Daten, Integrationen, Performance-Constraints)
Thin Slices verhindern die klassische Falle: zuerst die „einfache" UI bauen und später entdecken, dass Berechtigungen, Datenqualität oder Integrationen den ganzen Plan zerlegen.
3) Eine Architektur-Baseline setzen (leichtgewichtig, explizit)
Vielbeschäftigte Teams brauchen kein 40-seitiges Architekturdokument. Sie brauchen ein paar früh festgehaltene Entscheidungen:
- System-Form (oft ist ein modularer Monolith ein sicherer Default als verfrühte Microservices)
- Integrationsstil (REST, Events, GraphQL wo gerechtfertigt)
- Datenverantwortungs-Grenzen und ein erstes Domänenmodell
- Deployment-Ziel (Cloud-Account-Struktur, Umgebungen)
Erfassen Sie Entscheidungen als kurze ADRs (Architecture Decision Records). Es geht nicht um Perfektion, sondern darum, dieselben Entscheidungen nicht erneut zu verhandeln.
4) Den vertikalen Slice mit echten Quality Gates bauen
Bauen Sie den Thin Slice end-to-end mit produktionsreifer Disziplin, auch wenn der Feature-Scope klein ist. Das heißt:
- Automatisierte Builds und Tests bei jeder Änderung
- Code-Review-Regeln, die PRs klein halten
- Grundlegendes Logging/Metriken/Tracing, damit Sie debuggen können, was Sie ausliefern
Teams verschieben das oft auf „nach dem MVP". In der Praxis erzeugt das Überspringen einen MVP, vor dessen Release man Angst hat.
Wenn Ihr CI/CD aktuell manuell oder fragil ist, nutzen Sie diese praktische Baseline: CI/CD-Technologie.
5) Produktionsreife inkrementell aufbauen (Sicherheit, Zuverlässigkeit, Performance)
Produktionsreife ist keine Schlussphase. Es ist eine Checkliste, die Sie kontinuierlich anwenden, während das System wächst.
Eine pragmatische Baseline für die meisten Web-Systeme:
- Sicherheit: Secrets-Management, Least Privilege, Dependency-Scanning
- Zuverlässigkeit: Timeouts, Retries, Idempotenz für kritische Operationen
- Observability: aussagekräftige Logs und Alerting, gekoppelt an Nutzerwirkung
- Performance: Budgets für Nutzererlebnis und API-Latenz
Für sichere Entwicklungs-Leitlinien ist das NIST Secure Software Development Framework (SSDF) ein guter Referenzpunkt, und für Web-App-Risikomuster bleibt die OWASP Top 10 eine praktische Baseline.
6) Mit reversiblen Releases launchen
Vielbeschäftigte Teams sollten „Big Bang"-Launches vermeiden. Verwenden Sie Release-Taktiken, die den Blast Radius reduzieren:
- Feature Flags für graduellen Rollout
- Canary Releases, wo machbar
- Blue/Green-Deployments für sicherere Cutovers
Das Ziel ist einfach: Sie sollten eine riskante Änderung schnell rückgängig machen können, ohne War Room.
7) Betreiben und iterieren (messen, was passiert ist)
Wenn Sie ausliefern, schließen Sie die Schleife:
- Hat sich die Ergebnis-Metrik bewegt?
- Hat sich die Zuverlässigkeit verändert (Fehler, Latenz, Incidents)?
- Hat sich die Auslieferung verbessert (Lead Time, Frequenz, Failure Rate)?
Hier wird Software bauen zur Fähigkeit, nicht zum Projekt.
Eine Tabelle, die den Prozess konkret hält
Verwenden Sie diese als leichtgewichtige Referenz dafür, wie „fertig" in jeder Phase aussieht.
| Phase | Ziel | Typische Artefakte | Exit-Beleg |
|---|---|---|---|
| Ergebnisse | Auf Wert und Constraints ausrichten | Ergebnis-Brief, Erfolgsmetriken | Stakeholder einig über Erfolg und Trade-offs |
| Thin Slice | Wert belegen und Unbekannte reduzieren | Thin-Slice-Scope, Annahmenliste | Slice umfasst riskante Integrationen/Daten/Berechtigungen |
| Architektur-Baseline | Kernentscheidungen vor Churn schützen | 3 bis 8 ADRs, erstes Domänenmodell | Team kann Systemgrenzen und Datenfluss erklären |
| Bauen | Funktionierende End-to-End-Fähigkeit liefern | PRs, Tests, CI-Pipeline, Umgebungen | Slice läuft in einer produktionsähnlichen Umgebung |
| Produktionsreife | Operatives und Security-Risiko reduzieren | Runbook-Entwurf, Alerts, Performance-Budgets | Messbare SLO-Ziele und Monitoring vorhanden |
| Launch | Sicher releasen | Release-Plan, Rollback-Schritte | Reversibler Rollout (Flag/Canary/Blue-Green) |
| Betreiben und Iterieren | Ergebnisse kontinuierlich verbessern | Metriken-Dashboard, Incident-Notizen | Post-Launch-Lernen fließt in den nächsten Zyklus |
Der Operating-Rhythmus, der vielbeschäftigte Teams in Bewegung hält
Ein Prozess funktioniert nur, wenn er in die Realität von Unterbrechungen, Meetings und sich verschiebenden Prioritäten passt. Ein einfacher Rhythmus, der skaliert:
Wöchentlich: Ergebnis-Review und Re-Plan
Halten Sie eine kurze wöchentliche Session, die beantwortet:
- Was haben wir ausgeliefert?
- Was hat sich dadurch geändert (Metriken, Support-Tickets, Performance)?
- Was ist der nächste hochwertige Slice?
Vermeiden Sie „Status-Theater". Der Output sollten Entscheidungen sein: Trade-offs, De-Scoping, Sequenzierung.
Täglich: Fokus schützen und Arbeit klein halten
Sie brauchen keine langen Standups. Sie brauchen schnelles Alignment:
- Halten Sie Work in Progress niedrig (zu viele parallele Aufgaben erzeugen unsichtbare Verzögerungen).
- Halten Sie PRs klein (große PRs verlangsamen Reviews und erhöhen Defekte).
- Bevorzugen Sie asynchrone Updates, wenn das Team verteilt ist.
Pro Änderung: eine echte Definition of Done
Eine Definition of Done ist nur dann wertvoll, wenn sie vorhersehbares Versagen verhindert. Eine praxistaugliche DoD für die meisten Teams umfasst:
- Tests laufen automatisch in CI
- Linting/Formatierung und grundlegende statische Checks
- Security-Checks passend zu Ihrem Risiko (mindestens Dependency- und Secret-Scanning)
- Observability-Hooks für das neue Verhalten (Log-Events oder Metriken)
Wenn Sie das metriken-getrieben weiterentwickeln wollen, ohne daraus eine Bürokratie zu machen, siehe Code-Quality-Metriken, die zählen.
Häufige Fehlermodi (und wie man sie vermeidet)
Features ausliefern ohne nicht-funktionale Anforderungen
Teams behandeln Sicherheit, Zuverlässigkeit und Performance oft als „später". Später wird zu nie, bis ein Incident einen Rewrite erzwingt.
Fix: Definieren Sie früh ein paar messbare nicht-funktionale Ziele (zum Beispiel Fehlerrate, Latenz, Recovery-Zeit) und tracken Sie sie ab dem ersten Slice.
Discovery, die nie endet
Endlose Workshops fühlen sich sicher an, verzögern aber echte Validierung.
Fix: Timeboxen Sie Discovery und committen Sie sich auf einen Thin Slice, der echte Integration, echte Daten und echte Constraints erzwingt.
Manuelle Deployments und fragile Umgebungen
Wenn jedes Release eine Spezialistin braucht, haben Sie einen Auslieferungs-Engpass.
Fix: Standardisieren Sie eine minimale CI/CD-Pipeline und machen Sie Deployments routinemäßig. Zuverlässigkeit verbessert sich, wenn Releases häufig und langweilig sind.
Große Rewrites zum „Aufräumen"
Rewrites verschlingen Jahre und liefern oft weniger als inkrementelle Modernisierung.
Fix: Modernisieren Sie inkrementell mit sicheren Schnitten, Tests und Observability. (Wenn das Ihre Lage ist, ist Wolf-Techs Leitfaden zur Legacy-Modernisierung eine solide Folgelektüre.)
Ein praxistauglicher 30-Tage-Plan für vielbeschäftigte Teams
Wenn Sie schnell Schwung brauchen, reicht diese 30-Tage-Struktur meist, um einen sichtbaren Schritt nach vorn zu schaffen.
Woche 1: Ausrichten und Auslieferungs-Sicherheit schaffen
Einigen Sie sich auf Ergebnisse und wählen Sie einen Thin Slice. Setzen Sie die Basics auf oder härten Sie sie: Repository-Standards, CI mit Tests und eine deploybare Umgebung.
Woche 2: Den Thin Slice end-to-end bauen
Implementieren Sie den Slice mit echtem Auth, echten Daten und den ersten Integrationspunkten. Halten Sie den Scope eng und bestehen Sie auf einen releasefähigen Pfad.
Woche 3: Produktionsreife dort ergänzen, wo es zählt
Ergänzen Sie die minimale Observability, Alerting und Runbooks, die Sie zum Betrieb des Gebauten brauchen. Adressieren Sie die wichtigsten Security- und Reliability-Risiken, die aufgetaucht sind.
Woche 4: Sicher launchen und lernen
Releasen Sie mit einem reversiblen Ansatz (Feature Flags sind oft am einfachsten). Messen Sie Ergebnis- und Auslieferungsmetriken, dann passen Sie das Backlog an das an, was wirklich passiert ist.
Wenn Sie eine detailliertere, web-app-spezifische Checkliste für diese Phase wollen, nutzen Sie die Schritt-für-Schritt-Checkliste zum Erstellen einer Webanwendung.
Häufig gestellte Fragen
Was genau ist Software bauen? Software bauen ist die fortlaufende Fähigkeit, Geschäftsergebnisse in ausgelieferte, sichere, beobachtbare Software zu überführen – nicht nur Code zu schreiben oder ein einmaliges Projekt abzuschließen.
Wie wähle ich den richtigen Thin Slice? Wählen Sie die kleinste End-to-End-Fähigkeit, die die größten Risiken berührt (Auth, Daten, Integrationen, Performance-Constraints) und ein für den Nutzer sichtbares Ergebnis liefert.
Brauchen vielbeschäftigte Teams wirklich Architekturarbeit vorab? Ja, aber nur eine leichtgewichtige Baseline. Eine Handvoll expliziter Entscheidungen (als kurze ADRs erfasst) verhindert Churn und widersprüchliche Annahmen.
Was sollten wir in CI/CD zuerst automatisieren? Starten Sie mit reproduzierbaren Builds, Tests bei jeder Änderung und automatisiertem Deployment in mindestens eine Umgebung. Ergänzen Sie dann Security- und Quality-Checks inkrementell.
Wie wissen wir, ob unser Prozess besser wird? Tracken Sie ein kleines Set an Auslieferungs- und Reliability-Indikatoren, häufig die DORA-Metriken plus Incident-Rate und kundenbeeinträchtigende Fehler.
Wann sollten wir externe Hilfe holen? Wenn Sie in Auslieferungs-Engpässen feststecken (manuelle Releases, lange Lead Time), eine riskante Modernisierung anstehen oder einen erfahrenen Partner brauchen, um einen Thin-Slice-Bau mit Produktionsreife zu beschleunigen.
Schneller bauen, ohne die Latte zu senken
Wenn Ihr Team ausliefern muss, während es Legacy-Constraints, Wachstumsdruck oder einen komplexen Stack jongliert, kann Wolf-Tech mit Full-Stack-Entwicklung, Code-Quality-Consulting, Legacy-Optimierung, Cloud- und DevOps-Enablement sowie Tech-Stack-Strategie helfen.
Erkunden Sie Wolf-Tech unter wolf-tech.io oder melden Sie sich über die Website, um Ihre Roadmap, Engpässe und den schnellsten sicheren Weg zu messbaren Ergebnissen zu besprechen.