
Programmierende Entwicklung: Eine praktische Roadmap für 2026


Im Jahr 2026 bedeutet „programmierende Entwicklung" nicht nur Code schreiben. Es ist die Fähigkeit, wiederholt Änderungen auszuliefern, die korrekt, sicher, in der Produktion beobachtbar und wirtschaftlich zu betreiben sind. Teams, die Entwicklung als Liefersystem behandeln – nicht als Reihe von Features – bewegen sich schneller und brechen weniger.
Diese Roadmap richtet sich an Gründer, Produktleiter, Engineering-Manager und Entwickler, die einen praktischen Weg von „wir sollten das bauen" zu „wir können das zuverlässig betreiben und sicher weiterentwickeln" suchen. Sie konzentriert sich auf die Grundlagen, die sich anreichern: Umfangsdisziplin, schnelles Feedback, Verträge, Quality Gates und Produktionsbereitschaft.
Was „programmierende Entwicklung" im Jahr 2026 bedeuten sollte
Eine moderne Definition ist ergebnisorientiert und produktionsbewusst:
- Ergebnisorientiert: Sie können erklären, was die Software im Unternehmen ändert und wie Sie es messen werden.
- Änderungssicher: Sie können häufig liefern, ohne die Incident-Rate zu erhöhen.
- Betreibbar: Sie können „Funktioniert es?" und „Was hat sich geändert?" beantworten, ohne zu raten.
- Security-by-Default: Sie reduzieren Wahrscheinlichkeit und Auswirkungsradius von Sicherheitsfehlern.
- Wartbar: Zukünftige Änderungen werden günstiger, nicht teurer.
Dies stimmt überein mit dem, was hochleistungsfähige Lieferorganisationen messen und verbessern. Wenn Sie eine Baseline-Referenz für Liefermetriken wünschen, beginnen Sie mit der DORA-Forschung (jetzt über Google Cloud veröffentlicht) zu Durchsatz- und Stabilitätsmetriken wie Deploy-Frequenz, Lead-Time, Change-Failure-Rate und MTTR in den DORA-Berichten.
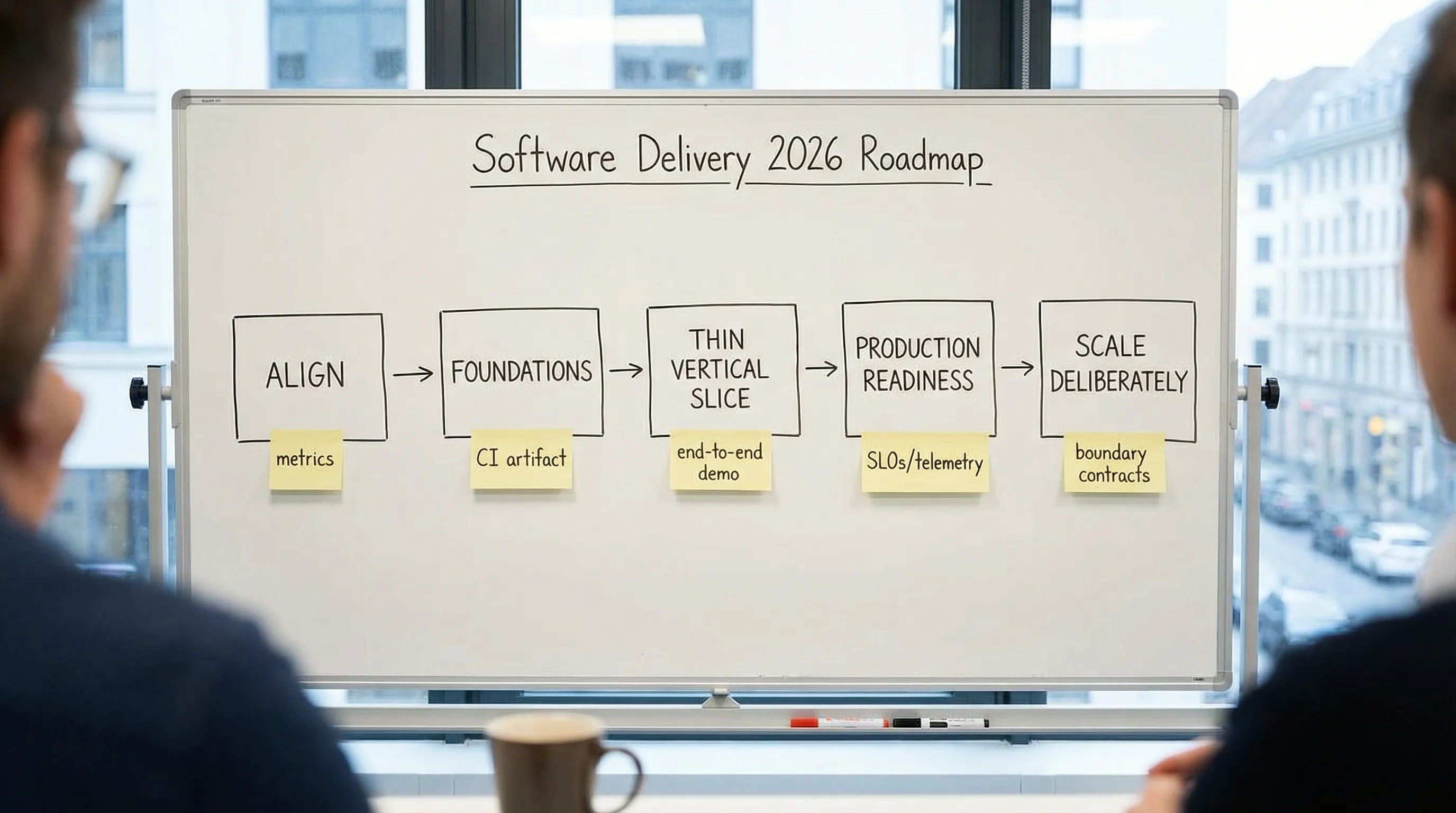
Die praktische Roadmap für 2026 (im Überblick)
Verwenden Sie dies als Sequenz, nicht als Menü. Jede Phase hat „Beweis", der teure Überraschungen später verhindert.
| Phase | Ziel | Wichtige Ausgaben (schwer zu fälschen) | Beweis, dass Sie weitergehen können |
|---|---|---|---|
| 0. Ausrichten | Das Richtige bauen | Einseitiges Briefing: Ergebnisse, Nutzer, Einschränkungen, Risiken | Team ist sich über Erfolgsmetriken und NFRs einig |
| 1. Fundamente | Liefern sicher machen | Repo-Standards, CI, Quality Gates, Preview-Env | Jeder PR erzeugt ein getestetes Artefakt, das Sie deployen können |
| 2. Dünner vertikaler Slice | End-to-End entrisiken | Eine kleine Nutzerreise in produktionsähnlichen Bedingungen | Sie können den vollständigen Pfad demonstrieren: UI, API, Daten, Auth, Logs |
| 3. Produktionsbereitschaft | Ausfälle und Incidents verhindern | SLOs, Observability, Rollback-Plan, Sicherheits-Baseline | Sie können Fehler schnell erkennen und vorhersehbar beheben |
| 4. Gezielt skalieren | Ohne Rewriting wachsen | Klare Grenzen, Verträge, Performance-/Kostenbudgets | Änderungen bleiben vorhersehbar, wenn Features und Teamgröße wachsen |
Phase 0: Ergebnisse und Einschränkungen ausrichten (bevor Sie „mit dem Coding beginnen")
Viele Projekte verschieben sich, weil sie mit einer Feature-Liste beginnen und mit einer nicht testbaren Erfolgsdefinition enden. Im Jahr 2026 bedeutet Ausrichten, sowohl den funktionalen Umfang als auch die operative Realität explizit zu definieren.
Minimales Ausrichtungspaket
Halten Sie es leichtgewichtig, aber vollständig:
- Ergebnis und Metrik: Umsatzsteigerung, Zeitersparnis, Konversionsrate, reduzierte Fehlerrate, geringeres Support-Volumen.
- Primäre Nutzer und Reisen: Wer macht was, in welcher Reihenfolge, und was „fertig" bedeutet.
- Nicht-funktionale Anforderungen: Latenz-Ziele, Verfügbarkeitserwartungen, Datenhaltung, Datenschutz-/Compliance-Einschränkungen.
- Risikoregister: Top-5-Risiken (Integration, Datenmigration, Sicherheit, Performance, Akzeptanz) und wie Sie sie beweisen oder reduzieren werden.
Wenn Sie eine praktische Struktur für Kickoff und messbare Erfolge wünschen, ist Wolf-Techs Leitfaden zum Software-Projekt-Kickoff eine solide Vorlage.
Praktische Regel für NFRs
Wenn Sie es nicht in Zahlen ausdrücken können, können Sie es nicht testen.
Beispiele:
- „Suche sollte sich schnell anfühlen" wird zu „p95-Suchantwortzeit unter 300 ms für 10.000 Einträge".
- „Zuverlässig" wird zu „99,9% Verfügbarkeit für den Kernworkflow mit einer Error-Budget-Policy".
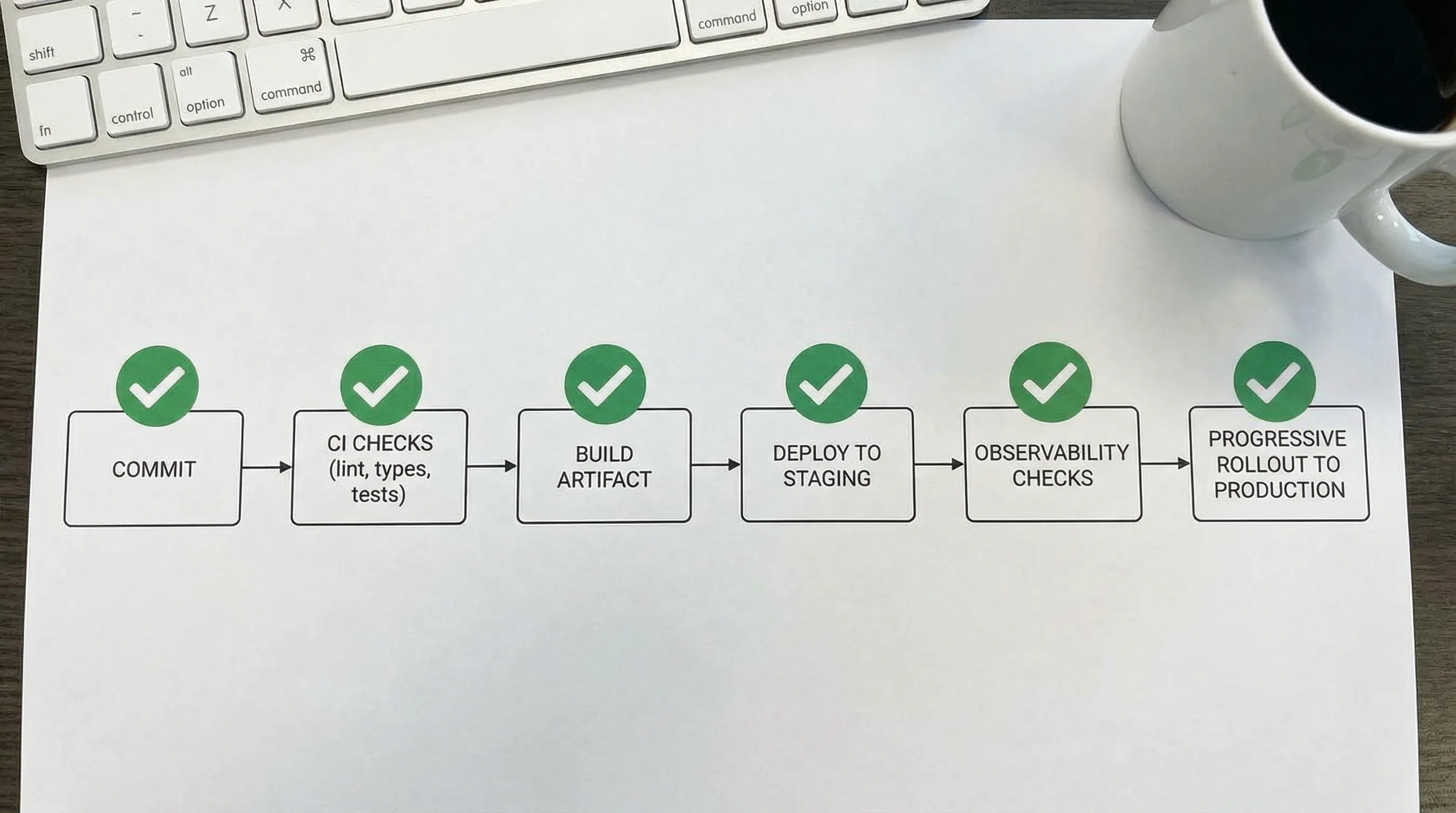
Phase 1: Das Lieferfundament aufbauen (schnelles Feedback schlägt heldenhaftes Debugging)
Ein Lieferfundament ermöglicht es einem Team, kleine Änderungen sicher auszuliefern. Der Fehler ist es, es zu überengineer. Der richtige Schritt ist, wenige wirkungsstarke Standards zu implementieren und sie zu automatisieren.
Fundament-Checkliste (langweilig und durchsetzbar halten)
Fokus auf Dinge, die die Unsicherheit pro Änderung reduzieren:
- Versionskontroll-Disziplin: Trunk-based oder kurzlebige Branches, klare Review-Regeln.
- CI Quality Gates: Lint, Typecheck, Tests, Sicherheitsprüfungen.
- Build-Artefakt: Dasselbe Artefakt wird über Umgebungen hinweg befördert.
- Preview-Umgebungen: Optional, aber extrem wertvoll für Produkt-Feedback.
- Dependency- und Secret-Hygiene: Grundlegendes Scanning und Prävention.
Für einen tieferen Einblick in das, was zuerst über Teams hinweg standardisiert werden sollte, lesen Sie Software-Entwicklungstechnologie: Was zuerst standardisieren.
Gates vs. Signale (ein einfacher Weg, CI vertrauenswürdig zu halten)
Nicht alles sollte einen Merge blockieren. Teams brennen aus, wenn CI laut ist.
| Kategorie | Gate machen, wenn… | Signal halten, wenn… |
|---|---|---|
| Formatierung/Lint | Es schnell und stabil ist | Es häufige False-Positives produziert |
| Typprüfungen | Ihre Codebase gut genug typisiert ist | Sie früh in der inkrementellen Einführung sind |
| Unit-/Komponenten-Tests | Sie schnell laufen und deterministisch scheitern | Sie flaky oder zu langsam sind |
| Sicherheitsprüfungen | Sie echte Probleme erkennen (Secrets, verwundbare Deps) | Sie Rauschen reduzieren müssen |
Wolf-Techs JS-Code-Qualitäts-Checkliste ist eine praktische Baseline für moderne Web-Teams.
Phase 2: Einen dünnen vertikalen Slice ausliefern (der schnellste Weg, versteckte Arbeit aufzudecken)
Ein dünner vertikaler Slice ist eine minimale, End-to-End-Nutzerreise, die jede wesentliche Schicht berührt: UI, Backend/API, Datenbank, Authentifizierung/Autorisierung, Logging und Deployment.
Es ist kein Prototyp. Es ist ein kleiner produktionsqualitativ hochwertiger Slice, der die Machbarkeit beweist.
Was in einen dünnen Slice gehört (damit er wirklich entrisikt)
Streben Sie einen Workflow an, der repräsentativ für das echte System ist:
- Ein echter Nutzeridentitätspfad (auch wenn vereinfacht)
- Ein echter Datenschreibvorgang (nicht nur lesend)
- Eine Integrationsnaht (auch wenn hinter einem Vertrag gemockt)
- Eine operative Geschichte: Fehler sind sichtbar, und Rollback ist möglich
Dieser Ansatz wird in vielen Wolf-Tech-Playbooks verwendet, weil er früh Realismus erzwingt. Wenn Sie eine vollständige Version dieses Denkens wünschen, lesen Sie das Konzept eines Lieferungs-„Build-Stacks" in Build Stack: Ein einfacher Blueprint für moderne Produktteams.
Die Slice-Akzeptanzkriterien (kopierbar)
Ihr Slice ist „real", wenn Sie diese Fragen mit Belegen beantworten können:
- Können wir ihn wiederholt ohne manuelle Schritte deployen?
- Wissen wir, wie lange es dauert, bis eine Änderung die Produktion erreicht?
- Wenn er scheitert, sehen wir es schnell (Logs/Metriken/Traces) und erholen uns sicher?
- Haben wir mindestens einen automatisierten Test pro kritischer Regel?
Wenn Sie eine Web-App bauen, kann Wolf-Techs Web-Anwendungs-Checkliste helfen sicherzustellen, dass Ihr Slice die wichtigen Edges abdeckt.
Phase 3: Produktionsbereitschaft (Sicherheit, Zuverlässigkeit und Observability sind Features)
Ein System, das „auf Staging funktioniert", ist kein System. Produktionsbereitschaft schützt das Kundenvertrauen und die Zeit Ihres Teams.
Sicherheits-Baseline: Mit bekannten Standards beginnen
Im Jahr 2026 sind Supply-Chain- und Anwendungssicherheit Grundvoraussetzungen, auch für MVPs.
Praktische Baselines, an denen es sich lohnt, sich auszurichten:
- Die OWASP Top 10 für häufige Web-Risiken und Präventionsprioritäten
- Das NIST Secure Software Development Framework (SSDF), SP 800-218 für Prozesserwartungen, auf die viele regulierte Branchen jetzt verweisen
Pragmatisch halten: Secrets-Handling, Dependency-Scanning, grundlegendes Bedrohungsmodellierung für kritische Flows und sichere Standards für Auth und Datenzugriff.
Zuverlässigkeits-Baseline: Für Fehler entwerfen, nicht auf Hoffnung
Die meisten Ausfälle sind nicht exotisch. Es sind Timeouts, Retries, die die Last verstärken, fehlende Idempotenz, DB-Hotspots und schlechte Observability.
Zuverlässigkeits-Grundlagen früh einführen:
- Timeouts, Retries mit Jitter und Circuit-Breaker wo angebracht
- Idempotente Schreibvorgänge für Operationen, die möglicherweise wiederholt werden
- Back-Pressure und Rate-Limiting auf teuren Endpoints
- Ein klarer Incident-Pfad: On-Call-Erwartungen, Runbooks und Eigentümerschaft
Wolf-Techs Backend-Entwicklung Best Practices für Zuverlässigkeit ist eine starke praktische Referenz.
Observability: Sie wollen Antworten, keine Dashboards
Behandeln Sie Observability als Frage-Antwort-System:
- „Gelingt die Kernreise?" (Erfolgsrate)
- „Wie langsam ist es für echte Nutzer?" (p95-Latenz)
- „Was hat sich geändert?" (Release-Tags, versionierte Deployments)
- „Wo geht die Zeit hin?" (Tracing)
Wenn Sie performance-sensibel im Web sind, richten Sie sich an messbaren Nutzermetriken wie den Core Web Vitals aus. Googles Dokumentation ist die kanonische Referenz: Web Vitals.
Phase 4: Gezielt skalieren (voreilige Komplexität vermeiden, aber Wachstum nicht ignorieren)
Skalierung ist nicht nur Traffic. Es ist auch:
- Mehr Features
- Mehr Integrationen
- Mehr Entwickler
- Mehr Daten
- Mehr Compliance-Anforderungen
Architektur, die für die meisten Teams skaliert: Klare Grenzen und Verträge
In der Praxis ist der größte Prädiktor für Wartbarkeit nicht, ob Sie Microservices gewählt haben. Es ist, ob Grenzen und Verträge explizit und durchgesetzt sind.
Aufbauen rund um:
- Domain-Grenzen: Module oder Services, die auf Geschäftsfähigkeiten abgebildet sind
- Contract-First-APIs/Events: Schemas und Kompatibilitätsregeln
- Eigentümerschaft: Jemand ist verantwortlich für Uptime und Änderungssicherheit
Wolf-Techs Software Systems 101: Grenzen, Verträge und Eigentümerschaft ist ein praktischer Weg, dies real zu machen.
Performance und Kosten: Budgets verwenden, kein Wunschdenken
Im Jahr 2026 sollte Performance-Arbeit messungsbasiert sein. Vermeiden Sie „Optimierungen" ohne Belege.
- Baselines etablieren (Feld und Labor)
- Den größten Engpass mit der kleinsten Änderung beheben
- Leitplanken hinzufügen, um Regressionen zu verhindern
Lesen Sie Performance Software Tuning: Ein messbasierter Workflow für einen konkreten Ansatz.
Ein einfacher 30-60-90-Tage-Plan, den Sie tatsächlich ausführen können
Dies ist ein pragmatischer Ausgangspunkt für programmierende Entwicklung in einer echten Organisation.
Tage 1–30: Feedback schnell und zuverlässig machen
Lieferables, auf die Sie zeigen können sollten:
- Einseitiger Umfang + NFRs + Erfolgsmetriken
- Repo-Konventionen und CI-Gates
- Ein Build-Artefakt und wiederholbare Deployments
- Den ersten dünnen Slice in einer produktionsähnlichen Umgebung
Tage 31–60: Produktion vorhersehbar machen
Fokus auf:
- SLOs für Kernreisen und grundlegendes Alerting
- Logging, Metriken, Tracing, das während eines Incidents nutzbar ist
- Sichere Standards (Secrets, Dependency-Scanning, Auth-Grenzen)
- Eine Rollback-Strategie, mindestens einmal getestet
Tage 61–90: Änderungen günstiger machen
Jetzt verschieben sich Ihre Prioritäten zur Wartbarkeit:
- Grenzen und Verträge (Modulregeln, API-Schemas)
- Qualitätsverbesserungen in Hotspots (Tests wo Änderungen stattfinden)
- Performance- und Kostenbaselines mit Budgets
- Dokumentation, die Onboarding unterstützt (Runbooks, ADRs)
Für Teams, die ein breiteres Betriebsmodell wünschen (nicht nur Code), bietet Wolf-Techs Softwareentwicklungsstrategie für diverse Teams eine nützliche Struktur.
Häufige Fallen im Jahr 2026 (und bessere Standards)
Falle: Einen „modernen Stack" wählen, bevor Sie Ihre Einschränkungen kennen
Besserer Standard: Einen fähigkeitsorientierten Auswahlansatz verwenden und mit einem dünnen Slice validieren. Wolf-Techs Software-Technologie-Stack-Scorecard legt einen messbaren Weg zur Auswahl dar.
Falle: KI-Coding-Tools als Abkürzung um Engineering herum behandeln
Besserer Standard: KI verwenden, um die Ausführung zu beschleunigen, aber menschlich gesteuerte Standards beibehalten:
- Code-Review-Disziplin
- Tests für Geschäftsregeln
- Sicherheitsprüfungen für Dependencies und Secrets
- Dokumentierte Entscheidungen (ADRs)
Falle: „Wir fügen Observability später hinzu"
Besserer Standard: Minimale Telemetrie am ersten Tag hinzufügen. Ohne sie wird jeder Incident zu einer Debatte.
Falle: Big-Bang-Rewrites, um „die Architektur zu reparieren"
Besserer Standard: Inkrementelle Modernisierung mit gemessenen Ergebnissen. Wenn Sie mit Legacy-Einschränkungen zu tun haben, beginnen Sie mit Legacy-Code zähmen: Strategien, die wirklich funktionieren.
Wann externe Hilfe einzuholen ist (und was zu verlangen ist)
Externe Unterstützung ist am wertvollsten, wenn sie Risiken schnell reduziert – besonders rund um Architektur, Liefersicherheit und Legacy-Modernisierung.
Hochwertige Engagements sehen typischerweise so aus:
- Architektur-Review mit Belegen: Fokus auf Ergebnisse, NFRs, Grenzen und Betreibbarkeit (nicht Geschmack)
- Thin-Slice-Validierungs-Sprint: Machbarkeit und Liefermechanik in 2 bis 4 Wochen beweisen
- Legacy-Optimierungsplan: Hotspots priorisieren und Sicherheitsmechanismen einführen, ohne Feature-Arbeit zu stoppen
Wenn Sie eine klare Sicht darauf haben wünschen, was ein ernsthafter Review abdecken sollte, lesen Sie Was ein Tech-Experte in Ihrer Architektur prüft.
Wie Wolf-Tech programmierende Entwicklung in der Praxis unterstützt
Wolf-Tech arbeitet mit Teams zusammen, um Produktionssoftware über moderne Stacks hinweg zu bauen, zu optimieren und zu skalieren – mit einem starken Schwerpunkt auf Code-Qualität, Liefersystemen und pragmatischer Architektur.
Wenn Sie einen Build oder eine Modernisierung für 2026 planen und ein zweites Paar erfahrener Augen wünschen, beginnen Sie mit einem fokussierten Review oder einem Thin-Slice-Plan. Sie können Wolf-Techs Ansatz unter wolf-tech.io erkunden und die Blog-Ressourcen oben verwenden, um sich intern abzustimmen, bevor Sie sich engagieren.