
Web Application Framework Comparison: Beyond the Hype


Framework debates are usually loud for a reason: a web application framework shapes how fast you ship, how safely you change code, how you scale teams, and how painful operations become after the first 6 to 18 months.
But most “framework comparisons” stop at popularity charts and hello-world ergonomics. That’s not where projects fail.
This guide compares web application frameworks beyond the hype by using a capability-first lens: performance, security boundaries, delivery safety, operability, data fit, and long-term change cost. You will leave with a practical scorecard, scenario-based defaults, and an evaluation plan you can run in two weeks.
What counts as a web application framework in 2026?
A “web application framework” can refer to multiple layers of your stack. Confusion here creates bad comparisons.
- Frontend UI frameworks and meta-frameworks: React-based frameworks (Next.js, Remix) or content-first frameworks (Astro) that handle routing, rendering, bundling, and increasingly data-fetching conventions.
- Backend frameworks: Opinionated foundations for HTTP, auth, data access, background jobs, and architecture patterns (Django, Rails, Spring Boot, ASP.NET Core, NestJS).
- Full-stack frameworks: Frameworks that intentionally span UI, server, data access, and conventions (Ruby on Rails, Django, Laravel, sometimes Next.js when used as “the app”).
The right comparison depends on what you are actually choosing:
- A rendering and routing model (SPA vs SSR vs hybrid)
- A runtime and hosting model (Node, JVM, .NET, serverless, edge)
- A way of structuring code (modular boundaries, dependency injection, conventions)
- An operating model (how you deploy, observe, secure, and upgrade)
If you want a refresher on how web apps work end-to-end (CDN, TLS, server-side logic, data layer, browser rendering), see Wolf‑Tech’s overview: Web Application: What Is It and How Does It Work?
Why hype-driven framework picks backfire
Framework hype tends to optimize for the first 4 weeks (developer experience, quick demos) instead of the next 18 months (reliability, change safety, onboarding, cost).
Common failure modes we see in real teams:
- Choosing a framework that fights your rendering needs (for example, SEO and caching requirements bolted onto a client-only SPA late in the game).
- Underestimating security and compliance work and assuming the framework “handles it.” Security is a system property, not a library feature.
- Picking “micro” primitives too early and rebuilding a platform (auth, jobs, observability, queues) ad hoc.
- Ignoring upgrade cadence until you are stuck on old versions (and old dependencies).
- Optimizing for personal preference over team reality, including hiring market and existing skills.
A more durable approach is to treat framework selection as an engineering decision that must be justified against outcomes and constraints. Wolf‑Tech’s broader, capability-first approach is summarized here: Web Development Technologies: What Matters in 2026
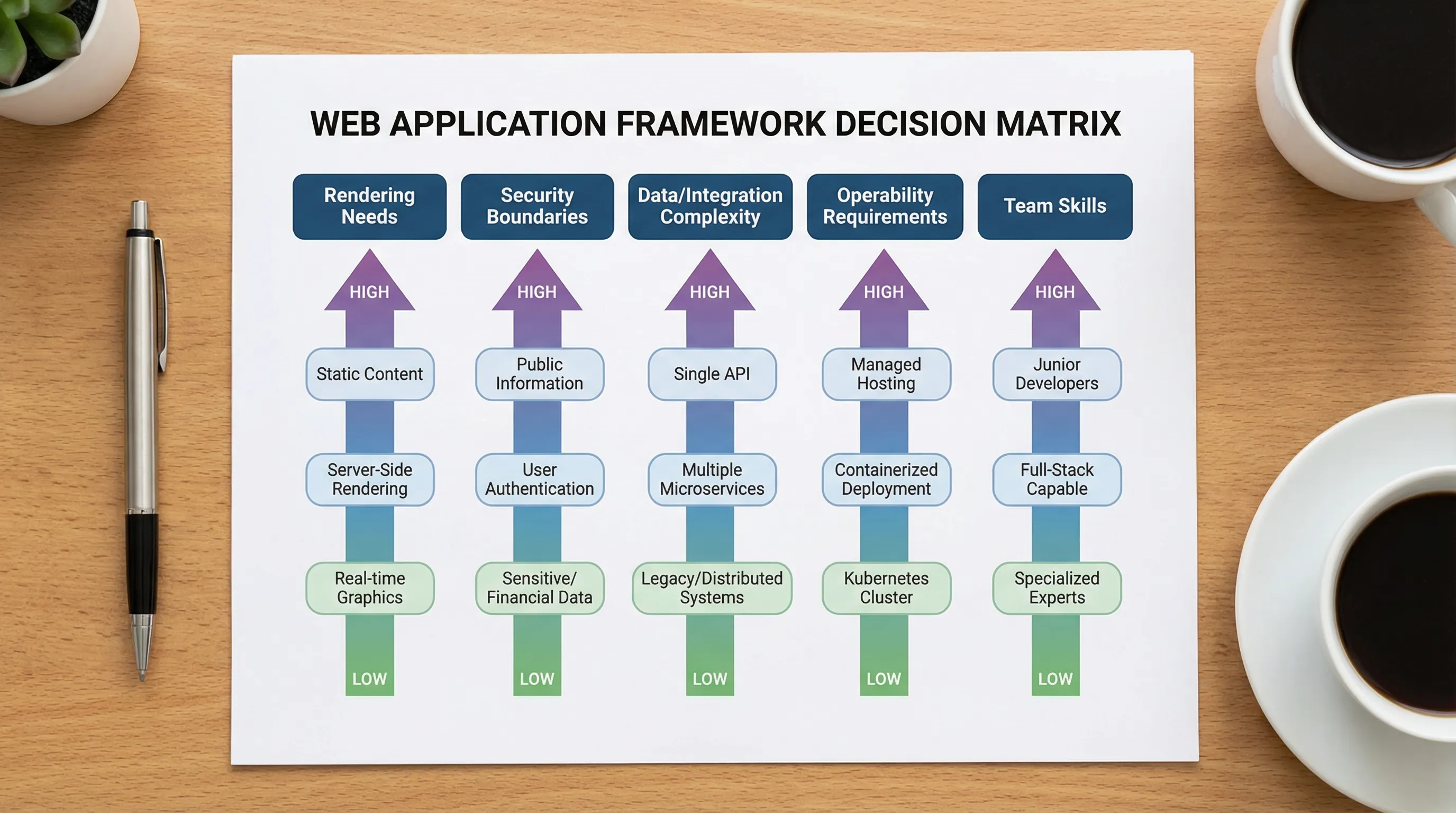
A practical framework comparison scorecard (what to evaluate)
Instead of trying to “rank” frameworks, evaluate them against the constraints that actually drive cost, risk, and speed.
Here is a scorecard you can use in architecture reviews and vendor evaluations.
| Dimension | What to ask | Evidence to collect (not opinions) |
|---|---|---|
| Rendering and performance | Do you need SSR/SSG/streaming? What are your Core Web Vitals goals? | A thin vertical slice with measured LCP/INP/CLS and server TTFB trends |
| Security boundaries | Where do secrets live? How do you enforce authz close to data? | Threat model notes, OWASP Top 10 mapping, authz tests, dependency scanning |
| Data and integration fit | Is your data access simple CRUD, complex reporting, real-time, multi-tenant? | Schema sketch, representative query plans, integration spike with 1-2 real systems |
| Change safety | How do you prevent regressions while shipping weekly? | Testing strategy, CI quality gates, rollback plan, feature flags |
| Operability | Can you debug production issues fast? | Logs, metrics, traces, error reporting, runbooks, on-call readiness |
| Team and hiring | What skills do you already have? What will be hard to hire for? | Skills matrix, onboarding time, codebase conventions, availability of senior talent |
| Longevity and upgrade path | How often do breaking changes land? How painful are upgrades? | Upgrade history, LTS policy where relevant, dependency health |
| Cost model | Where does cost show up (compute, bandwidth, DB, third parties)? | Load test + hosting estimate, caching strategy, background job plan |
Security note: OWASP’s Top 10 is still a good sanity checklist, but you should map threats to your system’s actual data and trust boundaries.
Comparison, by category (and what usually matters)
1) Frontend meta-frameworks: Next.js, Remix, Astro, and “React SPA + Vite”
Most teams are not choosing “React vs Next.js.” They are choosing a delivery model for UX, data fetching, caching, and security.
Next.js
Next.js has become a default for many teams because it supports multiple rendering strategies (SSR, SSG/ISR-style patterns, streaming) and can be used as a full-stack layer.
Where Next.js tends to win:
- Hybrid rendering (public + authenticated areas)
- Performance work that benefits from server-first composition
- Teams that want conventions for routing, bundling, and deployment
The real question is whether you can operate it well (caching, runtime choice, observability, safe migrations). If you are already on Next.js, Wolf‑Tech’s production guide is here: Next.js Best Practices for Scalable Apps
Remix
Remix emphasizes web fundamentals (nested routes, progressive enhancement, form actions) and often shines when you want a server-centric app with predictable data flows.
Where Remix tends to win:
- Apps that benefit from simple server rendering and strong HTML-first behavior
- Teams that want a smaller “magic surface area” than some meta-framework patterns
The trade-off is usually ecosystem gravity: hiring and third-party examples may skew more toward Next.js.
Astro
Astro is content-first and “islands”-oriented. It can be an excellent fit for marketing, docs, and content-heavy properties where shipping minimal client JavaScript matters.
Where Astro tends to win:
- Content and documentation sites
- Performance-sensitive public pages that should stay mostly static
But Astro is not always the best choice for complex, authenticated product surfaces, unless you treat it as the public edge and keep the application elsewhere.
React SPA with Vite
A client-rendered SPA is still a strong option, especially for internal tools and authenticated dashboards where SEO is irrelevant and latency comes mostly from APIs.
Where SPA + Vite tends to win:
- Internal B2B tools behind login
- Highly interactive UIs where SSR adds complexity without business value
The key is to be honest about what you are giving up: you are buying simpler hosting, but you may pay later if you need SEO, shareable previews, or fast first loads on weak devices.
If you want a deeper React-framework-specific comparison, see: React Frameworks Explained: Picking the Right Fit in 2026
2) Backend frameworks: what “enterprise-ready” really means
Backend framework comparison is less about syntax and more about how you handle:
- Authn/authz and tenancy boundaries
- Background work (queues, schedulers, async)
- Data migrations and long-lived schemas
- Observability and incident response
- Integration patterns (webhooks, ETL, events)
Below is a pragmatic comparison of common backend choices.
| Backend framework family | Typical strengths | Watch-outs (real-world) | Great fits |
|---|---|---|---|
| ASP.NET Core (.NET) | Performance, strong tooling, mature ecosystem, enterprise integrations | Can be overkill for very small teams if conventions are not agreed | B2B SaaS, internal platforms, regulated orgs, Microsoft-heavy environments |
| Spring Boot (Java/JVM) | Huge ecosystem, strong patterns, mature ops, long-lived systems | Complexity creep without architectural guardrails | Complex domains, multi-team systems, regulated industries, integration-heavy backends |
| Django (Python) | Productive, batteries included (admin, auth), fast CRUD and workflows | Async and high concurrency patterns require deliberate design | Data-driven apps, internal tooling, marketplaces, teams that value rapid iteration |
| FastAPI (Python) | Great for typed APIs, modern ergonomics, strong for service layers | You assemble more pieces yourself than Django | API-first systems, ML/AI-adjacent services, teams that want lightweight primitives |
| Ruby on Rails | Very fast product iteration, strong conventions, mature ecosystem | Scaling patterns require discipline (background jobs, caching, boundaries) | Startups, SaaS, products that iterate weekly with a strong test culture |
| NestJS (Node.js/TypeScript) | Opinionated structure for Node, good for teams that want DI and modules | Node ops and performance are fine, but you must design I/O and data access carefully | TypeScript shops, BFF layers, API gateways, multi-team Node backends |
The best backend choice is often the one that lets your team enforce consistency (architecture, testing, security, delivery) without heroics. For reliability fundamentals that apply regardless of framework, see: Backend Development Best Practices for Reliability
3) “Full-stack” doesn’t mean “one repo solves everything”
Full-stack frameworks are attractive because they reduce integration overhead early. But “full-stack” can also hide coupling.
A useful mental model is to separate:
- The product surface (routes, pages, UI composition)
- The application boundary (auth, authorization, orchestration)
- Domain logic and data (transactions, invariants, data lifecycle)
- Integrations (events, third parties, reporting, webhooks)
Some teams use Next.js as the surface and application boundary, then push domain logic into services or a modular backend. Others keep a monolith (Rails, Django, Symfony, Laravel) and scale via modularity.
If your organization expects a long-lived PHP codebase, Wolf‑Tech has a dedicated decision article: Symfony PHP: When It Beats Laravel
The “framework choice” that matters most: rendering + data boundaries
Most modern web applications fail at the seams:
- UI that calls too many endpoints
- APIs that leak internal data models
- Authz checks implemented inconsistently
- Caching that breaks correctness
Two boundary patterns reduce these risks across many stacks:
- BFF (Backend for Frontend): a dedicated API layer tailored to UI needs, which can be implemented in the same meta-framework (for example Next.js route handlers) or as a separate service.
- Contract-first APIs: explicit schemas and versioning rules so that UI and backend can evolve safely.
If you are considering GraphQL as the seam, make sure you understand the operational and authorization pitfalls, not just the query flexibility. Wolf‑Tech’s guide: GraphQL APIs: Benefits, Pitfalls, and Use Cases
Scenario-based defaults (not universal rules)
Framework comparisons become actionable when you map them to real scenarios. These are sensible starting points that you should still validate with a thin slice.
| Scenario | Frontend default | Backend default | Why this often works |
|---|---|---|---|
| Content-heavy public site (SEO matters) | Next.js or Astro | Simple backend or headless CMS + API | Strong control over rendering, caching, and performance |
| B2B SaaS dashboard (auth-first) | React SPA (Vite) or Next.js (hybrid) | ASP.NET Core, Spring Boot, Django, NestJS | Most complexity lives in domain logic and data permissions |
| E-commerce or transactional flows | Next.js (careful caching) | Backend with strong domain + reliability patterns | Correctness, latency, and payment/integration safety dominate |
| Regulated product (audit, compliance, high assurance) | Next.js (server-first) or conservative SPA | Spring Boot or ASP.NET Core (often) | Governance, long-term maintainability, and mature ops matter |
| Real-time collaboration | Hybrid, keep UI responsive | Backend with WebSocket/event support + durable messaging | The hard part is consistency, backpressure, and failure handling |
| Legacy modernization | Keep surface changes incremental | Strangler patterns, modular monolith defaults | Lowest risk comes from seams, tests, and reversible releases |
If you are actively modernizing, prioritize safety mechanisms (tests, flags, observability, reversible deploys) over framework novelty. A practical modernization playbook is here: Modernizing Legacy Systems Without Disrupting Business
A two-week evaluation plan that produces real answers
If a framework decision is meaningful, it is worth a timeboxed experiment that generates evidence.
Pick two candidates and build a thin vertical slice that includes at least:
- One core user journey end-to-end (UI to DB)
- Authentication and one authorization rule
- One integration (even a stubbed third party)
- One background job or async process if your product needs it
- Basic observability (structured logs, metrics, tracing where possible)
Measure:
- Performance: Core Web Vitals for the UI and p95 latency for APIs
- Change safety: time to add a feature with tests, PR size, CI duration
- Operability: time to debug an injected failure (timeout, bad input, partial outage)
- Upgrade friction: dependency hygiene, build reproducibility, environment parity
This aligns well with delivery metrics used in modern engineering orgs. If you want to operationalize this beyond a one-off evaluation, Wolf‑Tech’s delivery guidance is captured in multiple playbooks, including: CI/CD Technology: Build, Test, Deploy Faster
Red flags in framework comparisons (what to ignore)
Be skeptical when a comparison is based on:
- Benchmarks without your workload (database shape and network I/O usually dominate)
- “It scales to X users” claims without details (caching strategy, data model, concurrency)
- A single developer’s preference rather than team constraints
- Ignoring security and supply chain (dependency risk, patch cadence, deployment controls)
If you need a more complete selection method that ties framework choice into the broader stack (client, API, data, platform), this Wolf‑Tech guide provides a structured approach: Apps Technologies: Choosing the Right Stack for Your Use Case
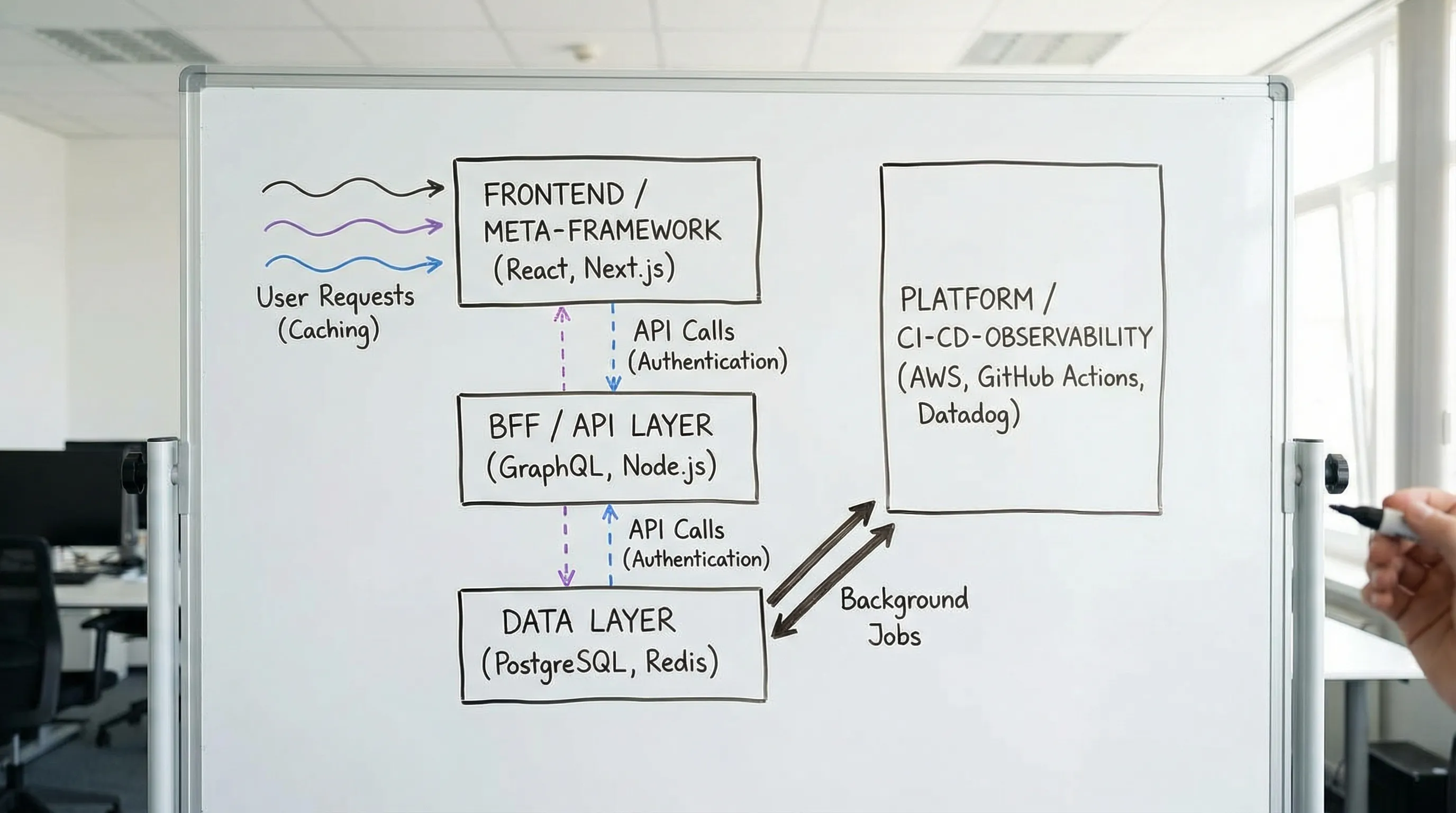
Bringing it together: “best framework” is the one you can operate
A web application framework is not just developer ergonomics. It is a set of defaults that shapes:
- How you meet performance targets
- How you enforce security boundaries
- How quickly you can change code without breaking production
- How easy it is to observe and recover from failure
- How expensive it is to upgrade over years
If you compare frameworks using those dimensions, hype becomes background noise.
Frequently Asked Questions
What is the best web application framework in 2026? There is no single best framework. The best choice depends on your rendering needs, security boundaries, data complexity, operability requirements, and the skills you can sustain for 18 to 36 months.
Is Next.js always better than a React SPA? No. A React SPA can be a great fit for authenticated dashboards and internal tools. Next.js usually wins when you need SEO, fast first loads, or hybrid rendering, but it adds server and caching complexity that you must operate well.
Should I pick a backend framework that matches my frontend language (TypeScript everywhere)? Sometimes, but “same language” is not automatically lower risk. The bigger question is whether you can enforce consistent architecture, testing, security, and operability in production.
How do I compare frameworks without building a full MVP twice? Build a thin vertical slice in two weeks. Include auth, one core journey, representative data access, a background task if needed, and baseline observability. Measure performance, change safety, and operability.
Do frameworks handle security for me? Frameworks help, but they do not “solve security.” You still need threat modeling, secure defaults, dependency management, authz design, and operational controls (monitoring, incident response, patching). Using OWASP Top 10 as a baseline checklist is a good start.
Want a framework decision you can defend (and operate)?
If you are choosing a web application framework for a new product, re-platforming a legacy system, or trying to standardize across teams, Wolf‑Tech can help you turn preferences into evidence.
Wolf‑Tech specializes in full‑stack development, code quality consulting, legacy optimization, and tech stack strategy. If you want a practical scorecard, a two-week thin-slice evaluation plan, or an architecture review focused on performance, security, and maintainability, start here: Wolf‑Tech | Technology, Development and Growth.