
Custom Application Development: From Discovery to Launch


Custom application development has never been “just building features.” In 2026, most teams are shipping into complex reality: identity and permissions, data migrations, third-party integrations, security requirements, performance expectations, and ongoing operations.
The difference between an app that quietly becomes core business infrastructure and one that becomes an expensive rewrite is usually not a single technology choice. It is the end-to-end process from discovery to launch, including what you prove (with evidence) before you scale.
This guide breaks that lifecycle down into practical phases, with clear deliverables and exit criteria you can use whether you are building in-house, outsourcing, or running a hybrid team.
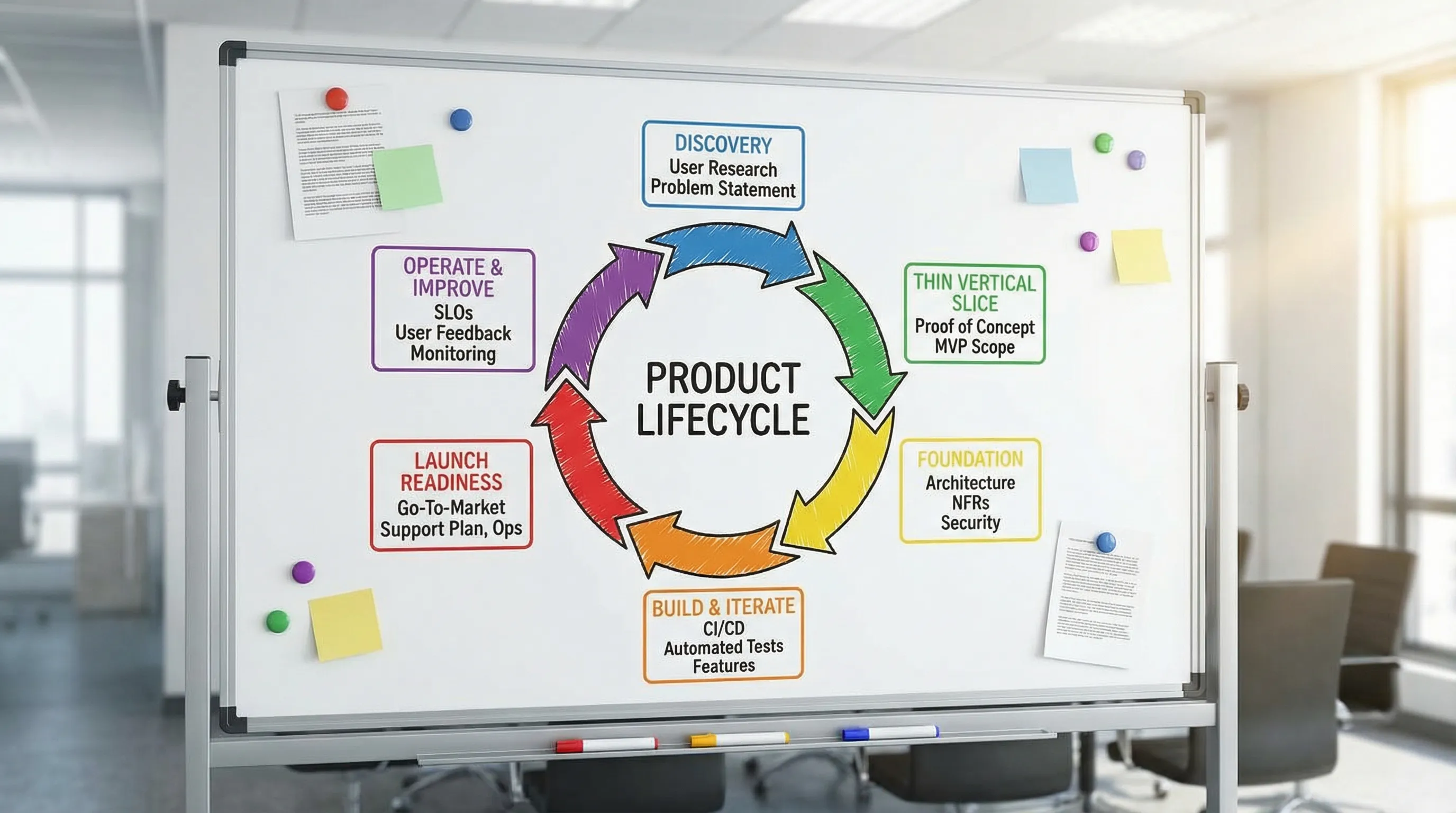
What “custom application development” should deliver (beyond code)
A custom application is an investment in a capability your business either cannot buy or cannot safely adopt off-the-shelf.
So the real deliverable is not a repository, it is:
- A measurable outcome (revenue, cost reduction, cycle-time reduction, risk reduction, retention)
- A production-grade system (secure, observable, operable, maintainable)
- A change system (CI/CD, quality gates, and a delivery rhythm that keeps improving the product after launch)
If you only optimize for shipping “an MVP,” you often get a demo that cannot be operated safely. If you only optimize for “enterprise-grade,” you often get analysis paralysis. The goal is to earn proofs in the right order.
Phase 1: Discovery that prevents rework
Discovery is where teams either buy themselves speed or buy themselves rework.
High-signal discovery focuses on workflows, constraints, and decision-grade clarity, not feature lists.
What to align in discovery
Outcomes and decision rules
Define what success looks like, and how you will decide to continue, pivot, or stop.
Users, workflows, and data reality
Map the real workflow end-to-end, including edge cases (approvals, exceptions, missing data, stale data, permissions).
Non-functional requirements (NFRs)
Write measurable targets for:
- Performance (latency, throughput, batch windows)
- Reliability (availability target, error budget, recovery expectations)
- Security and compliance (data classification, audit needs, retention)
- Operability (on-call needs, alerting, support model)
Integrations and contracts
List every upstream/downstream dependency and identify which ones are risky (rate limits, inconsistent data, brittle APIs).
A practical pattern is to explicitly run the “UX to architecture handshake” early, so the desired experience and system constraints are negotiated before build time. Wolf-Tech has a deeper guide on this alignment loop here: UX to architecture handshake.
Discovery deliverables you can hold a team accountable to
| Discovery artifact | What it’s for | What “good” looks like |
|---|---|---|
| Outcome brief | Align stakeholders on why you are building | 1 page with measurable KPIs and trade-offs |
| Workflow map | Prevent missing requirements | Happy path plus top edge cases |
| NFR list (measurable) | Avoid late surprises | Targets with units (ms, %, RTO/RPO, etc.) |
| Integration inventory | De-risk dependencies | Owners, constraints, contract approach |
| Risk register | Make risks actionable | Risk, likelihood, impact, mitigation owner |
| Initial scope slice | Prevent “boil the ocean” | Thin end-to-end slice proposal |
If you want a concrete, validation-first approach before committing to build, this Wolf-Tech article complements discovery well: Validate value before coding.
Phase 2: Define a thin vertical slice (the fastest way to learn safely)
A thin vertical slice is a working end-to-end path through the system, shipped to a real environment, with real constraints.
It is the most reliable way to validate feasibility and delivery maturity early.
What a thin slice should include
A slice is not “a screen” or “an API.” It should include:
- A user entry point (UI or client)
- Identity and authorization at least in a minimal form
- One core workflow
- A real data path (database plus migrations)
- One integration or a realistic stub with a contract
- Logging/metrics/tracing sufficient to debug the workflow
- A deployable pipeline to a non-prod environment
This is also where stack decisions should be validated with evidence, not opinions. If you need a structured way to choose and validate a stack, Wolf-Tech’s stack selection lens is here: Choosing the right stack for your use case.
Exit criteria for Phase 2
You are ready to move on when you can demonstrate:
- The slice works end-to-end in an environment your team controls
- You can deploy it repeatedly
- You have at least basic observability (and can debug failures)
- The biggest unknowns (data shape, integration, performance constraint) are reduced
Phase 3: Foundation that makes shipping repeatable
Teams often try to “start building features” before they can ship safely. The result is a backlog of invisible work that appears later as delays.
Foundation is where you make future delivery cheap.
Foundation essentials (minimum viable professional)
Delivery system
A working CI/CD pipeline is not a nice-to-have. It is the mechanism that makes small, safe changes possible. If you want a practical overview, see: CI/CD technology guide.
Quality gates
Set minimum standards early (formatting, linting, static analysis, tests, build reproducibility). The goal is not perfection, it is preventing obvious regression.
Security baseline
Define how you will handle:
- Secrets management
- Dependency scanning and patching
- Authentication and authorization boundaries
- Secure defaults in environments
Two credible starting points many teams use for baselines are the NIST Secure Software Development Framework (SSDF) and OWASP ASVS. You do not need to implement everything, but you should intentionally pick what applies.
Observability baseline
At minimum, you want:
- Structured logs with correlation IDs
- Basic service metrics (error rate, latency, saturation)
- Tracing across the main workflow
Working agreements
Make decision rights and “Definition of Done” explicit. A kickoff template helps prevent drift, Wolf-Tech has a practical guide here: Software project kickoff: scope, risks, success metrics.
A pragmatic foundation checklist (as a table)
| Area | Baseline question | Proof you should be able to show |
|---|---|---|
| CI/CD | Can we deploy on demand? | Pipeline run history, deployment logs |
| Quality | Will bad changes be caught early? | Tests, static checks, PR rules |
| Security | Are we preventing obvious footguns? | Secret scanning, dependency checks |
| Environments | Can we reproduce and debug? | IaC or scripted setup, runbooks |
| Observability | Can we diagnose issues fast? | Dashboards, traces, log search |
Phase 4: Build and iterate with change safety
This phase is where most of the calendar time goes, but it should not be “big-bang implementation.” The goal is small increments that stay shippable.
How to keep iteration from turning into chaos
Slice the backlog by outcomes, not components
Deliver increments that move a workflow forward (even if minimally) rather than building isolated layers that only integrate late.
Use contracts to control integration risk
Contract-first APIs and contract tests reduce the “it worked on my machine” integration spiral.
Treat data migrations as product work
Data shape changes are often the hidden schedule killer. Plan migration steps, rollback strategies, and backfills explicitly.
Build reliability patterns into the workflow
Time-outs, retries, idempotency, and backpressure are not “later hardening.” They are part of a workflow that must work under failure.
If reliability is a major driver for your app, this deeper Wolf-Tech guide covers concrete patterns: Backend development best practices for reliability.
Keep performance measurable
Avoid performance “debates.” Baseline, change, re-measure. If you need a practical workflow for high-impact fixes, see: Optimize the code: high-impact fixes.
Phase 5: Launch readiness (make launch reversible)
A launch is not a date. It is a risk event.
A good launch plan assumes something will go wrong and makes that failure recoverable.
Launch readiness gate: what to prove
| Launch readiness area | What to decide | Minimum evidence |
|---|---|---|
| SLOs and alerts | What is “bad” in production? | SLO targets, alert thresholds, on-call path |
| Rollback strategy | How do we undo changes fast? | Automated rollback or revert plan tested |
| Deployment safety | How do we reduce blast radius? | Canary or phased rollout approach |
| Data safety | What if a migration fails? | Backup/restore plan, migration rehearsal |
| Security review | Are we shipping known risks? | Threat model notes, top risks mitigated |
| Operational docs | Who does what when it breaks? | Runbook for top workflows and incidents |
If you operate in regulated environments or have high availability requirements, launch readiness should also include audit logging strategy, retention, and incident reporting responsibilities.

Phase 6: Operate, measure, and improve after launch
Post-launch is where custom apps either create compounding value or start accumulating silent cost.
What to measure immediately after launch
Business metrics
Tie usage and workflow completion to the original outcomes. If you cannot measure outcome movement, you cannot defend your roadmap.
Delivery and reliability metrics
Track a small set of signals that correlate with sustainable shipping, many teams use DORA-style metrics (deploy frequency, lead time, change failure rate, MTTR). The canonical community resource is DORA.
Cost and performance
Know your cost drivers (compute, data, third-party APIs) and decide who owns optimization decisions.
Technical debt as an explicit trade-off
Debt is not “bad,” but hidden debt is. Keep a short list of the top debt items that are actively increasing risk or slowing delivery.
Common failure modes (and the prevention pattern)
These issues show up repeatedly in custom application development, regardless of stack:
Discovery produces a feature list, not constraints
Prevention: require measurable NFRs, an integration inventory, and a risk register as discovery outputs.
The first production deploy happens late
Prevention: ship a thin vertical slice early, with real CI/CD, observability, and at least one real data path.
Architecture is decided by preference
Prevention: validate architecture decisions with a thin slice and explicit acceptance criteria, not slide decks.
“Hardening” is a phase that never ends
Prevention: define launch gates up front and build security, reliability, and operability incrementally.
Integrations break the schedule
Prevention: contract-first approach, early integration tests, realistic stubs, and explicit ownership of integration readiness.
Ownership is unclear after launch
Prevention: define on-call, SLAs/SLOs, and handover artifacts before launch, not after.
Where Wolf-Tech fits
Wolf-Tech supports teams across the lifecycle of custom application development, from discovery and tech stack strategy to full-stack delivery, code quality consulting, legacy optimization, and production hardening.
If you want to pressure-test your plan before committing months of build time, a good starting point is a short discovery plus a thin-slice validation plan. You can also explore Wolf-Tech’s perspective on what “good” delivery should include in these related guides:
- Custom web application development services: what to expect
- Custom software development services: scope, SLAs, and proof
- What a tech expert reviews in your architecture
To discuss a build, modernization, or launch-readiness assessment, visit Wolf-Tech and share what you are trying to ship, what constraints you are under, and what “done” needs to mean for your business.