
App-Technologien: Den richtigen Stack für Ihren Anwendungsfall wählen


Die Wahl von App-Technologien geht selten darum, das „beste" Framework zu finden. Es geht darum, einen Stack zu wählen, der Ihr spezifisches Produkt in den nächsten 12 bis 36 Monaten leichter lieferbar, sicherer änderbar und günstiger betreibbar macht.
Die Falle besteht darin, den Stack als einmalige Branding-Entscheidung zu behandeln („wir sind ein Rust-Shop" oder „wir machen Microservices"). In der echten Lieferung ist Ihr Stack eine Reihe von Kompromissen bei Performance, Einstellung, Zuverlässigkeit, Compliance und wie schnell Ihr Team in der Produktion lernen kann.
Dieser Leitfaden gibt Ihnen einen pragmatischen Weg, den richtigen Stack für Ihren Anwendungsfall zu wählen, plus mehrere bewährte „Stack-Rezepte", die Sie anpassen können, ohne blind zu kopieren.
Beginnen Sie mit dem Anwendungsfall, nicht dem Tool
Bevor Sie Frameworks vergleichen, fixieren Sie die Einschränkungen, die wirklich die Stack-Passung bestimmen. Für die meisten Teams bestimmen diese fünf Inputs 80 Prozent des Ergebnisses.
1) Was für eine App ist es (und wo läuft sie)?
„App" kann bedeuten:
- Eine öffentliche Web-App, bei der SEO und erster Ladevorgang wichtig sind
- Ein eingeloggtes B2B-SaaS-Dashboard
- Ein Mobile-first-Konsumentenprodukt
- Ein internes Tool mit vielen Formularen und Workflows
- Eine Echtzeit-Kollaborationserfahrung
Jedes treibt Sie zu unterschiedlichen Rendering-Strategien, Caching, Offline-Verhalten und Deployment-Zielen. Wenn Sie eine Auffrischung der beweglichen Teile benötigen, ist Wolf-Techs Tieftauchen über wie Webanwendungen von Ende zu Ende funktionieren eine gute Ausgangsbasis.
2) Ihre nicht-funktionalen Anforderungen (NFAs) in messbaren Begriffen
Wenn Sie es nicht messen können, können Sie auch nicht dafür wählen. Übersetzen Sie „schnell" und „zuverlässig" in Ziele:
- Performance: Core Web Vitals für Web (LCP, CLS, INP), p95-API-Latenz
- Zuverlässigkeit: Verfügbarkeitsziel, Fehlerbudget, RTO/RPO
- Änderungssicherheit: erwartete Deploy-Häufigkeit, akzeptable Änderungsfehlerrate
- Sicherheit und Compliance: Datenklassifizierung, Audit-Logging-Anforderungen, Aufbewahrung
Ein Stack, der in einer Demo großartig aussieht, kann unter NFAs zusammenbrechen, sobald Sie Auth, Caching, Observability, Migrationen und Produktionstraffic hinzufügen.
3) Datenform und Integrationsoberfläche
Daten und Integrationen dominieren oft die Komplexität mehr als UI oder Sprachauswahl:
- Transaktionale Workflows und Reporting bevorzugen tendenziell zuerst relationale Datenbanken
- Hohe Fan-out-Integrationen bevorzugen klare API-Grenzen und asynchrone Muster
- Echtzeit-Features erfordern sorgfältiges Zustands- und Event-Design
4) Team-Topologie und Fähigkeiten (heute, nicht aspirativ)
Eine „perfekte" Architektur, die Ihr Team nicht betreiben kann, verliert jedes Mal gegen eine einfachere Ausgangslage. Seien Sie ehrlich über:
- Was Ihre Ingenieure um 2 Uhr nachts debuggen können
- Was Sie auf Ihrem Markt einstellen können
- Ob Sie Plattform- oder SRE-Kapazität haben
5) Zeithorizont und Produktunsicherheit
Wenn Ihre Produktanforderungen noch in Bewegung sind, optimieren Sie für Lerngeschwindigkeit und reversible Entscheidungen. Wenn Sie ein umsatzkritisches System modernisieren, optimieren Sie für Sicherheit und inkrementelle Änderung.
Ein praktisches 4-Schichten-Modell zur Auswahl von App-Technologien
Die meisten modernen App-Stacks können als vier Schichten bewertet werden. Das verhindert „Framework-Fixierung" und hält Entscheidungen vergleichbar.
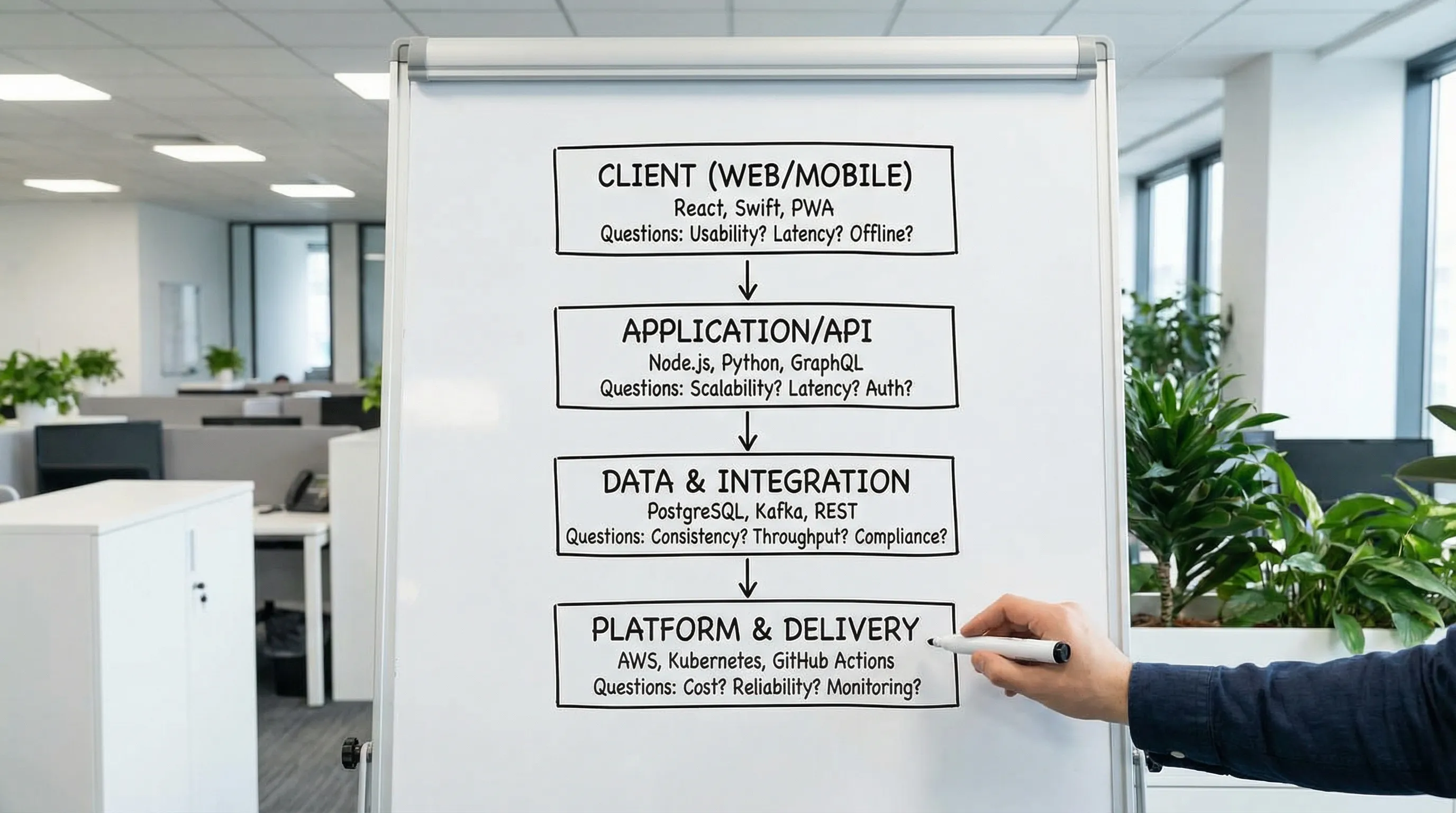
Schicht 1: Client und UI-Lieferung
Schlüsselfragen:
- Benötigen Sie SEO, teilbare URLs und schnelles erstes Rendering?
- Ist die App hauptsächlich authentifiziert und interaktiv?
- Benötigen Sie Offline-Support oder native Fähigkeiten?
Hier entscheiden Sie Muster wie MPA vs SPA, SSR vs SSG/ISR oder native vs Cross-Plattform.
Schicht 2: Anwendungs-Backend und API-Stil
Schlüsselfragen:
- Ist Ihre Domain hauptsächlich CRUD oder haben Sie komplexe Workflows?
- Benötigen Sie starke Grenzenkontrolle (BFF, Gateway, Verträge)?
- Benötigen Sie Echtzeit, Hintergrundjobs oder Event-Verarbeitung?
API-Stil ist ein Mittel, keine Identität. REST, GraphQL und event-driven Muster können alle korrekt sein, abhängig von Clients, Caching und Autorisierung. (Wenn GraphQL auf dem Tisch liegt, stellen Sie sicher, dass Sie die operativen Fallstricke wie Query-Kosten und Autorisierungskomplexität verstehen. Wolf-Techs GraphQL-APIs-Leitfaden deckt die Kompromisse ab.)
Schicht 3: Daten und Integration
Schlüsselfragen:
- Was ist Ihr System of Record?
- Wie behandeln Sie Schema-Evolution und Migrationen sicher?
- Benötigen Sie Suche, Analytics oder Streaming?
Ein häufiger Fehler ist, früh eine „coole" Datenbank zu wählen und dann nachträglich Transaktionen, Prüfbarkeit und Reporting anzupassen.
Schicht 4: Plattform, Lieferung und Betrieb
Schlüsselfragen:
- Können Sie sicher und häufig deployen?
- Haben Sie grundlegende Observability (Logs, Metriken, Tracing)?
- Wie verwalten Sie Geheimnisse, IAM und Supply-Chain-Sicherheit?
Diese Schicht ist, wo Stacks zu realen Systemen werden. Wenn Sie nicht sicher sind, wie „gut" aussieht, ist Wolf-Techs Übersicht über CI/CD-Technologie eine solide Referenz.
Verwenden Sie eine Scorecard, die Belege erzwingt
Um meinungsgetriebene Debatten zu vermeiden, verwenden Sie eine einfache Scorecard, die nach Beweisen fragt. Sie brauchen keinen schweren Beschaffungsprozess, nur genug Struktur, um versteckte Kosten aufzudecken.
| Dimension | Was „gute Passung" bedeutet | Belege in einem 1-2 Wochen Spike sammeln |
|---|---|---|
| Liefergeschwindigkeit | Kleine Änderungen werden vorhersehbar geliefert | Pipeline läuft schnell, Previews existieren, Rollback ist einfach |
| Performance | Entspricht nutzerwahrgenommenen Zielen | Baseline Core Web Vitals, p95-Latenz, Lasttest-Notizen |
| Zuverlässigkeit | Ausfälle sind enthalten und wiederherstellbar | Timeouts, Wiederholungen, SLOs, Vorfallübungs-Ergebnisse |
| Sicherheit & Compliance | Risiken sind standardmäßig kontrollierbar | OWASP-konforme Kontrollen, Audit-Logging-Plan, Geheimnis-/IAM-Ansatz |
| Daten-Evolution | Schema-Änderungen sind sicher | Migrationsstrategie, Backfill-Ansatz, Versionierungsregeln |
| Team-Passung | Von Ihrem Team debuggbar | On-Call-Simulation, „neuer Dev"-Setup-Zeit, Runbook-Klarheit |
| Kostenkontrolle | Kosten skalieren vorhersehbar | Kostenmodell für Compute, Datenbank, Observability, CI |
| Langlebigkeit | Upgrades sind machbar | Upgrade-Kadenz, Abhängigkeits-Gesundheit, LTS-Haltung |
Für Sicherheits-Baselines ist es vernünftig, sich mit weithin akzeptierten Richtlinien wie der OWASP Top 10 und modernen sicheren Entwicklungspraktiken wie dem NIST SSDF auszurichten.
Stack-Rezepte nach Anwendungsfall (und warum sie funktionieren)
Das Ziel hier ist nicht, einen einzigen wahren Stack vorzuschreiben. Es ist, die Arten von Kombinationen zu zeigen, die tend to erfolgreich sein, und die Fehlertypen zu beobachten.
Anwendungsfall A: Öffentliche Web-App, bei der SEO und Performance wichtig sind
Typische Beispiele: Marketing plus Produkt, inhaltsgesteuerte Akquise, E-Commerce-Kataloge, Dokumentationsseiten mit eingeloggten Bereichen.
Was am wichtigsten ist:
- Schnelles initiales Laden, gute Core Web Vitals
- Vorhersehbares Caching und Inhaltsfrische
- Sichere Edge-Grenzen (Rate-Limiting, Bot-Abwehr)
Häufige Technologieform:
- UI: React mit einem Meta-Framework, das SSR/SSG/ISR-Muster unterstützt (zum Beispiel Next.js)
- Backend: API-Routen/BFF plus Service-Schicht oder separate Backend-Dienste
- Daten: Postgres für Kerndaten, Redis für Caching (optional)
- Plattform: CDN, Edge-Caching, Observability von Tag eins
Wenn Next.js in Ihrem Weg liegt, ist Performance-Arbeit einfacher, wenn Sie zuerst messen und Budgets als Teil der Lieferung behandeln. Wolf-Techs Next.js Performance-Tuning-Leitfaden geht tief in praktische Diagnose.
Häufige Fallstricke:
- Zu viel Client-JavaScript liefern und es „modern" nennen
- Caching als Nachgedanken behandeln und dann später gegen Veraltung und TTFB kämpfen
- Drittanbieter-Skripte die Performance zerstören lassen ohne Leitplanken
Anwendungsfall B: B2B-SaaS-Dashboard (authentifiziert, workflow-schwer)
Typische Beispiele: Admin-Konsolen, Analyse-Dashboards, Operations-Tools, Multi-Mandanten-SaaS.
Was am wichtigsten ist:
- Autorisierungskorrektheit und Prüfbarkeit
- Konsistente UI-Muster und Formularerliability
- Sichere Schema-Änderungen und langfristige Wartbarkeit
Häufige Technologieform:
- UI: React-basiertes SPA oder hybrides Rendering, starke Komponentenkonventionen
- Backend: Ein „langweiliger" modularer Monolith gewinnt früh oft (klare Module, ein Deployment, starke Tests)
- Daten: Relational zuerst (Postgres), mit Read-Models für Reporting wenn nötig
- Plattform: Starkes CI/CD, Contract-Testing für Integrationen, Feature-Flags für sicherere Releases
Das ist auch, wo Architektur-Review sich auszahlt. Wenn Sie eine konkrete Perspektive wollen, passt Wolf-Techs Checkliste darüber, was ein Tech-Experte in Ihrer Architektur überprüft, gut zu SaaS-Realitäten.
Häufige Fallstricke:
- RBAC-Komplexität und Mandantenisolierung unterschätzen
- Ein Microservices-Netz aufbauen, um sich „auf Skalierung vorzubereiten", bevor stabile Grenzen existieren
- Betreibbarkeit überspringen und dann feststellen, dass Sie das Produktionsverhalten nicht erklären können
Anwendungsfall C: Mobile-first-Konsumentenapp (natives Gefühl, schnelle Iteration)
Typische Beispiele: Marktplatz, Gewohnheits-Apps, Konsumenten-Fintech, soziale Netzwerke.
Was am wichtigsten ist:
- App-Store-Release-Management und Rückwärtskompatibilität
- Offline-Toleranz und instabile Netzwerkbehandlung
- Analytics und Experimente mit Datenschutz im Sinn
Häufige Technologieform:
- Client: Natives iOS/Android oder Cross-Plattform (React Native, Flutter) wenn Team-Passung und UI-Anforderungen ausrichten
- Backend: Gut versionierte APIs, explizite Kompatibilitätsregeln, Idempotenz
- Daten: Relational für Transaktionen, Objektspeicher für Medien
- Plattform: Mobile CI, gestaffelte Rollouts, Absturzberichte, Feature-Flags
Häufige Fallstricke:
- Mobile-Releases wie Web-Deploys behandeln (sind sie nicht)
- Keine API-Versionierungsstrategie, die zu erzwungenen Upgrades und kaputten Clients führt
- Fehlende Observability für die „Client-Seite" von Fehlern (Netzwerk, Gerät, OS)
Anwendungsfall D: Echtzeit-Features (Kollaboration, Live-Updates, Chat)
Typische Beispiele: kollaboratives Bearbeiten, Live-Dashboards, Logistik-Tracking, Chat und Präsenz.
Was am wichtigsten ist:
- Vorhersehbare Latenz unter Last
- Korrektheit bei gleichzeitigen Updates
- Backpressure und Fehlereindämmung
Häufige Technologieform:
- Transport: WebSockets oder Server-sent Events wo angemessen
- Backend: Event-driven Muster, Hintergrundarbeiter, sorgfältiges Zustandsmanagement
- Daten: Ein System of Record plus ein Niedriglatenz-Zustandsspeicher (oft Redis), append-only Logs für Audit wenn nötig
- Plattform: Lasttest, Verbindungsmanagement, Observability, die Events von Ende zu Ende folgen kann
Häufige Fallstricke:
- „Echtzeit" als unkontrolliertes Polling implementiert
- Keine Strategie für Wiederverbindung, Reihenfolge und Idempotenz
- Verbindungen skalieren ohne an Fan-out-Kosten zu denken
Anwendungsfall E: Regulierte oder hochsichere Apps (Finanzen, Gesundheitswesen, Enterprise)
Typische Beispiele: Zahlungsflows, Risikosysteme, Systeme mit strengen Audit-Anforderungen.
Was am wichtigsten ist:
- Prüfbarkeit, Datenherkunft und Least-Privilege-Zugriff
- Sichere Software-Supply-Chain und Änderungskontrolle
- Reproduzierbare Builds und Belege für Compliance
Häufige Technologieform:
- Architektur: Weniger bewegliche Teile früh, explizite Grenzen, starkes Logging und Rückverfolgbarkeit
- Daten: Starke transaktionale Garantien, Aufbewahrungsregeln, Verschlüsselungspraktiken
- Lieferung: Enge Qualitätsgatter, Abhängigkeits-Scanning, Infrastructure as Code, kontrollierte Rollouts
Häufige Fallstricke:
- Compliance auf einen Stack aufpfropfen, der nicht darauf ausgelegt ist, Belege zu produzieren
- Architektur überkomplizieren, bevor Sie operative Reife haben
- Nicht von Anfang an für Datenaufbewahrung, Löschung und Audit-Abfragen planen
Monolith, Microservices oder Serverless: wählen Sie basierend auf Betriebsfähigkeit
Das sind eher Architekturentscheidungen als „App-Technologien", aber sie beeinflussen die Stack-Auswahl stark.
| Ansatz | Wann er tendenziell passt | Was Teams unterschätzen |
|---|---|---|
| Modularer Monolith | Die meisten frühen Produkte, viele SaaS-Backends, Legacy-Modernisierung via Nähte | Modulgrenzen und Abhängigkeitsdisziplin |
| Microservices | Klare Domain-Grenzen, mehrere Teams, unabhängige Skalierungsbedarfe | Betriebsoverhead, verteiltes Debugging, Konsistenz und Versionierung |
| Serverless | Unregelmäßige Workloads, event-driven Klebstoff, schnelle Experimente | Kaltstarts, lokale Dev-Komplexität, Vendor-Kopplung, Observability-Kosten |
Eine nützliche Regel: Wenn Sie kein exzellentes CI/CD und Observability auf einem Monolith betreiben können, werden Microservices Sie nicht retten. Sie werden Ihre Probleme verstärken.
Den Stack mit einem dünnen vertikalen Slice validieren
Der schnellste Weg, einen Stack zu wählen, ist, einen kleinen, produktionsähnlichen Slice zu liefern, der Sie zwingt, mit der Realität zu konfrontieren. Das vermeidet „Beweis per Foliensatz".
Ihr Slice sollte beinhalten:
- Eine echte Nutzer-Journey von Ende zu Ende (UI, Auth, API, Datenschreiben, Datenlesen)
- Eine Integration (sogar eine gemockte externe API mit Contract-Tests)
- Eine Migration (Schema-Änderung), um Ihren Evolutionspfad zu testen
- Grundlegende Liefer- und Sicherheitsmechanismen (CI, Deployment, Rollback)
- Minimale Observability (strukturierte Logs, Schlüsselmetriken, Tracing wo möglich)
Wenn Sie eine konkrete Liefer-Checkliste für diesen Ansatz wollen, passt Wolf-Techs MVP-Checkliste für schnellere Launches gut zur Stack-Validierung.
Was während der Validierung gemessen werden sollte
Wählen Sie einige Metriken, die direkt Ihrem Anwendungsfall entsprechen. Zum Beispiel:
- Web: Core Web Vitals, TTFB, p95-Routen-Latenz
- Backend: p95-Latenz pro Endpunkt, Fehlerrate, Sättigungssignale
- Lieferung: Lead-Time für Änderungen, Deploy-Häufigkeit, Änderungsfehlerrate, MTTR (die DORA-Kernmetriken sind eine gemeinsame Basis, siehe das DORA-Forschungsprogramm)
Der Punkt ist nicht, in Woche eins perfekte Zahlen zu erreichen. Es ist zu beweisen, dass Sie instrumentieren, verbessern und Rückschritte vermeiden können.
Für Optionalität gestalten (damit Ihr Stack sich entwickeln kann)
Stacks scheitern, wenn Teams versehentlich einsperren. Sie können Flexibilität bewahren, ohne zu verlangsamen.
Grenzen explizit halten
- Gut definierte API-Verträge zwischen UI und Backend verwenden
- Domain-Code von Frameworks wo praktisch trennen
- Wichtige Entscheidungen mit leichtgewichtigen Architecture Decision Records (ADRs) dokumentieren
Offene Schnittstellen an Integrationspunkten bevorzugen
- HTTP, OAuth/OIDC, S3-kompatible Objektspeichermuster, SQL wo es passt
- Event-Formate, die versioniert und dokumentiert sind
Eine Ausstiegsspur für Legacy und zukünftige Änderungen bauen
Wenn Sie modernisieren, bevorzugen Sie inkrementelle Muster (Strangler-Style-Änderungen, Feature-Flags, Canaries) gegenüber großen Neuprogrammierungen. Wolf-Techs Anleitung zur Modernisierung von Legacy-Systemen ohne Geschäftsunterbrechung zeigt, wie man Änderungen reversibel hält.
Eine schnelle „Stack-Passung"-Checkliste für Entscheidungstreffen
Verwenden Sie diese, wenn Sie mit Stakeholdern konvergieren müssen (Produkt, Engineering, Sicherheit).
- Können wir in diesem Stack innerhalb von 2 bis 4 Wochen einen dünnen vertikalen Slice in die Produktion liefern?
- Haben wir eine klare Baseline für Performance, Zuverlässigkeit und Sicherheit?
- Was ist unser Plan für Schema-Änderungen, Backfills und Datenmigrations-Sicherheit?
- Wie werden wir Auth, Rollen/Berechtigungen und Audit-Logs machen?
- Wie sieht „Debugging in Produktion" aus (Logs, Metriken, Traces, Runbooks)?
- Können wir diesen Stack für mindestens 2 Jahre einstellen, onboarden und warten?
- Welche Entscheidungen sind reversibel und was würde es kosten, sie umzukehren?
Wenn Sie diese nicht beantworten können, haben Sie noch keine Stack-Entscheidung, sondern eine Präferenz.
Wo Wolf-Tech helfen kann
Wenn Sie App-Technologien für einen Neubau wählen, ein bestehendes Produkt skalieren oder Legacy-Code modernisieren, ist der schnellste Weg in der Regel eine evidenzgestützte Bewertung plus ein Thin-Slice-Implementierungsplan.
Wolf-Tech unterstützt Teams mit Full-Stack-Entwicklung, Tech-Stack-Strategie, Legacy-Code-Optimierung, Codequalitätsberatung sowie Cloud- und DevOps-Guidance, mit Fokus auf messbare Ergebnisse und sichere Lieferung.
Wenn Sie eine zweite Meinung zu Ihrer Shortlist wünschen oder einen praktischen Plan benötigen, sie schnell zu validieren, beginnen Sie mit einem Architektur-Review oder einer kurzen Discovery, die eine Stack-Scorecard, Risiken und einen schrittweisen Pilot-Scope produziert.