
Development Application Roadmap: From MVP to Scale


Most “roadmaps” fail for one simple reason: they list features, not proofs. An application that feels great in a demo can still collapse under real traffic, real data, and real change. A useful development application roadmap is a sequence of stages where each stage reduces a specific kind of risk (value, usability, feasibility, operability), and leaves behind artifacts that make the next stage cheaper.
This guide lays out a practical path from MVP to scale, with the deliverables and metrics that matter when you want to ship fast without painting yourself into a corner.
What “MVP to scale” actually changes
Your application’s needs change in predictable ways as it grows:
- In the MVP stage, the biggest risk is building the wrong thing, or building the right thing in a way that cannot be shipped safely.
- In the growth stage, the biggest risk becomes regressions, reliability incidents, and teams slowing down due to coordination.
- In the scale stage, the risks shift again to cost control, governance, security posture, and predictable operations across multiple teams.
A roadmap that ignores these risk shifts usually over-invests early (gold-plating infrastructure) or under-invests early (skipping delivery and ops basics, then paying later).
The roadmap as stages and “proof gates”
Think of this roadmap as five stages. You do not need to perfectly “finish” a stage before starting the next, but you do want proof gates that prevent you from scaling chaos.
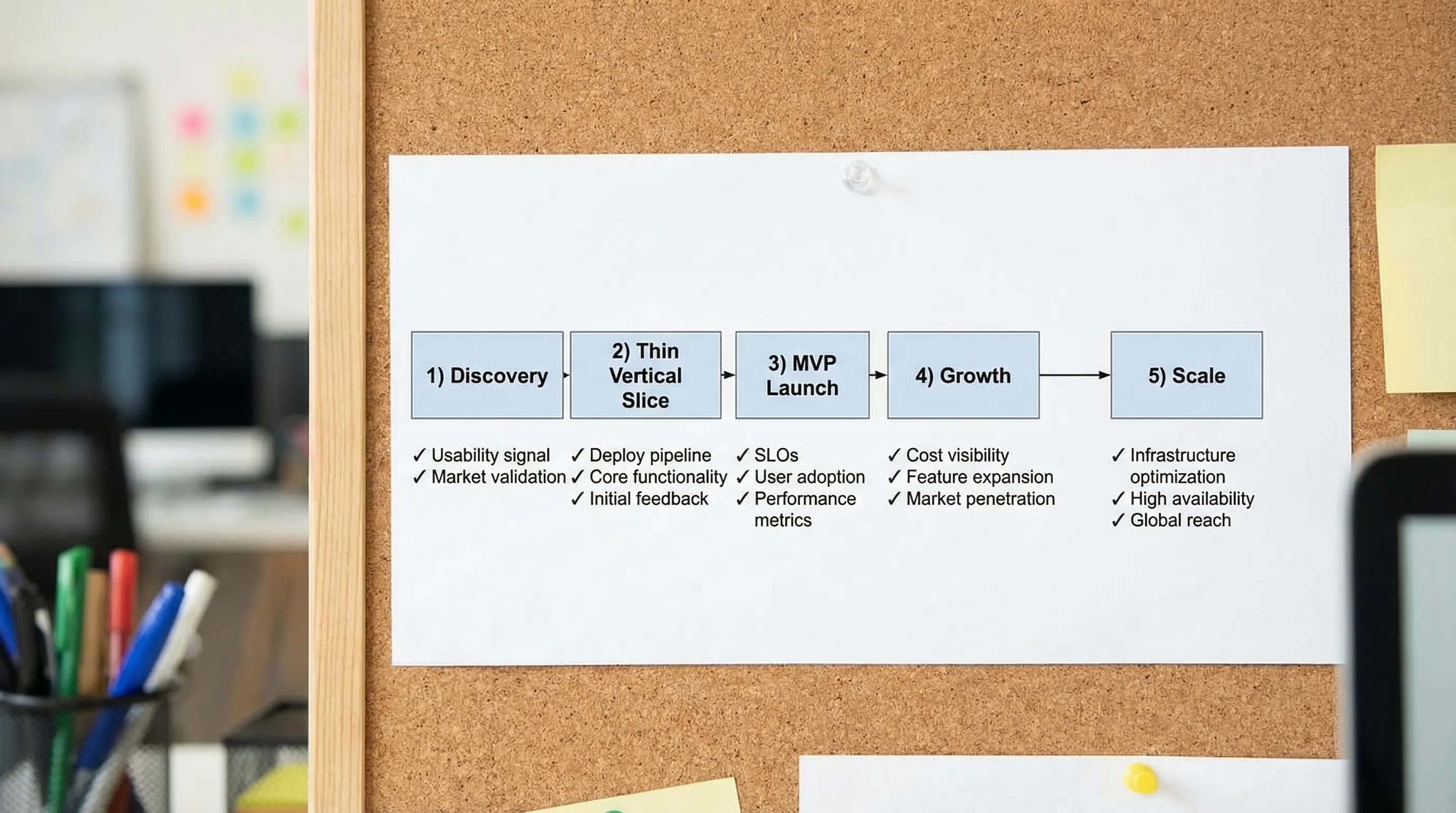
Roadmap overview (what to produce, and what to measure)
| Stage | Primary goal | Proof gate (what must be true) | Key artifacts (minimum) | Metrics to watch |
|---|---|---|---|---|
| Discovery | Align on outcomes, constraints, and scope boundaries | You can explain the “why now” and who it is for, in one page | Outcome brief, scope boundaries, risk list, initial NFR targets | Interview signal, time-to-first-usable prototype (if relevant) |
| Thin Vertical Slice | Prove end-to-end feasibility and operability | A real slice runs in a real environment with telemetry | Repo baseline, CI/CD, auth skeleton, one vertical flow, logging/metrics/tracing | Lead time, deploy success rate, p95 latency baseline |
| MVP Launch | Ship a minimal product that can be operated safely | Rollback works, incidents are triaged, user feedback loop exists | Runbook, alerts, dashboards, support workflow, security baseline | Activation/retention proxy, error rate, MTTR |
| Growth | Increase delivery throughput without breaking reliability | Teams ship weekly (or faster) with stable change failure rate | Modularization plan, contract discipline, feature flags, test strategy | DORA metrics, SLO compliance, cost per active user |
| Scale | Multi-team autonomy with governance and cost control | Teams can change safely without central bottlenecks | Paved path platform, standards + exceptions, audit evidence, DR plan | Error budgets, incident frequency, cloud unit economics |
If you want a deeper lifecycle view from discovery through launch, Wolf-Tech’s guide on custom application development from discovery to launch complements this roadmap. Here, we focus on how to evolve the application once “MVP” becomes “a real system.”
Stage 1: Discovery that is actually usable by engineering
Discovery is not about writing a long PRD. It is about creating decision-ready inputs so engineering can slice a build that has a chance to succeed.
The best discovery packages tend to be short, explicit, and testable.
Minimum discovery deliverables
- One-page outcomes brief: target users, the job-to-be-done, success metrics, and constraints (timeline, budget, regulatory exposure, integrations).
- Scope boundaries: what is in, what is explicitly out, and what “later” means.
- Non-functional requirements (NFRs) targets: initial performance, reliability, privacy/security, and data retention assumptions.
- Risk register: top risks with mitigation owners (especially around data and integrations).
If UX is involved, align UX and architecture early so that latency expectations, offline behavior, collaboration patterns, and permissions are not “surprises” later. Wolf-Tech calls this alignment loop the UX to architecture handshake.
Common failure mode
Teams treat discovery as “feature shopping” and postpone hard decisions (identity, data model, integrations). The result is an MVP that looks complete but is structurally expensive to change.
Stage 2: Thin Vertical Slice (the fastest way to de-risk)
A thin vertical slice is not a prototype. It is a production-shaped end-to-end flow that proves you can:
- Build and deploy reliably
- Integrate with the riskiest dependency
- Handle real auth and permissions
- Observe behavior in an environment that resembles production
This is the point where “application development” becomes a delivery system, not a code exercise.
What to include in the slice
Pick one user journey that forces real decisions. For example: “Create account, perform one core action, see the result, and receive a notification.”
Your slice should include:
- Identity: authentication, authorization, roles, and tenant boundaries if applicable
- Data: one real schema path, migrations, seed strategy
- API contract: versioning approach and error model
- Delivery: CI pipeline, automated deploy to a non-prod environment
- Observability: structured logs, basic metrics, tracing for the flow
For teams selecting stacks during this stage, keep the evaluation grounded in your next 12 to 36 months and validate with a thin slice. Wolf-Tech’s apps technologies stack guide shows a practical way to do that.
Proof gate: “We can ship and see what happened”
If you cannot deploy the slice repeatedly with confidence, do not scale feature work yet. You will just scale uncertainty.
A useful baseline is to start measuring delivery with the DORA metrics (lead time, deploy frequency, change failure rate, time to restore). The underlying research is maintained by the DORA program.
Stage 3: MVP launch as a reversible risk event
“MVP launch” is where many teams discover that they built an app, but not an operable system.
Your launch gate should focus on reversibility and supportability, not “more features.”
Launch readiness, minimum viable (but real)
Aim for:
- Rollback and progressive rollout: you can deploy and undo safely (feature flags, canary, or blue/green depending on your setup)
- Incident loop: on-call ownership, severity definitions, and a place to capture learning (even if it is lightweight)
- Data safety: backups tested, migration safety rules, basic audit trails where required
- Security baseline: vulnerability scanning, secrets handling, least privilege, and a plan to address OWASP-class risks
If you need a practical security starting point, the OWASP Top 10 is a good baseline for web applications, especially for avoiding common classes like broken access control and injection.
MVP metrics that are worth instrumenting early
Do not instrument everything. Instrument what changes decisions:
- Activation proxy: what action tells you a user got value (not just sign-up)
- Time-to-value: how long from first touch to successful core action
- Reliability signals: error rate and p95 latency for the core flow
- Support load: number of support contacts per active user
This is where many teams start defining service level objectives (SLOs), even if the first version is simple. Google’s Site Reliability Engineering book remains a strong reference for this mindset.
Stage 4: Growth, keeping speed while adding safety
Growth is where success creates pressure. More users, more data, more edge cases, more engineers touching the code.
The roadmap here should prioritize work that keeps change cheap:
1) Architecture that scales change, not just traffic
Traffic scale is often solved with caching, indexing, and capacity. Change scale is harder.
A pragmatic default for many products is to start with a modular monolith, then extract when the seams are real. If you are debating architectures, Wolf-Tech’s guide on when to go modular monolith first lays out high-signal decision criteria.
What “good” looks like in growth:
- Clear module boundaries (by business capability, not technical layer)
- Explicit API and data contracts (internal or external)
- Background work moved off the request path (queues, async jobs)
- A disciplined approach to schema changes (expand and contract migrations)
2) Delivery mechanics that prevent regression
In growth, your biggest hidden cost is rework caused by unsafe changes.
Invest in:
- CI that runs fast and is trusted
- A test strategy with a small number of high-signal tests (component tests plus a few end-to-end tests for critical paths)
- Preview environments for PR validation (when feasible)
- Feature flags for controlled rollout
If CI/CD is a bottleneck, address it explicitly. Wolf-Tech’s CI/CD technology guide provides a pragmatic adoption plan.
3) Operability as a product feature
As you grow, you should stop treating logs and dashboards as an afterthought. The goal is faster diagnosis and safer change.
At minimum, standardize:
- A request correlation strategy (trace IDs)
- A small set of “golden signals” dashboards (latency, traffic, errors, saturation)
- Alert thresholds tied to user impact
- A runbook for the most common failure modes
For reliability-focused engineering practices, Wolf-Tech’s backend reliability best practices is a strong next read.
Growth-stage anti-patterns
- “We will add monitoring later.” Later arrives as an outage.
- “Let’s do microservices to scale.” You often scale coordination cost first.
- “We just need more developers.” Without boundaries and delivery discipline, you just get more merge conflicts and incidents.
Stage 5: Scale, multi-team autonomy and governance
Scale is not just more load. It is more teams, more parallel workstreams, more compliance surface area, and more cost sensitivity.
Your roadmap should shift toward standardization of cross-cutting concerns, while still allowing teams to move.
What to standardize first (high leverage)
Standardize what reduces coordination cost and production risk across teams:
- Identity and access patterns
- Contract discipline for APIs and events
- Environment promotion and release mechanics
- Observability conventions (naming, dashboards, alerts)
- Security baseline and supply chain controls
This is aligned with Wolf-Tech’s broader guidance on what to standardize first.
“Paved path” platform thinking
At scale, internal platforms work best when they are treated as products. The paved path should make the right thing the easiest thing:
- A template for services/apps with CI/CD, security checks, and observability baked in
- Self-service environments (or at least self-service deploy)
- Shared libraries for contracts, auth, and telemetry that are versioned and governed
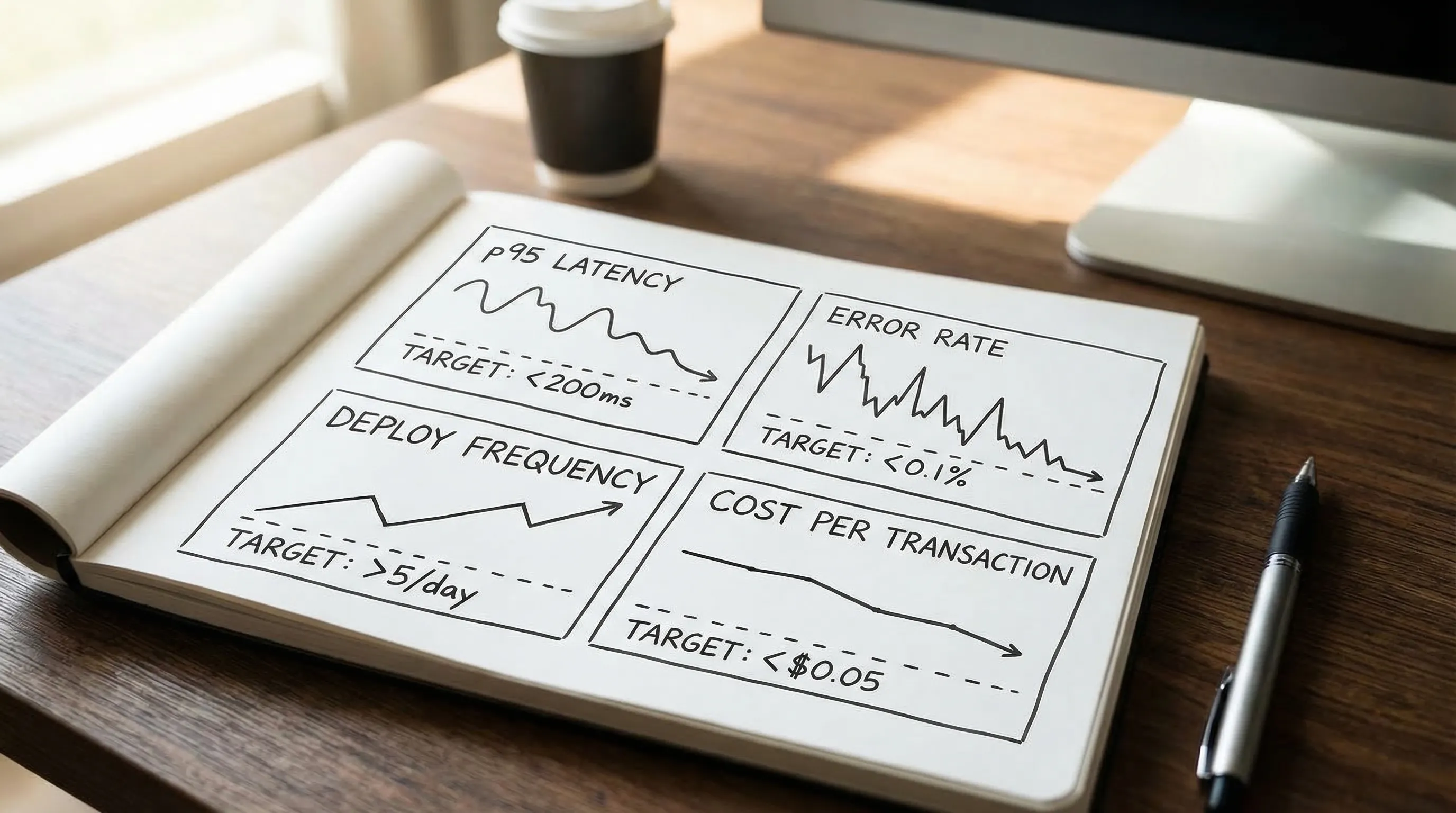
Cost and performance become first-class
As usage grows, you need unit economics and performance budgets, not just “it seems fine.”
A practical scale dashboard often includes:
- Cost per active customer, tenant, or transaction
- p95 and p99 latency for the critical flows
- Data growth rate and storage cost trend
- Queue lag / background job delay (if applicable)
When to introduce “scaling” techniques (without premature complexity)
Many teams ask, “When do we need microservices?” The more actionable question is, “Which constraint are we hitting?”
Use constraints to pick techniques:
| Constraint you are hitting | Typical symptoms | High-leverage first moves | What to avoid early |
|---|---|---|---|
| Database bottlenecks | p95 spikes, lock contention, slow queries | Indexing, query shaping, read replicas, caching, async write paths | Sharding as a first reaction |
| Slow releases | Big PRs, flaky tests, long QA cycles | Trunk-based flow, smaller slices, preview envs, feature flags | A “release train” that bundles everything |
| Fragile integrations | Incidents after partner changes | Contract tests, timeouts/retries, idempotency, circuit breakers | Tight coupling and implicit payload assumptions |
| Team coordination overhead | Dependency gridlock, unclear ownership | Modular boundaries, explicit contracts, ownership map | Splitting into services without boundaries |
| Cost blowups | Cloud spend grows faster than usage | Budget alerts, right-sizing, caching discipline, cost per unit metrics | Optimizing cost without product-level unit metrics |
If you do end up adopting multiple services, treat it as an operating model change (observability, deployments, ownership), not just a code refactor.
A practical 90-day plan: MVP to scale readiness
If you need a concrete starting plan, here is a simple 90-day sequence that fits many teams.
Days 0 to 30: Make shipping safe
Focus: delivery and feedback loops.
- Establish CI, automated deploy, and a repeatable release
- Build one thin vertical slice through the riskiest path
- Add baseline telemetry (logs, metrics, tracing) for the slice
- Define a minimal Definition of Done that includes operability
Days 31 to 60: Make production predictable
Focus: reliability, reversibility, and supportability.
- Add progressive delivery (feature flags, canary, or equivalent)
- Define first SLOs for the core flow and alert on user impact
- Create a runbook and an incident review habit
- Harden data migration and backup/restore testing
Days 61 to 90: Make growth cheaper
Focus: boundaries and throughput.
- Modularize by business capability, enforce basic dependency rules
- Introduce contract discipline (schemas, versioning, contract tests)
- Add performance budgets for critical pages/APIs
- Track DORA metrics and set improvement targets
This plan pairs well with Wolf-Tech’s broader perspective in developing software solutions that actually scale.
Where Wolf-Tech can help (without locking you in)
If you are building a new application or trying to evolve an MVP that is starting to creak, Wolf-Tech helps teams with:
- Full-stack development for custom applications
- Code quality consulting and legacy code optimization
- Architecture and tech stack strategy for the next 12 to 36 months
- Cloud, DevOps, database, and API solutions for scale readiness
If you want a second set of senior eyes on your roadmap, the fastest path is usually a focused review of your outcomes, NFRs, thin-slice plan, and delivery system. You can reach Wolf-Tech via the main site at wolf-tech.io.