
Individuelle Anwendungsentwicklung: Von der Discovery bis zum Launch


Individuelle Anwendungsentwicklung war nie „nur Features bauen". Im Jahr 2026 liefern die meisten Teams in eine komplexe Realität: Identität und Berechtigungen, Datenmigration, Drittanbieter-Integrationen, Sicherheitsanforderungen, Performance-Erwartungen und laufender Betrieb.
Der Unterschied zwischen einer App, die still und leise zur zentralen Geschäftsinfrastruktur wird, und einer, die zu einem teuren Rewrite wird, liegt meist nicht an einer einzelnen Technologieentscheidung. Es ist der End-to-End-Prozess von der Discovery bis zum Launch – einschließlich dessen, was man (mit Belegen) nachweist, bevor man skaliert.
Dieser Leitfaden unterteilt diesen Lebenszyklus in praktische Phasen mit klaren Lieferergebnissen und Exit-Kriterien, die man nutzen kann – egal ob man intern baut, outsourct oder ein hybrides Team führt.
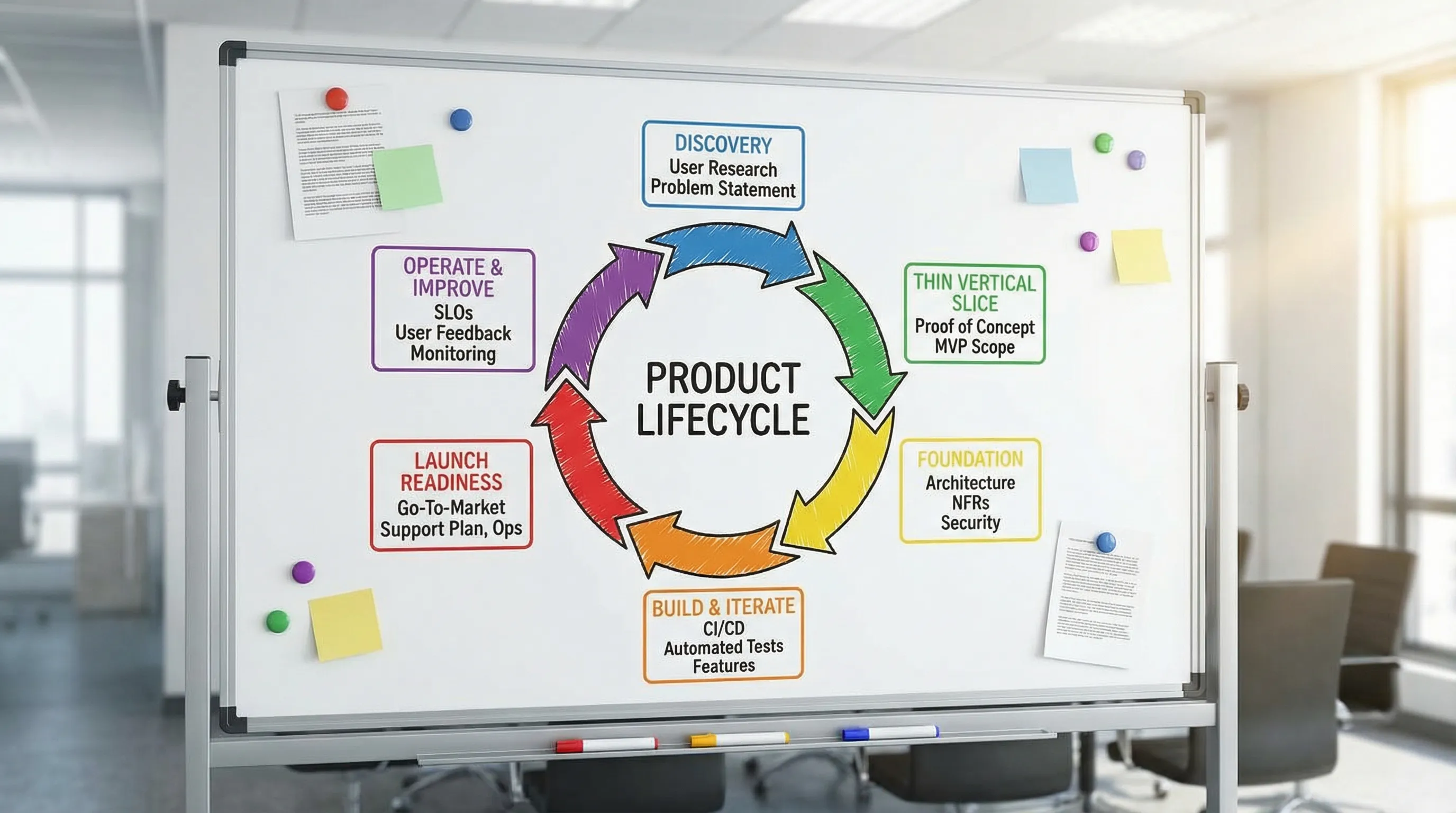
Was individuelle Anwendungsentwicklung liefern sollte (jenseits von Code)
Eine individuelle Anwendung ist eine Investition in eine Fähigkeit, die das Unternehmen entweder nicht kaufen kann oder nicht sicher als Standardlösung übernehmen kann.
Das eigentliche Lieferergebnis ist also kein Repository, sondern:
- Ein messbares Ergebnis (Umsatz, Kostensenkung, Zykluszeit-Reduktion, Risikoreduktion, Kundenbindung)
- Ein produktionsreifes System (sicher, beobachtbar, betreibbar, wartbar)
- Ein Änderungssystem (CI/CD, Qualitätsgates und ein Lieferrhythmus, der das Produkt nach dem Launch kontinuierlich verbessert)
Wer nur auf das Ausliefern eines „MVP" optimiert, erhält oft eine Demo, die nicht sicher betrieben werden kann. Wer nur auf „Enterprise-Qualität" optimiert, landet oft in Analyse-Lähmung. Das Ziel ist es, Nachweise in der richtigen Reihenfolge zu erbringen.
Phase 1: Discovery, die Nacharbeit verhindert
Discovery ist der Punkt, an dem Teams entweder Geschwindigkeit kaufen oder Nacharbeit kaufen.
Eine Discovery mit hohem Erkenntnisgewinn fokussiert auf Workflows, Einschränkungen und entscheidungsreife Klarheit – nicht auf Feature-Listen.
Was in der Discovery abzustimmen ist
Ergebnisse und Entscheidungsregeln
Definieren, wie Erfolg aussieht und wie entschieden wird, ob man weitermacht, pivotiert oder stoppt.
Nutzer, Workflows und Datenrealität
Den realen Workflow von Ende zu Ende kartieren – einschließlich Sonderfälle (Genehmigungen, Ausnahmen, fehlende Daten, veraltete Daten, Berechtigungen).
Nicht-funktionale Anforderungen (NFRs)
Messbare Zielwerte schreiben für:
- Performance (Latenz, Durchsatz, Batch-Fenster)
- Zuverlässigkeit (Verfügbarkeitsziel, Error Budget, Recovery-Erwartungen)
- Sicherheit und Compliance (Datenklassifizierung, Audit-Bedarf, Aufbewahrung)
- Betreibbarkeit (On-Call-Bedarf, Alerting, Support-Modell)
Integrationen und Verträge
Alle vor- und nachgelagerten Abhängigkeiten auflisten und identifizieren, welche riskant sind (Rate Limits, inkonsistente Daten, fragile APIs).
Ein praktisches Muster ist es, den „UX-zur-Architektur-Handshake" frühzeitig explizit durchzuführen, damit die gewünschte User Experience und die Systemeinschränkungen vor dem Build abgestimmt werden. Wolf-Tech hat dazu einen ausführlicheren Leitfaden: UX zur Architektur-Abstimmung.
Discovery-Lieferergebnisse, an denen man ein Team messen kann
| Discovery-Artefakt | Wofür es ist | Was „gut" bedeutet |
|---|---|---|
| Ergebnis-Briefing | Stakeholder auf den Baugrund abstimmen | 1 Seite mit messbaren KPIs und Trade-offs |
| Workflow-Karte | Fehlende Anforderungen verhindern | Happy Path plus wichtigste Sonderfälle |
| NFR-Liste (messbar) | Späte Überraschungen vermeiden | Zielwerte mit Einheiten (ms, %, RTO/RPO usw.) |
| Integrations-Inventar | Abhängigkeiten de-risken | Verantwortliche, Einschränkungen, Vertragsansatz |
| Risikoregister | Risiken handlungsrelevant machen | Risiko, Wahrscheinlichkeit, Auswirkung, Eigentümer |
| Initialer Scope-Slice | „Den Ozean kochen" verhindern | Vorschlag für einen dünnen End-to-End-Slice |
Wer einen konkreten, validierungsorientierten Ansatz vor dem Baucommitment sucht, findet hier einen passenden Wolf-Tech-Artikel: Wert vor dem Coding validieren.
Phase 2: Einen dünnen vertikalen Slice definieren (der schnellste Weg, sicher zu lernen)
Ein dünner vertikaler Slice ist ein funktionierender End-to-End-Pfad durch das System, in eine reale Umgebung geliefert, mit realen Einschränkungen.
Er ist der zuverlässigste Weg, Machbarkeit und Liefereife frühzeitig zu validieren.
Was ein dünner Slice beinhalten sollte
Ein Slice ist nicht „ein Screen" oder „eine API". Er sollte enthalten:
- Einen User-Einstiegspunkt (UI oder Client)
- Identität und Autorisierung zumindest in minimaler Form
- Einen zentralen Workflow
- Einen echten Datenpfad (Datenbank plus Migrationen)
- Eine Integration oder einen realistischen Stub mit einem Vertrag
- Logging/Metriken/Tracing ausreichend, um den Workflow zu debuggen
- Eine deploybare Pipeline in eine Non-Prod-Umgebung
Hier sollten Stack-Entscheidungen mit Belegen validiert werden, nicht mit Meinungen. Wer eine strukturierte Methode zur Stack-Wahl und -Validierung sucht, findet sie hier: Den richtigen Stack für den Anwendungsfall wählen.
Exit-Kriterien für Phase 2
Man ist bereit weiterzumachen, wenn man nachweisen kann:
- Der Slice funktioniert in einer vom Team kontrollierten Umgebung End-to-End
- Er kann wiederholt deployed werden
- Man hat zumindest grundlegende Beobachtbarkeit (und kann Fehler debuggen)
- Die größten Unbekannten (Datenform, Integration, Performance-Einschränkung) sind reduziert
Phase 3: Foundation, die wiederholbares Liefern ermöglicht
Teams versuchen oft, „Features zu bauen", bevor sie sicher liefern können. Das Ergebnis ist ein Backlog unsichtbarer Arbeit, der später als Verzögerungen auftaucht.
Foundation ist der Punkt, an dem zukünftige Lieferung kostengünstig gemacht wird.
Foundation-Grundlagen (Minimum Viable Professional)
Liefersystem
Eine funktionierende CI/CD-Pipeline ist kein Nice-to-have. Sie ist der Mechanismus, der kleine, sichere Änderungen möglich macht. Einen praktischen Überblick bietet: CI/CD-Technologie-Leitfaden.
Qualitätsgates
Mindeststandards frühzeitig setzen (Formatierung, Linting, statische Analyse, Tests, Build-Reproduzierbarkeit). Das Ziel ist nicht Perfektion, sondern die Verhinderung offensichtlicher Regressionen.
Sicherheits-Baseline
Definieren, wie man umgeht mit:
- Secrets-Management
- Dependency-Scanning und Patching
- Authentifizierungs- und Autorisierungsgrenzen
- Sicheren Defaults in Umgebungen
Zwei glaubwürdige Ausgangspunkte, die viele Teams für Baselines nutzen, sind das NIST Secure Software Development Framework (SSDF) und OWASP ASVS. Man muss nicht alles implementieren, aber man sollte bewusst auswählen, was zutrifft.
Beobachtbarkeits-Baseline
Mindestens benötigt man:
- Strukturierte Logs mit Korrelations-IDs
- Grundlegende Service-Metriken (Fehlerrate, Latenz, Auslastung)
- Tracing über den Haupt-Workflow
Arbeitsvereinbarungen
Entscheidungsrechte und die „Definition of Done" explizit machen. Ein Kickoff-Template hilft, Drift zu verhindern. Wolf-Tech hat dazu einen praktischen Leitfaden: Software-Projekt-Kickoff: Scope, Risiken und Erfolgskennzahlen.
Eine pragmatische Foundation-Checkliste (als Tabelle)
| Bereich | Baseline-Frage | Nachweis, den man zeigen können sollte |
|---|---|---|
| CI/CD | Können wir auf Abruf deployen? | Pipeline-Verlauf, Deployment-Logs |
| Qualität | Werden schlechte Änderungen frühzeitig erkannt? | Tests, statische Prüfungen, PR-Regeln |
| Sicherheit | Verhindern wir offensichtliche Fallen? | Secret-Scanning, Dependency-Checks |
| Umgebungen | Können wir reproduzieren und debuggen? | IaC oder geskriptetes Setup, Runbooks |
| Beobachtbarkeit | Können wir Probleme schnell diagnostizieren? | Dashboards, Traces, Log-Suche |
Phase 4: Bauen und iterieren mit Änderungssicherheit
Diese Phase beansprucht den größten Teil der Kalenderzeit, sollte aber keine „Big-Bang-Implementierung" sein. Das Ziel sind kleine Inkremente, die auslieferbar bleiben.
Wie man verhindert, dass Iteration zu Chaos wird
Backlog nach Ergebnissen aufteilen, nicht nach Komponenten
Inkremente liefern, die einen Workflow voranbringen (auch wenn minimal), statt isolierte Schichten zu bauen, die sich erst spät integrieren.
Verträge zur Kontrolle von Integrationsrisiken nutzen
Contract-First-APIs und Contract-Tests reduzieren die „Läuft auf meiner Maschine"-Integrationspirale.
Datenmigration als Produktarbeit behandeln
Änderungen an der Datenform sind oft der verborgene Schedule-Killer. Migrationschritte, Rollback-Strategien und Backfills explizit planen.
Zuverlässigkeitsmuster in den Workflow einbauen
Timeouts, Retries, Idempotenz und Backpressure sind keine „spätere Härtung". Sie sind Teil eines Workflows, der auch unter Fehlern funktionieren muss.
Wenn Zuverlässigkeit ein zentraler Treiber für die App ist, deckt dieser Wolf-Tech-Leitfaden konkrete Muster ab: Backend-Entwicklung Best Practices für Zuverlässigkeit.
Performance messbar halten
Performance-„Debatten" vermeiden. Baseline messen, Änderung vornehmen, neu messen. Wer einen praktischen Workflow für wirkungsvolle Optimierungen sucht: Code optimieren: Wirkungsvolle Fixes.
Phase 5: Launch Readiness (Launch umkehrbar machen)
Ein Launch ist kein Datum. Es ist ein Risikoereignis.
Ein guter Launch-Plan geht davon aus, dass etwas schiefgeht, und macht diesen Fehler behebbar.
Launch-Readiness-Gate: Was nachzuweisen ist
| Launch-Readiness-Bereich | Was zu entscheiden ist | Mindestnachweis |
|---|---|---|
| SLOs und Alerts | Was ist in der Produktion „schlecht"? | SLO-Ziele, Alert-Schwellenwerte, On-Call-Pfad |
| Rollback-Strategie | Wie machen wir Änderungen schnell rückgängig? | Automatisierter Rollback oder getesteter Revert-Plan |
| Deployment-Sicherheit | Wie reduzieren wir den Blast Radius? | Canary- oder phasenweiser Rollout-Ansatz |
| Datensicherheit | Was, wenn eine Migration fehlschlägt? | Backup/Restore-Plan, Migrations-Probe |
| Sicherheitsreview | Liefern wir bekannte Risiken aus? | Threat-Model-Notizen, Top-Risiken mitigiert |
| Betriebsdokumentation | Wer macht was, wenn es bricht? | Runbook für Top-Workflows und Incidents |
Für regulierte Umgebungen oder hohe Verfügbarkeitsanforderungen sollte die Launch Readiness auch Audit-Logging-Strategie, Aufbewahrung und Incident-Meldepflichten umfassen.

Phase 6: Nach dem Launch betreiben, messen und verbessern
Nach dem Launch entscheidet sich, ob individuelle Apps kumulativen Wert schaffen oder stille Kosten anhäufen.
Was direkt nach dem Launch zu messen ist
Business-Metriken
Nutzung und Workflow-Abschluss mit den ursprünglichen Ergebnissen verknüpfen. Wenn man keine Ergebnisbewegung messen kann, kann man seine Roadmap nicht verteidigen.
Liefer- und Zuverlässigkeitsmetriken
Eine kleine Menge an Signalen tracken, die mit nachhaltigem Liefern korrelieren. Viele Teams nutzen DORA-artige Metriken (Deployment-Häufigkeit, Lead Time, Change Failure Rate, MTTR). Die kanonische Community-Ressource ist DORA.
Kosten und Performance
Die Kostentreiber kennen (Compute, Daten, Drittanbieter-APIs) und entscheiden, wer Optimierungsentscheidungen trifft.
Technische Schulden als expliziter Trade-off
Schulden sind nicht „schlecht", aber verborgene Schulden sind es. Eine kurze Liste der Top-Schuldenposten führen, die aktiv Risiken erhöhen oder die Lieferung verlangsamen.
Häufige Fehlermuster (und das Präventionsmuster)
Diese Probleme tauchen immer wieder in der individuellen Anwendungsentwicklung auf, unabhängig vom Stack:
Discovery produziert eine Feature-Liste, keine Einschränkungen
Prävention: messbare NFRs, ein Integrations-Inventar und ein Risikoregister als Discovery-Outputs verlangen.
Das erste Produktions-Deployment passiert zu spät
Prävention: Früh einen dünnen vertikalen Slice mit echtem CI/CD, Beobachtbarkeit und mindestens einem echten Datenpfad liefern.
Architektur wird durch Präferenz entschieden
Prävention: Architekturentscheidungen mit einem dünnen Slice und expliziten Akzeptanzkriterien validieren, nicht mit Slide-Decks.
„Härtung" ist eine Phase, die nie endet
Prävention: Launch-Gates vorab definieren und Sicherheit, Zuverlässigkeit und Betreibbarkeit inkrementell einbauen.
Integrationen sprengen den Zeitplan
Prävention: Contract-First-Ansatz, frühe Integrationstests, realistische Stubs und explizite Verantwortung für Integrations-Readiness.
Verantwortlichkeit nach dem Launch ist unklar
Prävention: On-Call, SLAs/SLOs und Übergabe-Artefakte vor dem Launch definieren, nicht danach.
Wo Wolf-Tech passt
Wolf-Tech unterstützt Teams über den gesamten Lebenszyklus der individuellen Anwendungsentwicklung – von Discovery und Tech-Stack-Strategie bis zu Full-Stack-Delivery, Code-Qualitäts-Consulting, Legacy-Optimierung und Produktionshärtung.
Wer seinen Plan unter Druck setzen möchte, bevor er Monate Bauzeit committet, beginnt am besten mit einer kurzen Discovery plus einem Thin-Slice-Validierungsplan. Man kann auch Wolf-Techs Perspektive darauf erkunden, was „gute" Delivery beinhalten sollte, in diesen verwandten Leitfäden:
- Individuelle Webanwendungsentwicklung: Was zu erwarten ist
- Individuelle Softwareentwicklungsleistungen: Scope, SLAs und Nachweis
- Was ein Tech-Experte in Ihrer Architektur prüft
Um einen Build, eine Modernisierung oder ein Launch-Readiness-Assessment zu besprechen, besuchen Sie Wolf-Tech und teilen Sie mit, was ausgeliefert werden soll, welchen Einschränkungen man unterliegt und was „fertig" für das Unternehmen bedeuten muss.