
Individuelle Softwareentwicklung: Scope, SLAs und Nachweise


Individuelle Softwareentwicklung zu kaufen geht weniger darum, „Features pro Sprint" zu zählen, als vielmehr darum, ein Liefersystem zu kaufen, dem Sie vertrauen können. Der schnellste Weg zur Risikoreduktion besteht darin, drei Dinge schriftlich zu fixieren, bevor die Arbeit beginnt:
- Scope (was „fertig" bedeutet und was nicht)
- SLAs/SLOs (wie Zuverlässigkeit, Support und Reaktion gemessen werden)
- Nachweise (Belege, dass der Anbieter das liefern kann, was er verspricht)
Dieser Leitfaden gibt Ihnen einen praxisnahen, vertragsfreundlichen Weg, Scope zu definieren, realistische Service-Level festzulegen und die richtigen Nachweise zu fordern, bevor Sie unterschreiben.
1) Scope: Was Sie wirklich kaufen
Scope ist keine Feature-Liste. Eine Feature-Liste ist ein Backlog, und Backlogs ändern sich. Ein brauchbarer Scope definiert die Systemgrenzen, messbare Ergebnisse, Constraints und Abnahmenachweise.
Ein starkes Scope-Paket beantwortet typischerweise:
- Welches Ergebnis wird angestrebt? (Umsatz, Kosten, Risiko, eingesparte Zeit)
- Was ist inbegriffen und was nicht? (Grenzen und Integrationen)
- Was muss in der Produktion zutreffen? (nicht-funktionale Anforderungen)
- Welche Artefakte existieren bei jedem Meilenstein? (Lieferergebnisse)
- Wie nehmen wir Arbeit ab? (Tests, Demos, Umgebungen, Kriterien)
- Wer verantwortet welche Entscheidungen und operative Arbeit? (RACI-Klarheit)
Für eine tiefere Vorlage zu Kickoff-Lieferergebnissen passt Wolf-Techs Leitfaden zu Software-Projekt-Kickoff: Scope, Risiken und Erfolgskennzahlen gut zum unten dargestellten Scope-Modell.
Die „Scope-Oberfläche", die die meisten Verträge übersehen
Teams einigen sich oft auf UI-Screens und User Stories, versäumen es aber, die Bereiche zu erfassen, die Kosten- und Zeitplanüberraschungen erzeugen. Diese Bereiche sollten explizit angesprochen werden:
- Integrationen und Datenverträge (APIs, Webhooks, Dateiaustausche, Rate-Limits)
- Identity und Autorisierung (SSO, RBAC, Tenant-Modell, Auditierbarkeit)
- Umgebungen (Dev, Staging, Produktion, Preview-Apps, Datenstrategie)
- Sicherheits- und Compliance-Verpflichtungen (Bedrohungsmodell, Logging, Aufbewahrung)
- Operative Bereitschaft (Monitoring, Alerting, Runbooks, On-Call)
- Migration (Daten-Backfill, Dual-Run, Cutover, Rollback)
- Performance- und Zuverlässigkeitsanforderungen (p95-Latenz-Ziele, Verfügbarkeit)
Für Web-Apps können Sie Ihren Scope mit den beschriebenen Kernsystemkomponenten abgleichen: Web Application: What Is It and How Does It Work? – ohne Ihren Vertrag in ein Architekturlehrbuch zu verwandeln.
Eine Scope-Checkliste, die auf echte Lieferergebnisse abbildet
Verwenden Sie die folgende Tabelle, um Scope messbar zu machen. Sie brauchen nicht alle Artefakte am ersten Tag, aber Sie möchten Einigkeit darüber, was produziert wird und wann.
| Scope-Bereich | Was zu klären ist (Käuferfragen) | Konkrete Lieferergebnisse (Scope-Nachweis) |
|---|---|---|
| Ergebnisse und Constraints | Was verändert sich im Unternehmen? Was ist das Budget und der Zeitrahmen? Was darf nicht brechen? | Einseitiger Ergebnisbriefing, Erfolgskennzahlen, Constraint-Liste |
| Systemgrenzen | Wofür ist das Produkt verantwortlich vs. externe Systeme? | Kontextdiagramm, Grenzliste, Integrationsinventar |
| Funktionaler Scope (thin slice first) | Was ist der kleinste End-to-End-Flow, der Wert in der Produktion beweist? | Thin-Vertical-Slice-Plan, priorisierter Backlog, Abnahmekriterien |
| Nicht-funktionale Anforderungen (NFRs) | Was sind die Performance-, Zuverlässigkeits- und Sicherheitsziele? | NFR-Spezifikation, Performance-Budget, Verfügbarkeitsziel, Risikoregister |
| Daten und Reporting | Welche Daten sind autoritativ? Wie werden Daten abgerufen, aufbewahrt und auditiert? | Datenmodellskizze, Migrationsplan, Reporting-Anforderungen |
| Lieferung und Governance | Wie werden Änderungen ausgeliefert? Wer entscheidet? Wie werden Change Requests gehandhabt? | Liefer-Kadenz, Definition of Done, Change-Control-Prozess |
| Qualität und Testing | Welche Test-Typen sind erforderlich und wo laufen sie? | Test-Strategie, CI-Qualitätsgates, Testberichte, Regressionsplan |
| Betrieb | Wer ist On-Call? Wie funktionieren Vorfälle? Was wird überwacht? | Monitoring-Plan, Alert-Schwellenwerte, Runbooks, Incident-Prozess |
| Eigentümerschaft und Zugang | Wem gehört das geistige Eigentum? Wer hat Repository-Zugang? Was passiert, wenn das Engagement endet? | IP-Klausel, Zugangsliste, Übergabeplan |
Ein praktischer Weg zur Reduktion von Meinungsverschiedenheiten ist die Definition von „fertig" auf mehreren Ebenen (Story, Feature, Release, Produktionsbereitschaft). Wolf-Techs Artikel zu Custom Software Services: What You Should Get by Default ist eine nützliche Baseline dafür, was „professionell by default" oft beinhaltet.
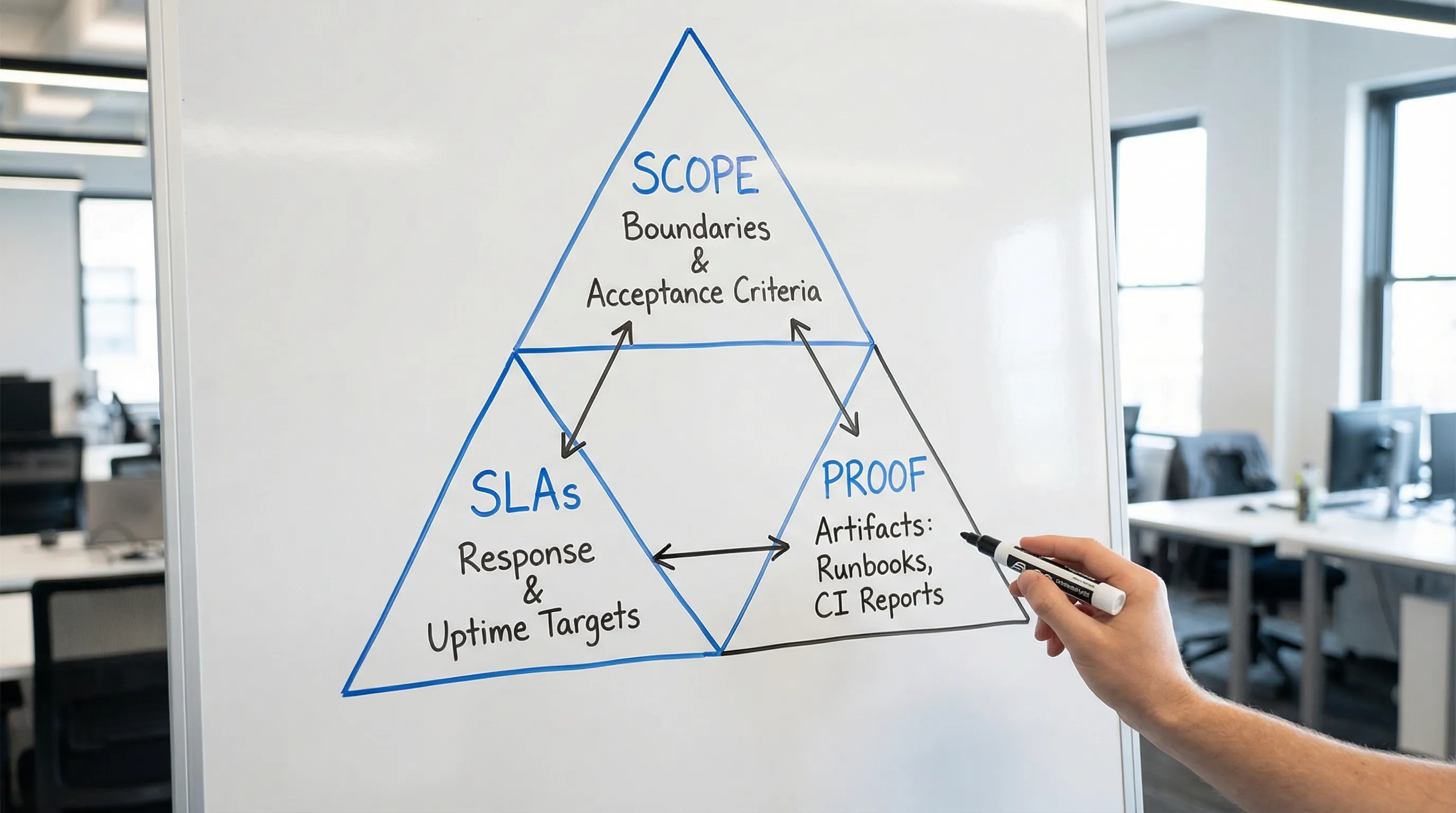
2) SLAs und SLOs: Erwartungen setzen, die der Realität entsprechen
Teams fordern oft einen SLA, weil er sich nach „Sicherheit" anfühlt. Aber es gibt zwei verwandte Konzepte, die häufig vermischt werden:
- SLA (Service Level Agreement): eine vertragliche Verpflichtung (oft an Abhilfemaßnahmen geknüpft) über Support und Service.
- SLO (Service Level Objective): ein internes oder gemeinsames Zuverlässigkeitsziel, das Engineering und Betrieb leitet.
Ein hilfreicher, weit verbreiteter Ansatz kommt aus Googles SRE-Praxis, die erklärt, warum klare Ziele und Fehlerbudgets bessere Zuverlässigkeitsentscheidungen treiben als vage Verfügbarkeitsversprechen. Siehe Googles kostenloses Site Reliability Engineering-Buch als Hintergrundlektüre.
Was sollten SLAs bei individuellen Softwareentwicklungsdienstleistungen abdecken?
SLAs sind am wichtigsten, wenn Ihr Anbieter für Produktionssupport, Betrieb oder einen Managed Service verantwortlich ist, nicht nur für die Feature-Lieferung.
Wenn Ihr Engagement Post-Launch-Support umfasst, definiert ein SLA-Abschnitt typischerweise:
- Support-Zeiten und -Kanäle (Geschäftszeiten vs. 24/7)
- Schweregrade (was als Sev1, Sev2, Sev3 gilt)
- Reaktionszeit- und Wiederherstellungsziele (Bestätigen, Mindern, Lösen)
- Eskalationspfad (wer alarmiert wird)
- Verfügbarkeitsumfang (welche Komponenten eingeschlossen sind, welche Abhängigkeiten ausgeschlossen sind)
- Wartungsfenster (wie geplante Ausfallzeiten behandelt werden)
- Messmethode (wie Verfügbarkeit berechnet wird, welches Monitoring autoritativ ist)
Beispiel-SLA-Struktur (anpassen, nicht blind kopieren)
Die folgenden Zahlen sind kein universeller „Best Practice". Sie sind ein Ausgangspunkt, um Klarheit zu erzwingen. Ihre Ziele sollten Geschäftsauswirkungen, Nutzererwartungen und Architektur-Constraints widerspiegeln.
| Schweregrad | Beispieldefinition | Reaktionsziel | Wiederherstellungs-/Minderungsziel | Kommunikationskadenz |
|---|---|---|---|---|
| Sev1 | Produktionsausfall, kritischer Nutzer-Flow blockiert, größerer Sicherheitsvorfall | 15–30 Minuten | 4–8 Stunden (Minderung) | Alle 30–60 Minuten |
| Sev2 | Degradierter Service, Workaround vorhanden, erhebliche Teilmenge betroffen | 1–2 Stunden | 1–3 Werktage | Täglich bis stabil |
| Sev3 | Geringfügiger Defekt, begrenzte Auswirkung | 1–3 Werktage | Im Backlog geplant | Wöchentlicher Status |
Wichtige Nuance: SLAs sollten definieren, was der Anbieter kontrolliert. Wenn Verfügbarkeit von Drittanbieter-Services abhängt, brauchen Sie explizites Abhängigkeits-Mapping und ein vereinbartes Incident-Protokoll.
Zuverlässigkeitsziele: Einen kleinen Satz messbarer SLOs wählen
Statt einer einzelnen Verfügbarkeitszahl, definieren Sie die Nutzerfahrung, die Sie schützen möchten. Häufige Beispiele:
| SLO-Kategorie | Beispiel-SLI (was gemessen wird) | Beispielziel |
|---|---|---|
| Verfügbarkeit | Erfolgreiche Requests / Gesamt-Requests (pro Endpoint) | 99,9% monatlich für Kern-APIs |
| Latenz | p95-Antwortzeit für Schlüssel-Endpoints | p95 unter 300 ms für Read-APIs |
| Datenfrische | Zeit von Event bis sichtbarer Zustand | Unter 60 Sekunden für kritische Updates |
| Änderungssicherheit | Change-Failure-Rate, Rollback-Rate | Weniger als X% fehlgeschlagene Änderungen |
| Wiederherstellung | Mean Time to Restore (MTTR) | Unter Y Minuten für Sev1 |
Für Liefer-Performance und Änderungssicherheit verfolgen viele Teams DORA-Metriken (Deploy-Frequenz, Lead Time for Changes, Change Failure Rate, Time to Restore). Diese werden am besten als Transparenzmetriken behandelt, nicht als strikte vertragliche SLAs. Als Hintergrund ist die DORA-Forschung eine solide Referenz.
3) Nachweise: Was Sie vor der Unterschrift anfordern sollten
„Vertrauen Sie mir" ist keine Lieferstrategie. Nachweise sind der Weg, wie Sie validieren, dass der Prozess eines Anbieters real, wiederholbar und mit Ihrem Risikoprofil kompatibel ist.
Das Ziel ist nicht Papierkram. Das Ziel ist der Nachweis, dass das Team:
- Änderungen sicher ausliefern kann,
- das in Betrieb nehmen kann, was es ausliefert,
- und Eigentümerschaft sauber übertragen kann.
Eine Nachweismatrix, die Sie bei Anbieterbewertungen wiederverwenden können
| Anbieterbehauptung | Wie „Nachweis" aussieht | Worauf Sie achten sollten |
|---|---|---|
| „Wir liefern zuverlässig." | CI/CD-Pipeline-Walkthrough, Release-Checkliste, Rollback-Strategie, aktuelle Release-Notes | Manuelle Deployments, kein Rollback-Plan, „kommt drauf an"-Antworten |
| „Wir bauen sichere Systeme." | Beispiel-Bedrohungsmodell, Secure-Coding-Baseline, Dependency-Scanning-Ansatz, Incident-Playbook | Sicherheit als letzte Phase, keine Supply-Chain-Geschichte |
| „Wir schreiben wartbaren Code." | Repo-Sample, Architecture Decision Records (ADRs), Code-Review-Standards, modulare Grenzen | „Rockstar"-Abhängigkeit, keine Konventionen, keine Refactoring-Strategie |
| „Wir testen richtig." | Test-Pyramiden-Ansatz, Beispiele für Integration-/Contract-Tests, Flake-Management | Nur Unit-Tests, keine Integrationsvalidierung, fragile E2E-Suite |
| „Wir können Produktion betreiben." | Observability-Ansatz (Logs, Metriken, Traces), On-Call-Policy, Runbooks, Postmortem-Template | Kein Alert-Hygiene, keine Eigentümerschaft, kein Incident-Lernloop |
| „Sie werden das Produkt besitzen." | IP-Bedingungen, Repo-Zugang, Dokumentationsplan, Übergabe-Checkliste | Anbieter-kontrollierte Umgebungen, fehlender Zugang, vage Eigentümerschaft |
Wenn Sie einen käuferorientierten Flow für die Anbieterauswahl benötigen, bietet Wolf-Techs How to Vet Custom Software Development Companies einen strukturierten Rahmen und die Idee eines kurzen bezahlten Piloten.
Der aussagekräftigste „Nachweis" ist ein zeitbegrenzter Pilot
Wenn das Projekt bedeutend ist, beginnen Sie nicht mit einem langen Vertrag und einer vagen Roadmap. Beginnen Sie mit einem kleinen Engagement, das darauf ausgelegt ist, Belege zu produzieren.
Ein guter Pilot dauert typischerweise 2–4 Wochen und endet mit einer Entscheidung basierend auf Outputs wie:
- einem Thin-Vertical-Slice-Plan (oder einem tatsächlichen Thin Slice in einer Sandbox),
- früh aufgedeckten Integrations- und Datenrisiken,
- einer Architektur-Baseline, die Constraints entspricht,
- einem funktionierenden Liefer-Loop (Repo, CI, Umgebungen),
- und einer realistischen Roadmap mit Risiken und Mitigations-Eigentümern.
Wolf-Tech behandelt diesen „Thin Slice First"-Ansatz in mehreren Leitfäden, darunter Custom Web Application Development Services: What to Expect und dem umfassenderen Custom Software Application Development: End-to-End Guide.
4) Häufige Vertragsfallen (und wie man sie vermeidet)
Die meisten gescheiterten Engagements scheitern vorhersehbar. Hier sind wiederkehrende Fallen, die speziell mit Scope, SLAs und Nachweisen zusammenhängen.
Falle 1: „Agile" als Entschuldigung für undefined Abnahme
Agile bedeutet nicht „undefiniert". Es bedeutet, dass Sie entdecken und anpassen, während Qualität und Ergebnisse konstant bleiben.
Lösung: Bestehen Sie auf Abnahmekriterien auf Story-/Feature-Ebene und einer gemeinsamen Definition of Done, die Testing und Produktionsbereitschaft einschließt.
Falle 2: NFRs als optional behandeln
Performance, Sicherheit und Betreibbarkeit sind keine Politur. Sie sind Produktanforderungen.
Lösung: Definieren Sie früh einen kleinen Satz messbarer NFRs. Wolf-Techs fähigkeitsorientierter Ansatz in Web Development Technologies: What Matters in 2026 zeigt, wie man Entscheidungen in messbaren Constraints verankert.
Falle 3: Verfügbarkeitsversprechen ohne Messklarheit
„99,9% Verfügbarkeit" ist bedeutungslos, wenn niemand übereinstimmt über:
- was als Ausfall gilt,
- welche Monitoring-Quelle autoritativ ist,
- welche Komponenten eingeschlossen sind,
- wie Wartungsfenster behandelt werden.
Lösung: Definieren Sie SLIs und Messmethoden. Das ist grundlegendes SRE-Hygiene.
Falle 4: „Support", der nur Best-Effort-E-Mail ist
Lösung: Definieren Sie Schweregrade, Reaktionsziele, Eskalation und Incident-Kommunikation. Machen Sie Eigentümerschaft explizit.
Falle 5: Nachweise, die nicht unabhängig verifiziert werden können
Slide Decks betreiben keine Produktion.
Lösung: Fragen Sie nach Artefakten, die Sie inspizieren können (ggf. anonymisiert), und verlangen Sie operative Bereitschaftslieferergebnisse (Runbooks, Alerts, Dashboards), wenn der Anbieter die Produktion berührt.
5) Ein praktischer Weg, Scope + SLAs + Nachweise in einem SOW zu verpacken
Wenn Sie einen Vertrag wollen, der nach der zweiten Woche noch nützlich ist, strukturieren Sie ihn in Schichten:
Schicht A: Ergebnis und Grenzen (stabil)
Dieser Abschnitt ändert sich selten und verankert alles andere.
- Ergebnisse und Erfolgskennzahlen
- In-Scope- und Out-of-Scope-Grenzen
- Benannte Constraints (Compliance, Deadlines, Legacy-Constraints)
Schicht B: Lieferansatz und Governance (halb-stabil)
- Meilensteine und Phasen-Lieferergebnisse (Discovery, Slice, MVP, Hardening)
- Kadenz und Entscheidungsrechte
- Change-Control-Prozess (wie Backlog-Änderungen Kosten und Zeitplan beeinflussen)
Schicht C: Qualität, Sicherheit und Betrieb (muss explizit sein)
- Testing und Qualitätsgates
- Sicherheits-Baseline und Verantwortlichkeiten
- Observability und Incident-Management
- SLAs für Support (falls eingeschlossen)
Schicht D: Nachweise und Abnahme (wie Sie Streitigkeiten vermeiden)
- Artefaktliste und wo sie liegen (Repo, Docs)
- Abnahmekriterien pro Meilenstein
- Übergabe und Eigentümerschaft (Zugang, Credentials, IP)
Dieses Format hält das „Warum" stabil, während sich das „Was" weiterentwickeln kann, ohne in Mehrdeutigkeit zu kollabieren.

Häufig gestellte Fragen
Sind SLAs bei individuellen Softwareentwicklungsdienstleistungen notwendig? SLAs sind am wichtigsten, wenn der Anbieter Produktionssupport bietet oder das System betreibt. Wenn das Engagement nur Build beinhaltet, konzentrieren Sie sich mehr auf Abnahmekriterien, Qualitätsgates und Übergabenachweise.
Was ist der Unterschied zwischen einem SLA und einem SLO? Ein SLA ist eine vertragliche Verpflichtung über Service-Level (oft an Abhilfemaßnahmen geknüpft). Ein SLO ist ein messbares Zuverlässigkeitsziel, das Engineering- und Betriebs-Trade-offs steuert.
Wie verhindere ich Scope Creep, ohne Iteration zu blockieren? Definieren Sie stabile Grenzen und Ergebnisse, dann behandeln Sie den Backlog als veränderlich innerhalb eines klaren Change-Control-Prozesses. Verlangen Sie Abnahmekriterien und eine Definition of Done, damit Iteration messbar bleibt.
Welche Nachweise sollte ich von einem Software-Anbieter anfordern? Bitten Sie um inspizierbare Artefakte wie CI/CD-Pipeline-Nachweis, Testing-Strategie und -Berichte, Sicherheits-Baseline (und Umgang mit Abhängigkeiten), Observability/Runbooks sowie Beispiele für Entscheidungsunterlagen oder Postmortems.
Sollten DORA-Metriken Teil des Vertrags sein? Normalerweise eignen sie sich besser als Transparenz- und kontinuierliche Verbesserungsmetriken als als vertragliche Strafmaßnahmen. Sie funktionieren am besten, wenn beide Seiten sie nutzen, um Engpässe zu erkennen und Liefer-Sicherheit zu verbessern.
Mit Wolf-Tech über Scope, SLAs oder Anbieternachweise sprechen
Wenn Sie Angebote prüfen oder einen Statement of Work vorbereiten, kann Wolf-Tech Ihnen helfen, Scope-Grenzen zu testen, messbare NFRs und Service-Level zu definieren sowie die Nachweise zu identifizieren, die die Lieferung de-risken.
Entdecken Sie Wolf-Tech auf wolf-tech.io oder beginnen Sie mit diesen verwandten Leitfäden: