
Anwendungsentwicklungs-Roadmap: Vom MVP zur Skalierung


Die meisten „Roadmaps" scheitern aus einem einzigen Grund: Sie listen Funktionen auf, keine Beweise. Eine Anwendung, die im Demo toll aussieht, kann unter echtem Traffic, echten Daten und echten Änderungen trotzdem zusammenbrechen. Eine nützliche Anwendungsentwicklungs-Roadmap ist eine Abfolge von Phasen, in denen jede Phase eine spezifische Art von Risiko reduziert (Wert, Nutzbarkeit, Machbarkeit, Betreibbarkeit) und Artefakte hinterlässt, die die nächste Phase günstiger machen.
Dieser Leitfaden skizziert einen praktischen Weg vom MVP zur Skalierung, mit den Lieferungen und Metriken, die wichtig sind, wenn Sie schnell liefern wollen ohne sich in eine Ecke zu manövrieren.
Was „MVP bis Skalierung" tatsächlich verändert
Die Anforderungen Ihrer Anwendung ändern sich auf vorhersehbare Weise, wenn sie wächst:
- In der MVP-Phase ist das größte Risiko, das Falsche zu bauen – oder das Richtige auf eine Art, die nicht sicher ausgeliefert werden kann.
- In der Wachstumsphase wird das größte Risiko zu Regressionen, Reliability-Incidents und Teams, die aufgrund von Koordination langsamer werden.
- In der Skalierungsphase verlagern sich die Risiken erneut auf Kostenkontrolle, Governance, Sicherheitsniveau und vorhersagbaren Betrieb über mehrere Teams.
Eine Roadmap, die diese Risikoveränderungen ignoriert, investiert typischerweise zu früh zu viel (Gold-Plating der Infrastruktur) oder zu früh zu wenig (Überspringen von Liefer- und Ops-Grundlagen, dann teuer nachholen).
Die Roadmap als Phasen und „Proof-Gates"
Stellen Sie sich diese Roadmap als fünf Phasen vor. Sie müssen eine Phase nicht perfekt „abschließen" bevor Sie die nächste beginnen, aber Sie brauchen Proof-Gates, die verhindern, dass Sie Chaos skalieren.
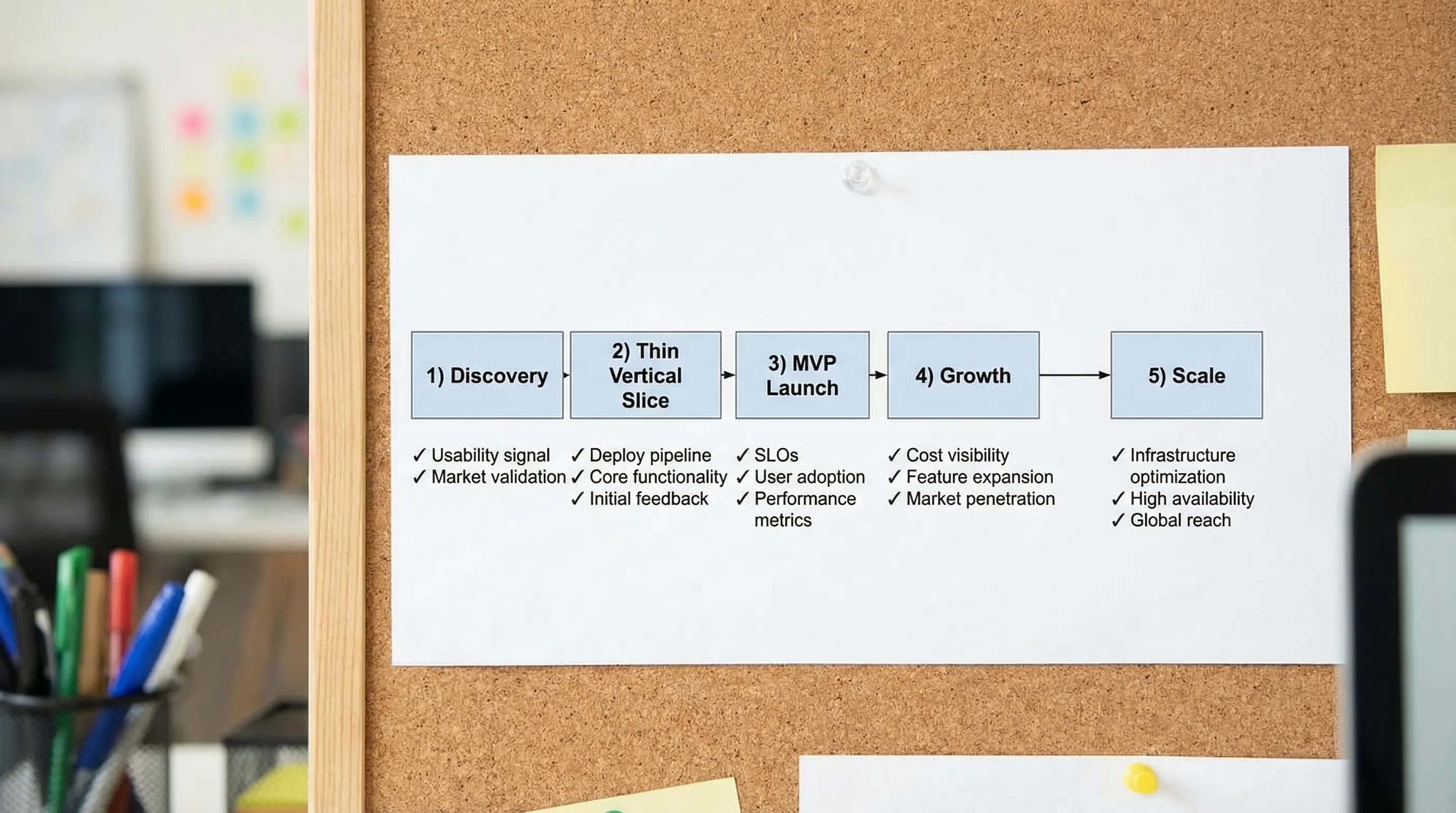
Roadmap-Übersicht (was zu produzieren und was zu messen ist)
| Phase | Primäres Ziel | Proof-Gate (was wahr sein muss) | Schlüssel-Artefakte (Minimum) | Zu beobachtende Metriken |
|---|---|---|---|---|
| Discovery | Outcomes, Rahmenbedingungen und Umfangsgrenzen ausrichten | Sie können das „Warum jetzt" und für wen es ist, auf einer Seite erklären | Outcome-Brief, Umfangsgrenzen, Risikoliste, initiale NFR-Ziele | Interview-Signal, Zeit bis zum ersten nutzbaren Prototyp (wenn relevant) |
| Dünner vertikaler Schnitt | Ende-zu-Ende-Machbarkeit und Betreibbarkeit beweisen | Ein echter Schnitt läuft in einer echten Umgebung mit Telemetrie | Repo-Baseline, CI/CD, Auth-Skelett, ein vertikaler Flow, Logging/Metriken/Tracing | Lead Time, Deploy-Erfolgsrate, p95-Latenz-Baseline |
| MVP-Launch | Ein minimales Produkt ausliefern, das sicher betrieben werden kann | Rollback funktioniert, Incidents werden triagiert, Nutzerfeedback-Schleife existiert | Runbook, Alerts, Dashboards, Support-Workflow, Sicherheits-Baseline | Aktivierungs-/Retention-Proxy, Fehlerrate, MTTR |
| Wachstum | Lieferdurchsatz steigern ohne Zuverlässigkeit zu brechen | Teams liefern wöchentlich (oder schneller) mit stabiler Change Failure Rate | Modularisierungsplan, Contract-Disziplin, Feature Flags, Test-Strategie | DORA-Metriken, SLO-Compliance, Kosten pro aktivem Nutzer |
| Skalierung | Mehrteilige Teamautonomie mit Governance und Kostenkontrolle | Teams können sicher Änderungen vornehmen ohne zentrale Flaschenhälse | Paved-Path-Plattform, Standards + Ausnahmen, Audit-Nachweis, DR-Plan | Error-Budgets, Incident-Häufigkeit, Cloud-Unit-Economics |
Für eine tiefere Lebenszyklus-Ansicht von Discovery bis Launch ergänzt Wolf-Techs Leitfaden zur individuellen Anwendungsentwicklung von der Discovery bis zum Launch diese Roadmap. Hier konzentrieren wir uns darauf, wie die Anwendung weiterentwickelt wird, sobald „MVP" zu „einem echten System" wird.
Phase 1: Discovery, die tatsächlich vom Engineering genutzt werden kann
Discovery bedeutet nicht, ein langes PRD zu schreiben. Es geht darum, entscheidungsreife Inputs zu schaffen, damit Engineering einen Build planen kann, der Erfolgsaussichten hat.
Die besten Discovery-Pakete sind kurz, explizit und testbar.
Minimum Discovery-Lieferungen
- Einseitiger Outcome-Brief: Zielnutzer, der zu erledigende Job, Erfolgsmetriken und Rahmenbedingungen (Zeitplan, Budget, regulatorische Exposition, Integrationen).
- Umfangsgrenzen: Was drin ist, was explizit raus ist und was „später" bedeutet.
- NFR-Ziele (nicht-funktionale Anforderungen): initiale Performance-, Zuverlässigkeits-, Datenschutz-/Sicherheits- und Datenaufbewahrungsannahmen.
- Risikoregister: Top-Risiken mit Mitigation-Eigentümern (besonders rund um Daten und Integrationen).
Wenn UX beteiligt ist, richten Sie UX und Architektur frühzeitig aus, damit Latenzerwartungen, Offline-Verhalten, Kollaborationsmuster und Berechtigungen keine späteren „Überraschungen" sind. Wolf-Tech nennt diese Ausrichtungsschleife den UX-zur-Architektur-Handshake.
Häufiges Fehlermuster
Teams behandeln Discovery als „Feature-Shopping" und verschieben schwierige Entscheidungen (Identität, Datenmodell, Integrationen). Das Ergebnis ist ein MVP, das vollständig wirkt, aber strukturell teuer zu ändern ist.
Phase 2: Dünner vertikaler Schnitt (der schnellste Weg zur Risikoreduzierung)
Ein dünner vertikaler Schnitt ist kein Prototyp. Es ist ein produktionsförmiger Ende-zu-Ende-Flow, der beweist, dass Sie:
- Zuverlässig bauen und deployen können
- Mit der risikoreichsten Abhängigkeit integrieren können
- Echte Auth und Berechtigungen handhaben können
- Verhalten in einer produktionsähnlichen Umgebung beobachten können
Dies ist der Punkt, an dem „Anwendungsentwicklung" zu einem Liefersystem wird, nicht zu einer Code-Übung.
Was in den Schnitt aufzunehmen ist
Wählen Sie einen Nutzer-Journey, der echte Entscheidungen erzwingt. Zum Beispiel: „Konto erstellen, eine Kernaktivität ausführen, das Ergebnis sehen und eine Benachrichtigung erhalten."
Ihr Schnitt sollte beinhalten:
- Identität: Authentifizierung, Autorisierung, Rollen und Tenant-Grenzen (falls anwendbar)
- Daten: einen echten Schema-Pfad, Migrationen, Seed-Strategie
- API-Vertrag: Versionierungsansatz und Fehlermodell
- Lieferung: CI-Pipeline, automatisches Deployen in eine Nicht-Prod-Umgebung
- Observability: strukturierte Logs, grundlegende Metriken, Tracing für den Flow
Für Teams, die in dieser Phase Stacks evaluieren: Halten Sie die Bewertung auf Ihren nächsten 12 bis 36 Monate verankert und validieren Sie mit einem dünnen Schnitt. Der Apps-Technologie-Stack-Leitfaden von Wolf-Tech zeigt einen praktischen Weg dafür.
Proof-Gate: „Wir können ausliefern und sehen, was passiert ist"
Wenn Sie den Schnitt nicht wiederholt mit Zuversicht deployen können, skalieren Sie noch keine Feature-Arbeit. Sie skalieren nur Unsicherheit.
Eine nützliche Baseline ist die Messung der Lieferung mit den DORA-Metriken (Lead Time, Deploy-Häufigkeit, Change Failure Rate, Time to Restore). Die zugrunde liegende Forschung wird vom DORA-Programm gepflegt.
Phase 3: MVP-Launch als umkehrbares Risikoereignis
„MVP-Launch" ist der Punkt, an dem viele Teams entdecken, dass sie eine App gebaut haben, aber kein betreibbares System.
Ihr Launch-Gate sollte sich auf Umkehrbarkeit und Unterstützbarkeit konzentrieren, nicht auf „mehr Funktionen".
Launch-Bereitschaft, minimal viable (aber real)
Anstreben:
- Rollback und progressives Rollout: Sie können sicher deployen und rückgängig machen (Feature Flags, Canary oder Blue/Green je nach Setup)
- Incident-Schleife: On-Call-Zuständigkeit, Schweredefinitionen und ein Ort zum Festhalten von Lernerkenntnissen (auch wenn leichtgewichtig)
- Datensicherheit: Backups getestet, sichere Migrationsregeln, grundlegende Audit-Trails wo erforderlich
- Sicherheits-Baseline: Schwachstellenscanning, Secrets-Handling, Least Privilege und ein Plan zur Behebung von OWASP-Klassen-Risiken
Für einen praktischen Sicherheitseinstieg ist das OWASP Top 10 eine gute Baseline für Web-Anwendungen, besonders zur Vermeidung häufiger Klassen wie Broken Access Control und Injection.
MVP-Metriken, die es lohnt, früh zu instrumentieren
Instrumentieren Sie nicht alles. Instrumentieren Sie, was Entscheidungen ändert:
- Aktivierungs-Proxy: welche Aktion zeigt Ihnen, dass ein Nutzer Wert erhalten hat (nicht nur Anmeldung)
- Time-to-Value: wie lange vom ersten Kontakt bis zur erfolgreichen Kernaktivität
- Zuverlässigkeitssignale: Fehlerrate und p95-Latenz für den Kernflow
- Support-Last: Anzahl der Support-Kontakte pro aktivem Nutzer
Hier beginnen viele Teams, Service Level Objectives (SLOs) zu definieren, auch wenn die erste Version einfach ist. Das Site Reliability Engineering-Buch von Google bleibt eine starke Referenz für dieses Mindset.
Phase 4: Wachstum – Geschwindigkeit beibehalten und Sicherheit hinzufügen
Wachstum ist der Punkt, an dem Erfolg Druck erzeugt. Mehr Nutzer, mehr Daten, mehr Randfälle, mehr Entwickler, die den Code anfassen.
Die Roadmap sollte hier Arbeit priorisieren, die Änderungen günstig hält:
1) Architektur, die Änderungen skaliert, nicht nur Traffic
Traffic-Skalierung wird oft mit Caching, Indexierung und Kapazität gelöst. Änderungs-Skalierung ist schwieriger.
Ein pragmatischer Standard für viele Produkte ist, mit einem modularen Monolithen zu beginnen, dann zu extrahieren wenn die Nähte real sind. Wenn Sie Architekturen debattieren, legt Wolf-Techs Leitfaden zum Thema wann zuerst modularer Monolith hochsignifikante Entscheidungskriterien dar.
Was „gut" im Wachstum aussieht:
- Klare Modulgrenzen (nach Business-Capability, nicht technischer Schicht)
- Explizite API- und Datenverträge (intern oder extern)
- Hintergrundarbeit vom Request-Pfad entfernt (Queues, Async-Jobs)
- Ein disziplinierter Ansatz für Schema-Änderungen (Expand-and-Contract-Migrationen)
2) Liefer-Mechanismen, die Regressionen verhindern
Im Wachstum sind Ihre größten versteckten Kosten Nacharbeit durch unsichere Änderungen.
Investieren Sie in:
- CI, das schnell läuft und vertrauenswürdig ist
- Eine Test-Strategie mit einer kleinen Anzahl hochsignifikanter Tests (Komponenten-Tests plus einige End-to-End-Tests für kritische Pfade)
- Preview-Umgebungen für PR-Validierung (wenn machbar)
- Feature Flags für kontrolliertes Rollout
Wenn CI/CD ein Engpass ist, adressieren Sie es explizit. Der CI/CD-Technologie-Leitfaden von Wolf-Tech bietet einen pragmatischen Adoptionsplan.
3) Betreibbarkeit als Produktfunktion
Mit dem Wachstum sollten Sie aufhören, Logs und Dashboards als Nachgedanken zu behandeln. Das Ziel ist schnellere Diagnose und sicherere Änderungen.
Als Minimum standardisieren:
- Eine Request-Korrelationsstrategie (Trace-IDs)
- Eine kleine Menge „Golden Signals"-Dashboards (Latenz, Traffic, Fehler, Sättigung)
- Alert-Schwellenwerte, die an Nutzerauswirkungen gebunden sind
- Ein Runbook für die häufigsten Fehlermodi
Für zuverlässigkeitsorientierte Engineering-Praktiken ist Wolf-Techs Backend-Reliability-Best-Practices eine starke nächste Lektüre.
Anti-Muster in der Wachstumsphase
- „Wir fügen Monitoring später hinzu." Später kommt als Ausfall.
- „Lass uns Microservices machen, um zu skalieren." Oft skalieren Sie zuerst die Koordinationskosten.
- „Wir brauchen einfach mehr Entwickler." Ohne Grenzen und Lieferdisziplin erhalten Sie nur mehr Merge-Konflikte und Incidents.
Phase 5: Skalierung – Mehrteilige Teamautonomie und Governance
Skalierung ist nicht nur mehr Last. Es sind mehr Teams, mehr parallele Workstreams, mehr Compliance-Oberfläche und mehr Kostensensitivität.
Ihre Roadmap sollte sich in Richtung Standardisierung von querschnittlichen Belangen verschieben, während Teams weiterhin agieren können.
Was zuerst zu standardisieren ist (hoher Hebel)
Standardisieren Sie, was Koordinationskosten und Produktionsrisiken über Teams hinweg reduziert:
- Identitäts- und Zugriffsmuster
- Contract-Disziplin für APIs und Events
- Umgebungsförderung und Release-Mechanismen
- Observability-Konventionen (Benennung, Dashboards, Alerts)
- Sicherheits-Baseline und Supply-Chain-Kontrollen
Dies ist abgestimmt mit Wolf-Techs breiterem Leitfaden zu was zuerst zu standardisieren ist.
„Paved Path"-Plattformdenken
Im Scale-Stadium funktionieren interne Plattformen am besten, wenn sie als Produkte behandelt werden. Der gepflasterte Pfad sollte das Richtige zur einfachsten Sache machen:
- Eine Vorlage für Services/Apps mit CI/CD, Sicherheitsprüfungen und Observability eingebaut
- Self-Service-Umgebungen (oder zumindest Self-Service-Deploy)
- Gemeinsame Bibliotheken für Verträge, Auth und Telemetrie, die versioniert und verwaltet sind
Kosten und Performance werden erstklassig
Mit wachsender Nutzung brauchen Sie Unit-Economics und Performance-Budgets, nicht nur „scheint okay".
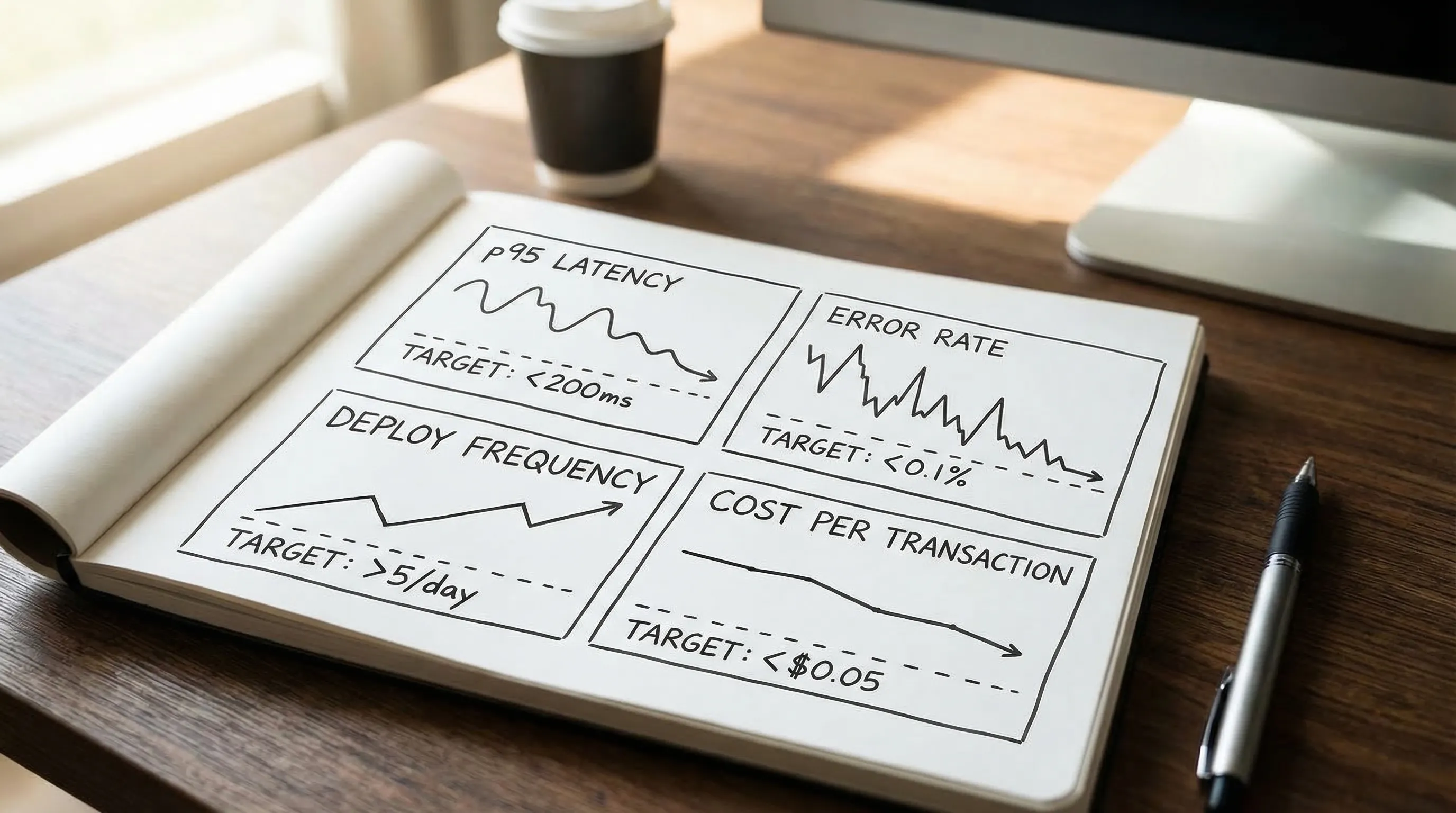
Ein praktisches Scale-Dashboard enthält oft:
- Kosten pro aktivem Kunden, Tenant oder Transaktion
- p95 und p99 Latenz für die kritischen Flows
- Datenwachstumsrate und Speicherkostentrend
- Queue-Verzögerung / Hintergrund-Job-Verzögerung (falls anwendbar)
Wann Skalierungstechniken einzuführen sind (ohne vorzeitige Komplexität)
Viele Teams fragen: „Wann brauchen wir Microservices?" Die umsetzbarere Frage ist: „Welchen Engpass treffen wir?"
Nutzen Sie Engpässe, um Techniken zu wählen:
| Engpass | Typische Symptome | Wirkungsvolle erste Maßnahmen | Was früh zu vermeiden ist |
|---|---|---|---|
| Datenbank-Engpässe | p95-Spikes, Lock-Contention, langsame Abfragen | Indexierung, Query-Optimierung, Read-Replicas, Caching, Async-Write-Pfade | Sharding als erste Reaktion |
| Langsame Releases | Große PRs, flaky Tests, lange QA-Zyklen | Trunk-basierter Flow, kleinere Slices, Preview-Envs, Feature Flags | Ein „Release-Train", der alles bündelt |
| Fragile Integrationen | Incidents nach Partner-Änderungen | Contract-Tests, Timeouts/Retries, Idempotenz, Circuit-Breaker | Enge Kopplung und implizite Payload-Annahmen |
| Team-Koordinations-Overhead | Abhängigkeitsgitter, unklare Zuständigkeit | Modulare Grenzen, explizite Verträge, Zuständigkeitskarte | In Services aufteilen ohne Grenzen |
| Kostenexplosionen | Cloud-Ausgaben wachsen schneller als Nutzung | Budget-Alerts, Right-Sizing, Caching-Disziplin, Kosten-pro-Unit-Metriken | Kosten optimieren ohne Produkt-Unit-Metriken |
Wenn Sie am Ende mehrere Services adoptieren, behandeln Sie das als Änderung des Betriebsmodells (Observability, Deployments, Zuständigkeit) – nicht nur als Code-Refactoring.
Ein praktischer 90-Tage-Plan: MVP zur Skalierungsbereitschaft
Wenn Sie einen konkreten Startplan brauchen, hier ist eine einfache 90-Tage-Sequenz, die zu vielen Teams passt.
Tage 0 bis 30: Auslieferung sicher machen
Fokus: Liefer- und Feedback-Schleifen.
- CI, automatisches Deploy und ein wiederholbares Release etablieren
- Einen dünnen vertikalen Schnitt durch den risikoreichsten Pfad bauen
- Basis-Telemetrie (Logs, Metriken, Tracing) für den Schnitt hinzufügen
- Eine minimale Definition of Done definieren, die Betreibbarkeit einschließt
Tage 31 bis 60: Produktion vorhersagbar machen
Fokus: Zuverlässigkeit, Umkehrbarkeit und Unterstützbarkeit.
- Progressive Delivery hinzufügen (Feature Flags, Canary oder Äquivalent)
- Erste SLOs für den Kernflow definieren und auf Nutzerauswirkungen alerten
- Ein Runbook und eine Incident-Review-Gewohnheit erstellen
- Datenmigration und Backup-/Wiederherstellungstests härten
Tage 61 bis 90: Wachstum günstiger machen
Fokus: Grenzen und Durchsatz.
- Nach Business-Capability modularisieren, grundlegende Abhängigkeitsregeln durchsetzen
- Contract-Disziplin einführen (Schemas, Versionierung, Contract-Tests)
- Performance-Budgets für kritische Seiten/APIs hinzufügen
- DORA-Metriken verfolgen und Verbesserungsziele setzen
Dieser Plan ergänzt gut Wolf-Techs breitere Perspektive zu Softwarelösungen entwickeln, die wirklich skalieren.
Wie Wolf-Tech helfen kann (ohne Sie zu binden)
Wenn Sie eine neue Anwendung bauen oder ein MVP weiterentwickeln wollen, das zu knarren beginnt, hilft Wolf-Tech Teams mit:
- Full-Stack-Entwicklung für individuelle Anwendungen
- Code-Qualitätsberatung und Legacy-Code-Optimierung
- Architektur- und Tech-Stack-Strategie für die nächsten 12 bis 36 Monate
- Cloud-, DevOps-, Datenbank- und API-Lösungen für Skalierungsbereitschaft
Wenn Sie einen zweiten Blick erfahrener Senior-Entwickler auf Ihre Roadmap wünschen, ist der schnellste Weg meist ein fokussierter Review Ihrer Outcomes, NFRs, Thin-Slice-Plans und Liefersystems. Wolf-Tech ist erreichbar über die Hauptseite unter wolf-tech.io.