
Programing Development: A Practical Roadmap for 2026


In 2026, “programing development” is not just writing code. It is the ability to repeatedly ship changes that are correct, secure, observable in production, and affordable to operate. Teams that treat development as a delivery system (not a series of features) move faster and break less.
This roadmap is designed for founders, product leaders, engineering managers, and developers who want a practical path from “we should build this” to “we can run this reliably and evolve it safely.” It focuses on the fundamentals that compound: scope discipline, fast feedback, contracts, quality gates, and production readiness.
What “programing development” should mean in 2026
A modern definition is outcome-first and production-aware:
- Outcome-first: you can explain what the software changes in the business and how you will measure it.
- Change-safe: you can ship frequently without increasing incident rate.
- Operable: you can answer “is it working?” and “what changed?” without guessing.
- Secure-by-default: you reduce the likelihood and blast radius of security failures.
- Maintainable: future changes get cheaper, not more expensive.
This aligns with what high-performing delivery organizations measure and improve. If you want a baseline reference for delivery metrics, start with the DORA research (now published via Google Cloud) on throughput and stability metrics like deploy frequency, lead time, change failure rate, and MTTR in the DORA reports.
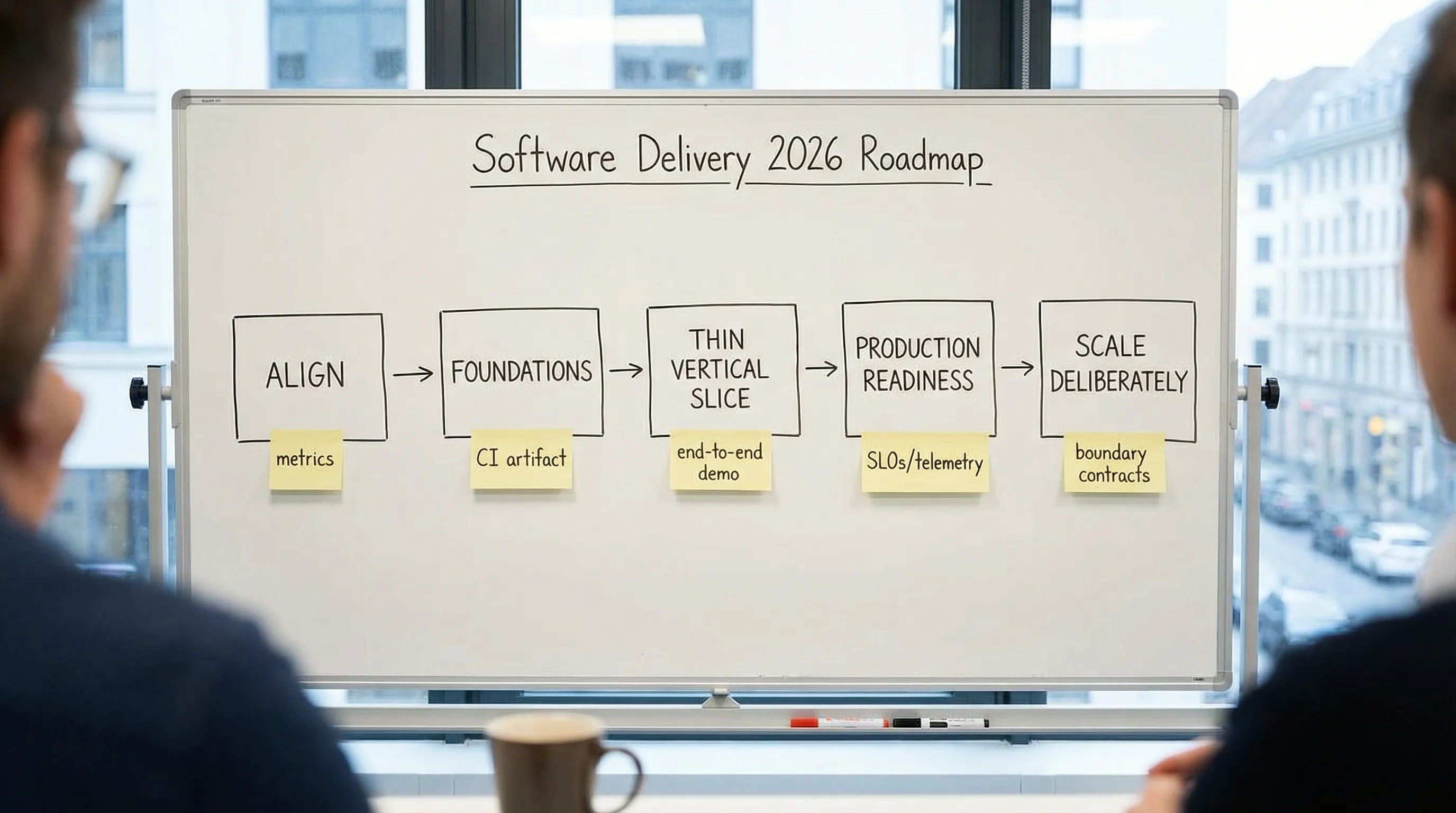
The practical roadmap for 2026 (at a glance)
Use this as a sequence, not a menu. Each phase has “proof” that prevents expensive surprises later.
| Phase | Goal | Key outputs (hard to fake) | Proof you can move on |
|---|---|---|---|
| 0. Align | Build the right thing | One-page brief: outcomes, users, constraints, risks | Team agrees on success metrics and non-functional requirements (NFRs) |
| 1. Foundations | Make shipping safe | Repo standards, CI, quality gates, preview env | Every PR produces a tested artifact you can deploy |
| 2. Thin vertical slice | De-risk end-to-end | A small user journey in prod-like conditions | You can demonstrate the full path: UI, API, data, auth, logs |
| 3. Production readiness | Prevent outages and incidents | SLOs, observability, rollback plan, security baseline | You can detect failures quickly and recover predictably |
| 4. Scale deliberately | Grow without rewriting | Clear boundaries, contracts, performance/cost budgets | Change remains predictable as features and team size increase |
Phase 0: Align on outcomes and constraints (before you “start coding”)
Many projects slip because they start with a feature list and end with an untestable definition of success. In 2026, alignment means explicitly defining both functional scope and operational reality.
Minimum alignment package
Keep it lightweight, but complete:
- Outcome and metric: revenue lift, time saved, conversion rate, reduced error rate, lower support volume.
- Primary users and journeys: who does what, in what order, and what “done” means.
- Non-functional requirements: latency targets, availability expectations, data retention, privacy/compliance constraints.
- Risk register: top 5 risks (integration, data migration, security, performance, adoption) and how you will prove or reduce them.
If you want a practical structure for kickoff and measurable success, Wolf-Tech’s guide on software project kickoff is a solid template.
Practical rule for NFRs
If you cannot say it in numbers, you cannot test it.
Examples:
- “Search should feel fast” becomes “p95 search response time under 300 ms for 10k listings.”
- “Reliable” becomes “99.9% availability for the core workflow, with an error budget policy.”
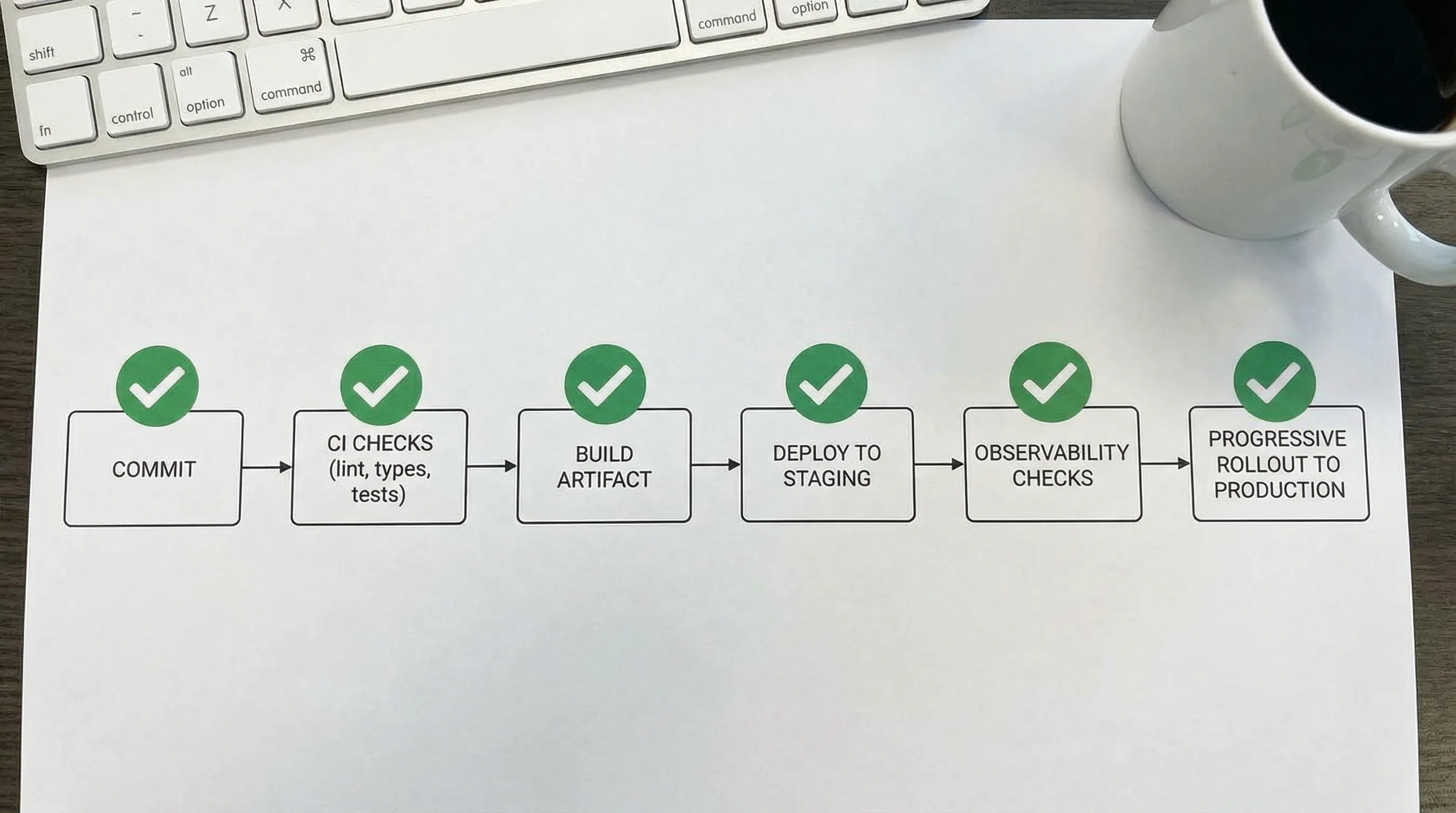
Phase 1: Build the delivery foundation (fast feedback beats heroic debugging)
A delivery foundation is what allows a team to ship small changes safely. The mistake is to over-engineer it. The correct move is to implement a few high-leverage defaults and automate them.
Foundation checklist (keep it boring and enforceable)
Focus on things that reduce uncertainty per change:
- Version control discipline: trunk-based or short-lived branches, clear review rules.
- CI quality gates: lint, type-check, tests, security checks.
- Build artifact: the same artifact promoted across environments.
- Preview environments: optional, but extremely valuable for product feedback.
- Dependency and secret hygiene: basic scanning and prevention.
For a deeper look at what to standardize first across teams, see software development technology: what to standardize first.
Gates vs signals (a simple way to keep CI trusted)
Not everything should block a merge. Teams burn out when CI is noisy.
| Category | Make it a gate when… | Keep it a signal when… |
|---|---|---|
| Formatting/lint | It is fast and stable | It produces frequent false positives |
| Type checks | Your codebase is typed enough to trust it | You are early in incremental adoption |
| Unit/component tests | They run quickly and fail deterministically | They are flaky or too slow |
| Security checks | They catch real issues (secrets, vulnerable deps) | They need tuning to reduce noise |
Wolf-Tech’s JS code quality checklist is a practical baseline for modern web teams.
Phase 2: Ship a thin vertical slice (the fastest way to expose hidden work)
A thin vertical slice is a minimal, end-to-end user journey that touches every major layer: UI, backend/API, database, authentication/authorization, logging, and deployment.
It is not a prototype. It is a small production-quality slice that proves feasibility.
What to include in a thin slice (so it actually de-risks)
Aim for one workflow that is representative of the real system:
- A real user identity path (even if simplified)
- A real data write (not just read-only)
- One integration seam (even if mocked behind a contract)
- One operational story: errors are visible, and rollback is possible
This approach is used across many Wolf-Tech playbooks because it forces realism early. If you want a complete version of this thinking, see the concept of a delivery “build stack” in Build Stack: a simple blueprint for modern product teams.
The slice acceptance criteria (copyable)
Your slice is “real” when you can answer these questions with evidence:
- Can we deploy it repeatedly without manual steps?
- Do we know how long it takes for a change to reach production?
- If it fails, do we see it quickly (logs/metrics/traces) and recover safely?
- Do we have at least one automated test per critical rule?
If you are building a web app, Wolf-Tech’s build a web application checklist can help ensure your slice covers the important edges.
Phase 3: Production readiness (security, reliability, and observability are features)
A system that “works on staging” is not a system. Production readiness is what protects customer trust and your team’s time.
Security baseline: start with known standards
In 2026, supply chain and application security are table stakes, even for MVPs.
Practical baselines worth aligning with:
- The OWASP Top 10 for common web risks and prevention priorities
- The NIST Secure Software Development Framework (SSDF), SP 800-218 for process expectations many regulated industries now reference
Keep it pragmatic: secrets handling, dependency scanning, basic threat modeling for critical flows, and secure defaults for auth and data access.
Reliability baseline: design for failure, not for hope
Most outages are not exotic. They are timeouts, retries amplifying load, missing idempotency, DB hotspots, and poor observability.
Adopt reliability basics early:
- Timeouts, retries with jitter, and circuit breakers where appropriate
- Idempotent writes for operations that might be retried
- Back-pressure and rate limiting on expensive endpoints
- A clear incident path: on-call expectations, runbooks, and ownership
Wolf-Tech’s backend development best practices for reliability is a strong practical reference.
Observability: you want answers, not dashboards
Treat observability as a question-answering system:
- “Is the core journey succeeding?” (success rate)
- “How slow is it for real users?” (p95 latency)
- “What changed?” (release tags, versioned deployments)
- “Where is the time going?” (tracing)
If you are performance-sensitive on the web, align to measurable user metrics like the Core Web Vitals. Google’s documentation is the canonical reference: Web Vitals.
Phase 4: Scale deliberately (avoid premature complexity, but don’t ignore growth)
Scaling is not only traffic. It is also:
- More features
- More integrations
- More developers
- More data
- More compliance requirements
Architecture that scales for most teams: clear boundaries and contracts
In practice, the biggest predictor of maintainability is not whether you chose microservices. It is whether boundaries and contracts are explicit and enforced.
Build around:
- Domain boundaries: modules or services mapped to business capabilities
- Contract-first APIs/events: schemas and compatibility rules
- Ownership: someone is accountable for uptime and change safety
Wolf-Tech’s Software Systems 101: boundaries, contracts, and ownership is a practical way to make this real.
Performance and cost: use budgets, not wishful thinking
In 2026, performance work should be measurement-first. Avoid “optimizing” without evidence.
- Establish baselines (field and lab)
- Fix the biggest bottleneck with the smallest change
- Add guardrails to prevent regression
See performance software tuning: a measurement-first workflow for a concrete approach.
A simple 30-60-90 day plan you can actually execute
This is a pragmatic starting point for programing development in a real organization.
Days 1-30: Make feedback fast and reliable
Deliverables you should be able to point to:
- One-page scope + NFRs + success metrics
- Repo conventions and CI gates
- A build artifact and repeatable deployments
- The first thin slice in a prod-like environment
Days 31-60: Make production predictable
Focus on:
- SLOs for core journeys and basic alerting
- Logging, metrics, tracing usable during an incident
- Secure defaults (secrets, dependency scanning, auth boundaries)
- A rollback strategy tested at least once
Days 61-90: Make change cheaper
By now, your priorities shift to maintainability:
- Boundaries and contracts (module rules, API schemas)
- Quality improvements in hotspots (tests where change happens)
- Performance and cost baselines with budgets
- Documentation that supports onboarding (runbooks, ADRs)
For teams that want a broader operating model (not only code), Wolf-Tech’s software development strategy for diverse teams provides a useful structure.
Common traps in 2026 (and better defaults)
Trap: Picking a “modern stack” before you know your constraints
Better default: use a capability-first selection approach and validate with a thin slice. Wolf-Tech’s software technology stack scorecard lays out a measurable way to choose.
Trap: Treating AI coding tools as a shortcut around engineering
Better default: use AI to accelerate execution, but keep human-owned standards:
- code review discipline
- tests for business rules
- security checks for dependencies and secrets
- documented decisions (ADRs)
Trap: “We’ll add observability later”
Better default: add minimal telemetry on day one. Without it, every incident becomes a debate.
Trap: Big-bang rewrites to “fix the architecture”
Better default: incremental modernization with measured outcomes. If you are dealing with legacy constraints, start with taming legacy code: strategies that actually work.
When to bring in expert help (and what to ask for)
Outside support is most valuable when it reduces risk quickly, especially around architecture, delivery safety, and legacy modernization.
High-signal engagements typically look like:
- Architecture review with evidence: focused on outcomes, NFRs, boundaries, and operability (not taste)
- Thin-slice validation sprint: proving feasibility and delivery mechanics in 2 to 4 weeks
- Legacy optimization plan: prioritizing hotspots and introducing safety mechanisms without stopping feature work
If you want a clear view of what a serious review should cover, see what a tech expert reviews in your architecture.
How Wolf-Tech supports programing development in practice
Wolf-Tech works with teams to build, optimize, and scale production software across modern stacks, with a strong emphasis on code quality, delivery systems, and pragmatic architecture.
If you are planning a 2026 build or modernization and want a second set of senior eyes, start with a focused review or a thin-slice plan. You can explore Wolf-Tech’s approach at wolf-tech.io and use the blog resources above to align internally before you engage.