
Software Development: Why Processes Fail and Fixes


Most “process problems” in software aren’t caused by choosing the wrong flavor of Agile, Scrum, Kanban, SAFe, or a homegrown hybrid. They fail because the process is asked to compensate for missing fundamentals: unclear outcomes, ambiguous ownership, weak engineering feedback loops, and no shared definition of what “done” means.
If you found this page searching for software software development, you are probably feeling one of these symptoms:
- Plans keep slipping even though the team is “busy.”
- Releases are stressful, manual, and full of surprises.
- QA is a phase at the end, not a built-in habit.
- Stakeholders don’t trust estimates, and engineers don’t trust requirements.
- Velocity looks fine, but production results do not.
This article breaks down why software development processes fail in practice, the signals that show up early, and the fixes that actually change outcomes.
The uncomfortable truth: a process is not a delivery system
A process tells people what ceremonies to attend and what artifacts to produce. A delivery system proves that you can:
- Turn intent into a shippable slice.
- Change code safely.
- Release predictably.
- Operate reliably.
- Learn from production and iterate.
High-performing teams treat process as the visible tip of a deeper system: architecture guardrails, CI/CD, automated quality gates, observability, and clear decision rights.
Research consistently shows that delivery performance is strongly tied to technical and organizational capabilities, not to “doing Agile harder.” The DORA research program (popularized by the book Accelerate) links outcomes like lead time and stability to capabilities such as continuous delivery, trunk-based development, and fast feedback loops. See Google Cloud’s DORA resources for an overview.
Why software development processes fail (and what it looks like when they do)
Most failures fall into a small number of repeatable patterns. The quickest way to diagnose your situation is to look for observable symptoms, then map them to the underlying constraint.
Failure mode 1: The team is executing tasks, not outcomes
What it looks like
Backlogs are written as feature lists. Teams deliver “everything requested,” but the business still cannot measure impact. Stakeholders keep changing priorities because nothing is clearly working.
Why it happens
When outcomes and constraints are unclear, the process becomes a treadmill: produce tickets, complete sprints, repeat. The organization confuses activity with progress.
Fix that works
Start with a one-page outcome brief that is testable:
- Target user and job to be done
- Success metric and baseline
- Non-functional requirements (latency, availability, data retention, security constraints)
- Scope boundaries (explicitly what is out)
A lightweight kickoff discipline makes a huge difference. If you want a template-driven approach, Wolf-Tech’s guide on software project kickoff is a solid baseline.
Failure mode 2: “Done” means merged, not shipped
What it looks like
Engineering completes work, but it sits behind long-lived branches, blocked QA, or release trains. Launch days become major events. Defects pile up in environments that don’t match production.
Why it happens
The process defines completion at the wrong boundary. If “done” stops at code review, you have no proof you can deploy safely.
Fix that works
Define “done” in levels that reflect real risk:
- Built and tested automatically
- Deployed to a production-like environment
- Observability in place (logs, metrics, tracing where needed)
- Reversible rollout plan (feature flag, canary, or safe rollback)
- Released to production (even if hidden behind a flag)
This is also where CI/CD maturity pays back immediately. A practical starting point is CI/CD technology.
Failure mode 3: Big batches hide unknowns until it’s too late
What it looks like
Projects run for weeks or months without a production-worthy increment. Integration happens late. Data migrations are discovered at the end. Performance is “tested later.”
Why it happens
Large batches delay feedback. Unknowns accumulate and then detonate during “integration,” “hardening,” or “UAT.”
Fix that works
Use a thin vertical slice as a proof mechanism, not a prototype theater.
A thin slice should include: UI, API, data, auth (if relevant), deployment, and telemetry, even if the feature is minimal. The point is to prove the end-to-end path.
If you want a step-by-step process built around this idea, see Wolf-Tech’s software building process for busy teams.
Failure mode 4: Handoffs create queues, and queues create delay
What it looks like
Work moves from Product to UX to Engineering to QA to Ops, with wait states between each. Everyone is “efficient” locally, but end-to-end delivery is slow.
Why it happens
Handoffs add translation loss and waiting. The process optimizes for role utilization instead of flow.
Fix that works
Reduce handoffs by aligning around a shared “slice team” that can deliver end-to-end.
That does not mean every individual is full-stack. It means the team has the capabilities and decision rights to ship a slice without waiting on another department for every step.
For many organizations, the most practical improvement is to define cross-functional agreements and contracts early. The UX and engineering alignment loop described in UX to architecture handshake is one of the highest leverage ways to prevent rework.
Failure mode 5: Quality is a promise, not a system
What it looks like
Quality depends on heroes. Reviews are inconsistent. Testing is “nice to have” under schedule pressure. Bugs recur. Security fixes are reactive.
Why it happens
If quality is not automated and enforced, it will lose to urgency every time. A process document cannot outvote a deadline.
Fix that works
Introduce automated quality gates that are hard to bypass:
- Linting and formatting
- Static analysis and typing (where applicable)
- Fast unit and component tests
- A small, stable E2E smoke suite
- Dependency and secret scanning
Treat these as part of the delivery system. Wolf-Tech has language-specific examples (for instance, the JS code quality checklist) and a broader view of which measures predict outcomes in code quality metrics that matter.
Failure mode 6: Architecture is accidental, so change becomes expensive
What it looks like
Every feature touches too many files and services. Teams are afraid to refactor. Incidents spike after releases. “We need a rewrite” enters the chat.
Why it happens
Without explicit boundaries and contracts, coupling grows silently. Process rituals can’t compensate for a system where everything depends on everything.
Fix that works
Establish a small set of architecture guardrails:
- Clear module boundaries (in code, not just a diagram)
- Contract-first APIs where integration risk is high
- A decision log (ADRs) for major trade-offs
- A default architecture baseline that matches current maturity
In 2026, many teams still get better results starting with a modular monolith than with premature microservices. If this is your situation, modular monolith first explains the trade-offs.
Failure mode 7: Decision rights are unclear, so priorities churn
What it looks like
Roadmaps change weekly. Engineers get contradictory instructions. Stakeholders escalate around the process. Teams stop trusting planning.
Why it happens
A process can schedule meetings, but it can’t fix governance. Without clear ownership for scope, architecture, risk, and release decisions, you get thrash.
Fix that works
Define decision rights explicitly:
- Who owns outcome metrics and acceptance?
- Who owns architecture guardrails and ADR approval?
- Who can interrupt the sprint, and under what conditions?
- Who approves production releases?
Even a simple decision table written down and reviewed monthly reduces churn.
A practical diagnostic table: map symptoms to root causes and fixes
Use this table to move from “we feel stuck” to actionable constraints.
| Symptom in the real world | Likely root cause | Fix to implement (proof-based) |
|---|---|---|
| Sprint commitments are met, but releases slip | “Done” ends at merge, not deploy | Make release a first-class artifact: CI/CD, preview envs, reversible release patterns |
| QA is always behind | Late integration, big batches, weak automation | Thin vertical slices + automated gates + shrink E2E to a stable smoke layer |
| Frequent production regressions | Weak change safety and observability | Add tests on changed code, release tagging, error budgets, monitoring alarms |
| Teams argue about requirements | Outcomes and constraints are ambiguous | One-page outcome brief + explicit NFRs and scope boundaries |
| Every feature touches everything | Accidental architecture and coupling | Boundaries, contracts, ADRs, dependency rules, modularization |
| Stakeholders constantly reprioritize | No measurable learning loop | Define success metrics, instrument, review outcomes weekly, prune work |
| Engineers are burned out | Hero culture, manual releases, constant interrupts | Automate release/quality, define interrupt policy, reduce WIP, improve on-call hygiene |
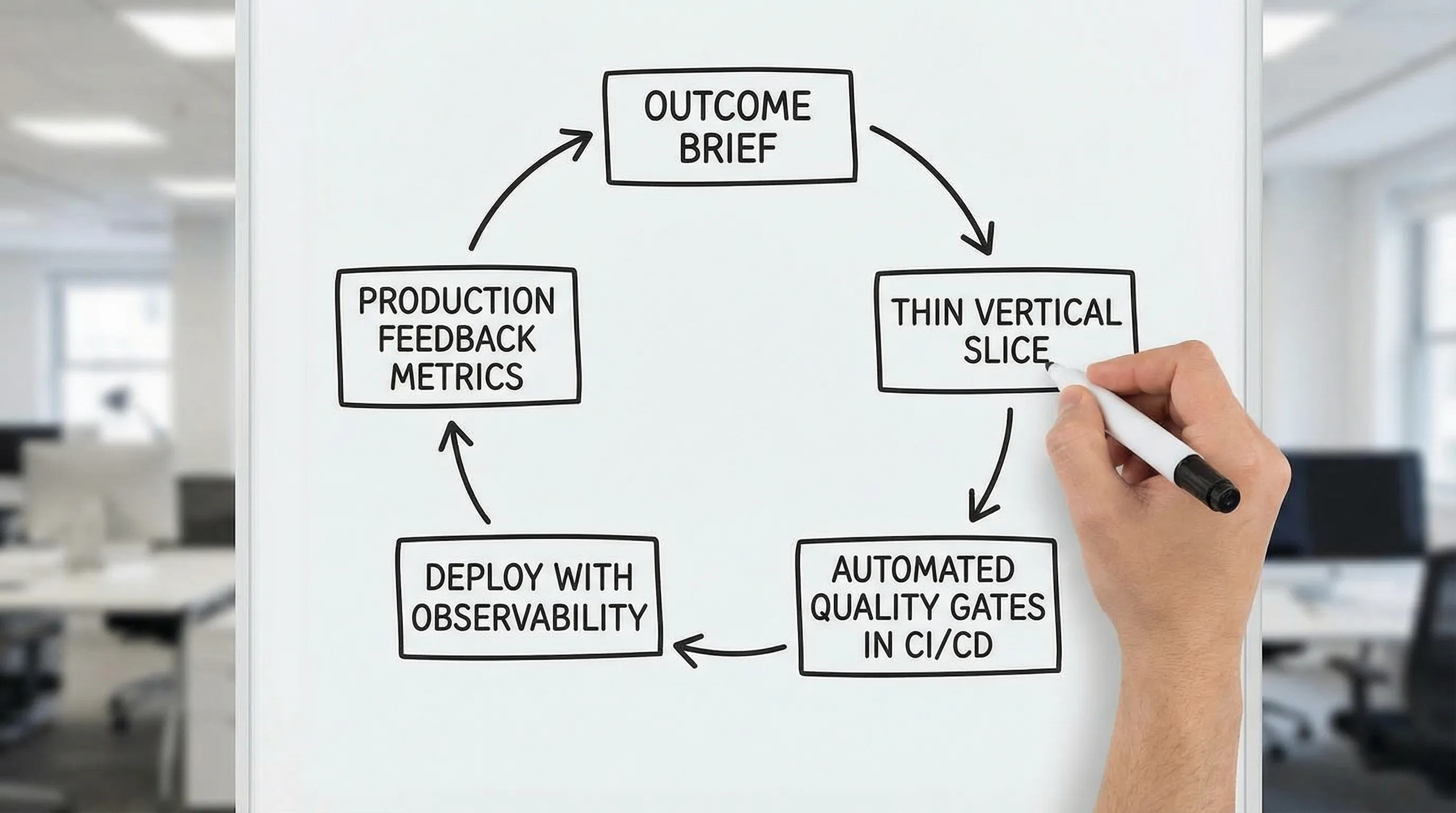
The fixes: build a minimum viable delivery system (MVDS)
If your process keeps failing, don’t start by rewriting the process. Start by installing a minimum set of capabilities that make shipping safe and repeatable.
1) Make outcomes and constraints explicit
Good software development starts with clarity that engineers can build against.
At minimum, capture:
- Outcome metric (and how you will measure it)
- Key user journeys
- Constraints: performance, reliability, security, compliance, data retention
- Integration surface (what systems you must touch)
This is where many teams discover they have been “agilely” building without shared acceptance criteria.
2) Slice work by end-to-end value, not by components
Component-based slicing (backend first, UI later) often creates “almost done” work that cannot be validated.
Prefer slices that are:
- Thin (small scope)
- Vertical (UI to data)
- Production-shaped (deployed, observable, reversible)
This shifts the process from speculative planning to continuous proof.
3) Standardize the feedback loop (fast, automated, trusted)
A reliable process depends on a reliable feedback ladder:
- Local feedback in minutes (lint, typecheck, unit tests)
- PR feedback in under an hour (fast CI)
- Environment feedback same day (preview deployments)
- Production feedback within days (feature flags, staged rollout, telemetry)
If CI is slow or flaky, developers stop trusting it, and your process becomes opinion-driven again.
4) Enforce quality as code, not as policy
Policies get bypassed. Automation does not (or at least, it fails loudly).
To reduce release risk, treat these as non-negotiable defaults:
- Formatting and lint rules
- Dependency checks and vulnerability scanning
- Automated tests that target change hotspots
- Database migration safety checks (when applicable)
If you are in a regulated environment or have a serious security posture, align engineering work with established guidance like the NIST Secure Software Development Framework and map it to your pipeline gates.
5) Add operability early: you can’t “process” your way out of production
Many process failures are actually operations failures showing up late.
Minimum operability includes:
- Basic service-level indicators (SLIs) for latency, errors, saturation
- Alerts tied to user impact
- Runbooks for common failure modes
- A defined rollback or disable path for new releases
If you want a pragmatic checklist for the backend side of this, see backend development best practices for reliability.
What to do in the next 30 days (without boiling the ocean)
A “process fix” that takes six months is usually a rebranding exercise. The highest leverage approach is to change a few constraints quickly, then iterate.
Week 1: Establish a baseline and a shared definition of done
Pick 3 to 5 metrics and measure the current state. A simple set that works across teams:
- Lead time to production (PR merged to prod)
- Deploy frequency
- Change failure rate
- MTTR
- Defect escape rate (bugs found after release)
These align with the DORA performance view and give you a reality check without turning into a metrics theater.
Week 2: Implement one thin vertical slice with real proof
Choose a small feature and deliver it end-to-end:
- A production-shaped route or flow
- A real deployment through CI/CD
- A small dashboard or alert proving observability
This creates a reference implementation for how the team ships.
Week 3: Install quality gates and make them boring
Make the pipeline dependable:
- Fast checks on every PR
- One stable E2E smoke run
- Security checks integrated into CI
The goal is not perfection. The goal is predictable change safety.
Week 4: Fix the biggest recurring queue
Look for the most expensive waiting point:
- Waiting on QA
- Waiting on environment promotion
- Waiting on approvals
- Waiting on another team’s API
Then remove it or reduce it with contracts, automation, or decision-right changes.
A simple “process health” scorecard you can run in one meeting
Use this as a structured conversation with engineering and product leadership. Score each 0 to 2:
| Capability | 0 points | 1 point | 2 points |
|---|---|---|---|
| Outcome clarity | Feature list only | Outcome metric exists, weak acceptance | Outcome + NFRs + measurable acceptance |
| Thin slicing | Work is component-based | Some vertical slices | Default is thin vertical slices |
| CI reliability | Slow/flaky, bypassed | Works but inconsistent | Fast, trusted, enforced |
| Release safety | Manual, high stress | Some automation | Reversible releases + staging + telemetry |
| Quality gates | Mostly manual QA | Some checks | Automated gates + stable test strategy |
| Operability | “We’ll add monitoring later” | Basic logs/alerts | SLIs/SLOs, dashboards, runbooks |
| Ownership & decisions | Unclear, political | Partial clarity | Explicit decision rights + ADRs |
A low score does not mean the team is bad. It means the system is missing proof mechanisms.
Where Wolf-Tech can help (without forcing a rewrite)
Wolf-Tech works with teams that need to build, optimize, or scale software delivery, especially when process changes alone have failed. Typical engagements include architecture and code quality reviews, legacy code optimization, delivery system upgrades (CI/CD, quality gates, operability), and full-stack implementation support.
If you want a fast, evidence-driven way to get unstuck, a good starting point is an architecture and delivery assessment similar to what’s outlined in what a tech expert reviews in your architecture. From there, you can define a targeted 30-day improvement plan focused on measurable delivery and production outcomes.