
Build Stack: Ein einfacher Blueprint für moderne Produktteams


Moderne Produktteams scheitern nicht, weil sie das „falsche Framework" gewählt haben. Sie scheitern, weil sie keinen Build Stack haben, der Ideen zuverlässig in sichere, messbare Produktionsänderungen verwandelt – immer wieder.
In diesem Artikel bedeutet „Build Stack" den End-to-End-Blueprint, der folgendes verbindet:
- Produktabsicht (welches Ergebnis wir anstreben)
- Engineering-Realität (wie wir es bauen)
- Betriebswahrheit (wie es sich in der Produktion verhält)
Wenn diese Verbindungen klar beschreibbar sind, kann man schneller liefern, mit weniger Überraschungen, und Produkt und Team skalieren, ohne den Prozess jedes Quartal neu zu erfinden.
Was ein „Build Stack" umfasst (er ist größer als ein Tech-Stack)
Die meisten Teams haben bereits einen Tech-Stack (Frontend, Backend, Datenbank, Cloud). Der Build Stack fügt die Teile hinzu, die bestimmen, ob dieser Tech-Stack unter echten Einschränkungen tatsächlich nutzbar ist.
Ein praktischer Build Stack umfasst fünf Fähigkeitsbereiche:
- Produkt- und Entscheidungsinputs (Ergebnisse, Nutzer, Einschränkungen, nicht-funktionale Anforderungen)
- Architektur-Baseline (Grenzen, Dateneigentümerschaft, Integrationsstil, wichtige Abwägungen)
- Delivery-System (CI/CD, Umgebungen, Release-Strategie, Rollback)
- Qualitäts- und Security-Baseline (Teststrategie, Code-Qualitätsgates, Supply-Chain-Kontrollen)
- Betreibbarkeit (Observability, Grundlagen der Incident-Reaktion, Performance-Budgets, Kostentransparenz)
Das erklärt, warum zwei Teams mit demselben Cloud-Anbieter und Framework völlig unterschiedliche Ergebnisse erzielen können.
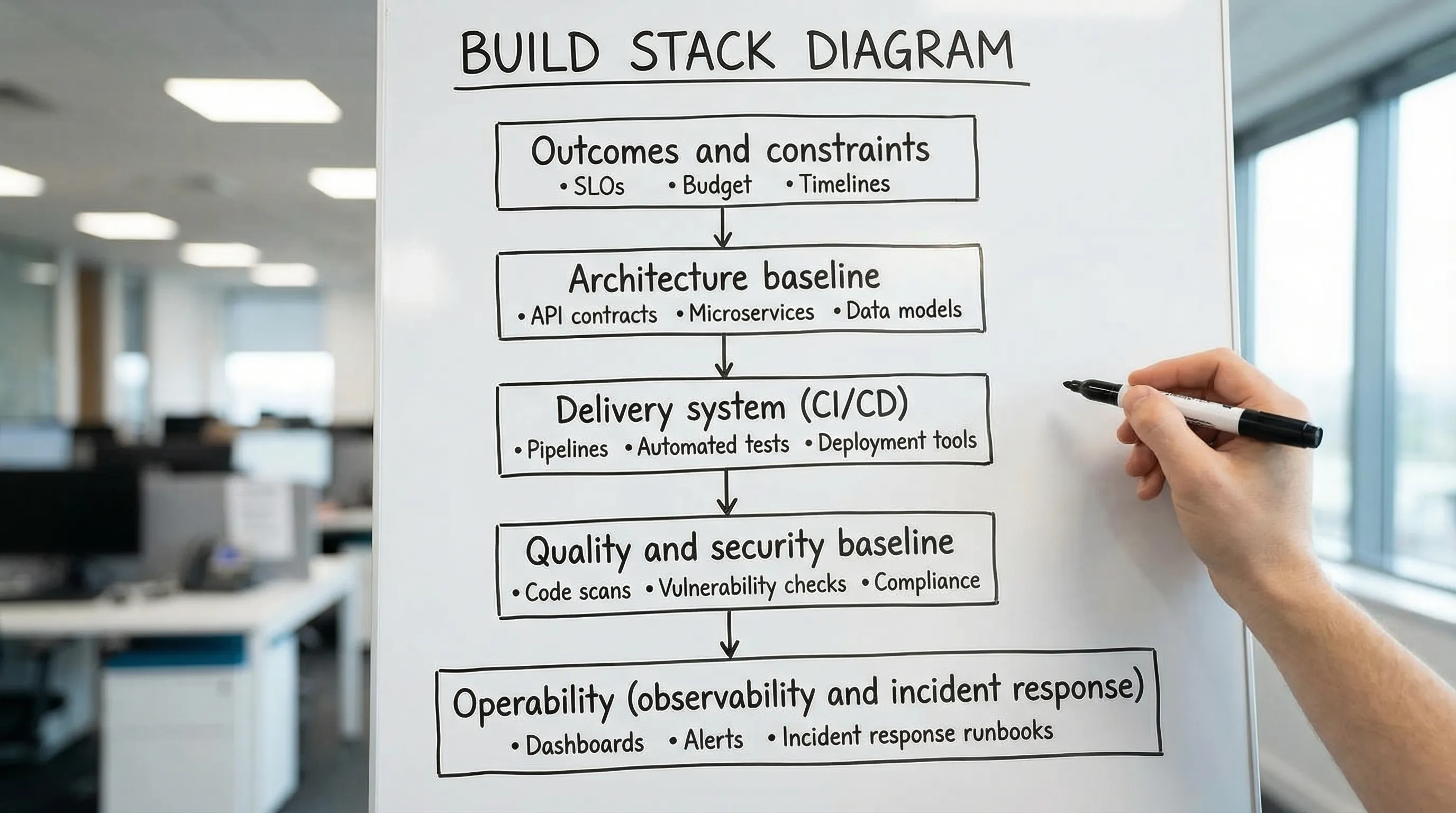
Der Build-Stack-Blueprint (ein einfaches Einseitenmodell)
Das Ziel ist nicht, alles zu dokumentieren. Es geht darum, die wichtigsten Entscheidungen explizit zu machen und zu definieren, was „gut" anhand beobachtbarer Belege bedeutet.
Die folgende Tabelle als einseitiger Build-Stack-Canvas nutzen. In einem kurzen Workshop mit Product, Engineering und wer auch immer Operations verantwortet (auch wenn das „die Devs" sind) ausfüllen.
| Build-Stack-Bereich | Die Entscheidung, die getroffen werden muss | „Guter" Beleg (worauf man zeigen kann) |
|---|---|---|
| Ergebnisse und Einschränkungen | Worauf optimieren wir in den nächsten 90 Tagen (und worauf nicht)? Was sind die Top-3-NFRs? | Ein kurzes Ergebnis-Brief, 3 messbare NFRs (Latenz, Uptime, Compliance, Kosten) und eine klare „Nicht-do"-Liste |
| Architektur-Baseline | Was sind die Hauptgrenzen, Dateneigentümerschaftsregeln und der Integrationsstil? | Ein leichtgewichtiges Architekturdiagramm, wichtige ADRs und mindestens ein dünner vertikaler Slice in Prod |
| Delivery-System | Wie fließen Änderungen sicher und wiederholbar von Commit zu Produktion? | Funktioniegende CI-Pipeline, automatisiertes Deploy in eine Nicht-Prod-Umgebung und ein reversibler Produktions-Release-Pfad |
| Qualitäts- und Security-Baseline | Was verhindern wir automatisch, was prüfen wir? | Tests in CI, Code-Qualitätschecks, Dependency-Scanning, Secret-Handling und eine Definition of Done |
| Betreibbarkeit | Wie wissen wir, dass es gesund ist, und wie erholen wir uns, wenn es das nicht ist? | Dashboards/Alerts für wichtige User-Flows, strukturierte Logs, Traces wo nötig und eine grundlegende On-Call- oder Incident-Routine |
Wenn sich das nach „viel" anfühlt: Jede Zeile kann zunächst auf einem Minimum-Viable-Level implementiert werden. Der Blueprint geht um Abdeckung und Klarheit, nicht um Vergoldung.
Schritt 1: Mit Ergebnissen und messbaren Einschränkungen beginnen (nicht mit Features)
Wer das überspringt, macht alles nachgelagerte meinungsbasiert.
Ein nützliches Format:
- Ergebnis: Was ändert sich für das Unternehmen oder den Nutzer
- Führender Indikator: Was wöchentlich messbar ist
- Leitplanken: Was nicht zurückgehen darf (Security, Zuverlässigkeit, Performance, Kosten)
Beispieleinschränkungen, die bei der Produktlieferung 2026 wichtig sind:
- Performance-Ziele verknüpft mit echter UX (Core Web Vitals für Web-Apps)
- Zuverlässigkeitsziele ausgedrückt als SLOs und Error-Budgets
- Security-Kontrollen abgestimmt auf das eigene Risikoniveau (für manche Teams reichen OWASP-Grundlagen; für regulierte Teams braucht man evidenzbasierte Kontrollen)
Eine tiefere Methode zur Übersetzung von UX-Bedürfnissen in Architektureinschränkungen bietet Wolf-Techs „Handshake"-Modell: UX-to-Architecture-Handshake.
Schritt 2: Eine Architektur-Baseline definieren, die Optionalität erhält
Der Build Stack braucht eine standardmäßige Architekturform, damit Teams liefern können, ohne Grundlagen immer wieder neu zu debattieren.
Für viele Produktteams ist die pragmatischste Baseline:
- Früh ein modularer Monolith (klare interne Grenzen, ein Deployable)
- Explizite API-Verträge (auch innerhalb des Monolithen)
- Klare Dateneigentümerschafts-Regeln pro Bounded Context
Das ist nicht anti-Microservices. Es ist pro-Evidenz. Man kann zu Services wechseln, wenn man beweisen kann, dass man unabhängige Skalierung, Deployment-Autonomie oder Isolation braucht.
Ein einfaches „Baseline-Paket":
- Ein Kontext- und Container-Diagramm (C4-Stil ist gut)
- 3–7 Architecture Decision Records (ADRs)
- Ein dünner vertikaler Slice, der UI, API, Daten, Auth und Deployment berührt
Für eine Referenz, worauf ein Experte achtet, diese Baseline abstimmen mit: Was ein Tech-Experte in deiner Architektur prüft.
Schritt 3: CI/CD als Teil des Build Stacks behandeln, nicht als DevOps-Nachgedanke
Moderne Teams gewinnen, indem sie Feedback-Schleifen verkürzen und Deployment-Risiken reduzieren. Das ist Delivery-System-Arbeit.
Das Minimum-Viable-Delivery-System sollte Folgendes unterstützen:
- Schnelle, wiederholbare Builds
- Automatisierte Tests und Qualitätsgates
- Artifact-Versionierung
- Automatisiertes Deploy in eine Testumgebung
- Einen Produktions-Deployment-Pfad mit eingebautem Rollback (oder Forward-Fix)
Der Grund ist einfach: Wenn Releases angsteinflößend sind, hört das Lernen auf.
Für eine praktische Aufschlüsselung der Bausteine und einen 0–90-Tage-Adoptionsplan: CI/CD-Technologie: schneller bauen, testen, deployen.
Für Teams, die ein forschungsbasiertes Messmodell wollen, sind die DORA-Metriken (Deployment-Frequenz, Lead Time, Change-Failure-Rate, Time-to-Restore) eine nützliche Linse. Die DevOps Research and Assessment (DORA)-Arbeit von Google ist hier zusammengefasst: DORA research.
Schritt 4: Eine Qualitäts-Baseline setzen, die mit der Teamgröße skaliert
Qualität bedeutet nicht „mehr Tests". Es ist die Kombination von Praktiken, die Änderungen sicher hält, wenn Codebase und Team wachsen.
Eine pragmatische Baseline umfasst typischerweise:
- Eine klare Teststrategie (Unit, Integration und mindestens ein End-to-End-kritischer Pfad)
- Kleine Pull Requests und vorhersehbare Review-Latenz
- Automatisierte Checks für Formatting, Linting und statische Analyse
- Eine „Keine kaputten Fenster"-Regel für flakige Tests
Metriken wählen, die Handlungen antreiben, keine Eitelkeitsmetriken. Ein hilfreicher Ausgangspunkt: Code-Qualitätsmetriken, die zählen.
Security-Baseline (proportional halten, realistisch bleiben)
Security im Build Stack geht darum, offensichtliche Fehler zu verhindern und Belege zu erzeugen, die dem eigenen Risikoniveau entsprechen.
Eine minimale Baseline umfasst oft:
- Dependency-Scanning und Patch-Hygiene
- Secrets-Management (keine Secrets in Repos, kurzlebige Credentials wo möglich)
- Sichere Standardwerte für Auth und Session-Handling
- Threat-Modeling für die wichtigsten User-Flows (sogar ein 60-minütiger Workshop hilft)
In regulierten Umgebungen den Prozess an anerkannten Leitlinien wie dem NIST Secure Software Development Framework (SSDF) ausrichten.
Schritt 5: Betreibbarkeit als erstklassiges Feature behandeln
Betreibbarkeit verwandelt „wir haben deployed" in „wir können dieses Produkt zuversichtlich betreiben."
Der Build Stack sollte definieren:
- Die wichtigsten User-Journeys und ihre Gesundheitssignale
- Was geloggt wird (und was nicht, z.B. sensible Daten)
- Wie Incidents erkannt und behoben werden
- Performance-Budgets, die schleichendes Verlangsamen verhindern
Ein einfacher Ausgangspunkt:
- 3 Dashboards: Traffic, Fehler, Latenz (pro kritischem Flow)
- 3 Alerts: Verfügbarkeit, Fehler-Spikes und ein „Etwas ist kaputt"-Synthetic-Check
- Eine leichtgewichtige Incident-Vorlage: Was passiert ist, Auswirkung, Erkennung, Schadensbegrenzung, Folgeaktionen
Wenn Reliability-Engineering Priorität hat, kann man das mit den defensiven Mustern ergänzen in: Backend Development Best Practices für Zuverlässigkeit.
Ein praktischer „Minimum Viable Build Stack" für ein neues Produktteam
Ein funktionierender Build Stack kann ohne Platform-Team oder monatelange Tooling-Arbeit aufgebaut werden.
Hier eine realistische Baseline, die für die meisten Early-Stage-Produktvorhaben passt:
| Fähigkeit | Minimum Viable Default | Was zu vermeiden ist |
|---|---|---|
| Architektur | Modularer Monolith, klare Module, dokumentierte Grenzen | Mit verteilten Microservices starten, weil „wir später skalieren werden" |
| Delivery | Eine CI-Pipeline, automatisierte Tests, Ein-Klick-Deploy, reversibler Release | Manuelle Deployments und Umgebungs-Snowflakes |
| Qualität | Unit + Integration Tests, 1–2 E2E-kritische Flows, PR-Größen-Leitplanken | 90%-Coverage anstreben, während Incidents weiter passieren |
| Security | Dependency-Scanning, Secret-Hygiene, grundlegendes Threat-Model, Least Privilege | Security erst nach der Integration von Payments oder PII nachzurüsten |
| Betreibbarkeit | Logs, Metriken, grundlegendes Tracing, Dashboards für Top-Journeys, SLO-Entwurf | Auf den ersten Ausfall warten, bevor Observability hinzugefügt wird |
Diese Baseline ist absichtlich einfach. Sie schafft Hebelwirkung: schnellere Iteration heute und weniger Rewrites beim Wachsen.
Wie man Tools wählt, ohne in Entscheidungslähmung zu verfallen
Tool-Entscheidungen sind wichtig, sollten aber nachgelagert zu Fähigkeiten sein.
Ein praktischer Auswahlansatz:
- Tools wählen, die zu den Team-Skills für die nächsten 12–24 Monate passen
- Langweiligen Standardwerten bevorzugen, wo das Ökosystem stark ist
- Mit einem dünnen vertikalen Slice validieren, dann committen
Wenn das Team gerade über Frameworks oder Cloud-Services diskutiert, kann man das Gespräch verankern mit: App-Technologien: den richtigen Stack für den Anwendungsfall wählen.
Ein 30-Tage-Rollout-Plan zur Implementierung des Build-Stack-Blueprints
Der Blueprint kann schnell implementiert werden, wenn er timegeboxt und auf Evidenz fokussiert wird.
Woche 1: Abstimmen und den Canvas definieren
Ergebnisse:
- Ergebnis-Brief (90-Tage-Horizont)
- Top-3-NFRs mit messbaren Zielen
- Build-Stack-Canvas mit Verantwortlichen pro Zeile ausgefüllt
Woche 2: Architektur-Baseline mit einem dünnen Slice beweisen
Ergebnisse:
- Funktionierender vertikaler Slice (UI zu Daten) in einer Nicht-Prod-Umgebung
- Erste ADRs (Grenzen, Dateneigentümerschaft, Integrationsstil)
- Ein einfaches Systemdiagramm, das der Realität entspricht
Woche 3: CI/CD und Qualitätsgates verdrahten
Ergebnisse:
- CI-Pipeline mit Tests und grundlegenden Qualitätschecks
- Automatisiertes Deploy in eine Preview- oder Testumgebung
- Klare Definition of Done (einschließlich Security- und Betreibbarkeits-Checks)
Woche 4: Produktionsreife und Betreibbarkeit hinzufügen
Ergebnisse:
- Instrumentierung für wichtige User-Journeys (Dashboards, Alerts)
- Release-Strategie dokumentiert (Rollback, Canary, Feature-Flags nach Bedarf)
- Erster SLO-Entwurf und eine Incident-Routine (auch wenn informell)
Für Teams, die einen breiteren Prozessrahmen dazu wollen, veröffentlicht Wolf-Tech auch einen leichtgewichtigen Lieferprozess, der gut zum Build-Stack-Konzept passt: Software bauen: ein praktischer Prozess für vielbeschäftigte Teams.

Häufige Build-Stack-Fehlermodi (und der Fix)
Fehlermodus: „Wir haben einen modernen Stack gewählt, warum ist die Lieferung noch langsam?"
Meistens fehlt das Delivery-System. Langsame Reviews, flakige Tests, manuelle Releases und unklare Umgebungen töten den Durchsatz.
Fix: CI/CD und Qualitätsgates als Produkt-Infrastruktur behandeln, Lead-Time und Failure-Rate messen und den größten Engpass zuerst beseitigen.
Fehlermodus: „Architektur-Debatten enden nie."
Das bedeutet oft, dass es keine gemeinsamen Einschränkungen oder keinen Beweis durch einen dünnen Slice gibt.
Fix: NFRs aufschreiben, eine Baseline wählen und mit einem vertikalen Slice validieren, der Deployment und Observability einschließt.
Fehlermodus: „Produktions-Incidents überraschen uns immer wieder."
Das ist eine Betreibbarkeits-Lücke, nicht nur eine Code-Qualitäts-Lücke.
Fix: Gesundheitssignale für Top-User-Journeys definieren, sie instrumentieren und einen grundlegenden Incident-Workflow etablieren.
Wann es sinnvoll ist, externe Hilfe zu holen
Ein Build Stack ist am einfachsten, wenn man neu startet. Er ist schwieriger, wenn man hat:
- Ein Legacy-System mit unklaren Grenzen und fragilen Releases
- Mehrere Teams, die in dieselbe Runtime liefern ohne gemeinsame Standards
- Regulatorische Anforderungen, die audit-fähige Belege erfordern
Wolf-Tech hilft Teams, pragmatische Build Stacks über Full-Stack-Entwicklung, Delivery-Systeme, Modernisierung und Code-Qualitäts-Consulting hinweg zu entwerfen und zu implementieren. Wenn du einen zweiten Blick auf deinen Blueprint möchtest (oder Hilfe bei der Umsetzung brauchst), starte hier: Wolf-Tech.