
Softwareentwicklung: Warum Prozesse scheitern und wie man sie behebt


Die meisten „Prozessprobleme" in der Software werden nicht durch die Wahl des falschen Agile-Geschmacks verursacht – ob Scrum, Kanban, SAFe oder ein eigens entwickeltes Hybrid. Sie scheitern, weil der Prozess fehlende Grundlagen ausgleichen soll: unklare Ergebnisse, unklare Verantwortlichkeiten, schwache Engineering-Feedback-Schleifen und keine gemeinsame Definition von „fertig".
Wenn Sie diese Seite gefunden haben, während Sie nach Softwareentwicklung suchen, spüren Sie wahrscheinlich eines dieser Symptome:
- Pläne verschieben sich immer weiter, obwohl das Team „beschäftigt" ist.
- Releases sind stressig, manuell und voller Überraschungen.
- QA ist eine Phase am Ende, keine eingebaute Gewohnheit.
- Stakeholder vertrauen den Schätzungen nicht, und Entwickler vertrauen den Anforderungen nicht.
- Die Velocity sieht gut aus, aber die Produktionsergebnisse nicht.
Dieser Artikel erläutert, warum Softwareentwicklungsprozesse in der Praxis scheitern, welche Signale früh auftauchen und welche Korrekturen wirklich etwas verändern.
Die unbequeme Wahrheit: Ein Prozess ist kein Liefersystem
Ein Prozess sagt den Menschen, welche Zeremonien sie besuchen und welche Artefakte sie produzieren sollen. Ein Liefersystem beweist, dass man:
- Absichten in lieferbare Slices umwandeln kann.
- Code sicher ändern kann.
- Vorhersehbar veröffentlichen kann.
- Zuverlässig betreiben kann.
- Aus der Produktion lernen und iterieren kann.
Hochleistungsteams behandeln den Prozess als sichtbare Spitze eines tieferen Systems: Architektur-Leitplanken, CI/CD, automatisierte Quality Gates, Observability und klare Entscheidungsrechte.
Forschungen zeigen konsistent, dass die Lieferperformance stark mit technischen und organisatorischen Fähigkeiten zusammenhängt – nicht damit, „Agile harder zu machen". Das DORA-Forschungsprogramm (bekannt durch das Buch Accelerate) verbindet Ergebnisse wie Lead-Time und Stabilität mit Fähigkeiten wie Continuous Delivery, Trunk-Based Development und schnellen Feedback-Schleifen. Einen Überblick bieten Googles DORA-Ressourcen.
Warum Softwareentwicklungsprozesse scheitern (und wie es aussieht, wenn sie es tun)
Die meisten Misserfolge fallen in eine kleine Anzahl von wiederkehrenden Mustern. Der schnellste Weg zur Diagnose ist, nach beobachtbaren Symptomen zu suchen und sie auf die zugrunde liegende Einschränkung abzubilden.
Fehlermodus 1: Das Team führt Aufgaben aus, keine Ergebnisse
Wie es aussieht
Backlogs sind als Feature-Listen geschrieben. Teams liefern „alles Angeforderte", aber das Unternehmen kann die Auswirkungen immer noch nicht messen. Stakeholder ändern ständig Prioritäten, weil nichts klar funktioniert.
Warum es passiert
Wenn Ergebnisse und Einschränkungen unklar sind, wird der Prozess zu einem Laufband: Tickets produzieren, Sprints abschließen, wiederholen. Die Organisation verwechselt Aktivität mit Fortschritt.
Korrektur, die funktioniert
Beginnen Sie mit einem einseitigen Ergebnis-Briefing, das testbar ist:
- Zielbenutzer und zu erledigende Aufgabe
- Erfolgsmetrik und Baseline
- Nicht-funktionale Anforderungen (Latenz, Verfügbarkeit, Datenhaltung, Sicherheitsanforderungen)
- Umfangsgrenzen (explizit, was ausgeschlossen ist)
Eine leichtgewichtige Kickoff-Disziplin macht einen enormen Unterschied. Wenn Sie einen vorlagenbasierten Ansatz wünschen, ist Wolf-Techs Leitfaden zum Software-Projekt-Kickoff eine solide Grundlage.
Fehlermodus 2: „Fertig" bedeutet zusammengeführt, nicht ausgeliefert
Wie es aussieht
Engineering schließt Arbeit ab, aber sie wartet hinter langlebigen Branches, blockiertem QA oder Release-Zügen. Launch-Tage werden zu Großereignissen. Fehler häufen sich in Umgebungen, die nicht der Produktion entsprechen.
Warum es passiert
Der Prozess definiert den Abschluss an der falschen Grenze. Wenn „fertig" bei der Code-Review aufhört, haben Sie keinen Beweis, dass Sie sicher deployen können.
Korrektur, die funktioniert
Definieren Sie „fertig" auf Ebenen, die das echte Risiko widerspiegeln:
- Automatisch gebaut und getestet
- In einer produktionsähnlichen Umgebung deployed
- Observability vorhanden (Logs, Metriken, Tracing wo nötig)
- Reversibler Rollout-Plan (Feature-Flag, Canary oder sicheres Rollback)
- In Produktion released (auch wenn hinter einem Flag versteckt)
Hier zahlt sich auch die CI/CD-Reife sofort aus. Ein praktischer Einstiegspunkt ist CI/CD-Technologie.
Fehlermodus 3: Große Batches verbergen Unbekanntes bis es zu spät ist
Wie es aussieht
Projekte laufen wochen- oder monatelang ohne einen produktionswürdigen Increment. Die Integration erfolgt spät. Datenmigrationen werden am Ende entdeckt. Performance wird „später getestet".
Warum es passiert
Große Batches verzögern das Feedback. Unbekanntes akkumuliert sich und explodiert dann während „Integration", „Hardening" oder „UAT".
Korrektur, die funktioniert
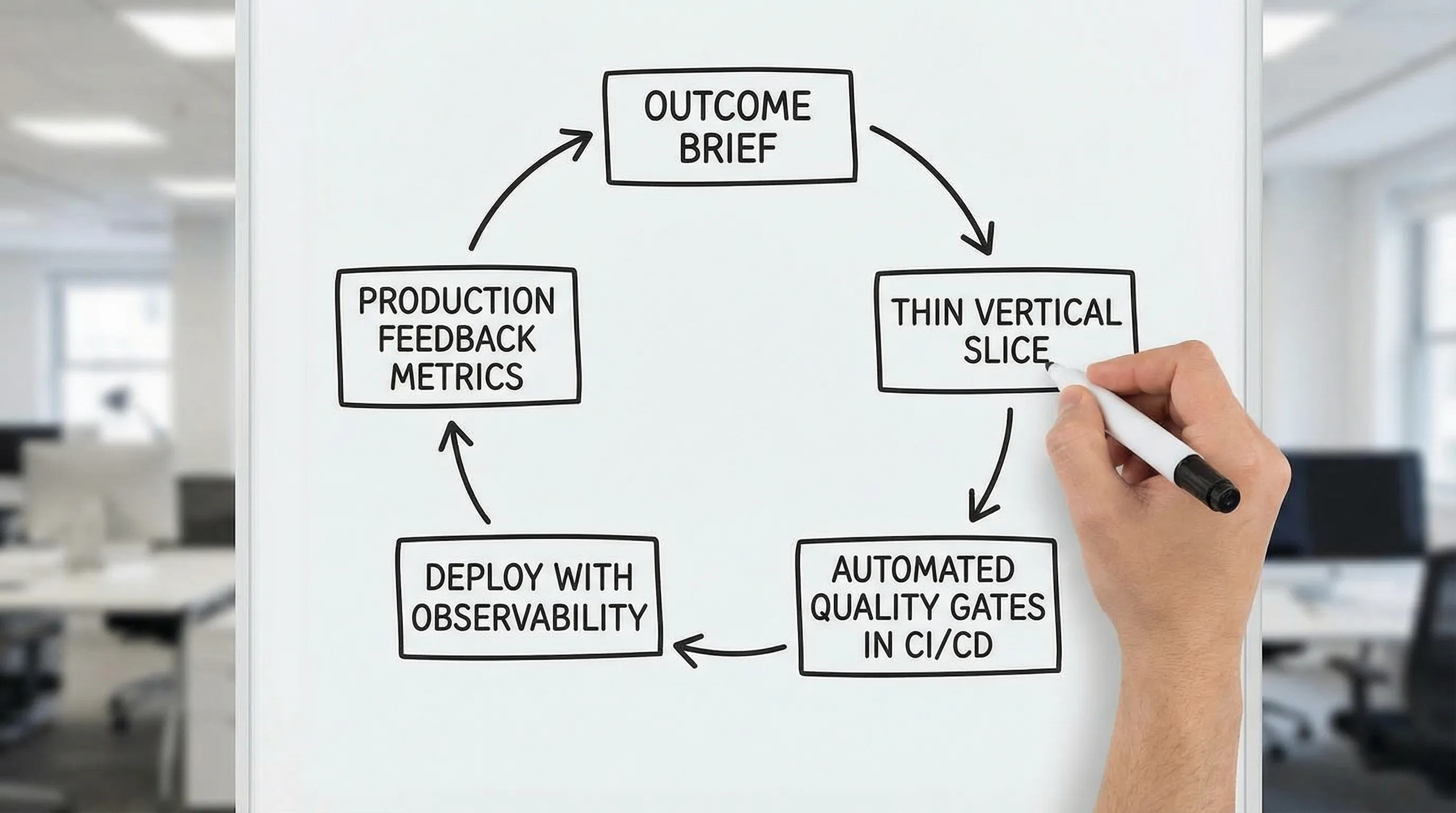
Verwenden Sie einen dünnen vertikalen Slice als Proof-Mechanismus, nicht als Prototyp-Theater.
Ein dünner Slice sollte enthalten: UI, API, Daten, Auth (falls relevant), Deployment und Telemetrie – auch wenn das Feature minimal ist. Der Punkt ist, den End-to-End-Pfad zu beweisen.
Wenn Sie einen schrittweisen Prozess rund um diese Idee wünschen, lesen Sie Wolf-Techs Software-Bauprozess für vielbeschäftigte Teams.
Fehlermodus 4: Übergaben erzeugen Warteschlangen, und Warteschlangen erzeugen Verzögerungen
Wie es aussieht
Arbeit bewegt sich von Produkt zu UX zu Engineering zu QA zu Ops, mit Wartezeiten zwischen jedem Schritt. Alle sind lokal „effizient", aber die End-to-End-Lieferung ist langsam.
Warum es passiert
Übergaben fügen Übersetzungsverluste und Wartezeiten hinzu. Der Prozess optimiert die Rollenauslastung statt den Fluss.
Korrektur, die funktioniert
Reduzieren Sie Übergaben, indem Sie sich um ein gemeinsames „Slice-Team" ausrichten, das End-to-End liefern kann.
Das bedeutet nicht, dass jede Person Full-Stack sein muss. Es bedeutet, dass das Team die Fähigkeiten und Entscheidungsrechte hat, einen Slice zu liefern, ohne bei jedem Schritt auf eine andere Abteilung warten zu müssen.
Für viele Organisationen ist die praktischste Verbesserung die frühzeitige Definition funktionsübergreifender Vereinbarungen und Verträge. Die in UX-zu-Architektur-Abstimmung beschriebene UX-und-Engineering-Ausrichtungsschleife ist einer der wirkungsvollsten Wege, Nacharbeit zu verhindern.
Fehlermodus 5: Qualität ist ein Versprechen, kein System
Wie es aussieht
Qualität hängt von Helden ab. Reviews sind inkonsistent. Testen ist unter Zeitdruck „nice to have". Bugs wiederholen sich. Sicherheitskorrekturen sind reaktiv.
Warum es passiert
Wenn Qualität nicht automatisiert und durchgesetzt wird, verliert sie immer gegen Dringlichkeit. Ein Prozessdokument kann keine Deadline überstimmen.
Korrektur, die funktioniert
Führen Sie automatisierte Quality Gates ein, die schwer zu umgehen sind:
- Linting und Formatierung
- Statische Analyse und Typisierung (wo anwendbar)
- Schnelle Unit- und Komponenten-Tests
- Eine kleine, stabile E2E-Smoke-Suite
- Dependency- und Secret-Scanning
Behandeln Sie diese als Teil des Liefersystems. Wolf-Tech hat sprachspezifische Beispiele (zum Beispiel die JS-Code-Qualitäts-Checkliste) und eine breitere Sicht auf welche Maßnahmen Ergebnisse vorhersagen in Code-Qualitäts-Metriken, die zählen.
Fehlermodus 6: Architektur ist zufällig, also wird Änderung teuer
Wie es aussieht
Jedes Feature berührt zu viele Dateien und Services. Teams fürchten sich vor dem Refactoring. Incidents häufen sich nach Releases. „Wir brauchen einen Rewrite" kommt zur Sprache.
Warum es passiert
Ohne explizite Grenzen und Verträge wächst Kopplung still. Prozess-Rituale können kein System kompensieren, bei dem alles von allem abhängt.
Korrektur, die funktioniert
Etablieren Sie einen kleinen Satz von Architektur-Leitplanken:
- Klare Modulgrenzen (im Code, nicht nur in einem Diagramm)
- Contract-First-APIs wo Integrationsrisiko hoch ist
- Ein Entscheidungsprotokoll (ADRs) für wichtige Trade-offs
- Eine Standard-Architektur-Baseline, die der aktuellen Reife entspricht
Im Jahr 2026 erzielen viele Teams immer noch bessere Ergebnisse, wenn sie mit einem modularen Monolith beginnen, anstatt mit voreiligen Microservices. Wenn dies Ihre Situation ist, erklärt Modularer Monolith zuerst die Trade-offs.
Fehlermodus 7: Entscheidungsrechte sind unklar, also wechseln Prioritäten ständig
Wie es aussieht
Roadmaps ändern sich wöchentlich. Entwickler erhalten widersprüchliche Anweisungen. Stakeholder eskalieren um den Prozess herum. Teams hören auf, der Planung zu vertrauen.
Warum es passiert
Ein Prozess kann Meetings planen, aber keine Governance reparieren. Ohne klare Eigentümerschaft für Umfang, Architektur, Risiko und Release-Entscheidungen entsteht Chaos.
Korrektur, die funktioniert
Definieren Sie Entscheidungsrechte explizit:
- Wer besitzt Ergebnismetriken und Akzeptanz?
- Wer besitzt Architektur-Leitplanken und ADR-Genehmigung?
- Wer kann den Sprint unterbrechen, und unter welchen Bedingungen?
- Wer genehmigt Produktions-Releases?
Selbst eine einfache Entscheidungstabelle, die monatlich schriftlich und überprüft wird, reduziert Chaos.
Eine praktische Diagnosetabelle: Symptome auf Ursachen und Korrekturen abbilden
Nutzen Sie diese Tabelle, um von „wir fühlen uns feststeckend" zu umsetzbaren Einschränkungen zu gelangen.
| Symptom in der Realität | Wahrscheinliche Ursache | Umzusetzende Korrektur (beweisbasiert) |
|---|---|---|
| Sprint-Commitments werden erfüllt, aber Releases verschieben sich | „Fertig" endet beim Merge, nicht beim Deploy | Release als First-Class-Artefakt: CI/CD, Preview-Envs, reversible Release-Muster |
| QA ist immer im Rückstand | Späte Integration, große Batches, schwache Automatisierung | Dünne vertikale Slices + automatisierte Gates + E2E auf stabile Smoke-Schicht reduzieren |
| Häufige Produktions-Regressionen | Schwache Änderungssicherheit und Observability | Tests auf geändertem Code, Release-Tagging, Error-Budgets, Monitoring-Alarme hinzufügen |
| Teams streiten über Anforderungen | Ergebnisse und Einschränkungen sind unklar | Einseitiges Ergebnis-Briefing + explizite NFRs und Umfangsgrenzen |
| Jedes Feature berührt alles | Zufällige Architektur und Kopplung | Grenzen, Verträge, ADRs, Abhängigkeitsregeln, Modularisierung |
| Stakeholder priorisieren ständig um | Keine messbare Lernschleife | Erfolgsmetriken definieren, instrumentieren, Ergebnisse wöchentlich überprüfen, Arbeit beschneiden |
| Entwickler sind ausgebrannt | Heldenkultur, manuelle Releases, ständige Unterbrechungen | Release/Qualität automatisieren, Unterbrechungsrichtlinie definieren, WIP reduzieren, On-Call-Hygiene verbessern |
Die Korrekturen: Ein Minimum Viable Delivery System (MVDS) aufbauen
Wenn Ihr Prozess immer wieder scheitert, beginnen Sie nicht damit, den Prozess neu zu schreiben. Beginnen Sie damit, einen minimalen Satz von Fähigkeiten einzuführen, die das Liefern sicher und wiederholbar machen.
1) Ergebnisse und Einschränkungen explizit machen
Gute Softwareentwicklung beginnt mit Klarheit, gegen die Entwickler bauen können.
Mindestens erfassen:
- Ergebnismetrik (und wie Sie sie messen werden)
- Wichtige Nutzerreisen
- Einschränkungen: Performance, Zuverlässigkeit, Sicherheit, Compliance, Datenhaltung
- Integrationsfläche (welche Systeme Sie berühren müssen)
Hier entdecken viele Teams, dass sie „agile" ohne gemeinsame Akzeptanzkriterien gebaut haben.
2) Arbeit nach End-to-End-Wert schneiden, nicht nach Komponenten
Komponentenbasiertes Schneiden (erst Backend, dann UI) erzeugt oft „fast fertige" Arbeit, die nicht validiert werden kann.
Bevorzugen Sie Slices, die:
- Dünn sind (kleiner Umfang)
- Vertikal sind (UI bis Daten)
- Produktionsförmig sind (deployed, beobachtbar, reversibel)
Dies verlagert den Prozess von spekulativer Planung zu kontinuierlichem Beweis.
3) Die Feedback-Schleife standardisieren (schnell, automatisiert, vertrauenswürdig)
Ein zuverlässiger Prozess hängt von einer zuverlässigen Feedback-Leiter ab:
- Lokales Feedback in Minuten (Lint, Typecheck, Unit-Tests)
- PR-Feedback in unter einer Stunde (schnelles CI)
- Umgebungs-Feedback am selben Tag (Preview-Deployments)
- Produktions-Feedback innerhalb von Tagen (Feature-Flags, gestaffelter Rollout, Telemetrie)
Wenn CI langsam oder flaky ist, hören Entwickler auf, ihm zu vertrauen, und Ihr Prozess wird wieder meinungsgetrieben.
4) Qualität als Code durchsetzen, nicht als Richtlinie
Richtlinien werden umgangen. Automatisierung nicht (oder sie schlägt zumindest laut fehl).
Um das Release-Risiko zu reduzieren, behandeln Sie diese als nicht verhandelbare Standards:
- Formatierungs- und Lint-Regeln
- Dependency-Prüfungen und Vulnerability-Scanning
- Automatisierte Tests, die Change-Hotspots abzielen
- Sicherheitsprüfungen für Datenbankmigrationen (wenn anwendbar)
Wenn Sie in einer regulierten Umgebung arbeiten oder eine ernsthafte Sicherheitslage haben, richten Sie Engineering-Arbeit an etablierten Leitlinien wie dem NIST Secure Software Development Framework aus und bilden Sie es auf Ihre Pipeline-Gates ab.
5) Frühzeitig Betreibbarkeit hinzufügen: Man kann sich nicht aus der Produktion herausentwickeln
Viele Prozessfehler sind eigentlich Betriebsfehler, die spät auftauchen.
Mindest-Betreibbarkeit umfasst:
- Grundlegende Service-Level-Indikatoren (SLIs) für Latenz, Fehler, Auslastung
- Alarme, die an Nutzerauswirkungen gebunden sind
- Runbooks für häufige Fehlermodi
- Ein definierter Rollback- oder Deaktivierungspfad für neue Releases
Wenn Sie eine pragmatische Checkliste für die Backend-Seite davon wünschen, lesen Sie Backend-Entwicklung Best Practices für Zuverlässigkeit.
Was in den nächsten 30 Tagen zu tun ist (ohne das Rad neu zu erfinden)
Eine „Prozesskorrektur", die sechs Monate dauert, ist normalerweise eine Rebranding-Übung. Der wirkungsvollste Ansatz ist, wenige Einschränkungen schnell zu ändern, dann zu iterieren.
Woche 1: Eine Baseline und eine gemeinsame Definition von „fertig" etablieren
Wählen Sie 3 bis 5 Metriken und messen Sie den aktuellen Zustand. Ein einfacher Satz, der über Teams funktioniert:
- Lead-Time bis zur Produktion (PR gemergt bis Prod)
- Deploy-Frequenz
- Change-Failure-Rate
- MTTR
- Defect-Escape-Rate (Bugs nach dem Release gefunden)
Diese stimmen mit der DORA-Performance-Sicht überein und geben Ihnen einen Realitätscheck, ohne zum Metriken-Theater zu werden.
Woche 2: Einen dünnen vertikalen Slice mit echtem Beweis implementieren
Wählen Sie ein kleines Feature und liefern Sie es End-to-End:
- Eine produktionsförmige Route oder Flow
- Ein echtes Deployment durch CI/CD
- Ein kleines Dashboard oder Alert, das Observability beweist
Dies schafft eine Referenzimplementierung dafür, wie das Team liefert.
Woche 3: Quality Gates installieren und sie langweilig machen
Machen Sie die Pipeline zuverlässig:
- Schnelle Prüfungen bei jedem PR
- Ein stabiler E2E-Smoke-Lauf
- Sicherheitsprüfungen integriert in CI
Das Ziel ist nicht Perfektion. Das Ziel ist vorhersehbare Änderungssicherheit.
Woche 4: Den größten wiederkehrenden Queue beheben
Suchen Sie den teuersten Wartepunkt:
- Warten auf QA
- Warten auf Umgebungsbeförderung
- Warten auf Genehmigungen
- Warten auf die API eines anderen Teams
Dann entfernen oder reduzieren Sie ihn mit Verträgen, Automatisierung oder Änderungen der Entscheidungsrechte.
Ein einfacher „Prozessgesundheits"-Scorecard, den Sie in einem Meeting durchführen können
Verwenden Sie dies als strukturiertes Gespräch mit Engineering- und Produktführung. Bewerten Sie jeden Punkt von 0 bis 2:
| Fähigkeit | 0 Punkte | 1 Punkt | 2 Punkte |
|---|---|---|---|
| Ergebnisklarheit | Nur Feature-Liste | Ergebnismetrik vorhanden, schwache Akzeptanz | Ergebnis + NFRs + messbare Akzeptanz |
| Dünnes Slicing | Arbeit ist komponentenbasiert | Einige vertikale Slices | Standard sind dünne vertikale Slices |
| CI-Zuverlässigkeit | Langsam/flaky, umgangen | Funktioniert aber inkonsistent | Schnell, vertrauenswürdig, durchgesetzt |
| Release-Sicherheit | Manuell, sehr stressig | Etwas Automatisierung | Reversible Releases + Staging + Telemetrie |
| Quality Gates | Meist manuelles QA | Einige Prüfungen | Automatisierte Gates + stabile Test-Strategie |
| Betreibbarkeit | „Monitoring fügen wir später hinzu" | Grundlegende Logs/Alarme | SLIs/SLOs, Dashboards, Runbooks |
| Eigentümerschaft & Entscheidungen | Unklar, politisch | Teilweise Klarheit | Explizite Entscheidungsrechte + ADRs |
Eine niedrige Punktzahl bedeutet nicht, dass das Team schlecht ist. Es bedeutet, dass dem System Beweis-Mechanismen fehlen.
Wo Wolf-Tech helfen kann (ohne einen Rewrite zu erzwingen)
Wolf-Tech arbeitet mit Teams zusammen, die Software-Lieferung aufbauen, optimieren oder skalieren müssen – besonders wenn Prozessänderungen allein gescheitert sind. Typische Engagements umfassen Architektur- und Code-Qualitäts-Reviews, Legacy-Code-Optimierung, Liefersystem-Upgrades (CI/CD, Quality Gates, Betreibbarkeit) und Full-Stack-Implementierungsunterstützung.
Wenn Sie einen schnellen, evidenzbasierten Weg suchen, um wieder voranzukommen, ist ein guter Ausgangspunkt eine Architektur- und Lieferbewertung ähnlich wie in Was ein Tech-Experte in Ihrer Architektur prüft beschrieben. Von dort aus können Sie einen gezielten 30-Tage-Verbesserungsplan definieren, der sich auf messbare Lieferung und Produktionsergebnisse konzentriert.