
Code optimieren: Wirkungsvolle Fixes jenseits von Mikro-Optimierungen


Die meisten Teams haben kein Problem mit „langsamem Code". Sie haben ein Problem mit falsch eingesetztem Aufwand.
Entwickler verbringen Tage damit, Millisekunden aus engen Schleifen herauszuholen, während der eigentliche Engpass eine zu geschwätzige Datenbank ist, eine einzige nicht-indizierte Abfrage, ein Third-Party-Aufruf im Request-Pfad oder schlicht eine zu große Payload. Wer Code so optimieren möchte, dass Nutzer und das Business es spüren, muss sich auf Fixes konzentrieren, die die Form des Systems verändern – nicht nur die Syntax.
Dieser Leitfaden handelt von wirkungsvoller Optimierung: Änderungen, die p95-Latenz, Fehlerraten und Infrastrukturkosten messbar verbessern, ohne die Codebasis in ein unlesbares Wissenschaftsprojekt zu verwandeln.
Warum Mikro-Optimierungen selten etwas bewegen
Mikro-Optimierungen (kleine Code-Änderungen, die eine einzelne Funktion beschleunigen) können wertvoll sein, sind aber meist der falsche erste Schritt, weil:
- Die meiste Produktionslatenz ist I/O-gebunden, nicht CPU-gebunden. Netzwerk, Datenbank, Disk, Serialisierung und Queuing dominieren.
- Amdahls Gesetz gilt: Einen Teil des Systems zu beschleunigen, der nur 5 Prozent der Gesamtzeit ausmacht, kann niemals einen großen Gesamtgewinn bringen. (Siehe Amdahls Gesetz.)
- Komplexität ist eine Performance-Steuer. Cleverer Code kann lokal schneller sein, global aber langsamer, weil er Bugs, Review-Zeit und Regressionsrisiko erhöht.
- Ohne Messung wird das Falsche optimiert. Der „offensichtliche" Engpass ist oft nicht der echte.
Für einen umfassenden Katalog von Optimierungstechniken über Frontend, Backend und Datenschichten hinweg hat Wolf-Tech einen begleitenden Leitfaden: Code Optimization Techniques to Speed Up Apps. Dieser Artikel geht eine Ebene höher: Wie werden die wichtigsten Fixes ausgewählt?
Mit einem Performance-Ziel beginnen, das an Ergebnisse geknüpft ist
„Mach es schneller" ist keine Anforderung. Vor dem Anfassen von Code sollte definiert werden, was optimiert werden soll.
Beispiele für Ziele, die Klarheit schaffen:
- Checkout-API: p95 unter 250 ms für authentifizierte Nutzer in Region X
- Suche: p95 unter 800 ms, p99 unter 2 s, Fehlerrate unter 0,1 %
- Web-App: Core Web Vitals (LCP, INP, CLS) auf wichtigen Landing Pages verbessern
- Kosten: Rechenausgaben um 20 Prozent reduzieren ohne Funktionsänderungen
Performance-Arbeit wird nur dann hochheblig, wenn folgendes beantwortet werden kann:
- Welche Nutzerreisen sind am wichtigsten?
- Welches Perzentil ist relevant? (p50 spiegelt selten Schmerzen wider. p95 und p99 häufig schon.)
- Was ist der akzeptable Kompromiss? (Konsistenz vs. Aktualität, Latenz vs. Kosten usw.)
Wer Zuverlässigkeit und Latenz noch nicht diszipliniert trackt, sollte mit dem vorhandenen Observability-Stack eine Baseline aufbauen und SLOs abstimmen. Wolf-Techs Ansatz zu messbarer Betreibbarkeit findet sich in mehreren Engineering-Leitfäden, darunter Backend Development Best Practices for Reliability.
Den Engpass mit Evidenz finden (nicht mit Instinkten)
Wirkungsvolle Optimierung ist ein Kreislauf:
- Echtes Verhalten messen (Produktion oder eine getreue Staging-Umgebung).
- Die dominanten Ursachen identifizieren.
- Die kleinstmögliche Änderung anwenden, die den größten Verursacher entfernt.
- Neu messen und Leitplanken hinzufügen.
Entscheidend ist, das richtige Tool für die Frage zu verwenden:
- Distributed Tracing, um zu sehen, wo Zeit über Services und Dependencies hinweg vergeht.
- Datenbank-Query-Metriken (Slow-Query-Logs, Abfragepläne, Lock-Zeit, Index-Nutzung).
- Profiling (CPU, Memory, Lock Contention), wenn Rechen- oder Runtime-Overhead vermutet wird.
- Frontend-Felddaten für echte Nutzererfahrung, nicht nur Labor-Lighthouse-Scores.
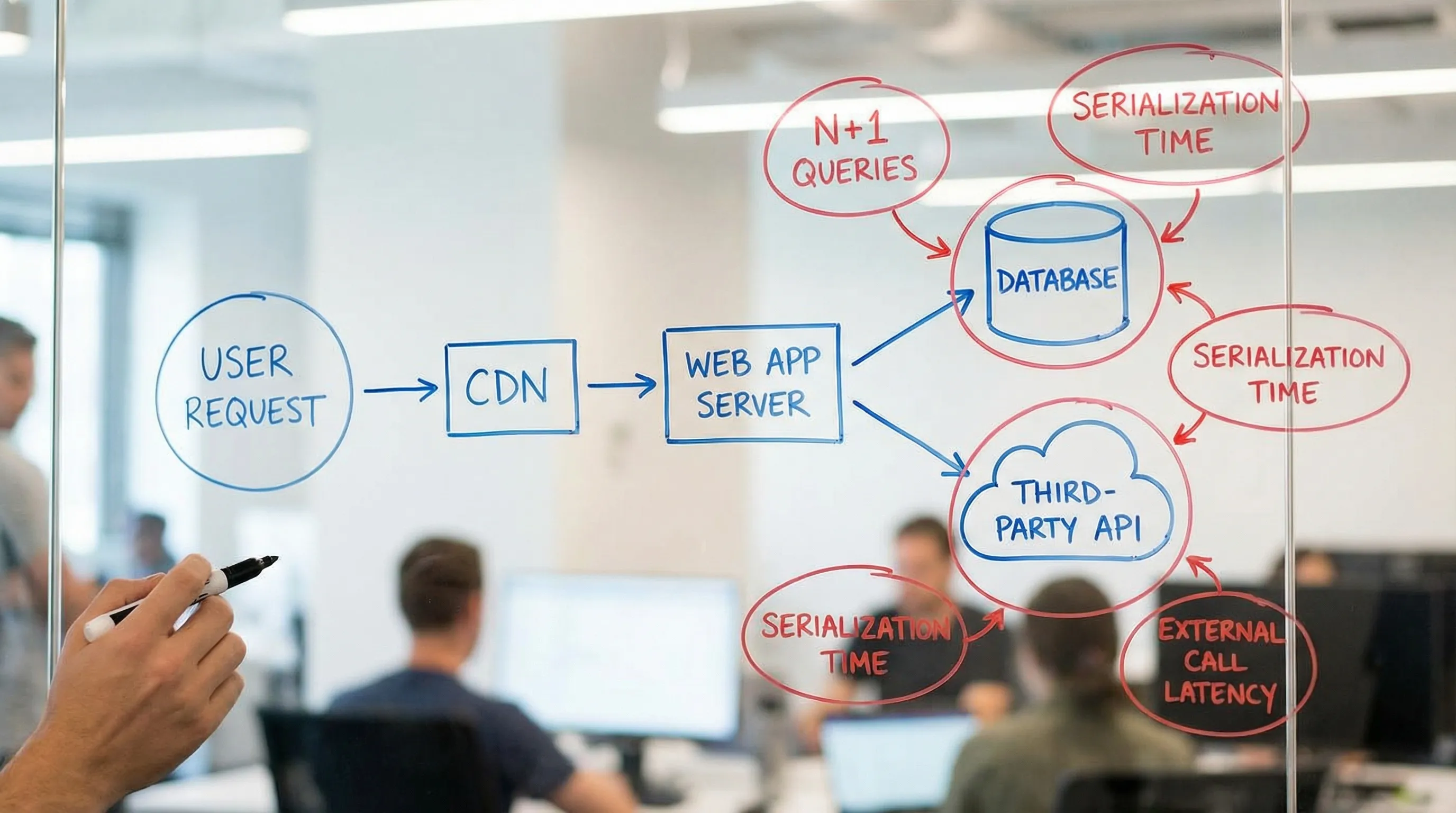
Eine schnelle Triage „Wo ist es langsam?"
Symptome helfen, den ersten Untersuchungsschritt auszuwählen.
| Beobachtetes Symptom | Wahrscheinliche Engpasskategorie | Beste erste Evidenz | Wirkungsvolle Fix-Familie |
|---|---|---|---|
| p95 ist hoch, p50 ist in Ordnung | Queuing, Contention, Spitzen | Traces nach Perzentil, Sättigungsmetriken | Backpressure, Pooling, Concurrency-Limits, Isolation |
| Latenz korreliert mit Traffic | Kapazitäts- oder DB-Sättigung | CPU, DB-Verbindungen, Locks, Request-Rate | Indizierung, Caching, Read-Replicas, Autoscaling |
| Ein einzelner Endpoint ist langsam | Hot-Path-Logik oder Abfrage | Trace-Spans, Endpoint-Profiling, Abfrageplan | Arbeit entfernen, Abfrageform korrigieren, Batching |
| Requests sind schnell, aber Nutzer klagen | Frontend-Engpass | Web Vitals, JS-Bundle, Waterfall | JS reduzieren, LCP optimieren, Third-Party verschieben |
| CPU ist hoch, aber Durchsatz ist niedrig | Ineffizienter Rechenaufwand oder GC | CPU-Profil, Heap-Profil, GC-Logs | Algorithmus-/Datenstrukturänderungen, Allokationsreduzierung |
Wirkungsvolle Fixes, die Mikro-Optimierungen schlagen
Die meisten bedeutsamen Gewinne kommen aus einem von fünf Zügen:
- Arbeit entfernen.
- Roundtrips reduzieren.
- Datenzugriff vorhersehbar machen.
- Arbeit aus dem kritischen Pfad auslagern.
- Regressionen verhindern.
Im Folgenden werden diese mit konkreten Beispielen aufgeschlüsselt.
1) Arbeit aus dem Hot Path entfernen
Der schnellste Code ist der Code, der nicht ausgeführt wird.
Nach „versteckter Arbeit" suchen, die sich ansammelt:
- Abgeleitete Werte bei jedem Request neu berechnen
- Schwere Autorisierungsprüfungen wiederholt statt einmal pro Request durchführen
- Daten abrufen, die der Aufrufer nicht verwendet
- UI rendern, die nie sichtbar über dem Fold ist
- Teure Validierungen in synchronen Pfaden ausführen, die asynchron sein könnten
Praktische Muster:
- Early Exits: bei ungültigen Zuständen schnell scheitern, bevor die Datenbank getroffen wird.
- Doppeltes Parsing/Serialisierung vermeiden: einmal parsen, strukturierte Daten durchreichen.
- Feature-Umfang in Hot-Endpoints reduzieren: die kritische Nutzerreise schlank halten.
Hier zahlt sich auch Code-Qualität in Performance-Dividenden aus. Ist der Hot Path schwer zu verstehen, ist er schwer sicher zu optimieren. Für eine metrikgetriebene Sicht auf das, was zuerst verbessert werden sollte: Code Quality Metrics That Matter.
2) Roundtrips und „geschwätziges" I/O reduzieren
Viele Anwendungen sind langsam, weil sie zu viele kleine Remote-Aufrufe machen:
- N+1-Datenbankabfragen
- N+1-Aufrufe an einen nachgelagerten Service
- Mehrere sequentielle API-Aufrufe, wo ein einziger gebündelter Aufruf ausreichen würde
- Wiederholte Aufrufe, die für Sekunden gecacht werden könnten
Wirkungsvolle Fixes sehen oft so aus:
- Batching: Kollektionen in einer einzigen Abfrage abrufen oder Batch-Endpoints einführen.
- Parallelisierung (vorsichtig): unabhängige Aufrufe gleichzeitig ausführen, mit strikten Timeouts.
- Coalescing: identische In-Flight-Requests deduplizieren, damit 100 Requests nicht alle dieselbe Dependency stürmen.
- Layer zusammenführen: einen extra Hop entfernen, wenn er wenig Wert hinzufügt.
Vorsicht: „Mach es parallel" kann die Last auf nachgelagerte Systeme erhöhen. Das Ziel ist nicht mehr Parallelität – es ist weniger Warten und weniger Gesamtarbeit.
3) Datenzugriff vorhersehbar machen (hier liegen meist die größten Gewinne)
Wer Code wirklich optimieren möchte, beginnt dort, wo die Daten leben. Abfrageform und Indizes können fast jeden Eingriff auf Anwendungsebene in den Schatten stellen.
Abfrageform korrigieren, bevor Anwendungscode optimiert wird
Häufige hochimpaktige Datenprobleme:
- Fehlende oder falsche Indizes
- Abfragen, die große Bereiche scannen und spät filtern
- Sortieren großer Ergebnismengen ohne unterstützende Indizes
- Zu viele Daten zurückgeben und in Anwendungscode filtern
- Lock Contention durch lange Transaktionen
Was „gut" aussieht:
- Abfragen sind begrenzt (nach Tenant, Zeitbereich, Cursor)
- Paginierung ist cursor-basiert, wo tiefes Paging möglich ist
- Teure Operationen pro Zeile im Request-Pfad werden vermieden
- Langsame Abfragen können über Logs und Traces erklärt und reproduziert werden
Caches einführen, die explizit und sicher sind
Caching ist mächtig, wenn es:
- Begrenzt ist (Größe und TTL)
- Beobachtbar ist (Hit-Rate, Eviction-Rate)
- Korrekt ist (klare Invalidierungsregeln)
Hochimpaktige Cache-Ziele:
- Referenzdaten, die sich selten ändern
- Abgeleitete Views, die teuer zu berechnen, aber günstig zu liefern sind
- Autorisierungs- und Policy-Checks mit kurzen TTLs
- Ergebnisse teurer Third-Party-Aufrufe mit graceful Fallback
„Zufälliges Caching", das nicht an einen gemessenen Engpass gebunden ist, vermeiden. Es erzeugt Korrektheitrisiken und schwer debuggbares Verhalten.
4) Arbeit aus dem kritischen Pfad auslagern (Async und Precomputation)
Eine klassische Performance-Falle ist das Ausführen nicht-dringlicher Arbeit während nutzerorientierter Requests.
Beispiele für Arbeit, die oft außerhalb des Request-Pfads gehört:
- PDF-Generierung
- E-Mails und Benachrichtigungen senden
- Webhook-Auslieferungen
- Suchindizierung
- Analytics-Events
- Report-Aggregation
Hochimpaktige Lösungen:
- Background Jobs mit Idempotenz und Retries
- Event-getriebene Flows (Outbox-Pattern, Queues) für zuverlässige asynchrone Verarbeitung
- Vorberechnete Read-Models oder materialisierte Views für leseintensive Seiten
- Streaming: früh Teilergebnisse zurückgeben, wenn die UX es erlaubt
Hier können auch Legacy-Systeme inkrementell und wenig disruptiv modernisiert werden, indem Seams eingeführt und Verantwortlichkeiten schrittweise verlagert werden. Für ältere Architekturen: Modernizing Legacy Systems Without Disrupting Business.
5) Payload- und Serialisierungskosten reduzieren (Frontend und Backend)
Payload-Bloat ist ein stiller Latenz-Multiplikator:
- Mehr Zeit zum Serialisieren auf dem Server
- Mehr Zeit zur Übertragung über das Netzwerk
- Mehr Zeit zum Parsen auf dem Client
- Mehr Speicherdruck, mehr GC
Hochimpaktige Fixes:
- Nur zurückgeben, was die UI braucht (Overfetch vermeiden)
- Responses komprimieren und bei großen JSON-Blobs bewusst vorgehen
- Paginierung und Partial Loading verwenden
- Bilder und Fonts für Web-Delivery optimieren
Wenn das Produkt ein React- oder Next.js-Frontend enthält, kann Bundle-Größe und Rendering-Strategie die wahrgenommene Performance dominieren. Wolf-Tech hat dazu einen eigenen Performance-Leitfaden: Next.js Development: Performance Tuning Guide.
Die Optimierungs-Hebel-Leiter (was zuerst ausprobiert werden sollte)
Wenn Teams sagen, sie wollen „den Code optimieren", springen sie oft ans Ende dieser Leiter. Besser oben beginnen:
| Ebene | Was geändert wird | Typischer Impact | Typisches Risiko |
|---|---|---|---|
| Systemverhalten | Arbeit entfernen, Async, Hops reduzieren | Sehr hoch | Mittel (erfordert Design-Disziplin) |
| Datenzugriff | Abfrageform, Indizes, Caching-Strategie | Sehr hoch | Mittel (erfordert Korrektheit und Validierung) |
| Runtime und Infrastruktur | Pooling, Timeouts, Connection-Limits, Autoscaling | Hoch | Mittel bis hoch (kann Zuverlässigkeit beeinfl.) |
| Anwendungscode | Algorithmen, Allokation, Hot Loops | Mittel bis hoch (nur in echten CPU-Hotspots) | Niedrig bis mittel |
| Mikro-Optimierungen | Kleine Refactorings für Geschwindigkeit | Niedrig (außer nachgewiesener Hotspot) | Niedrig bis mittel (kann Lesbarkeit schaden) |
Ein praktischer „hochimpaktiger" Workflow in 2 Wochen
Für einen zeitbegrenzten Plan, der kein endloses Performance-Projekt wird:
Woche 1: Die 1 bis 3 wichtigsten Engpässe identifizieren und beweisen
- Eine kritische Nutzerreise auswählen und ein Ziel definieren (p95, Fehlerrate, Kosten).
- Traces instrumentieren oder verbessern, um Dependency-Timing klar zu sehen.
- Die langsamsten Traces herausziehen, dann nach dominanter Ursache gruppieren (DB, nachgelagerter API, Serialisierung, Queuing).
- Einen kurzen Engpass-Report mit Screenshots, Beispiel-Traces und einer Hypothese pro Gruppe erstellen.
Woche 2: Einen hochhebligen Fix anwenden und Leitplanken hinzufügen
- Den Fix mit dem besten Impact-zu-Risiko-Verhältnis wählen.
- Möglichst hinter einem reversiblen Mechanismus implementieren (Feature-Flag, Config-Switch).
- In der Produktion neu messen, Fokus auf p95 und p99.
- Eine Regressions-Leitplanke hinzufügen (Budget, Test, Alert), damit das Problem behoben bleibt.
Ein gutes Ergebnis dieses Sprints ist nicht „wir haben die Performance verbessert". Es ist:
- Ein reproduzierbares Measurement-Setup
- Eine bewiesene Verbesserung
- Eine neue Engineering-Leitplanke, die Rückschritte verhindert
Performance-Regressionen mit Delivery-Leitplanken verhindern
Performance-Gewinne verschwinden oft, weil Teams ein Problem einmal beheben und es dann über Monate still wieder regressiert.
Hochwertige Leitplanken:
- Performance-Budgets für wichtige Endpoints (Latenz) und wichtige Seiten (Web Vitals)
- CI-Checks, die bei offensichtlichen Regressionen fehlschlagen (Bundle-Größe, langsame Unit-Integrations-Hotspots)
- Canary- oder progressive Delivery, um Probleme vor dem vollständigen Rollout zu erkennen
- Dashboards, die Perzentile tracken, nicht nur Durchschnitte
Das ist eng mit Delivery-Reife verbunden. Wer das System zum sicheren Ausliefern von Änderungen stärken möchte, findet bei Wolf-Tech eine solide Basis: CI/CD Technology Guide.
Wenn Optimierung durch die Codebasis blockiert wird (und was zu tun ist)
Manchmal ist der Engpass keine einzelne Abfrage oder Funktion. Die Codebasis ist zu verworren, um sie sicher zu ändern.
Signale für diese Situation:
- Verhalten kann lokal nicht reproduziert werden.
- Kleine Änderungen erzeugen unerwartete Nebeneffekte.
- Niemand vertraut Refactorings, also wird alles additiv.
- Performance-Fixes sind riskant, weil Verhalten nicht mit Tests fixiert werden kann.
In diesen Fällen ist die wirkungsvollste „Optimierung" oft:
- Characterization Tests um Hotspots herum hinzufügen
- Refactoring, um Seams zu schaffen
- Module mit hoher Änderungsrate oder hohen Kosten isolieren
Deshalb sind Performance und Wartbarkeit keine konkurrierenden Ziele. Sie sind oft dasselbe Ziel. Ein pragmatischer Ansatz dazu findet sich in Refactoring Legacy Applications: A Strategic Guide.

Wie Wolf-Tech Teams hilft, Code ohne Rätselraten zu optimieren
Wolf-Tech ist auf Full-Stack-Entwicklung und Code-Qualitäts-Consulting spezialisiert, mit umfangreicher Erfahrung in Legacy-Code-Optimierung, moderner Webanwendungsentwicklung sowie Cloud- und DevOps-Praktiken. Wenn Teams Wolf-Tech für Performance-Arbeit engagieren, ist das Ziel kein einmaliges Tuning – es ist ein messgetriebener Verbesserungsplan, der aufrechterhalten werden kann.
Für Hilfe bei der Engpassidentifizierung, dem sicheren Beheben von Hotspots oder der Modernisierung eines Legacy-Systems, damit es performt und skaliert: Wolf-Techs Arbeit auf wolf-tech.io entdecken und für eine Beurteilung kontaktieren.