
Custom Software Development: Scope, SLAs, and Proof


Buying custom software development services is less about “features per sprint” and more about buying a delivery system you can trust. The fastest way to reduce risk is to make three things explicit, in writing, before work starts:
- Scope (what “done” means and what it does not mean)
- SLAs/SLOs (how reliability, support, and response will be measured)
- Proof (evidence that the vendor can deliver what they promise)
This guide gives you a practical, contract-friendly way to define scope, set realistic service levels, and ask for the right proofs before you sign.
1) Scope: what you are really buying
Scope is not a feature list. A feature list is a backlog, and backlogs change. A usable scope defines the system boundaries, measurable outcomes, constraints, and acceptance proofs.
A strong scope package typically answers:
- What outcome are we targeting? (revenue, cost, risk, time saved)
- What is in and out? (boundaries and integrations)
- What must be true in production? (non-functional requirements)
- What artifacts will exist at each milestone? (deliverables)
- How do we accept work? (tests, demos, environments, criteria)
- Who owns which decisions and operational work? (RACI-style clarity)
If you want a deeper template for kickoff deliverables, Wolf-Tech’s guide on software project kickoff scope, risks, and success metrics pairs well with the scope model below.
The “scope surface area” most contracts miss
Teams often agree on UI screens and user stories, but fail to scope the parts that create cost and schedule surprises. These areas should be explicitly addressed:
- Integrations and data contracts (APIs, webhooks, file exchanges, rate limits)
- Identity and authorization (SSO, RBAC, tenant model, auditability)
- Environments (dev, staging, production, preview apps, data strategy)
- Security and compliance obligations (threat model, logging, retention)
- Operational readiness (monitoring, alerting, runbooks, on-call)
- Migration (data backfill, dual-run, cutover, rollback)
- Performance and reliability requirements (p95 latency targets, uptime)
For web apps specifically, you can cross-check your scope against the core system components described in Web Application: What Is It and How Does It Work? without turning your contract into an architecture textbook.
A scope checklist that maps to real deliverables
Use the table below to make scope measurable. You do not need every artifact on day one, but you want agreement on what will be produced and when.
| Scope area | What to clarify (buyer questions) | Concrete deliverables (proof of scope) |
|---|---|---|
| Outcomes and constraints | What changes in the business? What is the budget and timebox? What cannot break? | One-page outcome brief, success metrics, constraint list |
| System boundaries | What is the product responsible for vs external systems? | Context diagram, boundary list, integration inventory |
| Functional scope (thin slice first) | What is the smallest end-to-end flow that proves value in production? | Thin vertical slice plan, prioritized backlog, acceptance criteria |
| Non-functional requirements (NFRs) | What are the performance, reliability, and security targets? | NFR spec, performance budget, availability target, risk register |
| Data and reporting | What data is authoritative? How is data accessed, retained, and audited? | Data model sketch, migration plan, reporting requirements |
| Delivery and governance | How do changes ship? Who decides? How do we handle change requests? | Delivery cadence, Definition of Done, change control process |
| Quality and testing | What types of tests are required and where do they run? | Test strategy, CI quality gates, test reports, regression plan |
| Operations | Who is on call? How do incidents work? What is monitored? | Monitoring plan, alert thresholds, runbooks, incident process |
| Ownership and access | Who owns IP? Who has repo access? What happens if the engagement ends? | IP clause, access list, handover plan |
A practical way to reduce disagreement is to define “done” at multiple levels (story, feature, release, production readiness). Wolf-Tech’s article on custom software services defaults is a useful baseline for what “professional by default” often includes.
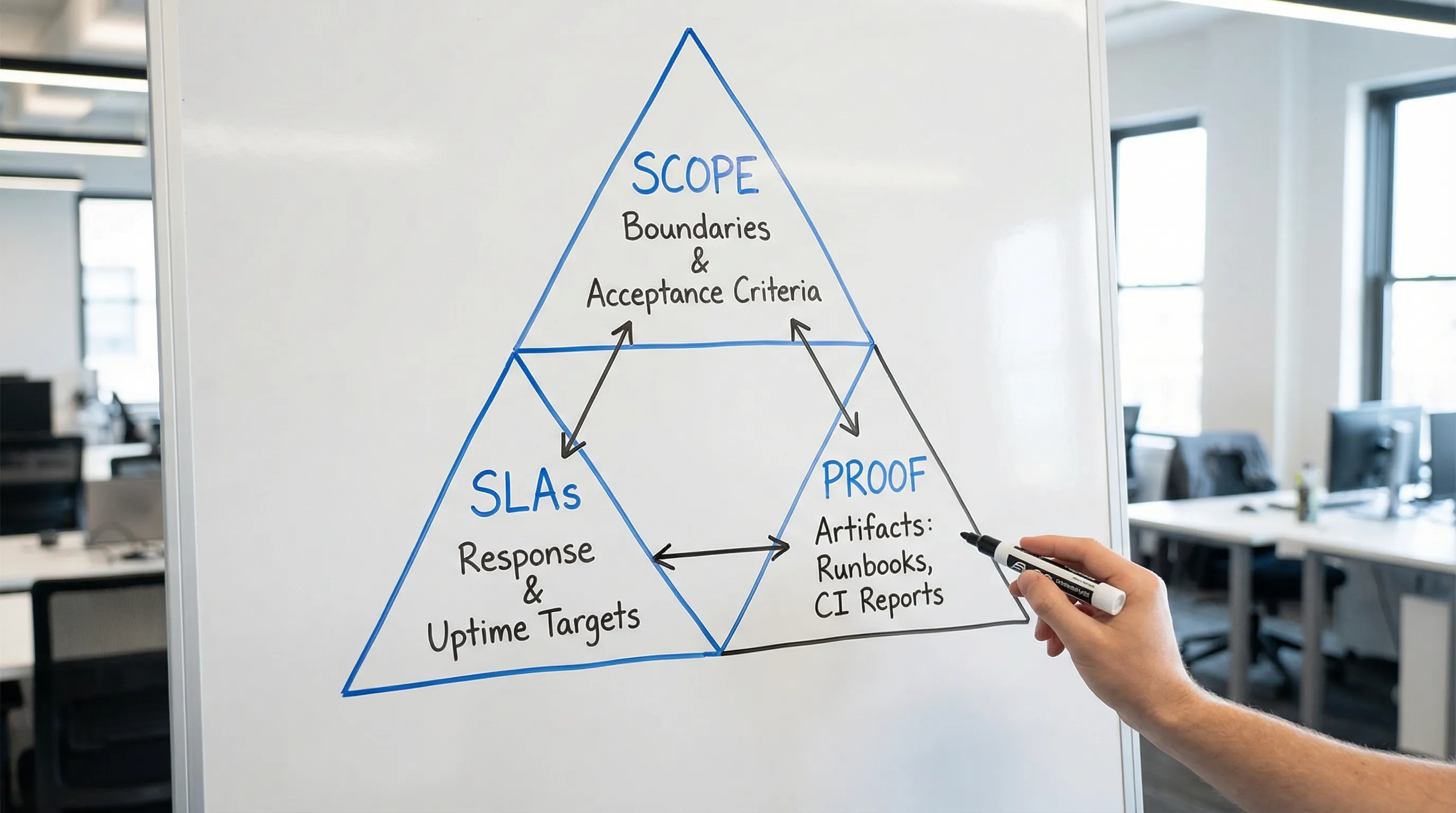
2) SLAs and SLOs: set expectations that match reality
Teams often ask for an SLA because it feels like “safety.” But there are two related concepts that are frequently mixed up:
- SLA (Service Level Agreement): a contractual commitment (often tied to remedies) about support and service.
- SLO (Service Level Objective): an internal or shared reliability target that guides engineering and operations.
A helpful, widely used model comes from Google’s SRE practice, which explains why clear objectives and error budgets drive better reliability decisions than vague uptime promises. See Google’s free Site Reliability Engineering book for background.
What should SLAs cover in custom software development services?
SLAs matter most when your vendor is responsible for production support, operations, or a managed service, not just feature delivery.
If your engagement includes post-launch support, an SLA section typically defines:
- Support hours and channels (business hours vs 24/7)
- Severity levels (what counts as Sev1, Sev2, Sev3)
- Response time and restore targets (acknowledge, mitigate, resolve)
- Escalation path (who gets paged when)
- Availability scope (which components are included, which dependencies are excluded)
- Maintenance windows (how planned downtime is handled)
- Measurement method (how uptime is calculated, what monitoring is authoritative)
Example SLA structure (adapt, do not copy blindly)
The numbers below are not universal “best practice.” They are a starting point to force clarity. Your targets should reflect business impact, user expectations, and architecture constraints.
| Severity | Example definition | Response target | Restore/mitigate target | Communication cadence |
|---|---|---|---|---|
| Sev1 | Production outage, critical user flow blocked, major security incident | 15 to 30 minutes | 4 to 8 hours (mitigation) | Every 30 to 60 minutes |
| Sev2 | Degraded service, workaround exists, significant subset impacted | 1 to 2 hours | 1 to 3 business days | Daily until stable |
| Sev3 | Minor defect, limited impact | 1 to 3 business days | Planned in backlog | Weekly status |
Key nuance: SLAs should define what the vendor controls. If availability depends on third-party services, you need explicit dependency mapping and an agreed incident protocol.
Reliability targets: pick a small set of measurable SLOs
Instead of a single uptime number, define the user experience you are protecting. Common examples:
| SLO category | Example SLI (what you measure) | Example objective |
|---|---|---|
| Availability | Successful requests / total requests (per endpoint) | 99.9% monthly for core APIs |
| Latency | p95 response time for key endpoints | p95 under 300 ms for read APIs |
| Data freshness | Time from event to visible state | Under 60 seconds for critical updates |
| Change safety | Change failure rate, rollback rate | Less than X% failed changes |
| Recovery | Mean time to restore (MTTR) | Under Y minutes for Sev1 |
For delivery performance and change safety, many teams track DORA metrics (deploy frequency, lead time for changes, change failure rate, time to restore). These are usually best treated as transparency metrics, not strict contractual SLAs. If you want background, the DORA research is a solid reference.
3) Proof: what to ask for before you sign
“Trust me” is not a delivery strategy. Proof is how you validate that a vendor’s process is real, repeatable, and compatible with your risk profile.
The goal is not paperwork. The goal is evidence that the team can:
- ship changes safely,
- operate what they ship,
- and transfer ownership cleanly.
A proof matrix you can reuse in vendor evaluations
| Vendor claim | What “proof” looks like | What you should watch for |
|---|---|---|
| “We ship reliably.” | CI/CD pipeline walkthrough, release checklist, rollback strategy, recent release notes | Manual deployments, no rollback plan, “it depends” answers |
| “We build secure systems.” | Threat model example, secure coding baseline, dependency scanning approach, incident playbook | Security as a final phase, no supply-chain story |
| “We write maintainable code.” | Repo sample, architecture decision records (ADRs), code review standards, modular boundaries | “Rockstar” dependence, no conventions, no refactoring strategy |
| “We test properly.” | Test pyramid approach, examples of integration/contract tests, flake management | Only unit tests, no integration validation, brittle E2E suite |
| “We can run production.” | Observability approach (logs, metrics, traces), on-call policy, runbooks, postmortem template | No alert hygiene, no ownership, no incident learning loop |
| “You will own the product.” | IP terms, repo access, documentation plan, handover checklist | Vendor-controlled environments, missing access, vague ownership |
If you need a buyer-focused flow for vendor selection, Wolf-Tech’s how to vet custom software development companies offers a structured framework and the idea of a short paid pilot.
The highest-signal “proof” is a timeboxed pilot
If the project is meaningful, do not start with a long contract and a vague roadmap. Start with a small engagement designed to produce evidence.
A good pilot is typically 2 to 4 weeks and ends with a decision based on outputs like:
- a thin vertical slice plan (or an actual thin slice in a sandbox),
- integration and data risks surfaced early,
- an architecture baseline that matches constraints,
- a working delivery loop (repo, CI, environments),
- and a realistic roadmap with risks and mitigation owners.
Wolf-Tech covers this “thin slice first” approach across multiple guides, including custom web application development services: what to expect and the broader custom software application development end-to-end guide.
4) Common contract traps (and how to avoid them)
Most failed engagements fail predictably. Here are recurring traps tied specifically to scope, SLAs, and proof.
Trap 1: “Agile” used as an excuse for undefined acceptance
Agile does not mean “undefined.” It means you discover and adjust while still holding quality and outcomes constant.
Fix: insist on acceptance criteria at the story/feature level and a shared Definition of Done that includes testing and production readiness.
Trap 2: NFRs treated as optional
Performance, security, and operability are not polish. They are product requirements.
Fix: define a small set of measurable NFRs early. If you need help choosing what matters in your context, Wolf-Tech’s capability-first approach in web development technologies: what matters in 2026 shows how to anchor decisions in measurable constraints.
Trap 3: Availability promises without measurement clarity
“99.9% uptime” is meaningless if nobody agrees on:
- what counts as downtime,
- what monitoring source is authoritative,
- which components are included,
- how maintenance windows are treated.
Fix: define SLIs and measurement methods. This is basic SRE hygiene.
Trap 4: “Support” that is really just best-effort email
Fix: define severity levels, response targets, escalation, and incident communications. Make ownership explicit.
Trap 5: Proof that cannot be independently verified
Slide decks do not run production.
Fix: ask for artifacts you can inspect (redacted if necessary), and require operational readiness deliverables (runbooks, alerts, dashboards) when the vendor touches production.
5) A practical way to package scope + SLAs + proof into an SOW
If you want a contract that stays useful after week two, structure it in layers:
Layer A: Outcome and boundaries (stable)
This section changes rarely and anchors everything else.
- Outcomes and success metrics
- In-scope and out-of-scope boundaries
- Named constraints (compliance, deadlines, legacy constraints)
Layer B: Delivery approach and governance (semi-stable)
- Milestones and phase deliverables (discovery, slice, MVP, hardening)
- Cadence and decision rights
- Change control process (how backlog changes affect cost and timeline)
Layer C: Quality, security, and operations (must be explicit)
- Testing and quality gates
- Security baseline and responsibilities
- Observability and incident management
- SLAs for support (if included)
Layer D: Proof and acceptance (how you avoid arguments)
- Artifact list and where they live (repo, docs)
- Acceptance criteria per milestone
- Handover and ownership (access, credentials, IP)
This format keeps the “why” stable while allowing the “what” to evolve without collapsing into ambiguity.

Frequently Asked Questions
Are SLAs necessary for custom software development services? SLAs are most important when the vendor provides production support or operates the system. If the engagement is build-only, focus more on acceptance criteria, quality gates, and handover proofs.
What is the difference between an SLA and an SLO? An SLA is a contractual commitment about service levels (often tied to remedies). An SLO is a measurable reliability target used to manage engineering and operational trade-offs.
How do I prevent scope creep without blocking iteration? Define stable boundaries and outcomes, then treat the backlog as changeable within a clear change-control process. Require acceptance criteria and a Definition of Done so iteration stays measurable.
What proof should I request from a software vendor? Ask for inspectable artifacts such as CI/CD pipeline evidence, testing strategy and reports, security baseline (and how dependencies are handled), observability/runbooks, and examples of decision records or postmortems.
Should DORA metrics be part of the contract? Usually they are better as transparency and continuous improvement metrics rather than contractual penalties. They work best when both sides use them to spot bottlenecks and improve delivery safety.
Talk to Wolf-Tech about your scope, SLAs, or vendor proofs
If you are reviewing proposals or preparing a statement of work, Wolf-Tech can help you pressure-test scope boundaries, define measurable NFRs and service levels, and identify the proofs that de-risk delivery.
Explore Wolf-Tech at wolf-tech.io or start with these related guides: