
Apps Technologies: Choosing the Right Stack for Your Use Case


Choosing apps technologies is rarely about finding “the best” framework. It is about picking a stack that makes your specific product easier to ship, safer to change, and cheaper to operate for the next 12 to 36 months.
The trap is treating the stack as a one-time branding decision (“we’re a Rust shop” or “we do microservices”). In real delivery, your stack is a set of trade-offs across performance, hiring, reliability, compliance, and how fast your team can learn in production.
This guide gives you a pragmatic way to choose the right stack for your use case, plus several proven “stack recipes” you can adapt without copying blindly.
Start with the use case, not the tool
Before comparing frameworks, lock down the constraints that actually drive stack fit. For most teams, these five inputs decide 80 percent of the outcome.
1) What kind of app is it (and where does it run)?
“App” can mean:
- A public web app where SEO and first load matter
- A logged-in B2B SaaS dashboard
- A mobile-first consumer product
- An internal tool with lots of forms and workflows
- A real-time collaboration experience
Each pushes you toward different rendering strategies, caching, offline behavior, and deployment targets. If you need a refresher on the moving parts, Wolf-Tech’s deep dive on how web applications work end to end is a good baseline.
2) Your non-functional requirements (NFRs) in measurable terms
If you cannot measure it, you cannot choose for it. Translate “fast” and “reliable” into targets:
- Performance: Core Web Vitals for web (LCP, CLS, INP), p95 API latency
- Reliability: availability target, error budget, RTO/RPO
- Change safety: expected deploy frequency, acceptable change failure rate
- Security and compliance: data classification, audit logging needs, retention
A stack that looks great in a demo can collapse under NFRs once you add auth, caching, observability, migrations, and production traffic.
3) Data shape and integration surface area
Data and integrations often dominate complexity more than UI or language choice:
- Transactional workflows and reporting tend to favor relational databases first
- High fan-out integrations favor clear API boundaries and asynchronous patterns
- Real-time features require careful state and event design
4) Team topology and skills (today, not aspirationally)
A “perfect” architecture that your team cannot operate will lose to a simpler baseline every time. Be honest about:
- What your engineers can debug at 2 a.m.
- What you can hire for in your market
- Whether you have platform or SRE capacity
5) Time horizon and product uncertainty
If your product requirements are still moving, optimize for learning speed and reversible decisions. If you are modernizing a revenue-critical system, optimize for safety and incremental change.
A practical 4-layer model for choosing apps technologies
Most modern app stacks can be evaluated as four layers. This prevents “framework fixation” and keeps decisions comparable.
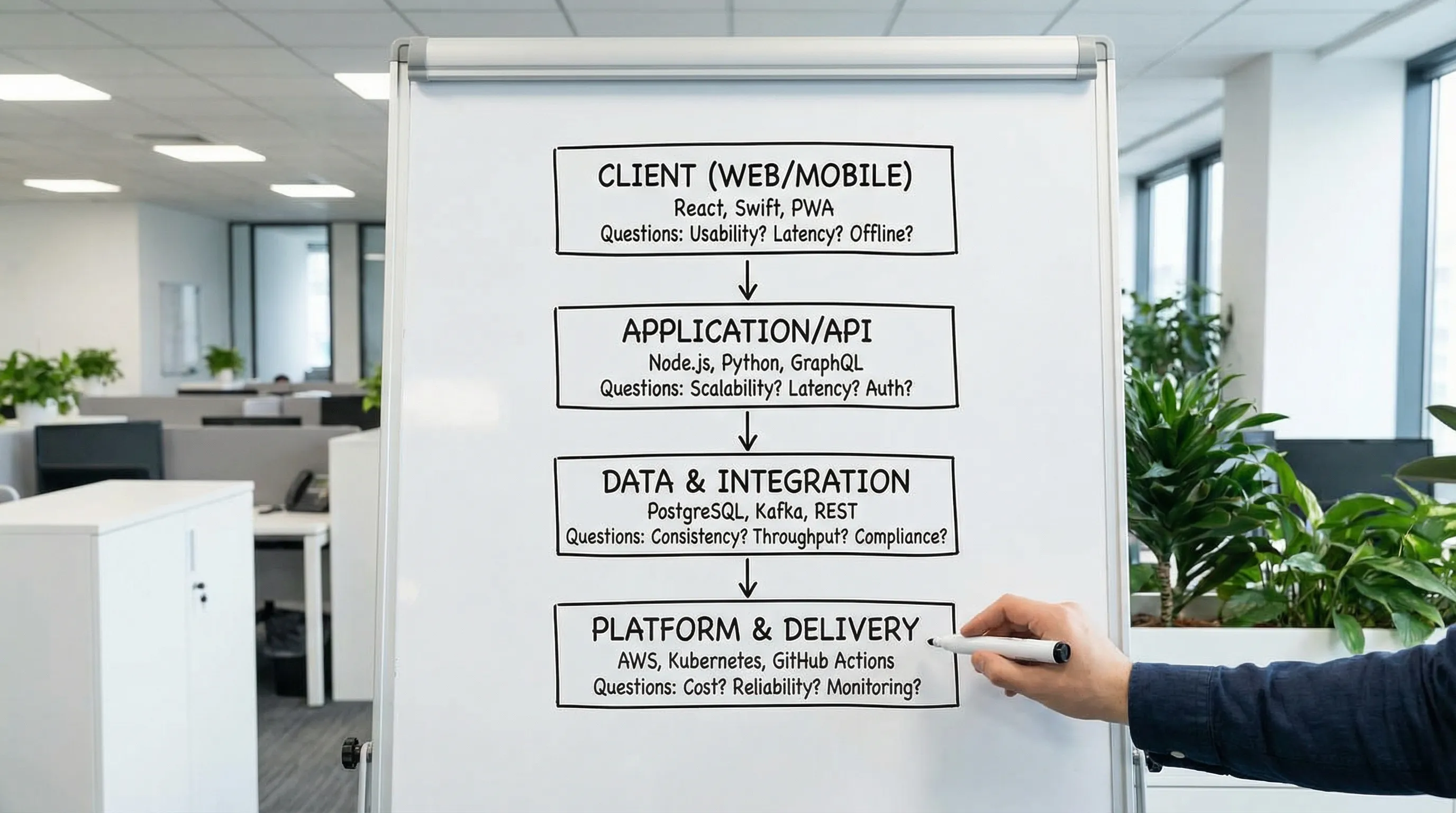
Layer 1: Client and UI delivery
Key questions:
- Do you need SEO, shareable URLs, and fast first paint?
- Is the app mostly authenticated and interactive?
- Do you need offline support or native capabilities?
This is where you decide patterns like MPA vs SPA, SSR vs SSG/ISR, or native vs cross-platform.
Layer 2: Application backend and API style
Key questions:
- Is your domain mostly CRUD, or do you have complex workflows?
- Do you need strong boundary control (BFF, gateway, contracts)?
- Do you need real-time, background jobs, or event processing?
API style is a means, not an identity. REST, GraphQL, and event-driven patterns can all be correct depending on clients, caching, and authorization. (If GraphQL is on the table, be sure you understand the operational pitfalls like query cost and authorization complexity. Wolf-Tech’s GraphQL APIs guide covers the trade-offs.)
Layer 3: Data and integration
Key questions:
- What is your system of record?
- How do you handle schema evolution and migrations safely?
- Do you need search, analytics, or streaming?
A common failure mode is selecting a “cool” database early, then retrofitting transactions, auditability, and reporting later.
Layer 4: Platform, delivery, and operations
Key questions:
- Can you deploy safely and often?
- Do you have baseline observability (logs, metrics, tracing)?
- How do you manage secrets, IAM, and supply-chain security?
This layer is where stacks become real systems. If you are not sure what “good” looks like, Wolf-Tech’s overview of CI/CD technology is a solid reference.
Use a scorecard that forces evidence
To avoid opinion-driven debates, use a simple scorecard that asks for proof. You do not need a heavy procurement process, just enough structure to surface hidden costs.
| Dimension | What “good fit” means | Evidence to collect in a 1-2 week spike |
|---|---|---|
| Delivery speed | Small changes ship predictably | Pipeline runs fast, previews exist, rollback is easy |
| Performance | Meets user-perceived targets | Baseline Core Web Vitals, p95 latency, load test notes |
| Reliability | Failures are contained and recoverable | Timeouts, retries, SLOs, incident drill results |
| Security & compliance | Risks are controllable by default | OWASP-aligned controls, audit logging plan, secrets/IAM approach |
| Data evolution | Schema changes are safe | Migration strategy, backfill approach, versioning rules |
| Team fit | Debuggable by your team | On-call simulation, “new dev” setup time, runbook clarity |
| Cost control | Costs scale predictably | Cost model for compute, database, observability, CI |
| Longevity | Upgrades are feasible | Upgrade cadence, dependency health, LTS posture |
For security baselines, it is reasonable to align with widely accepted guidance like the OWASP Top 10 and modern secure development practices such as the NIST SSDF.
Stack recipes by use case (and why they work)
The goal here is not to prescribe one true stack. It is to show the kinds of combinations that tend to succeed, and the failure modes to watch.
Use case A: Public web app where SEO and performance matter
Typical examples: marketing plus product, content-led acquisition, e-commerce catalogs, documentation sites with logged-in areas.
What matters most:
- Fast initial load, good Core Web Vitals
- Predictable caching and content freshness
- Secure edge boundaries (rate limiting, bot mitigation)
Common technology shape:
- UI: React with a meta-framework that supports SSR/SSG/ISR patterns (for example, Next.js)
- Backend: API routes/BFF plus service layer, or separate backend services
- Data: Postgres for core data, Redis for caching (optional)
- Platform: CDN, edge caching, observability from day one
If Next.js is in your path, performance work is easier when you measure first and treat budgets as part of delivery. Wolf-Tech’s Next.js performance tuning guide goes deep on practical diagnosis.
Common pitfalls:
- Shipping too much client JavaScript and calling it “modern”
- Treating caching as an afterthought, then fighting staleness and TTFB later
- Letting third-party scripts destroy performance without guardrails
Use case B: B2B SaaS dashboard (authenticated, workflow-heavy)
Typical examples: admin consoles, analytics dashboards, operations tools, multi-tenant SaaS.
What matters most:
- Authorization correctness and auditability
- Consistent UI patterns and form reliability
- Safe schema changes and long-term maintainability
Common technology shape:
- UI: React-based SPA or hybrid rendering, strong component conventions
- Backend: A “boring” modular monolith often wins early (clear modules, one deployment, strong tests)
- Data: Relational first (Postgres), with read models for reporting if needed
- Platform: Strong CI/CD, contract testing for integrations, feature flags for safer releases
This is also where architecture review pays off. If you want a concrete lens, Wolf-Tech’s checklist on what a tech expert reviews in your architecture maps well to SaaS realities.
Common pitfalls:
- Underestimating RBAC complexity and tenant isolation
- Building a microservices mesh to “prepare for scale” before you have stable boundaries
- Skipping operability, then discovering you cannot explain production behavior
Use case C: Mobile-first consumer app (native feel, fast iteration)
Typical examples: marketplace, habit apps, consumer fintech, social.
What matters most:
- App store release management and backwards compatibility
- Offline tolerance and flaky network handling
- Analytics and experimentation with privacy in mind
Common technology shape:
- Client: Native iOS/Android, or cross-platform (React Native, Flutter) when team fit and UI needs align
- Backend: Well-versioned APIs, explicit compatibility rules, idempotency
- Data: Relational for transactions, object storage for media
- Platform: Mobile CI, staged rollouts, crash reporting, feature flags
Common pitfalls:
- Treating mobile releases like web deploys (they are not)
- No API versioning strategy, leading to forced upgrades and broken clients
- Missing observability for the “client side” of failures (network, device, OS)
Use case D: Real-time features (collaboration, live updates, chat)
Typical examples: collaborative editing, live dashboards, logistics tracking, chat and presence.
What matters most:
- Predictable latency under load
- Correctness with concurrent updates
- Backpressure and failure containment
Common technology shape:
- Transport: WebSockets or server-sent events where appropriate
- Backend: Event-driven patterns, background workers, careful state management
- Data: A system of record plus a low-latency state store (often Redis), append-only logs for audit when needed
- Platform: Load testing, connection management, observability that can follow events end to end
Common pitfalls:
- “Real-time” implemented as uncontrolled polling
- No strategy for reconnection, ordering, and idempotency
- Scaling connections without thinking about fan-out cost
Use case E: Regulated or high-assurance apps (finance, healthcare, enterprise)
Typical examples: payment flows, risk systems, systems with strict audit requirements.
What matters most:
- Auditability, data lineage, and least-privilege access
- Secure software supply chain and change control
- Reproducible builds and evidence for compliance
Common technology shape:
- Architecture: Fewer moving parts early, explicit boundaries, strong logging and traceability
- Data: Strong transactional guarantees, retention rules, encryption practices
- Delivery: Tight quality gates, dependency scanning, infrastructure as code, controlled rollouts
Common pitfalls:
- Bolting compliance onto a stack not designed to produce evidence
- Overcomplicating architecture before you have operational maturity
- Not planning for data retention, deletion, and audit queries from day one
Monolith, microservices, or serverless: choose based on operating ability
These are architectural choices more than “apps technologies,” but they heavily influence stack selection.
| Approach | When it tends to fit | What teams underestimate |
|---|---|---|
| Modular monolith | Most early-stage products, many SaaS backends, legacy modernization via seams | Module boundaries and dependency discipline |
| Microservices | Clear domain boundaries, multiple teams, independent scaling needs | Operational overhead, distributed debugging, consistency and versioning |
| Serverless | Spiky workloads, event-driven glue, fast experiments | Cold starts, local dev complexity, vendor coupling, observability costs |
A useful rule: if you cannot run excellent CI/CD and observability on a monolith, microservices will not save you. They will amplify your problems.
Validate the stack with a thin vertical slice
The fastest way to choose a stack is to ship a small, production-like slice that forces you to confront reality. This avoids “proof by slide deck.”
Your slice should include:
- One real user journey end to end (UI, auth, API, data write, data read)
- One integration (even a mocked external API with contract tests)
- One migration (schema change) to test your evolution path
- Baseline delivery and safety mechanisms (CI, deployment, rollback)
- Minimal observability (structured logs, key metrics, tracing where possible)
If you want a concrete delivery checklist for that approach, Wolf-Tech’s MVP checklist for faster launches aligns well with stack validation.
What to measure during validation
Pick a few metrics that map directly to your use case. For example:
- Web: Core Web Vitals, TTFB, p95 route latency
- Backend: p95 latency per endpoint, error rate, saturation signals
- Delivery: lead time for change, deploy frequency, change failure rate, MTTR (the core DORA metrics are a common baseline, see the DORA research program)
The point is not to hit perfect numbers in week one. It is to prove you can instrument, improve, and avoid regressions.
Design for optionality (so your stack can evolve)
Stacks fail when teams lock in by accident. You can preserve flexibility without slowing down.
Keep boundaries explicit
- Use well-defined API contracts between UI and backend
- Separate domain code from frameworks where practical
- Document major decisions with lightweight Architecture Decision Records (ADRs)
Prefer open interfaces at integration points
- HTTP, OAuth/OIDC, S3-compatible object storage patterns, SQL where it fits
- Event formats that are versioned and documented
Build an exit ramp for legacy and future changes
If you are modernizing, favor incremental patterns (strangler-style changes, feature flags, canaries) over big rewrites. Wolf-Tech’s guidance on modernizing legacy systems without disrupting business shows how to keep change reversible.
A quick “stack fit” checklist for decision meetings
Use this when you need to converge with stakeholders (product, engineering, security).
- Can we ship a thin vertical slice to production in this stack within 2 to 4 weeks?
- Do we have a clear baseline for performance, reliability, and security?
- What is our plan for schema changes, backfills, and data migration safety?
- How will we do auth, roles/permissions, and audit logs?
- What does “debugging in production” look like (logs, metrics, traces, runbooks)?
- Can we hire, onboard, and maintain this stack for at least 2 years?
- Which decisions are reversible, and what would it cost to reverse them?
If you cannot answer these, you do not yet have a stack decision, you have a preference.
Where Wolf-Tech can help
If you are choosing apps technologies for a new build, scaling an existing product, or modernizing legacy code, the fastest path is usually an evidence-driven assessment plus a thin-slice implementation plan.
Wolf-Tech supports teams with full-stack development, tech stack strategy, legacy code optimization, code quality consulting, and cloud and DevOps guidance, with a focus on measurable outcomes and safe delivery.
If you want a second opinion on your shortlist, or you need a practical plan to validate it quickly, start with an architecture review or a short discovery that produces a stack scorecard, risks, and a step-by-step pilot scope.